x86 core architecture
 clockwork
clockwork
.noise
hello_friend,
I hope y'all doing well now that 2023 is finally over for good. In this article I want to introduce you to some of the basics of the x86 architecture. This will serve as a reference for me too, so maybe this article will keep growing on in the future.
I've decided to let the new year come online a little bit more quiet this time, in contrast to all the bonobos that still blow up tons and tons of firecrackers each year, so here is something that sounds [ A LOT ] better than black-powder explosions:
Data Types
Let's start by going over the fundamental data types. All data types fall somewhere in between 8 bits and 256 bits, making the largest one, you guessed it, 32 byte long. Let's start by looking at all available types:
| Data Type | Length (bit) | Typical use |
| Byte | 8 | Characters, integers, BCD value |
| Word | 16 | Characters, intergers |
| Doubleword | 32 | integers, single-precision floats |
| Quadword | 64 | integers, double-precision floats, packed integers |
| Quintword | 80 | double-extended-precision floats, packed BCD |
| Double Quadword | 128 | packed integers, packed floats |
| Quad Quadword | 256 | packed integers, packed floats |
We can see that most data types' sizes are powers of 2, with quintwords being a little bit of a snowflake, using 5 times the size of a word. Generally spoken, the doubleword is the data type you will encounter most of the time in x86. This is due to the fact that most integers are 32 bit wide and pointers use this data type, too.
By the way, the safe C way of ensuring a specific data type has a given length is the usage of a defined data type like uint32_t , and will come in handy when operating with protocols that enforce specific data types, f.e. 16 bit integer (uint16_t). It also makes your code portable, since most standard types' sizes are dependent on the compiler and architecture, but such a fixed width integer type will have the same size on every architecture.
In general, compilers will align data types in memory by placing them at a memory location that is evenly dividable by it's size in bytes, so a doubleword f.e. is properly aligned when it's placed at a memory location that is evenly divisible by 4. This means that we might encounter 00s in between our operations, where data types where aligned to fit this specific. Although not strictly required, this behavior will sometimes even be hardware-enforced, and ultimately has the purpose of giving the processor a performance boost during execution.
Numerical, Packed and other data types
There are several specialized data types representing numbers, arrays or strings among others. All these data types are represented using one of the fundamental data types we already looked into, f.e. a char is represented by a byte. There are special instructions for calculations using these numerical data types, in case you wonder why we even need these when the fundamental data types would be enough.
Numerical data types are 8, 16, 32 and 64 bit wide. As I already mentioned, an integer is 32 bit long and thus represented by a doubleword, which is by far the most common used data type ( it's also used for pointers and function arguments, that's probably why ). Beside that, one of the oldest expansion for the x86 architecture is the x87 floating point unit.
brief history of x87 fpu
We will look into fpu operations in future articles, for now just remember these exist and are represented by a doubleword (for float), quadword (for double) and a quintword (for long double).

Packed data types are representations of smaller data types stuffed into a bigger one. For example, a 32 bit wide packed data type could be used to hold 4 bytes. Packed data types are mainly used for SIMD instructions ( single instruction, multiple data ). SIMD is a form of hardware-accelerated true parallel processing, in contrast to threads, which are time-slicing single tasks. The x86 architecture was modded with a series of SIMD enhancements over the years, like MMX or AVX2.
Other data types consist of miscellaneous types used for a variety of tasks of which the most common probably is holding bytes or words in a string. Think of a long chain of memory containing character values. These values must be contained in a single block of memory, which explains why working with arrays requires careful memory management to not go out of bounds. For this reason, many languages have implemented higher-level objects representing these data types, like Java's String, Hashmap or ArrayList.
There are other examples of miscellaneous data types, like bit fields for masking, binary coded decimals ( bcd ) among others, but these are not that important for now, so let's just move on.
Internal architecture
Let's talk a little bit about registers now. Registers are memory fields directly on the CPU, thus making them the fastest overall memory inside your machine. Below these registers is L1-L3 cache memory, which is somewhat slower but much bigger. As a comparison, reading the value from a register requires 1-2 CPU cycles, while reading from L1 cache is at least 4 cycles.
Lets look at the 8086, a now ancient 16 bit x86 platform.
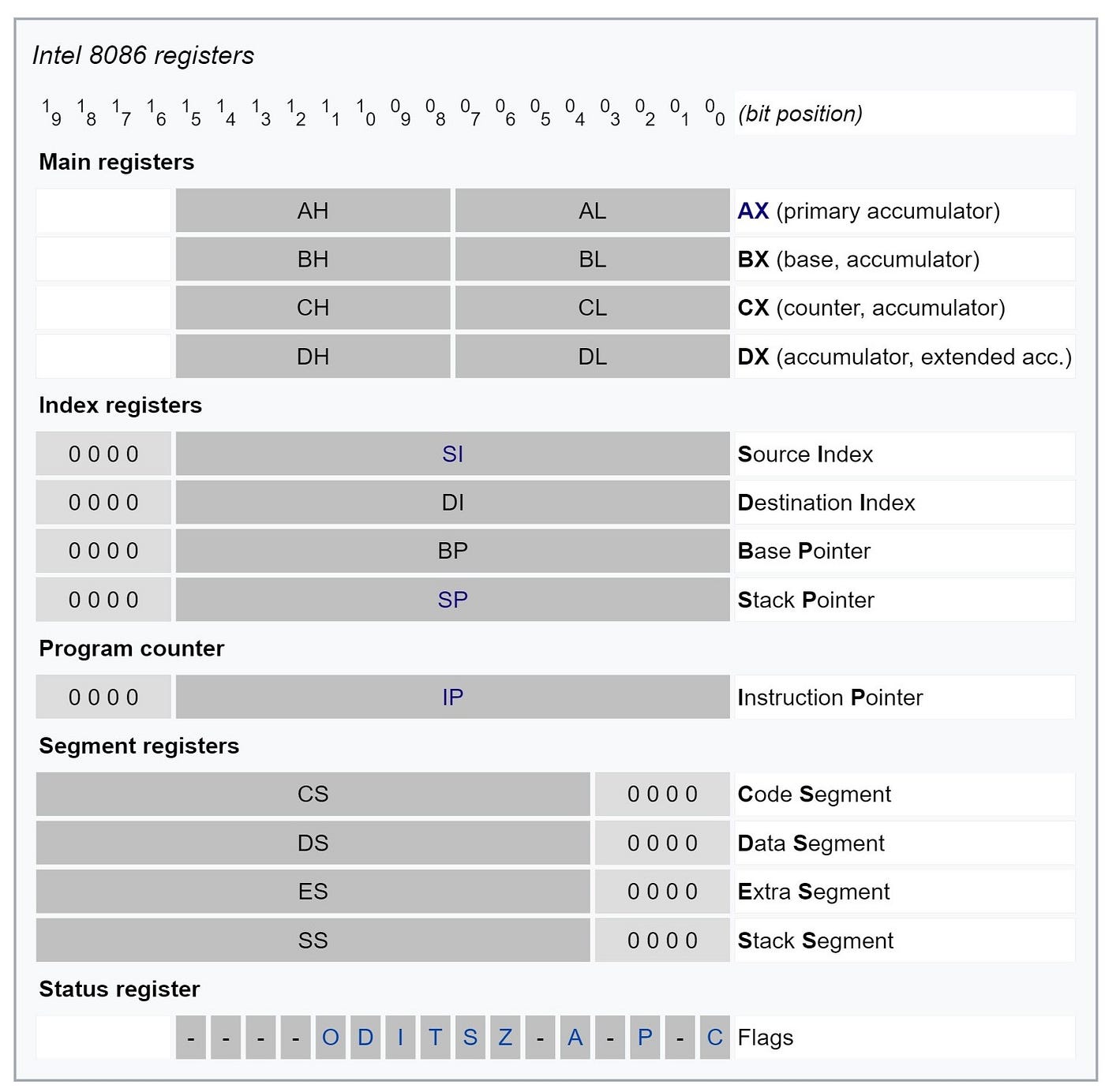
This is the most basic setup for an x86 architecture available. Before we look into 32 bit, or even 64 bit architecture, we need to understand this image first.
Main registers are used for most operations. Whenever you calculate something, chances are the result will be dumped inside the AX register. Similar, whenever you loop something, the loop counter will likely be stored inside CX. For now, look at AX. See how it is made up from 2 smaller registers? The first 8 bit are called AL, or A-low, and the second one AH, or A-high. To create this 16 bit register, we simply glue together two 8 bit ones and call it A-Xtended. This means AL will always contain the least-significant bit, which is famously used to decide whether a number is even or odd, while AH will contain the most-significant bit, often used as the sign-bit ( as in, you know, signed integer ). Now that we found out how 16 bit architecture is made up, can you already tell how the 32 bit architecture is made up?
Index registers are primarily used as pointers. Source- and destination-index (SI, DI) often point to memory locations where, unsurprisingly, data is read and written to, often times in string operations. This will become more understandable once we look at our first real coding example. Stack- and base-pointer have a special purpose in programming. The Stack pointer SP always points to the topmost item on the call stack. Whenever we push something there, or call any function, this pointer will be changed. The base pointer serves as kind of an anchor into the stack, so we can address memory from this location. Whenever we call a new function in our program, a new stack frame is pushed onto the stack, with the first values (which are higher addresses) being the arguments we pass to the function, after which the return address is stored. After that, the base pointer is placed and can be accessed. After the stack pointer, any local variables from inside the function are pushed, with the stack pointer updated after each operation, accordingly. Look at the picture to get a better understanding of this:
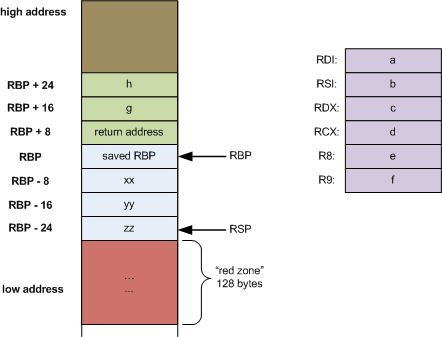
Here, our base pointer is called RBP, because we are in a 64 bit context and thus registers are prefixed with an "R", with memory fields being 8 byte long (8 registers glued together). If we want to access the second function argument (g in the image), we could write something like
mov rax, [rbp+16] ; move [ the content ] of g into rax
As you can see, the base pointer allows us to access memory in the stack frame without first doing complex calculations to find out where in memory the exact data is stored. This will be a handy tool when we start writing actual code later.
If you wonder why not just to work with the stack pointer, I already took the time asking these questions.
Program counter refers to a special register which is updated with each new instruction, thus it is also called instruction pointer. It is, however, more complex than a register that just counts up the instructions we already executed. Instead of just counting upwards, the register counts up the location of the next instruction that will be executed in our code. Depending on the length of the actual instruction, the instruction pointer is increased between 1-4 bytes on average, with some instructions having multiple operands and thus getting longer. If you want to look into x86 heuristics, take a look at Peter Kankowski's blog.
Segment registers are special registers which aren't normally manipulated ( or even known ) to the programmer. Here, the core execution unit defines a logical memory model for code execution and data storage. You can look at these as anchors into memory, f.e. the beginning of the stack. However, in protected mode, these registers contain a selector, or index, into a segment descriptor table. These registers and segments are usually handled by the operating system when loading a process, so leave the details of segmentation to the loader. If you want to work with pages of fixed size ( f.e. 4096 bytes ), you might want to come back to these registers.
Control flow
Status register, aka FLAGS, is one of the most important register overall. After almost every operation on the CPU, the status register is updated in some form. If you want to know which flags are available on your specific CPU, take a look into /proc/cpuinfo.
There are many**flags, and this register is ordered differently on each architecture, so let's not go over each one here but instead focus on the zero flag** on a 16 bit machine.
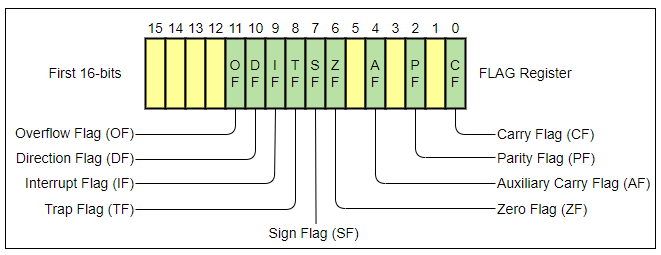
Assume we have a c++ array that represents a string, and we want to know it's size, or in other words count(a_string); Without going into the details of how the compiler will handle and optimize this, we will probably end up with something along these lines:
; Loop to determine the size of the array
count_loop:
cmp byte [esi], 0 ; Check if the current byte is null (end of string)
je end_loop ; If it is null, jump to the end of the loop
inc ecx ; Increment the counter
inc esi ; Move to the next byte in the array
jmp count_loop ; Jump back to the beginning of the loop
I don't want to talk about the symbol count_loop here since this is stuff for another article. The cmp instruction compares 0 against the current symbol in the string and updates the flags register accordingly, to be specific, it sets the zero flag to 1 if we found a null-byte. The je instruction then [ jump if equal ]s to the end_loop symbol (not visible). Interestingly, although a different opcode, a jz [ jump if zero ] would result in the exact same outcome.
We will continue looking into control flow in the next article, since this one is already long enough. Thanks for reading
Subscribe to my newsletter
Read articles from clockwork directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by