Octo - Your AI-Powered GitHub Companion
 Pranav Prajapati
Pranav Prajapati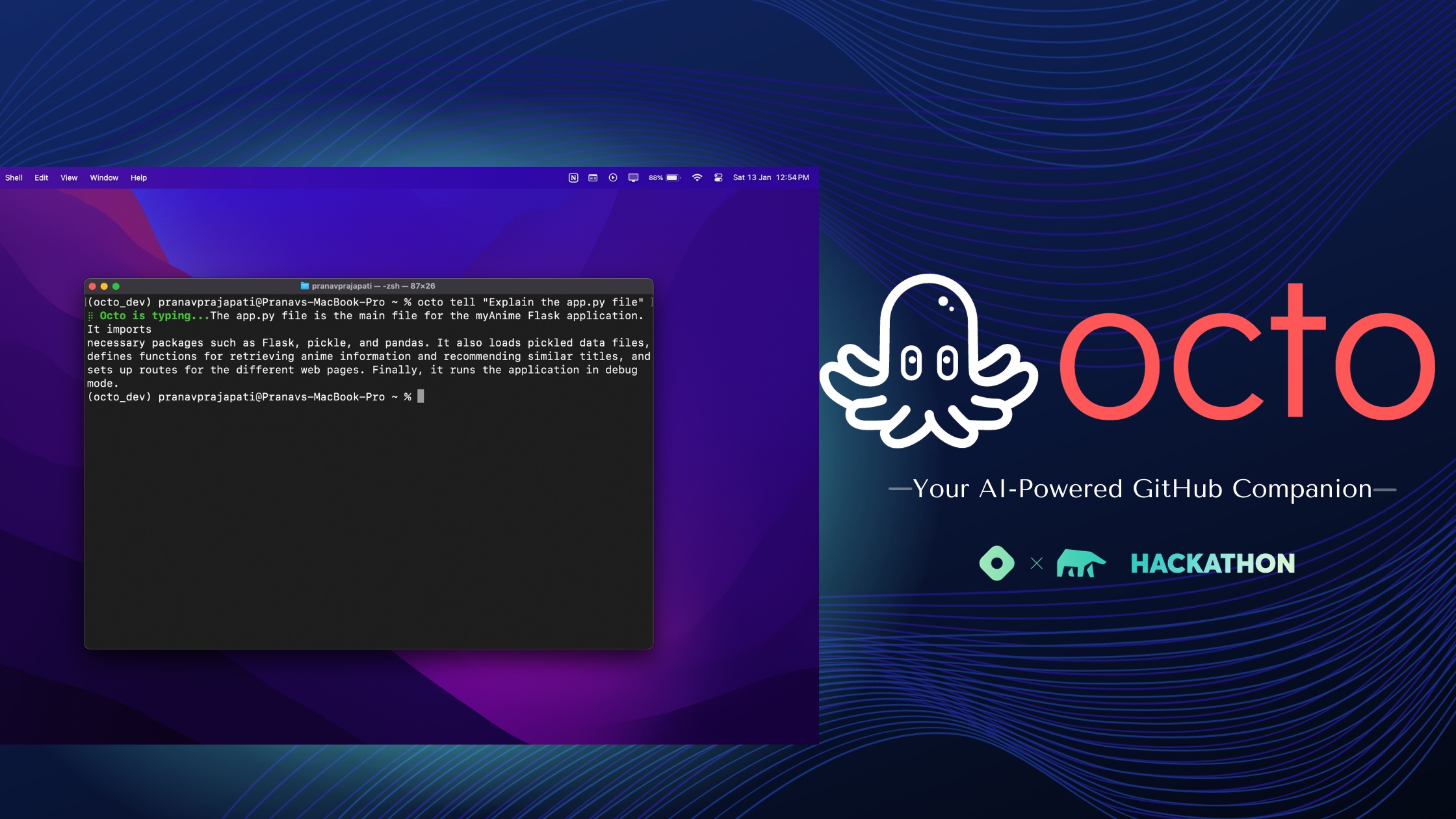
Octo is a command-line tool with commands similar to git. It is powered by Large Language Models it allows users to QA the GitHub repository with native git commands and add a tell command that answers all your questions regarding the repository.
Story Behind Building Octo
It was a usual evening in the month of December and I was just scrolling through my discord updates until I saw Mindsdb has announced an AI agent hackathon in collaboration with Hashnode in the Hashnode server. This sparked my interest as a few days ago I saw a video from Fireship talking about 15 futuristic Databases which included Mindsdb too, video. So finally I had enough signs and motivation to participate in the hackathon. So I started with the hackathon page and explored some ideas.
Later I joined the slack channel of Mindsdb where I found the blogs of previous hackathon winners. From the 5 winners, I was inspired by Hey-Pair Programming Partner. Being inspired by the awesome-looking project, I made up my mind to build a CLI tool but, the idea was already done and dusted. Meanwhile, I was going through the docs of Mindsdb, and I found the llama_index integration. Diving deep into it I found with the help of RAG and llama_index I can add any website page in the knowledge source of my LLM. So using the SimpleWebPageReader in mindsdb llama_index handler, we can achieve this and then QA that webpage.
The first thing that came to my mind was to ingest the page of the GitHub repository using the integration. I did it and failed miserably 😅. As Simple Web-Page loader was unable to add all the files from the Github repository to the knowledge source. Now my 1st idea for the hackathon failed and I was back to the start. Meanwhile, I found that the current llama_index integration from mindsdb only supported 2 loaders DFReader and SimpleWebPageReader. At the same time, there are many loaders available on llama_hub which were remaining to add in the integration of mindsdb. While surfing through the loaders in the llama hub I found a GithubRepositoryReader a loader for adding GitHub repositories to knowledge sources.
Now I was back to the old idea, of creating a command line tool to QA any Github Repository. So the first task I had to do was learn how to add a new integration to mindsdb. After going through the documentation I started contributing to add a new handler in Mindsdb, and it worked. I made a PR with llama_index_github_handler and added a new handler in mindsdb that was able to add repositories to the knowledge source of LLM. Link to PR. I was so happy that was able to make a working integration for mindsdb and now I can use it in my project!
But............
Wake up to reality, Nothing goes as ever planned. - Madara Uchiha
I had a talk with Zoran maintainer of Mindsdb regarding the PR, and he asked me to update the existing llama_index handler, and not create a whole new handler as there are many loaders in llama_hub and it is not feasible to add a new handler for each of the loaders.
Back to basics
Now once again I was back to start, but Zoran provided me with the solution to the problem and asked to update the existing handler with the GithubLoader. So now I started working on updating the existing llama_index integration. After some brainstorming, I found a good solution to not only add GithubLoader to the existing integration but also add more loaders from llama_hub. This idea came from the design of picking models in Keras NLP, as I have been working too much lately on the Keras ecosystem. So finally I updated the handler and instead of adding just the GithubLoader, I ended up adding YoutubeTranscriptLoader also. Now it was easy to add new loaders to the handler due to the design I picked from Keras NLP which was adding config.py a file to validate inputs of the model before creation. So once again I finally updated the handler and was ready to make the PR.
This time the PR was merged successfully and I was so happy I made a tweet regarding the Update which was retweeted by the CEO of mindsdb Jorge Torres.
This tweet also received a reply from llama_index's official Twitter handler. Now that the handler is being merged. I could now finally work on Octo and consume the update I made in the llama_index integration.
Shutdown/Depreciation of OpenAI models
Now that everything was working fine OpenAI decided to shut down the legendary text-davinci-003 model. This was used by the llama_index handler by default in mindsdb. Also chat models like gpt-3.5-turbo where migrated to openai>=1.0.0.I wasn't able to change the handler at the time of model creation due migration of v1/chat/completion endpoints and it went to the default text-davinci-003 the model was shut down by OpenAI on 4th Jan, lol I still remember the day it was a nightmare as the hackathon was going to end on 15th Jan and I didn't start working on Octo which was the actual project for the hackathon.
But come on we are developers and I created a new issue in mindsdb informing them of the changes in OpenAI. Meanwhile, I made a PR to fix this issue in the llama_index handler which would now use the default model as gpt-3.5-turbo-instruct which belonged to v1/completion endpoint. This PR is yet to be merged due to some issues with the get_api_key() utility in mindsdb.
So I used the fixed fork of mindsdb which was working to start building octo.
That's it, there were lot a preparations done before building octo. From bringing a whole new handler in mindsdb to updating the llama_index existing handler. It was quiet fun contributing to mindsdb during the hackathon. Now let's get real stuff i.e Octo.
Introduction
Octo seamlessly blends the power of artificial intelligence with the familiarity of Git, empowering you to interact with your repositories in a whole new way. Whether you're a seasoned developer or just getting started with Git, Octo offers innovative features to streamline your workflow and enhance your productivity.
Commands utilized
Native Git Integration:
status: View information about your current repository.checkout: Switch between repositories effortlessly.init: Initialize Octo for a new project.
Interactive AI Agent: Interact with Octo using natural language:
tell: Explain functions, know the repository and be ready with your contributions
Effortless Workflow Management:
start: Activate the MindsDB server (essential for AI features).stop: Gracefully stop the MindsDB server.drop: Remove repositories from your Octo list.list: Display all the models created
Usage
Requirements
Firstly you need to have OPENAI_API_KEY and GITHUB_TOKEN and set the environment variables OPENIAI_API_KEY and GITHUB_TOKEN respectively.
$ echo "export OPENAI_API_KEY=<KEY>" >> ~/.bashrc
$ echo "export GITHUB_TOKEN=<TOKEN>" >> ~/.bashrc
If you're using Zshell (ZSH), run the following command instead.
$ echo "export OPENAI_API_KEY=<KEY>" >> ~/.zshrc
$ echo "export GITHUB_TOKEN=<TOKEN>" >> ~/.zshrc
Close the terminal and reopen it to redefine the environment variables.
Local Installation
Note: This quick tutorial is designed for octo version 0.1.0 and this version is not stable on Windows machines yet. It's highly recommended to use octo on Unix-like operating systems like Linux distros or MacOS.
Clone the project
git clone https://github.com/pranavvp16/octo.gitGo to the project directory
cd octoSet up your local environment by Python venv or conda. It is highly recommended to set up your environment and install all the packages in it.
Install dependencies
Once you have set up your environment you can start installing the packages in it.
pip install -r requirements.txtpip install git+https://github.com/pranavvp16/mindsdb.git@llama_indexpip install .To check your installation
octo start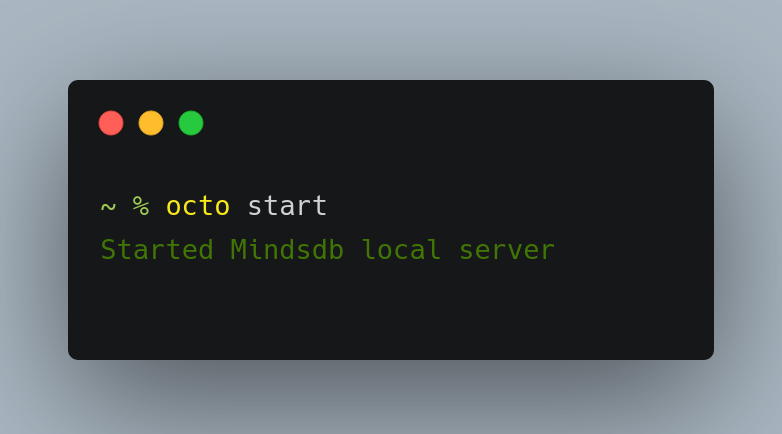
octo --version
Octo commands
startcommand to start the mindsdb server locally. This command starts the local minsdb server in the background by running a subprocess in the shell.def start_local(self): """ Connect to local installation of mindsdb """ # Run shell command to start the local mindsdb server command = "nohup python -m mindsdb > mindsdb.log 2>&1 &" subprocess.run(command, shell=True, check=True)octo start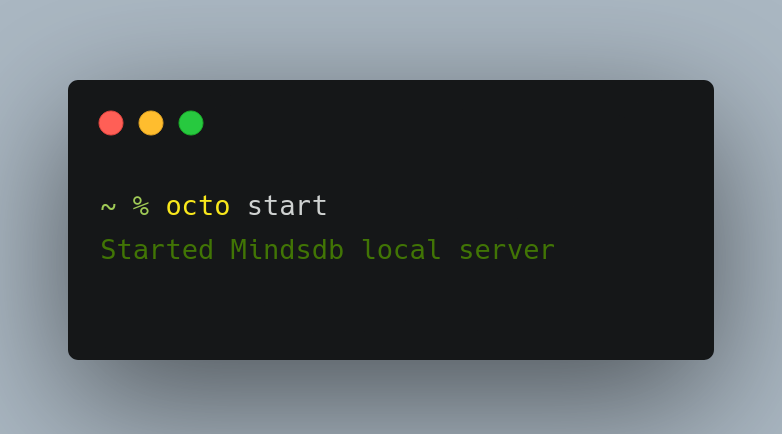
You can ignore the MindsDB Web portal that will be launched in your web browser.
initcommand to initialize the repo. As the server is running you will be able to initialize the repo in Octo by following the syntax below. By default, this init command will add all the .docs and .md files in the knowledge source of the LLM.def init(self, repo, owner, branch, all_files=False): if not os.path.exists(".octo"): os.makedirs(".octo") self.repo = repo self.owner = owner self.branch = branch self.repo_initialized = True message, error = self.create_model( self.owner, self.repo, self.branch, all_files=all_files ) if not error: self._save_state() elif ( self.repo.lower() == repo and self.owner.lower() == owner and self.branch.lower() == branch ): message = f"[bold][blue]Repository already initialized." self.repo_initialized = True else: self.repo = repo self.owner = owner self.branch = branch self.repo_initialized = True message, error = self.create_model( self.owner, self.repo, self.branch, all_files=all_files ) if not error: self._save_state() return messageocto init <GitHubUsername>/<repo> <branch_name>But if you want the ingest all the files in the repository you can do this by passing the
--allflag. This will enable you to add all the files in the repository to the knowledge source of LLMocto init <GitHubUsername>/<repo> <branch_name> --allWarning: Github stops the loader while trying to ingest large repositories based on the API key.

statuscommand to check the status of the octo.Now that you have initialized a repository successfully with Octo. You can check the status of Octo by the
statuscommand. This should print the AI table to which Octo is currently pointing in mindsdb.def status(self): return f"[bold][green]On branch {self.branch}\n[bold][blue]Repository: {self.owner}/{self.repo}"octo status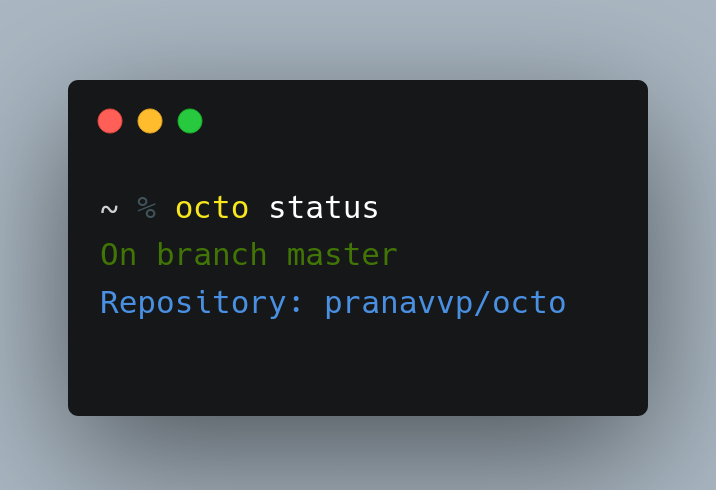
tellcommand for asking questions about the repo.The tell command is the main feature of Octo which will answer the question asked regarding the repo which was initialized using octo.
def tell(self, df): pred = self.predict(df, self.owner, self.repo) return predocto tell "<Your Question>"
checkoutcommand to change the working repoOcto can work with different repositories with the checkout command. The checkout command can work by changing the repository which was already initialized and its model exists in mindsdb. So need to initialize a repo with octo before checking out!
def checkout(self, owner, repo): self.owner = owner self.repo = repo model_names = [i.name for i in self._get_project().list_models()] if f"{owner}_{repo}" not in model_names: return f"[bold][red]Error: Repository not initialized. Use 'octo init' to initialize." else: self.status() self._save_state() return f"[bold][green]Switched to repo '{owner}/{repo}'."octo checkout <GitHubUsername>/<repo>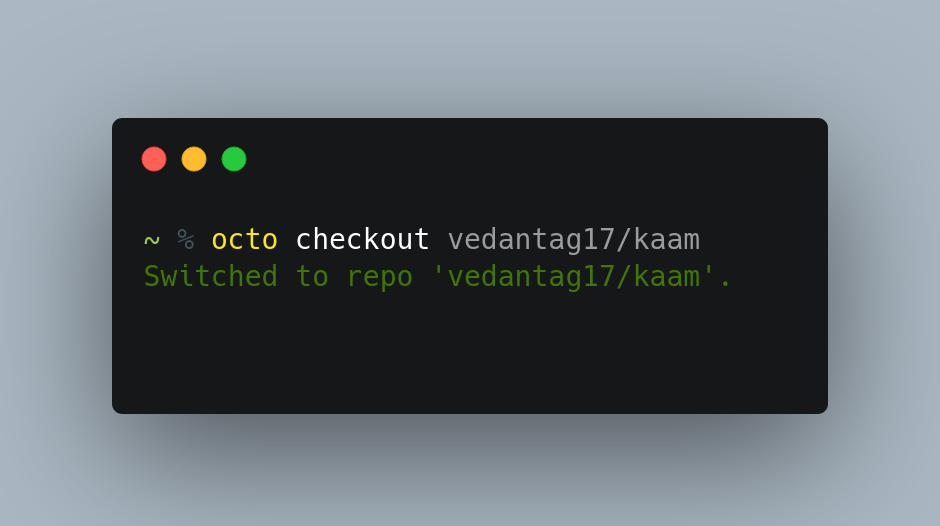
Now, we can check if the
checkoutwas successful or not by checking itsstatus.
If we try to
checkouta repo that is not initialized before then following steps can be followed.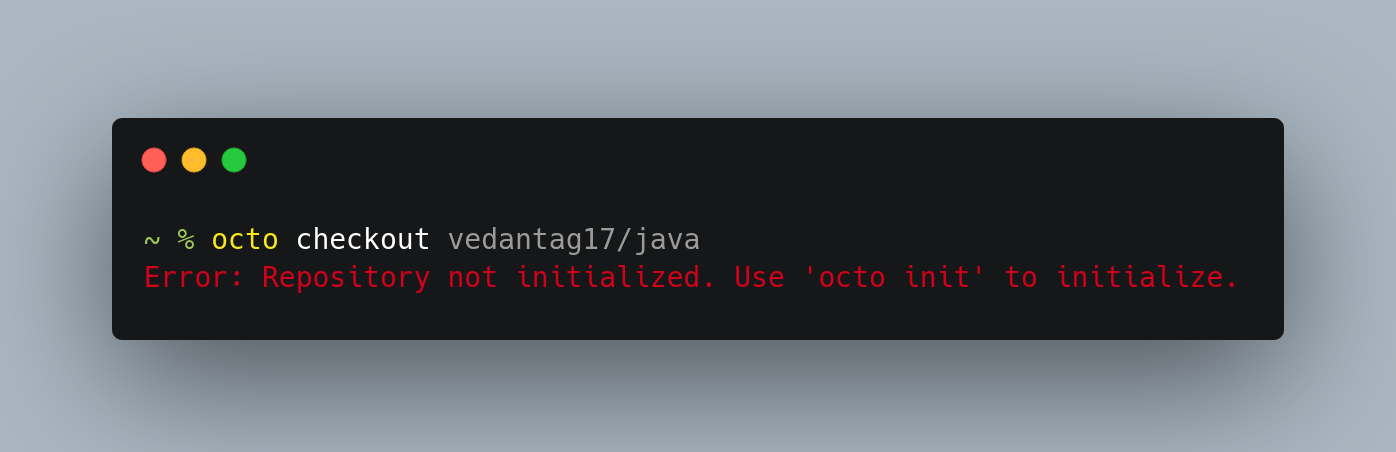
Oops! you can see an error is displayed as I forgot to initialize the repo before checkout.
You will have to initialize the repo first withinitand then you cancheckoutin further commands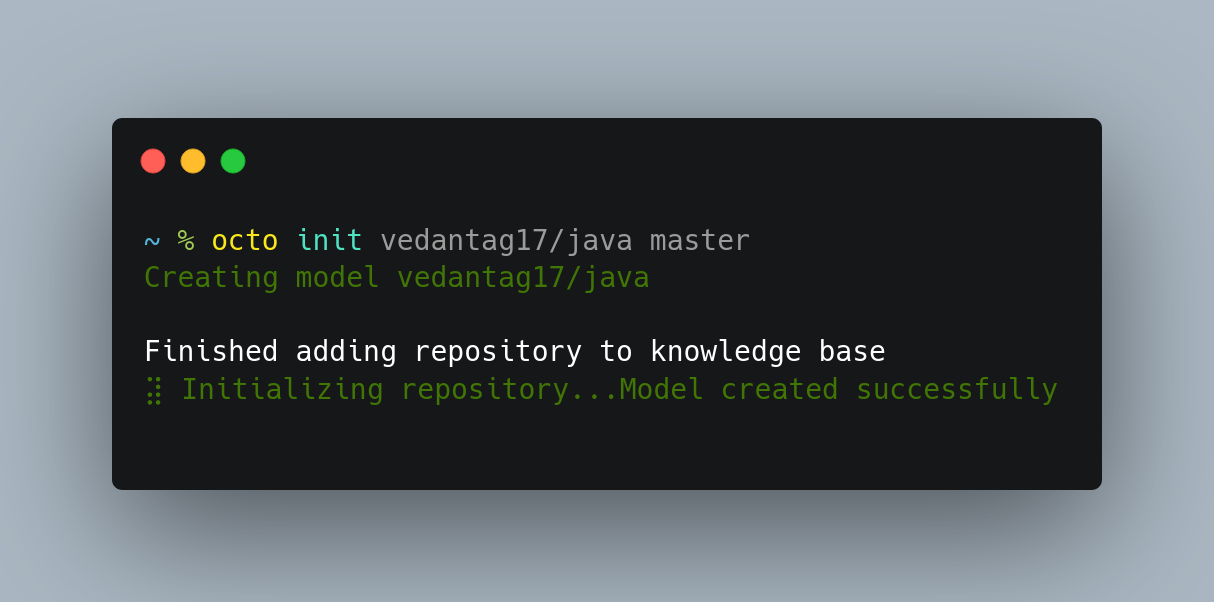
Now I have initialized the repo and it will automatically be set as a working repo. Meanwhile, you switch to the previous repository with the
checkoutcommand.dropcommand to remove a modelThe drop command is a utility command in octo that can be used to drop and delete repositories that were initialized with octo. Sometimes model training fails in mindsdb, the drop commands can be used to drop models that failed during training and are of no use currently.
def drop(self, owner, repo): project = self._get_project() try: project.drop_model(f"{owner}_{repo}") return f"[bold][green]Deleted model {owner}/{repo}" except: return f"[bold][red]Error: Model {owner}/{repo} does not exist"octo drop <GitHubUsername>/<repo>
listcommand to display all the models initializedYou can take a look at all the models that you have created in mindsdb using the list command. This will print all the models that were initialized using octo.
if args.command == "list": model_names = octo.list_models() # Format the string model_names = [i.replace("_", "/") for i in model_names] with console.status("[bold green]Fetching models...", spinner="dots2"): for i in model_names: console.print(i)octo list
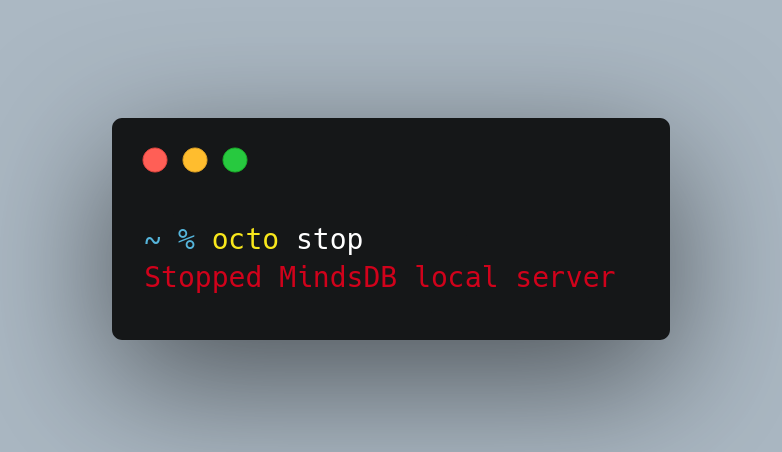
stopcommand to terminate the mindsdb serverAs Octo works on the local installation of mindsdb, It needs the local server running which we achieved from
octo startcommand. After all your work is done you can stop the local server withocto stop.def stop_local(self): """ Stop local installation of mindsdb """ # Run shell command to stop the local mindsdb server command = 'pkill -f "python"' subprocess.run(command, shell=True, check=True, stdout=subprocess.DEVNULL)octo stop
Key Features
At this stage of octo, we recommend you utilize it for small to medium-sized repositories as the rate limit criteria of OPENAI and Github Client from llama_index stop working when trying to ingest large repositories.
Know your repo better
Making it easier to contribute to organizations
Personal Chat GPT, working on your repository
Future Updates
We know some bugs need to be fixed in octo, and we will continue building it. The next goal of octo is to upload the package of PyPi which we were unable to do due to a few reasons.
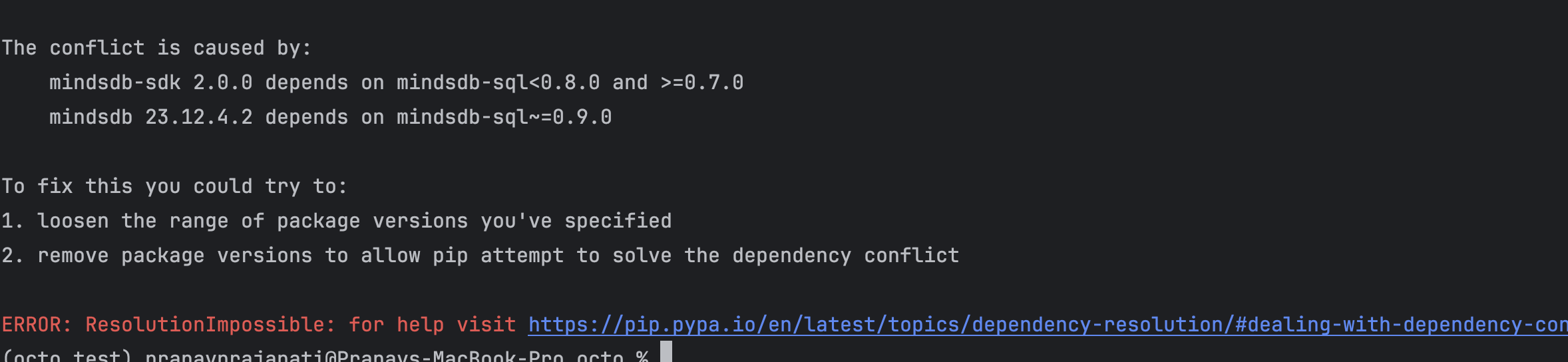
Mindsdb's latest version and mindsbd_sdk==2.0.0 cannot be installed in the same script at the same time due to dependency conflicts. So the
setup.pyfailure while installing octo withpip install octo. Once this error is fixed octo will be available to PyPi too.Edit: This has been fixed by the mindsdb team now. [16th Jan,2024]
The PR fixing the OpenAI depreciation is yet to be merged, once it is fixed in Mindsdb and it releases its latest version. Octo will be able to directly download mindsdb from PyPi instead of installing it from the fork.
For Huge repos that cannot be ingested by octo currently, we can add a feature to filter out directories and remove the ones that are of no use. The command will look something like
octo init mindsdb/mindsdb/docs stagingThe above command will only include the docs folder of mindsdb in the knowledge source. Enabling to filter out directories accordingly.
Add a log command which logs answers to previous questions asked by the user. The command will look something like this.
octo log
Tech Stacks
Useful Links
Conclusion
It was a great and hustling journey of building Octo, we came across many different challenges but at last, we were able to develop a product that had more features than we thought before starting this project.
We would like to present a vote of thanks to MindsDB and Hashnode for creating this amazing Hackathon.
Hope you like our project and article, If you encounter any issues anywhere.
Please do let us know in the comments or you can contact Pranav Prajapati and Vedant Agrawal maintainers of octo.
Subscribe to my newsletter
Read articles from Pranav Prajapati directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pranav Prajapati
Pranav Prajapati
Machine learning and Data Science | Open Source contributor | Python Developer