Decentralized Compute: Why It's Important Now More Than Ever
 Spheron Network
Spheron Network
According to Statista latest estimates, 328.77 million terabytes of data are created each day. (“Created” includes data that is newly generated, captured, copied, or consumed). In zettabytes, that equates to 120 zettabytes in 2023, 10 zettabytes per month, 2.31 zettabytes per week, or 0.33 zettabytes daily. It is expected to increase by over 150% in 2025, hitting 181 zettabytes.
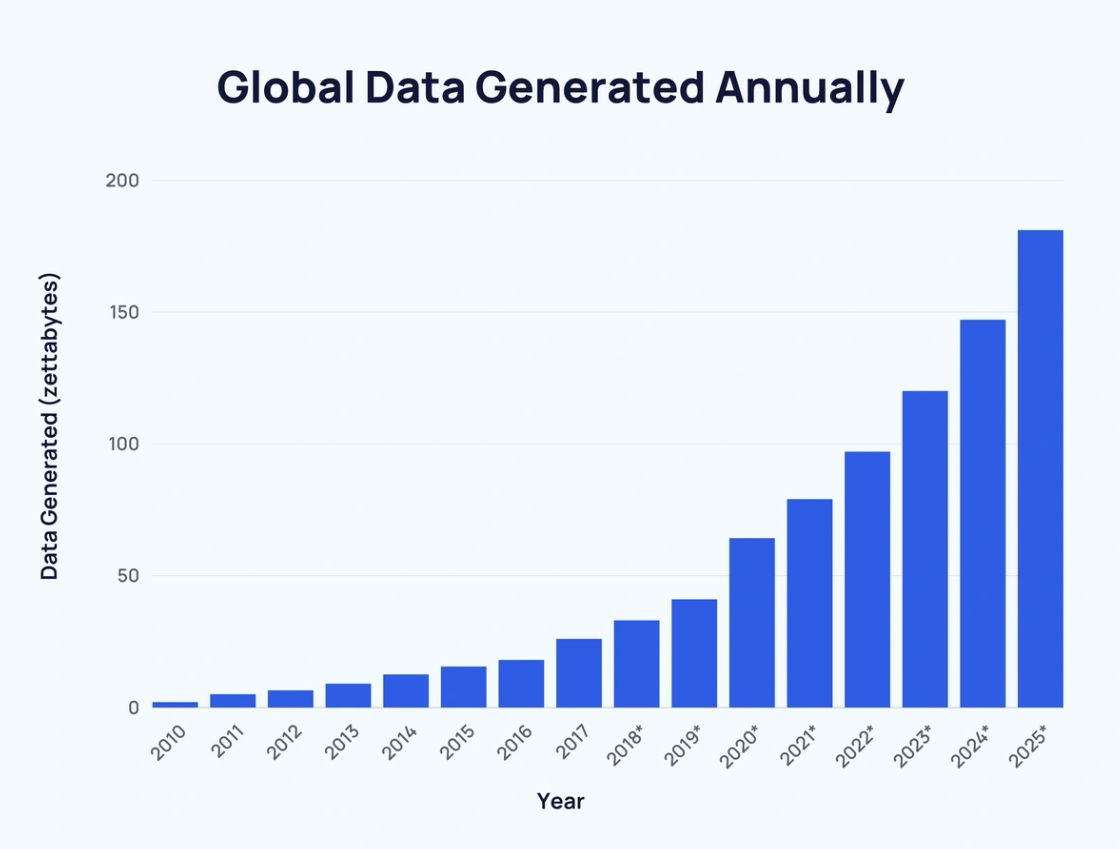
Key Drivers of Data Growth:
The Internet of Things (IoT): Billions of connected devices, from smart homes to wearables, are continuously collecting and transmitting data, fueling the data deluge.
Artificial Intelligence (AI): AI algorithms require massive amounts of data to train and operate effectively, further contributing to storage demands.
Cloud Computing: The shift towards cloud-based applications and services means more data is stored remotely than personal devices.
Streaming Services: The popularity of music, video, and gaming platforms generates vast amounts of data as users consume and create content.
The ever-expanding world of data presents significant challenges that we face today.
Capacity: Accommodating the ever-increasing volume of data requires constant innovation and investment in storage solutions. Traditional methods like hard drives need help with scalability and energy efficiency, necessitating exploring alternatives like cloud storage, solid-state drives, and DNA storage.
Cybersecurity Threats: As data becomes more valuable and produced in high amounts, it becomes a prime target for cyberattacks.
Moving data is slow and expensive. Moving data is a critical task for many businesses, but it can be slow and expensive due to several reasons. Here are some key points to consider:
Associated Costs with Data Travel: When moving data to a new location, there are costs associated with certain types of travel. For instance, moving data to Amazon Web Services (AWS) or between different AWS storage offerings incurs costs. This is also true if data needs to be transferred across multiple AWS availability zones or regions.
Increasing Data Accumulation: As the number of internet-connected devices rises, so does the data they gather. Companies charge migration fees and specific rates based on how much storage space a client requires. As a service collects and stores more information, these rates increase.
Migration Roadblocks: Challenges encountered during data migration can increase the expenses of moving the data to its new location. For example, dependency bottlenecks could pose expensive problems if companies don’t perform complete application assessments.
According to recent studies, a significant portion of data collected by companies goes unutilized. A report by Towards Data Science published in 2023 indicates that as much as 68% of all data gathered by businesses remains unused. Similarly, the Data Waste Index 2023 by NetApp found that 41% of data in the United Kingdom falls into this category, resulting in an estimated annual cost of £3.7 billion to the private sector. These findings suggest that many organizations struggle to manage and utilize their data resources effectively because of poor network growth, expensive data processing, and regulatory constraints.
To address this issue, the Compute-Over-Data (CoD) paradigm advocates for performing computations near the location of the data, thereby reducing the need for data transfer and enabling faster processing speeds and lower network bandwidth requirements. CoD platforms such as Spheron Network aim to make this approach more accessible by allowing compute resources to be moved closer to the data storage locations, minimizing the need for data transport and maximizing processing efficiency.
The Current State of Data Processing
Organizations have adopted one of three primary strategies in response to the complex challenges of data processing, each with its drawbacks.
1. Relying on Centralized Systems
Many enterprises rely on centralized systems, such as compute frameworks like Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, and Ray, to process large amounts of data. While these systems are effective in some respects, they struggle to address issues related to network inconsistencies and data mobility regulations, resulting in significant financial penalties for data breaches.
2. Custom Orchestration Systems
Another approach involves developing tailored orchestration systems designed to meet specific organizational needs. Although this method offers greater control and flexibility, it requires a high degree of technical expertise and places a heavy burden on individual developers to maintain and operate the system, increasing the risk of failure.
3. Ignoring the Problem
Perhaps shockingly, many organizations opt to do something with their data, especially when faced with the prohibitive costs of processing and storing vast amounts of information. For instance, a single city might generate multiple petabytes of data daily from CCTV recordings yet need more resources or infrastructure to efficiently manage and analyze this data, leaving it untouched and underutilized.
Building Truly Decentralized Compute
The world is rapidly moving towards a digital era, and computing resources are increasingly centralized. This centralization has led to concerns about data privacy, security, and the potential for abuse of power by large corporations. To address these issues, there is a growing need for truly decentralized compute solutions that are secure, transparent, and resilient. Here we will explore two possible solutions for building decentralized compute systems: (1) building on top of open-source compute-over-data platforms and (2) building on top of decentralized data protocols.
Solution 1: Utilizing Open-Source Compute-Over-Data Platforms to Create Resilient Decentralized Compute Systems
Open-source compute-over-data platforms, such as Apache Beam and TensorFlow, have gained popularity in recent years due to their ability to process large amounts of data efficiently and at scale. These platforms allow developers to write code that can be executed across multiple machines, making them ideal for distributed computing tasks. By leveraging these platforms, it is possible to build decentralized compute systems that are highly scalable and fault-tolerant.
Benefits:
Scalability: Open-source compute-over-data platforms are designed to handle large volumes of data and can scale horizontally to meet the needs of growing datasets.
Fault tolerance: These platforms are built to handle failures and can continue processing even if one or more nodes fail.
Cost-effective: By utilizing commodity hardware, open-source compute-over-data platforms can reduce costs compared to traditional cloud-based solutions.
Solution 2: Utilizing Decentralized Data Protocols
Decentralized data protocols, such as InterPlanetary File Systems (IPFS) and Distributed Hash Tables (DHT), offer a unique opportunity to create decentralized computing systems that are secure and resilient to censorship. Using these protocols makes it possible to store and process data in a decentralized manner, ensuring that no single entity controls the data or the computation.
Benefits:
Decentralization: Decentralized data protocols ensure that data is stored and processed across a network of peers, eliminating any central point of control or failure.
Security: Data is encrypted and tamper-proof, providing strong guarantees against unauthorized access or manipulation.
Censorship resistance: Decentralized data protocols make it difficult for anyone to suppress or manipulate information.
Decentralization: Maximizing Choices
Deploying on decentralized protocols like the Filecoin network or IPFS opens up a multitude of possibilities for clients. These clients can access hundreds or even thousands of machines spread across different geographical locations within the same network. They operate under the same protocol rules as the rest of the network. Spheron Network compute makes it easy for developers and organizations to deploy their containers, data, or nodes easily in a few simple clicks.
Spheron provides a diverse array of computing options to accommodate various user requirements, featuring cutting-edge GPUs such as Nvidia 1660, Nvidia A100, Nvidia T4, Nvidia V100, Nvidia 3090, and instances equipped with up to 64GB RAM and 64 CPU cores. Additionally, Spheron's Marketplace offers an extensive selection of databases like Redis, MongoDB, PostgreSQL, and MySQL, along with specialized nodes for Shardeum Testnet Validator, DeSo Node, AR.IO, IPFS, ZkSync, and more. The platform also includes useful tools like Grafana, TensorFlow CPU, Visual Studio Code Server, and even Minecraft, all designed to handle anything from modest workloads to demanding applications.
CPU-Based Instances: For general-purpose computing, Spheron allows users to run containers on CPU-based instances. This option is perfect for a wide range of workloads, from web hosting to data analysis.
GPU-Powered Computation: If user applications demand high-performance and parallel processing, Spheron Network provides a GPU-powered computation boost. This feature is indispensable for tasks like machine learning, deep learning, and scientific simulations.
Why Decentralized Compute Matters
No Central Authority: There is no central authority in a decentralized network. This means each user can make their own decisions and control their own data, enhancing security and privacy.
Greater Expansion: Decentralized systems can scale faster and more efficiently than centralized ones because the capacity of a single server or database does not limit them. As the network grows, so does its processing power and storage capacity.
Expression, Freedom, and Inclusivity: Anyone with an internet connection can participate in a decentralized system, regardless of their geographical location or financial status. This democratizes access to services and opportunities, fostering greater inclusion and equality. Users can express their ideas or share data freely with less censorship in a decentralized network.
Transparency: Decentralized systems operate transparently, with all transactions and interactions recorded publicly on a blockchain or similar ledger. This ensures accountability and trustworthiness, as participants can verify the system's integrity.
Resource Optimization and Greater Output: Decentralization allows users to share their burdens, leading to more efficient use of resources. Since all users have equal authority, they work more efficiently to enhance maximum productivity.
Fault tolerance: With no central control point, decentralized systems can continue functioning even if one or more nodes fail or go offline. This makes them ideal for applications where high availability is critical.
Security: Centralized systems are vulnerable to single points of failure, making them attractive targets for attackers. Decentralized networks are highly secured. Even if hackers attempt to compromise multiple servers, it's not feasible due to the absence of a central server.
Community-driven Development: Decentralized networks can foster a community of developers, leading to rapid growth and improvement of the system.
Control Over Data: Users have control over their data in a decentralized network, reducing reliance on third-party platforms and mitigating risks associated with data breaches.
Open Development Platforms: Decentralized systems often promote open development platforms, allowing for less censorship and more innovation.
Interoperability: Decentralized systems can integrate with other decentralized systems, creating a seamless web of interconnected services that can communicate and exchange value without intermediaries.
Economic benefits: By eliminating intermediaries and reducing operational costs, decentralized systems can provide lower fees and higher efficiency for transactions and computations. This can lead to significant economic savings and increased productivity.
Decentralization aligns with human values: Decentralization resonates with principles like individuality, autonomy, and fairness, which are fundamental human values. It enables people to have greater control over their digital lives, data, and assets, aligning technology with humanitarian ideals.
Conclusion
In conclusion, the exponential growth of data generation, driven by factors such as IoT, AI, cloud computing, and streaming services, poses significant challenges for individuals and businesses. The need for more efficient and secure ways to store, process, and move data is urgent. Decentralized compute solutions, such as those offered by Spheron Network, offer a promising alternative to centralized systems. As we grapple with the ever-expanding world of data, it is clear that the future lies in decentralized computing. This approach offers a more secure, efficient, and empowering way to harness the power of data, ultimately benefiting all stakeholders involved.
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute