Fun with Avatars: Optimizing the service for cost-effectiveness | Part. 3
 Lewis Munyi
Lewis Munyi
This article series is split into four parts:
Part 1: Involves creating the project, establishing the API, and developing the avatar generation module.
Part 2: Focuses on containerizing the application for development and deployment.
Part 3: Delves into optimizing the service for cost-effectiveness.
Part 4: Explores the integration of the service into real-life projects.
Intro
In Part 1 of this series, we established the API and avatar generation module. During this phase, we configured our application to utilize FastAPI, enabling the API to produce avatars based on supplied prompts. While this addressed the immediate need, it introduced a subsequent challenge. With each incoming request, our API initiated a new request to OpenAI's DALL-E service. Given that this service is not free, our approach proved cost-ineffective, especially in scenarios where users might share similar facial features, leading to redundant requests.
In this article, our focus shifts to implementing a caching mechanism for previous requests. This enhancement aims to prevent redundant calls to DALL-E by storing and reusing previous responses. If the API identifies an existing request, it retrieves and returns the cached response; otherwise, it initiates a request to DALL-E, captures the response, and caches it for future optimization. The following image provides an overview of the implementation covered in this article.
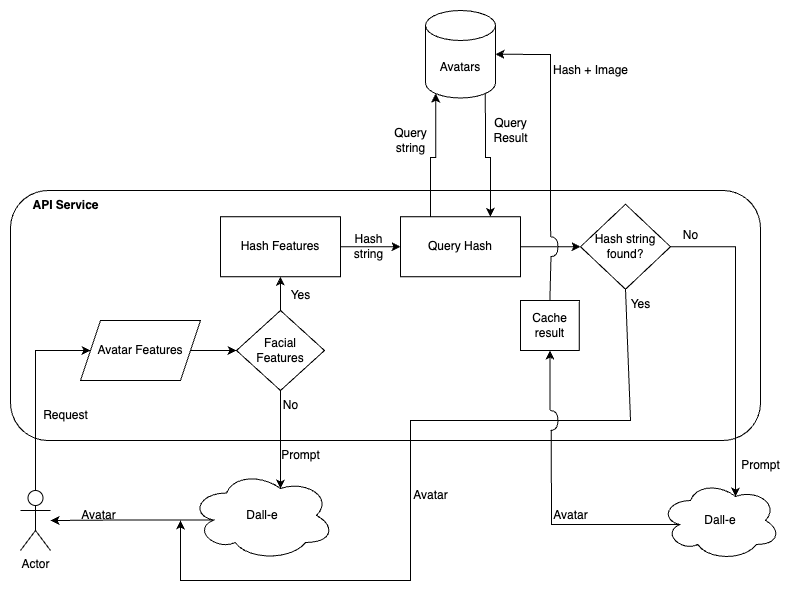
Optimizing the service
Project Re-organization
To make this project more reader-friendly We will reorganize it before making any changes.
Start by renaming the
avatars_as_a_service/serializers/Avatar.pyfile toavatars_as_a_service/serializers/schemas.pyand move it to theavatars_as_a_service/directory. Run the following:cp avatars_as_a_service/serializers/Avatar.py avatars_as_a_service/schemas.py && rm -r avatars_as_a_service/serializers/Create an
enumsdirectory inavatars_as_a_service/and move theavatars_as_a_service/serializers/AvatarFeatures.pyto it.mkdir avatars_as_a_service/enums && cp avatars_as_a_service/serializers/AvatarFeatures.py avatars_as_a_service/enums/Delete the
avatars_as_a_service/serializers/directoryrm -r avatars_as_a_service/serializersUpdate the
main.pyfile importsfrom fastapi import FastAPI from avatars_as_a_service.schemas import AvatarRequest, AvatarResponseUpdate the
schemas.pyimports:from avatars_as_a_service.enums.AvatarFeatures import Mood, HeadShape, EyeColor, SkinTone, SmileType, NoseTypeThe project directory should look like this:
. ├── Dockerfile ├── LICENSE ├── README.md ├── README.rst ├── avatars_as_a_service │ ├── __init__.py │ ├── enums │ │ └── AvatarFeatures.py │ └── schemas.py ├── development.Dockerfile ├── main.py ├── poetry.lock ├── pyproject.toml └── tests ├── __init__.py └── test_avatars_as_a_service.py
Database design
The primary avatars table will encompass all user-selected features and the images retrieved from DALL-E. Its structure will resemble the following:
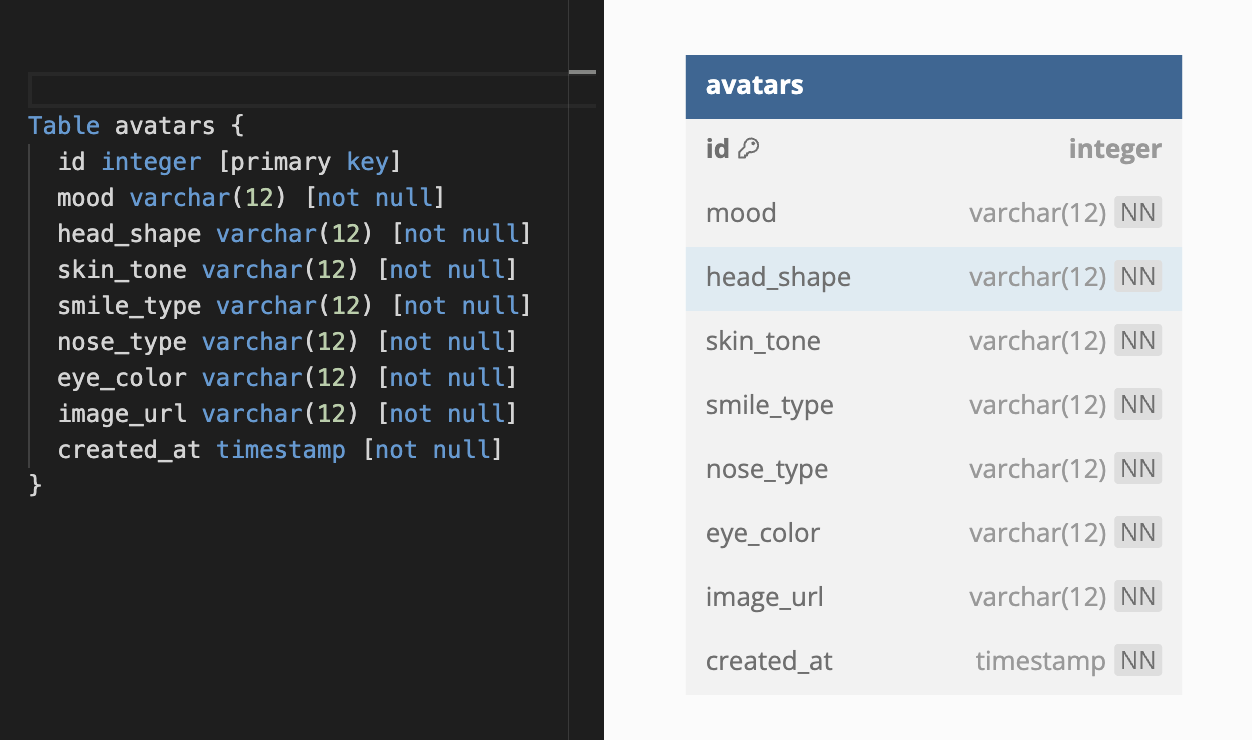
While the current table serves its purpose adequately, there is room for further optimization.
Let's calculate the combinations of our AvatarFeatures to estimate the number of rows expected in our table:
Mood: 2 options (FUN or OFFICIAL)
HeadShape: 5 options (OVAL, ROUND, SQUARE, HEART, TRIANGULAR)
SkinTone: 3 options (FAIR, MEDIUM, DARK)
SmileType: 6 options (WIDE, FULL, CLOSED_LIP, OPEN_LIP, TEETH_BARING, SMIRK)
NoseType: 6 options (STRAIGHT, ROMAN, BUTTON, SNUB, WIDE, NARROW)
EyeColor: 6 options (BROWN, BLUE, AMBER, HAZEL, GREEN, GREY)
Therefore, we can have 5400 (2 × 5 × 3 × 6 × 6 × 6) combinations for the provided features, resulting in a maximum of 5400 rows.
Data type space consumption for SQL:
INT: 4 bytes
VARCHAR: Length of the stored data + 2 bytes = 12 + 2 = 14 bytes
TIMESTAMP: 8 bytes
TEXT: Length of the stored data + 2 bytes = 500 (average) + 2 = 502 bytes
In our current design, a single row consumes (4 bytes × 1) + (14 bytes × 7) + (8 bytes × 1) + (502 bytes × 1) = 612 bytes. The entire table will be roughly 612 bytes × 5400 rows = 3,304,800 bytes (approximately 3225 KB or 3.15 MB).
Enhanced Database Design
We could further optimize this design by hashing the values for the AvatarFeatures class and storing the unique hash string representing the features against the image URL. This optimization brings several benefits, including:
Reduced query times due to a smaller dataset
Flexibility to increase features in the
Avatarclass without modifying theavatarstable structure
The final design will take this form:
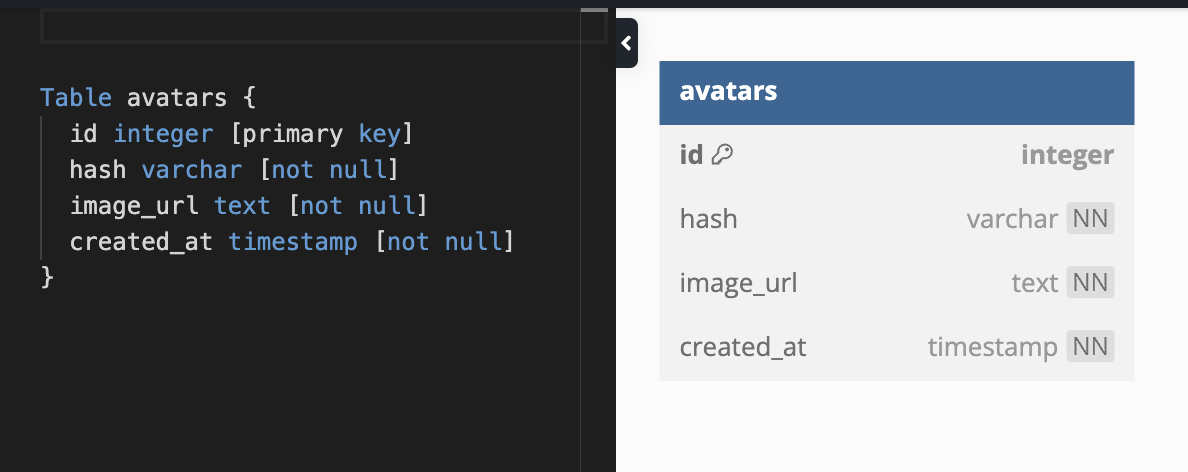
This refined design will only consume (4 × 1) + (14 × 1) + (8 × 1) + (502 × 1) = 528 bytes per row, totalling 528 bytes × 5400 rows = 2,851,200 bytes (2782 KB or 2.718 MB) across the entire table. This represents a 13.7% improvement, with further enhancements expected as the number of features increases.
For this article, I will employ an SQLite database hosted within the container to cache our images. You can seamlessly replace the database connection string with a custom one suitable for PostgreSQL, MySQL, SQLite, Oracle, etc. This flexibility arises from two key considerations:
Size Efficiency:
- Our bundled SQLite database imposes minimal impact on container size (4MB max).
User Flexibility:
- Users can provide database connection strings for their external custom databases.
Create Database
Install python dependencies
Don't forget to install SQLAlchemy and other needed dependencies
poetry add sqlalchemy pymysql cryptography psycopg2
Create connection file
Create a file named connection.py in a avatars_as_a_service/database/ directory.
mkdir avatars_as_a_service/database && touch avatars_as_a_service/database/connection.py
Add the following code to it
import os
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
if db_string := os.getenv('DB_STRING'):
if 'sqlite' in db_string:
engine = create_engine(db_string, connect_args={"check_same_thread": False})
else:
engine = create_engine(db_string)
else: # Default to sqlite if there is no DB string supplied
db_string = "sqlite:///./avatars_as_a_service/database/fun-avatars.sqlite.db"
engine = create_engine(db_string, connect_args={"check_same_thread": False})
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
async def init_db(): # checkfirst option to make sure that tables are only created if they don't exist
Base.metadata.create_all(bind=engine, checkfirst=True)
def get_db() -> Session:
db: Session = SessionLocal()
try:
yield db
finally:
db.close()
The code above will check for a DB_STRING environment variable on app startup. If found it will attempt to connect to the supplied DB URL. It will create a default SQLite db if no DB_STRING is found.
The init_db() function will attempt to create the avatar table with its appropriate columns if no table is found so ensure that the database user provided has table creation rights, or that the table exists beforehand.
The get_db() function will yield an initialized database session
Create SQL Alchemy models
Create a avatars_as_a_service/models.py file with the following code:
from datetime import datetime
from sqlalchemy import Integer, DateTime, Column, String, Text
from sqlalchemy.orm import DeclarativeBase, mapped_column, Mapped
from sqlalchemy.ext.declarative import declarative_base
from avatars_as_a_service.database.connection import Base
class Avatar(Base):
__tablename__ = "avatar"
id = Column(Integer, primary_key=True, autoincrement=True, index=True)
created_at = Column(DateTime, default=datetime.now(), nullable=False)
image_hash = Column(String(30), nullable=False)
image_url = Column(Text, nullable=False)
Hashing methods and properties
Create the hashing method of the Avatar schema
def hash_avatar(self) -> str:
if self.description:
return ''
features = f'{self.head_shape}+{self.eye_color}+{self.skin_tone}+{self.glasses}+{self.smile_type}+{self.nose_type}+{self.mood}'
return str(hash(features))
Update the AvatarResult schema to include the image_hash field
class AvatarResult(BaseModel):
image_hash: str = None
image_url: str = None
Update the dall_e_search() method of the Avatar schema to populate the hash field:
def dall_e_search(self):
try:
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'), )
response = client.images.generate(
model="dall-e-2",
prompt=self.generate_prompt(),
size="256x256",
quality="standard",
n=1,
)
res = AvatarResult()
res.image_url = response.data[0].url
res.image_hash = self.hash_avatar()
return res
except Exception as e:
print(str(e))
Update Request/Response classes
In the avatars_as_a_service/schemas.py file update the AvatarRequest class to include the cache flag.
class AvatarRequest(BaseModel):
properties: Avatar
disable_cache: bool = False # Default to querying the cache before OpenAI
Add a cache_hit flag to the AvatarResponse schema
class AvatarResponse(BaseModel):
data: AvatarResult = None
cache_hit: bool = False # Has the resulkt been returned from the cache
prompt: str = None
Create search methods
Create a file avatars_as_a_service/search.py file with the following code and functions:
from typing import Any
from sqlalchemy.orm import Session
from avatars_as_a_service.models import Avatar
from avatars_as_a_service.schemas import Avatar as AvatarSchema, AvatarResult, AvatarRequest, AvatarResponse
Write to cache function
# Commit the OpenAI result to the cache
def write_to_cache(result: AvatarResult, db: Session) -> bool:
try:
avatar_model = Avatar(**dict(result))
db.add(avatar_model)
db.commit()
except Exception as e:
raise RuntimeError("An unexpected DB error occurred: " + str(e))
Search DALL-E function
This is the function that will request Dall-e for an avatar given a prompt/features
def search_dall_e(avatar: AvatarSchema, cache=True) -> AvatarResult:
result = avatar.dall_e_search()
if avatar.description is not None: # Directly search for description without caching
return result
if cache:
try:
write_to_cache(result)
except:
print("Unable to cache result")
pass
return result
Search Cache function
This function attempts to find a cached Avatar and return it
# Return the query result or None
def search_cache(avatar: AvatarSchema, db: Session, skip: int = 0, limit: int = 100) -> Any:
return db.query(Avatar).filter(Avatar.image_hash == avatar.hash_avatar()).first()
Main search function
This function takes an AvatarRequest object and returns a AvatarResponse object.
def avatar_search(request: AvatarRequest, db: Session) -> AvatarResponse:
search_result: AvatarResult
cache_hit: bool = False
prompt: str = request.properties.generate_prompt()
if request.disable_cache: # Search dall-e and don't cache the result
search_result: AvatarResult = search_dall_e(avatar=request.properties, db=db, cache=False)
else: # Search cache
query_result = search_cache(avatar=request.properties, db=db)
if query_result is None: # Cache miss: Browse image and attempt to cache the result
search_result: AvatarResult = search_dall_e(avatar=request.properties, db=db, cache=True)
else: # Cache hit
cache_hit: bool = True
search_result = AvatarResult()
search_result.image_hash = query_result.image_hash
search_result.image_url = query_result.image_url
result = AvatarResponse()
result.data = search_result
result.cache_hit = cache_hit
result.prompt = prompt
return result
Update the main route file
import os
from fastapi import FastAPI, Depends
from avatars_as_a_service.database.connection import get_db, init_db
from avatars_as_a_service.search import avatar_search
from avatars_as_a_service.schemas import AvatarRequest, AvatarResponse
from sqlalchemy.orm import Session
app = FastAPI()
@app.on_event("startup")
async def startup_event():
await init_db()
@app.post("/query")
def search(req: AvatarRequest, db: Session = Depends(get_db)) -> AvatarResponse:
return avatar_search(request=req, db=db)
The app directory now looks like this:
.
├── Dockerfile
├── LICENSE
├── README.md
├── README.rst
├── avatars_as_a_service
│ ├── __init__.py
│ ├── database
│ │ └── connection.py
│ ├── enums
│ │ ├── AvatarFeatures.py
│ ├── models.py
│ ├── schemas.py
│ └── search.py
├── development.Dockerfile
├── docker-compose.yml
├── main.py
├── poetry.lock
├── pyproject.toml
└── tests
├── __init__.py
├── create-testing-database.sql
└── test_avatars_as_a_service.py
The app request flow goes somewhat like this:
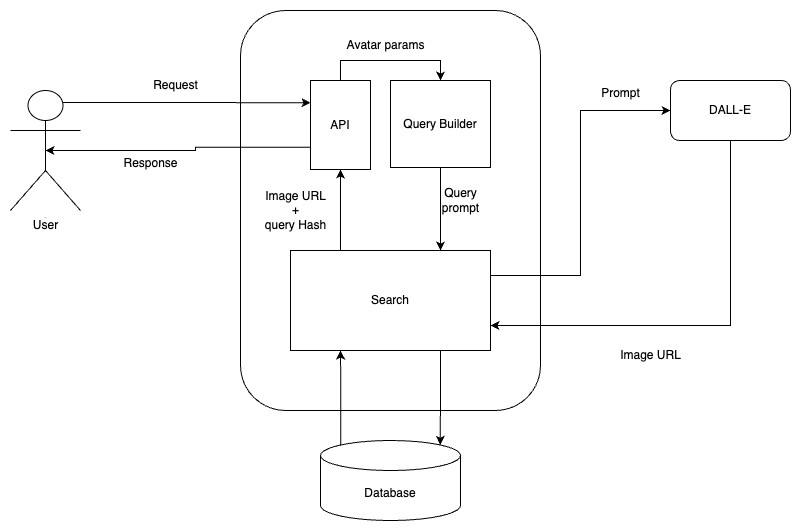
App testing
Make sure to pass a DB_STRING env to your container when starting it up or add it to the .env file if you are running it from docker-compose
> export DB_STRING='mysql+pymysql://user:password@host:port/db_name?[params]'
> docker run -p 8000:8000 -e OPENAI_API_KEY -e DB_STRING -v .:/api/ avatars-as-a-service:dev
- Sending a request with a custom description sends the request directly to OpenAI.
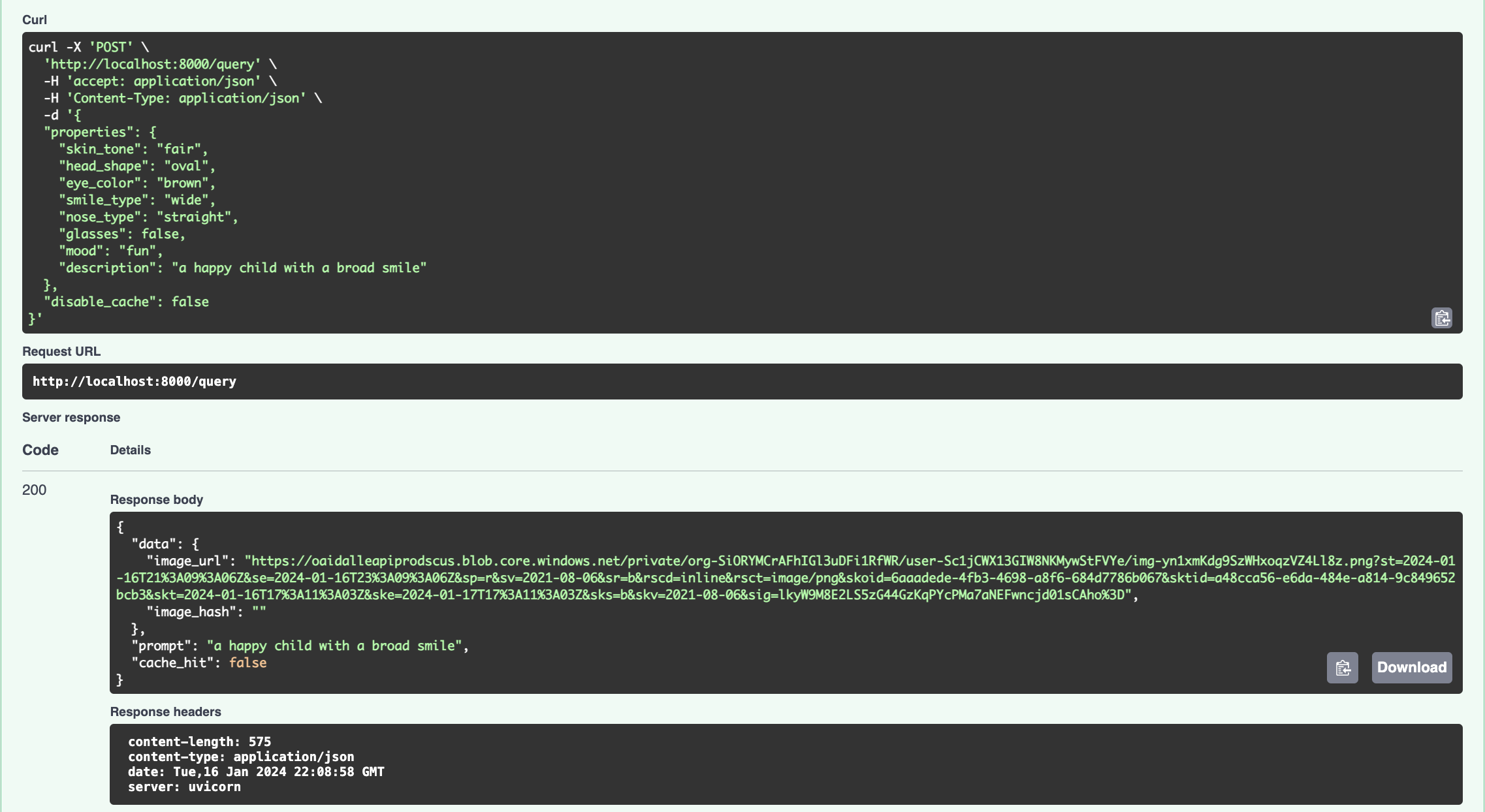
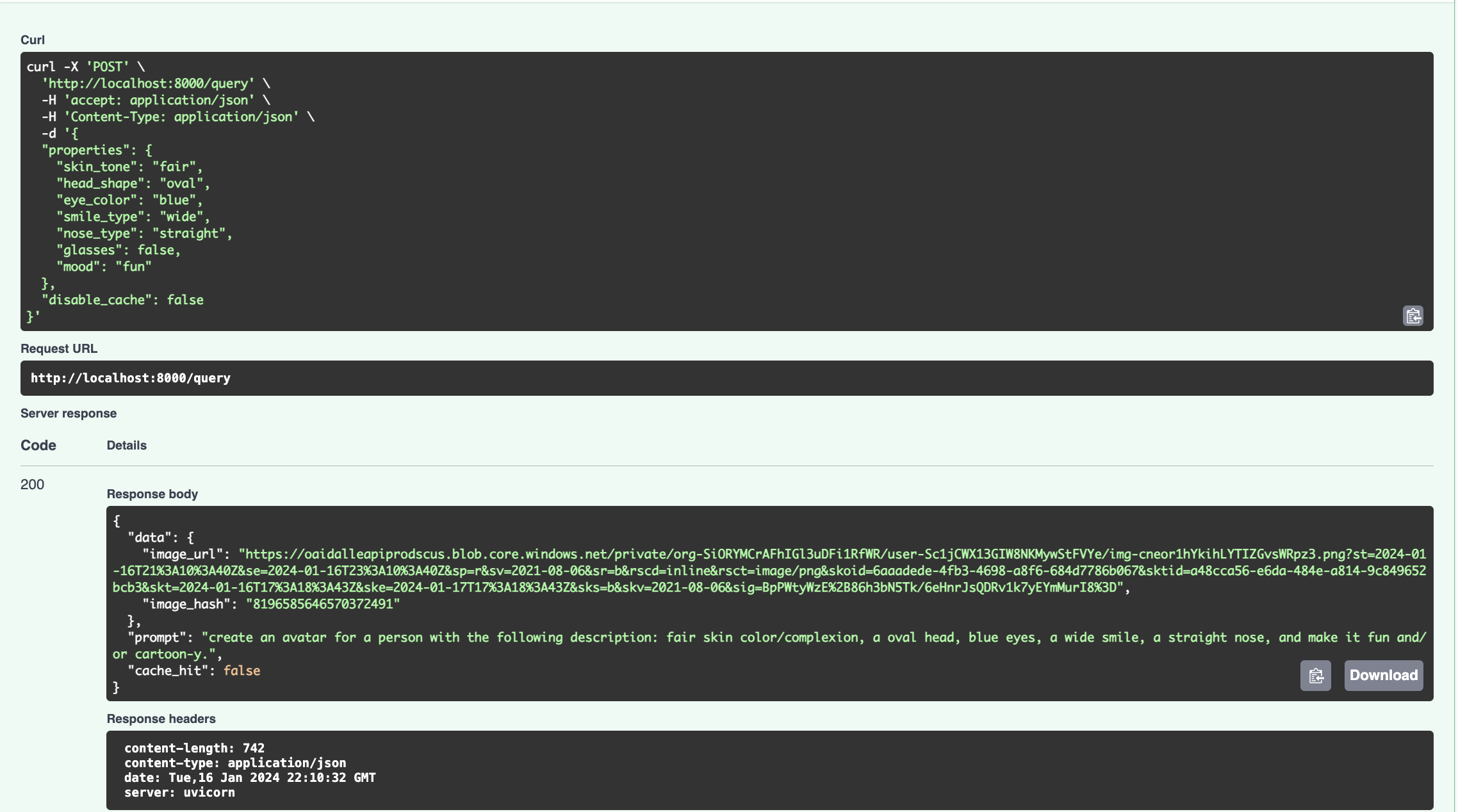
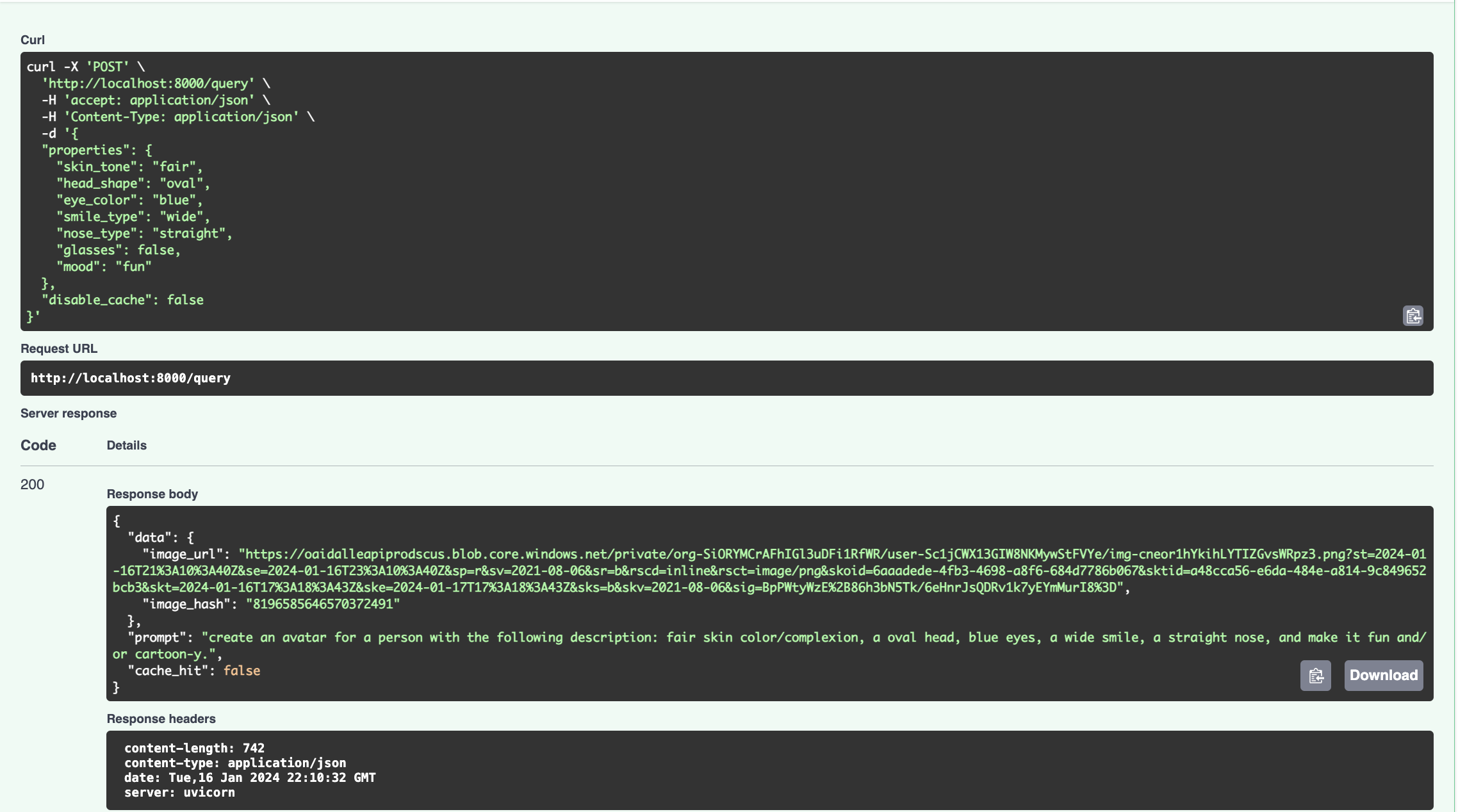
- Making a first-time request with the cache flag set to
truewill cause it to search OpenAI then cache persist the result to the database. Similar subsequent results will not query OpenAI but return the cached result instead. Subsequent requests have much lower response latency.
Requests made with the
disable_cacheset to true will return results directly from OpenAI.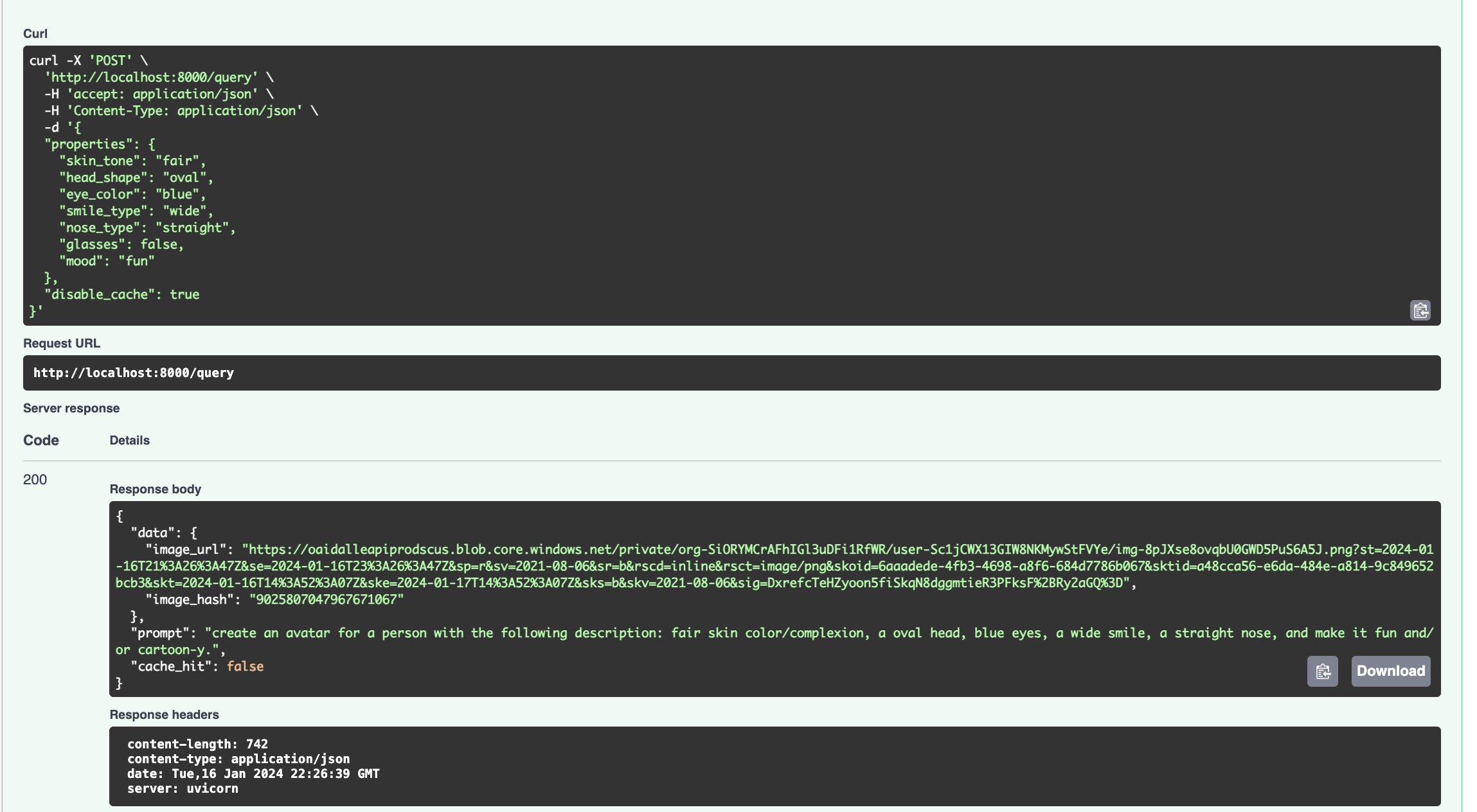
Conclusion
In conclusion, we delved into the optimization of our Avatars as a Service project by implementing a caching mechanism for previous requests. Recognizing the cost-inefficiency of redundant calls to OpenAI's DALL-E service, we introduced a streamlined approach. This enhancement involves storing and reusing previous responses, significantly reducing the load on external services. The reorganization of the project structure, optimization of the database design, and the implementation of an SQLite database for caching contribute to a more efficient and scalable solution. By incorporating these improvements, we not only enhance the performance of our avatar generation service but also pave the way for future expansions and feature additions. All the code for this project can be found in this repo. Stay tuned for the next instalment in this series where we will incorporate this project into a real-life project.
Cheers!
Subscribe to my newsletter
Read articles from Lewis Munyi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by