Extractive Text Summarization Using Machine Learning Technique - Random Forest
 Aditya Tomar
Aditya Tomar
Nowadays, Automatic text summarization is gaining importance due to the abundance of online text data and the difficulty of going through all the information. Summarization helps reduce the reading time and navigate huge amounts of information efficiently by highlighting the key points. Summaries aid in selecting relevant documents when researching as they highlight the most important information. Summarization techniques can extract important sentences, paragraphs, or sections and condense the text while retaining its key ideas.
So, keeping in mind that text summarizations reduce reading time I have made the project on this using Machine Learning and it is also the Minor project I had completed now.
In this article, we will discuss in depth how the project was made using a Random Forest Machine Learning technique on Google collab.
Objective
This project aims to create a Machine Learning model using Random Forest Classification technique. The effectiveness and robustness of the Model will be evaluated using openly available datasets like Trip Advisor about which will be discussed in detail shortly. The primary goal is to develop a machine learning model tailored for extractive summarization, fine tuning its performance through a thorough exploration of different features and assessing its reliability and effectiveness with publicly accessible dataset.
Setting Up Environment
import sys, os
ON_COLAB = 'google.colab' in sys.modules
if ON_COLAB:
GIT_ROOT = 'https://github.com/blueprints-for-text-analytics-python/blueprints-text/raw/master'
os.system(f'wget {GIT_ROOT}/ch09/setup.py')
%run -i setup.py
The above code determines whether the Python script is running on Google Colab (a cloud-based machine learning platform) and, if so, downloads a setup file from a GitHub repository and runs it with '%run -i setup.py'. The setup file most likely provides configuration or setup instructions to ensure that the code runs properly in the Colab environment.
Dataset and Algorithm To Be Used
Dataset-The dataset which we will be using is Trip Advisor. This dataset likely contains information and reviews about various travel-related experiences, such as hotels, restaurants, and attractions. Researchers and developers can use this dataset to analyze and derive insights about user opinions and ratings for different travel destinations and services. This dataset contains 7358 rows with 8 attributes which are Filename, ThreadID , Title , userID , Date , postNum , text , summary.
Algorithm - Random Forest is an advanced machine learning classification technique. Consider it a virtual forest of decision trees collaborating to create predictions. Each tree, like a mini-expert, votes on the outcome independently. These votes are combined by the algorithm to produce a democratic decision.
Consider a game of 20 Questions, where each question contributes to the final solution. Random Forest operates in a similar manner, producing distinct trees by training on various subsets of data and characteristics. This variety guarantees a robust and accurate prediction.
Random Forest improves accuracy and decreases overfitting, making it suitable for a wide range of applications. Its versatility and ensemble nature make it an excellent choice for forecasting outcomes in real-world settings ranging from customer preferences to illness diagnosis. So, when it comes to accuracy and dependability, Random Forest stands tall in the algorithmic forest of possibilities.
Creating Target Labels
Now , after setting up environment it is time to create target labels by using below code.
import pandas as pd
import numpy as np
pd.set_option('display.max_colwidth', 500)
pd.set_option('display.max_rows',1000)
file = "travel_threads.csv.gz"
file = f"{BASE_DIR}/data/travel-forum-threads/travel_threads.csv.gz"
### real location
df = pd.read_csv(file, sep='|', dtype={'ThreadID': 'object'})
df[df['ThreadID']=='60763_5_3122150'].head(1).T
The code above performs task which are -
Imports the required pandas (as pd) and numpy (as np) libraries.
Sets pandas display parameters to show a maximum of 500 characters per column and 1000 rows.
Creates a CSV file path ("travel_threads.csv.gz") and reads it into a pandas DataFrame (df). The file is considered to be in the directory supplied by the BASE_DIR variable.
Selects and shows the first row (transposed) of the DataFrame with the value '60763_5_3122150' in the 'ThreadID' column.
Pandas is a strong Python data manipulation and analysis toolkit.It offers data structures such as DataFrame, a two-dimensional, size-mutable, possibly heterogeneous tabular data structure with named axes (rows and columns). To read data from a CSV file into a DataFrame, use pd.read_csv().DataFrame procedures are used to easily evaluate and alter data.
Numpy is a Python numerical computation package.It supports massive, multi-dimensional arrays and matrices, as well as mathematical algorithms for operating on these arrays.
Text Preprocessing
Now ,its time for the main and crucial step which is cleaning the textual data before training our dataset. The code below is using various functions to clean the text for better performance.
from blueprints.preparation import clean as regex_clean
pip install textacy
import re ###
import spacy ###
from spacy.tokenizer import Tokenizer
from spacy.util import compile_prefix_regex, \
compile_infix_regex, compile_suffix_regex
#from textacy.preprocessing.replace import replace_urls
import textacy
def custom_tokenizer(nlp):
# use default patterns except the ones matched by re.search
prefixes = [pattern for pattern in nlp.Defaults.prefixes
if pattern not in ['-', '_', '#']]
suffixes = [pattern for pattern in nlp.Defaults.suffixes
if pattern not in ['_']]
infixes = [pattern for pattern in nlp.Defaults.infixes
if not re.search(pattern, 'xx-xx')]
return Tokenizer(vocab = nlp.vocab,
rules = nlp.Defaults.tokenizer_exceptions,
prefix_search = compile_prefix_regex(prefixes).search,
suffix_search = compile_suffix_regex(suffixes).search,
infix_finditer = compile_infix_regex(infixes).finditer,
token_match = nlp.Defaults.token_match)
nlp = spacy.load('en_core_web_sm')
nlp.tokenizer = custom_tokenizer(nlp)
def extract_lemmas(doc, kwargs):
return [t.lemma_ for t in textacy.extract.words(doc, kwargs)]
def extract_noun_chunks(doc, include_pos=['NOUN'], sep='_'):
chunks = []
for noun_chunk in doc.noun_chunks:
chunk = [token.lemma_ for token in noun_chunk
if token.pos_ in include_pos]
if len(chunk) >= 2:
chunks.append(sep.join(chunk))
return chunks
def extract_entities(doc, include_types=None, sep='_'):
ents = textacy.extract.entities(doc,
include_types=include_types,
exclude_types=None,
drop_determiners=True,
min_freq=1)
return [re.sub('\s+', sep, e.lemma_)+'/'+e.label_ for e in ents]
def clean(text):
# Replace URLs
text = re.sub(r'https?://\S+|www\.\S+', '[URL]', text)
# Replace semi-colons (relevant in Java code ending)
text = text.replace(';','')
# Replace character tabs (present as literal in description field)
text = text.replace('\t','')
# Find and remove any stack traces - doesn't fix all code fragments but removes many exceptions
start_loc = text.find("Stack trace:")
text = text[:start_loc]
# Remove Hex Code
text = re.sub(r'(\w+)0x\w+', '', text)
# Initialize Spacy
doc = nlp(text)
# From Blueprint function
lemmas = extract_lemmas(doc,exclude_pos = ['PART', 'PUNCT', 'DET', 'PRON', 'SYM', 'SPACE', 'NUM'],
filter_stops = True,
filter_nums = True,
filter_punct = True)
return lemmas
The above text preprcoessing code doed the following tasks.
Import libraries: The code includes libraries like re (regular expressions), spacy, and textacy. It uses pip install textacy to install the textacy library.
Custom Tokenizer Function: This function (custom_tokenizer) defines a custom tokenizer function for the spaCy natural language processing library. It also excludes particular characters and patterns from the default tokenization patterns.
Text Cleaning Function:
Defines a function ('clean') to clean up text data in various ways:
Replace URLs with the placeholder '[URL]'.
Removes semicolons.
Removes character tabs.
Removes stack traces (error messages) starting from "Stack trace:".
Removes hexadecimal codes.
Tokenizes the text using the spaCy pipeline and extracts lemmas (base forms of words).
- Entity and Chunk Extraction Functions:
This defines functions for extracting noun chunks and entities from spaCy-processed text (extract_noun_chunks and extract_entities).
- DataFrame Operations:
Apply a regex-based cleaning function (regex_clean) to the DataFrame's 'text' column.
Apply the custom clean function on the 'text' column, extracting lemmas and saving the results in a new column named labelled ‘lemmas’.
Now , we will split the data into training and testing data in 80:20 ratio means 80% data is training data and 20% is testing data. We will be using scikit-learn's GroupShuffleSplit to perform a single split of a dataset into training and testing sets while taking into account a grouping variable.
from sklearn.model_selection import GroupShuffleSplit
gss = GroupShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
train_split, test_split = next(gss.split(df, groups=df['ThreadID']))
Now we will use df.iloc[] to segregate into train and test data.
train_df = df.iloc[train_split]
test_df = df.iloc[test_split]
print ('Number of threads for Training ', train_df['ThreadID'].nunique())
print ('Number of threads for Testing ', test_df['ThreadID'].nunique())
Output of above code is:
Number of threads for Training 559
Number of threads for Testing 140
Now we will calculate the Jaro-Winkler similarity between the 'text' and 'summary' columns in a DataFrame named train_df. Jaro-Winkler similarity is a measure of how similar two strings are. It calculates the similarity of two strings by comparing the characters they share as well as the order in which those characters appear. The Jaro-Winkler similarity yields a value between 0 and 1, with 0 indicating no resemblance and 1 indicating an exact match.
It then ranks the similarity scores within each thread (grouped by 'ThreadID') and creates a new column 'rank'. Finally, it filters the rows based on a compression factor, creating a new column 'summaryPost' to retain only the top N rows within each thread, where N is determined by the compression factor.The code for this is shown below:
import textdistance
compression_factor = 0.3
train_df['similarity'] = train_df.apply(
lambda x: textdistance.jaro_winkler(x.text, x.summary), axis=1)
train_df["rank"] = train_df.groupby("ThreadID")["similarity"].rank(
"max", ascending=False)
topN = lambda x: x <= np.ceil(compression_factor * x.max())
train_df['summaryPost']=
train_df.groupby('ThreadID')['rank'].apply(topN)
Adding features to assist model prediction
train_df['titleSimilarity'] = train_df.apply(
lambda x: textdistance.jaro_winkler(x.text, x.Title), axis=1)
## Adding post length as a feature
train_df['textLength'] = train_df['text'].str.len()
train_df.loc[train_df['textLength'] <= 20, 'summaryPost'] = False
feature_cols = ['titleSimilarity','textLength','postNum']
train_df['combined'] = [
' '.join(map(str, l)) for l in train_df['lemmas'] if l is not '']
tfidf=TfidfVectorizer(min_df=10,ngram_range=(1,2), stop_words="english")
tfidf_result = tfidf.fit_transform(train_df['combined']).toarray()
tfidf_df=pd.DataFrame(tfidf_result, columns=tfidf.get_feature_names_out())
tfidf_df.columns = ["word_" + str(x) for x in tfidf_df.columns]
tfidf_df.index = train_df.index
train_df_tf = pd.concat([train_df[feature_cols], tfidf_df], axis=1)
test_df['similarity'] = test_df.apply(lambda x: textdistance.jaro_winkler(x.text, x.summary), axis=1)
test_df["rank"] = test_df.groupby("ThreadID")["similarity"].rank("max", ascending=False)
topN = lambda x: x <= np.ceil(compression_factor * x.max())
test_df['summaryPost'] = test_df.groupby('ThreadID')['rank'].apply(topN)
test_df['titleSimilarity'] = test_df.apply(lambda x: textdistance.jaro_winkler(x.text, x.Title), axis=1)
test_df['textLength'] = test_df['text'].str.len()
test_df.loc[test_df['textLength'] <= 20, 'summaryPost'] = False
test_df['combined'] = [' '.join(map(str, l)) for l in test_df['lemmas'] if l is not '']
tfidf_result = tfidf.transform(test_df['combined']).toarray()
tfidf_df = pd.DataFrame(tfidf_result, columns = tfidf.get_feature_names_out())
tfidf_df.columns = ["word_" + str(x) for x in tfidf_df.columns]
tfidf_df.index = test_df.index
test_df_tf = pd.concat([test_df[feature_cols], tfidf_df], axis=1)
This Python code snippet provides a complete text processing and feature engineering strategy for NLP jobs. It calculates Jaro-Winkler similarity between the 'text' and 'Title' columns, adds a 'textLength' feature, and filters short texts. It turns lemmatized text into numeric features via TF-IDF vectorization, improving the model's grasp of the input. To ensure uniformity, the technique is done to both training and test datasets. This code sets the basis for a powerful machine learning model to properly assess and categorize textual input by using similarity metrics and informative features.
Build a Machine Learning Model
Now, we will build the machine learning model using sklearn.ensemble
Module which is present in sickit-learn library ,a popular machine learning library in Python. We will use RandomForestClassifier which is a method in sklearn.ensemble to build Random Forest model. After choosing the model we will use “fit” method to train the model (model1) on the training data. The training data consists of features (train_df_tf) and the target variable (train_df['summaryPost']), where the model learns to predict whether posts are considered summaries (True) or not (False).
The code snippet is:
from sklearn.ensemble import RandomForestClassifier
model1 = RandomForestClassifier(random_state=20)
model1.fit(train_df_tf, train_df['summaryPost'])
Now, we just have to predict the output of summary generated using our model.
test_df['predictedSummaryPost'] = model1.predict(test_df_tf)
example_df = test_df[test_df['ThreadID'] == '60974_588_2180141']
print('Total number of posts', example_df['postNum'].max())
print('Number of summary posts',
example_df[example_df['predictedSummaryPost']].count().values[0])
print('Title: ', example_df['Title'].values[0])
example_df[['postNum', 'text']][example_df['predictedSummaryPost']]
Output is:

Measure Performance
Using Confusion Matrix
A confusion matrix is a table used to assess the effectiveness of a classification system. It is very beneficial in the fields of machine learning and statistics. The confusion matrix summarizes a classification model's performance by displaying the number of accurate and wrong predictions generated by the model in comparison to the actual results.
A confusion matrix normally includes four entries in a binary classification issue (where there are two potential classes, sometimes designated as "positive" and "negative").
True Positive (TP): The number of positive predictions that were right.
True Negative (TN): The amount of times a negative prediction was right.
False Positive (FP): The number of positive predictions that were inaccurate (Type I error).
False Negative (FN): The number of instances anticipated as negative when they were not (Type II error).
Using the values in the confusion matrix, various performance metrics can be calculated, including:
Accuracy: (TP + TN) / (TP + TN + FP + FN)
Precision: TP / (TP + FP)
Recall (Sensitivity or True Positive Rate): TP / (TP + FN)
Specificity (True Negative Rate): TN / (TN + FP)
F1 Score: 2 (Precision Recall) / (Precision + Recall)
Code:
import matplotlib.pyplot as plt
# Extract true and predicted labels
y_true = test_df['summaryPost']
y_pred = test_df['predictedSummaryPost']
# Calculate confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred)
fig, ax = plt.subplots(figsize=(2,2))
ax.matshow(cm, cmap=plt.cm.Blues, alpha=0.3)
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(x=j, y=i,s=cm[i, j], va='center', ha='center', size='xx-large')
plt.xlabel('Predictions', fontsize=18)
plt.ylabel('Actuals', fontsize=18)
plt.title('Confusion Matrix', fontsize=18)
plt.xticks([0.5, 1.5], ['False', 'True'], fontsize=14)
plt.yticks([0.5, 1.5], ['False', 'True'], fontsize=14)
plt.show()
Output is a matrix of 2*2:

Here, we can see if actual output is false and prediction is also false so it gives correct output 883 times which is good score.Similarly if actual is true and predicted is also true it gives 357 times correct output.
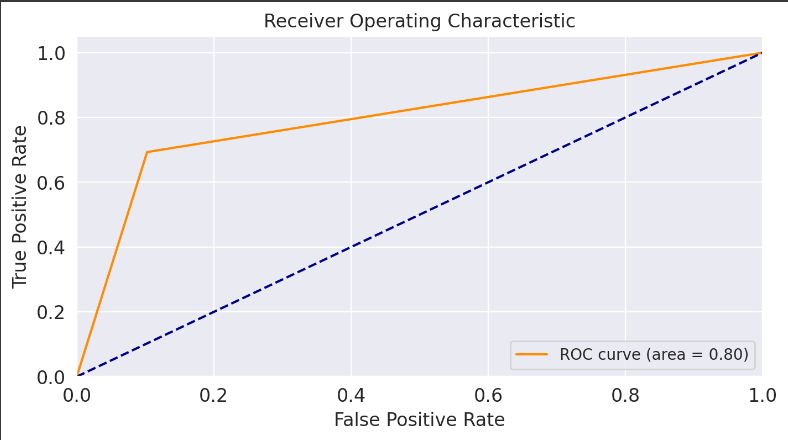
Using ROC Curve
The Receiver Operating Characteristic (ROC) curve is a graphical depiction of a binary classification model's performance at various threshold levels. At various threshold settings, it shows the true positive rate (sensitivity or recall) versus the false positive rate.
A ROC curve looks like this:
The x-axis displays the false positive rate (FPR), which is computed as FP / (FP + TN).
The y-axis displays the true positive rate (TPR), which is computed as TP / (TP + FN).
The code snippet is:
# Add ROC Curve
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_true, y_pred)
roc_auc = auc(fpr, tpr)
import matplotlib.pyplot as plt
plt.figure()
plt.plot(fpr, tpr, color='darkorange', label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
Output is ROC curve value comes out to be 0.8 and it has range from 0 to 1.An AUC-ROC value of 0.8 suggests that the model has good discriminatory power. It means that, on average, the model has a high true positive rate while keeping the false positive rate relatively low across different classification thresholds.
Conclusion and Future Scope
This project dealt with extractive text summarization using random forest classification technique and the accuracy is good enough on the Trip advisor dataset which we have chosen. Our aim is to work on LLMs i.e. Large Language models to step into the field of Generative AI and increase the effectiveness of text summary by also gathering past queries.
Subscribe to my newsletter
Read articles from Aditya Tomar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Tomar
Aditya Tomar
I am a developer from India and I am continuously learning and sharing knowledge with the community.