Replace withColumn with withColumns to speed up your Spark applications.
 Anees Shaikh
Anees ShaikhDisclaimer - the views and opinions expressed in this blogpost are my own.
Practical takeaways
The .withColumn() function in Spark has been a popular way of adding and manipulating columns. In my experience, it is far more common than adding columns via select. This is also the way that I used to add and manipulate columns. As of Spark 3.3, I would recommend using .withColumns() instead. It scales better with multiple columns and avoids a StackOverflowException. Making the change is also relatively easy.
How did I stumble on this?
Recently, I was tasked with upgrading a series of Spark jobs from Spark 2.4 to Spark 3.3. Whilst tasked with making sure things ran, I also had to carry out other upgrades to make the code run faster. One of the pipelines would take 3+ hours to finish and most of the time, it would just timeout or error out with a StackOverflowException. This particular pipeline was not processing a lot of data, less than 3-4GB and it was over-provisioned to boot. Moreover, the executor metrics showed negligible CPU and memory usage. So, I pulled my sleeves up and got to debugging. To kick things off, this script had minimal logging and thus it was arduous to find out which part of the script it would get stuck at. I added a bunch of print statements(as one does) and added some timers to see how long code would take to execute. I find that this approach is a decent way to identify bottlenecks/slow-downs.
import time
for i in range(0,100):
start_time = time.perf_counter()
# code executable here
end_time = time.perf_counter()
print(f"it took {end_time-start_time} seconds to complete")
# you can modify this to save the time take in a list and then compare how long each iteration took ;)
To my surprise, there was a for-loop that was adding/manipulating roughly 700 columns using .withColumn that took 3 hours to execute. This blew my mind because I had thought that such operations were lazily executed and thus no data was being materialized. Furthermore, the time taken for each subsequent call within the for-loop got longer. This wasn't the first time I had encountered lazy operations taking this long. I had suspected that the Spark DAG for that dataframe had gotten quite long. In such cases, I've tried to use checkpointing(local and non) to truncate the lineage of the DAG. This is an oft-repeated approach and one that has worked well for me in the past(barring the reliability tradeoffs of this approach of course). Upon implementing checkpointing every 5-10 iterations, the job was significantly faster and completed within 15-20 minutes. However, this didn't scale as well when tested with much larger volumes, you'd eventually have to pay the cost of materializing the data and executing the DAG, and could end up eating disk space on the executors. Moreover, I'd still run into timeouts occasionally. While there was potentially a way to manage the space with some spark configuration or hacky heuristic, I tried to go for an alternate approach. One of my colleagues had mentioned that using a select statement instead would've solved the issue. Another colleague mentioned that if I had used spark-sql, it would've yielded better results. I didn't think either approach would've made a difference because I had assumed that a .withColumn call was mapped out to select/spark-sql all the same. Upon doing some more research, I was wrong on both fronts and had found that using .withColumn to add and manipulate this many columns is not recommended at all.

The spark docs had recommended my colleague's approach of using .select.
Existing approaches
In this rabbit-hole, I stumbled upon two more blogs that spoke about this issue. Firstly, we have one of my favourite blogs, waiting for code, by Bartosz Konieczny. He goes in-depth about how this operation may appear relatively harmless but does cause significant harm when used repeatedly. He does propose a viable solution. Secondly, we have my other favourite blog, MungingData, by Matthew Powers. He talks similarly about how this operation hammers the catalyst optimizer and suggests using a function within the quinn package to solve it - definitely a viable solution and that package has some other super useful functions. Well, the solution is now natively supported within Spark 3.3 - .withColumns(). After using .withColumns, the aforementioned code chunk executed within a matter of seconds.
Why bother using .withColumns?
For starters, it is significantly more performant than using .withColumn to add columns. It also requires minimal code-change to use.
# old way of adding columns
columns = ["test_1", "test_2", "test_3"]
for column in columns:
df = df.withColumn(column, lit(None))
# alternatively
df = df.withColumn("test_1", lit(None))\
.withColumn("test_2", lit(None))\
.withColumn("test_3", lit(None))
# in this old way, you would've seen a line for each iteration within the analyzed logical plan
# new and better way of adding columns
new_column_dict = {}
for column in columns:
new_column_dict[column] = lit(None)
df = df.withColumns(new_column_dict)
# alternatively
new_column_dict = {"test_1": lit(None), "test_2": lit(None), "test_3": lit(None)}
df = df.withColumns(new_column_dict)
From the above code example, we can see that it requires a little bit of effort to put the columns into a python dictionary and then add those columns via .withColumns.
In the example below, take a look at the analyzed logical plan and the parsed logical plan. There's a project step for every withColumn call.
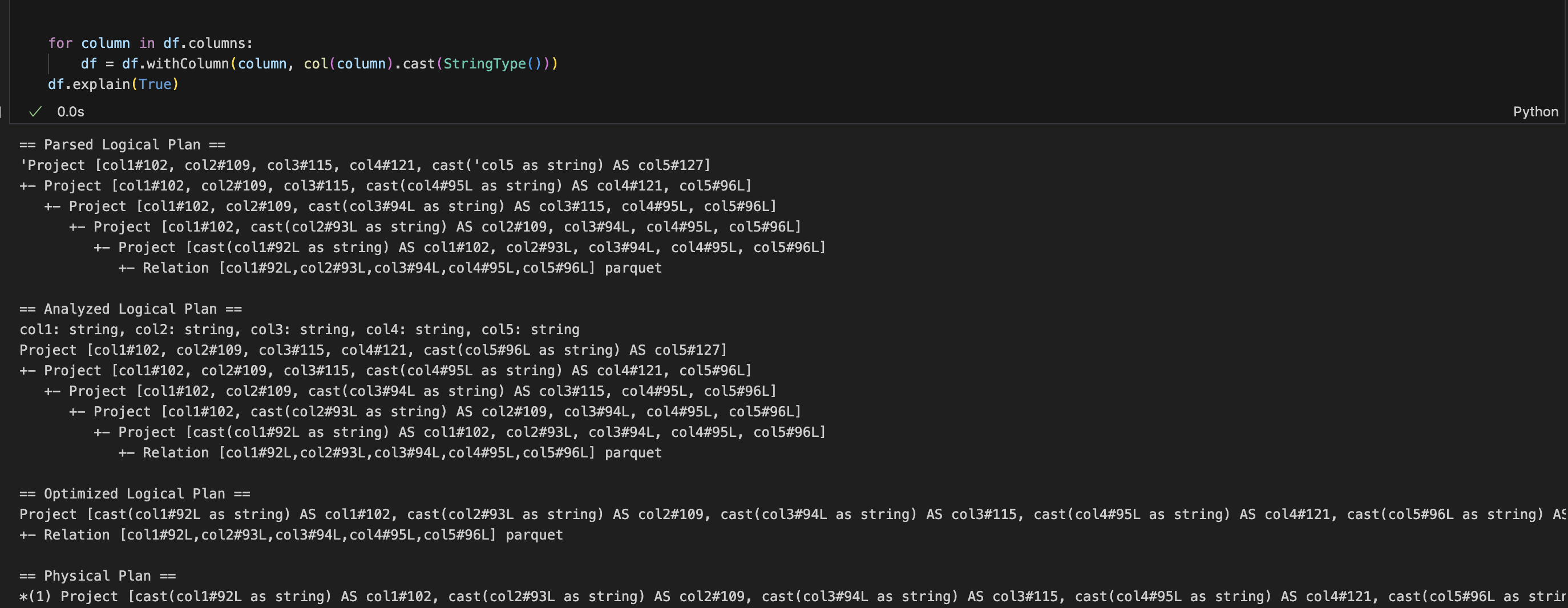
If we re-write this to use .withColumns() instead, we see that there's only one step and this is exactly what we're trying to accomplish.
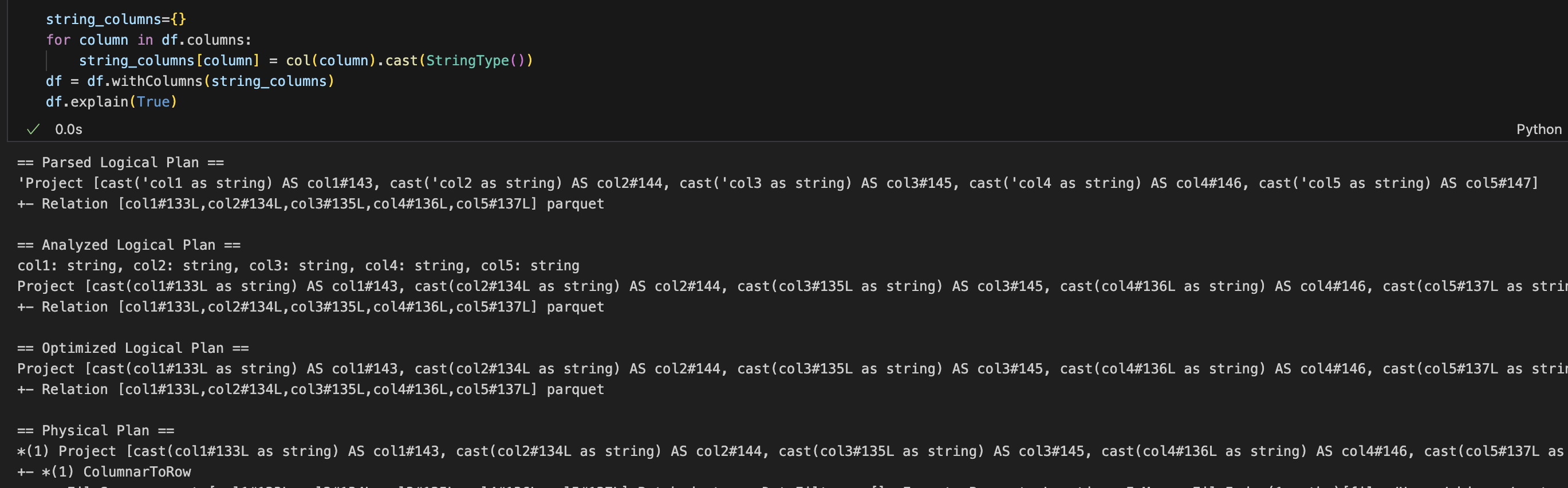
This is similar to what Matthew and Bartosz mentioned in their examples. The point is the same here too, we are trying to simplify these expressions so that the optimizer doesn't get hammered. The physical and optimized logical plan are the exact same in both cases, however, arriving at those plan is not the same in terms of performance.
To illustrate, this is a simple example comparing the time taken to add more columns to a dataframe. We can see that it remains constant using .withColumns(), and gets worse using .withColumn(). Moreover, we see that each successive .withColumn call takes longer, something that I had observed in the initial spark app that faced this issue. Within that example, a for-loop operation with 700 columns was being called 4-5 times during the spark job. In that example, changing to .withColumns() had significant advantages and lowered runtime drastically as a result. You may not see such dramatic increases for existing spark scripts but it's worth implementing this from a future-proofing perspective at the very least. If you're doing some housekeeping on old scripts, it's a quick and easy change to make anyway.
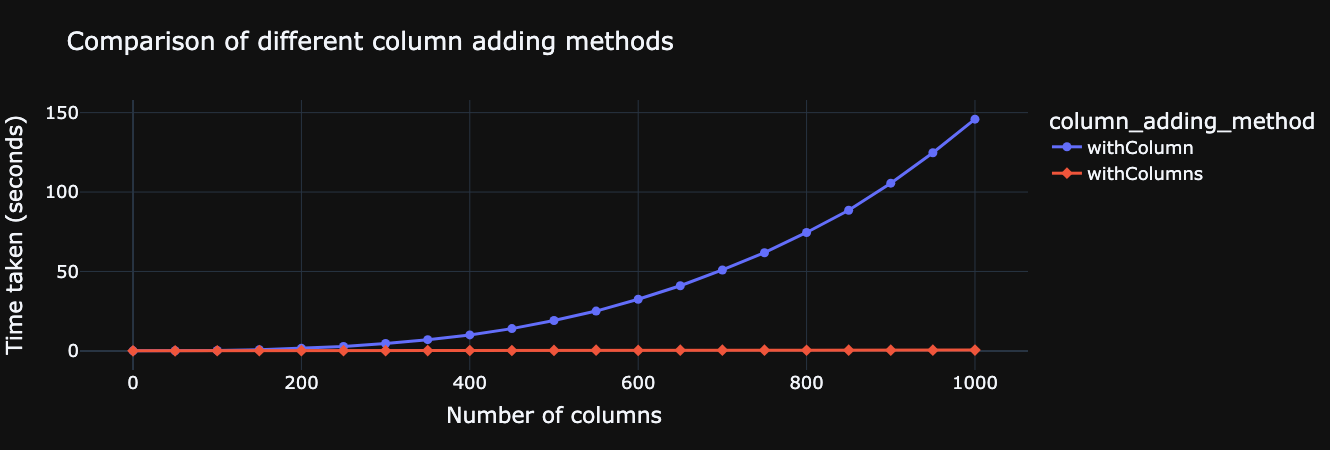
Ideally, your spark application should only really be taking some time to execute actions and other method calls that take up compute and memory, not in defining transformations.
Note - you may have to chain multiple .withColumns calls if you're going to refer to the result of one column within the same .withColumns() call.
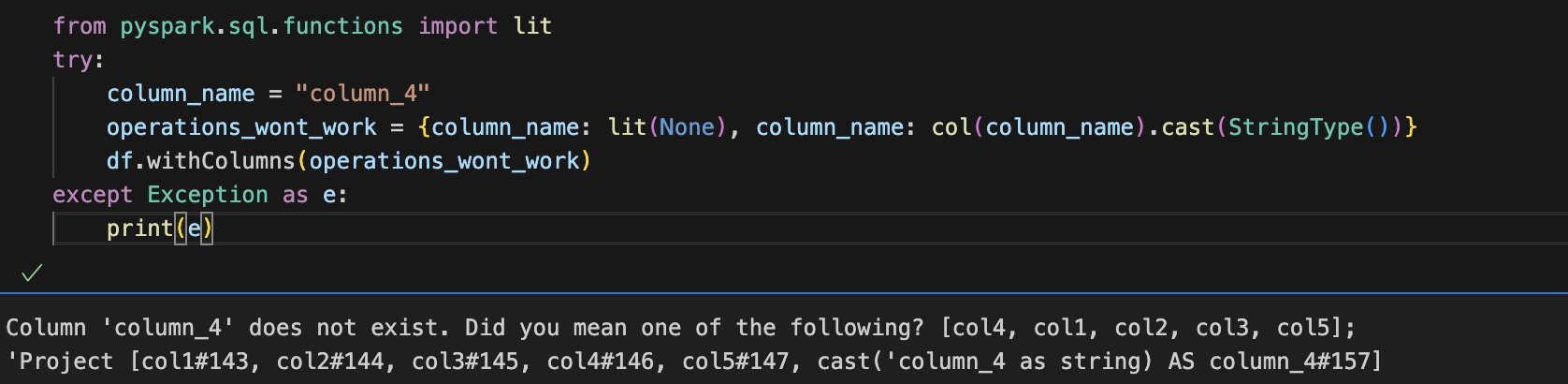
You would get the same error if you tried to do the same thing in a select statement. In such cases, you need to chain the calls as seen below:
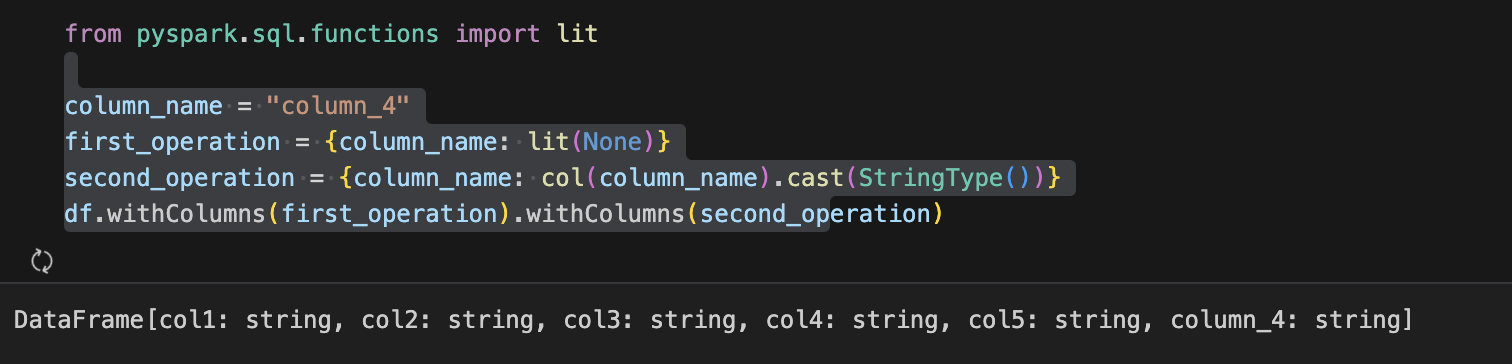
There is no performance difference in the above case if you were to use .withColumn but I would still use .withColumns in the event that you have to break a long series of transformations and just chain a few .withColumns vs several .withColumn.
Lessons learned
For starters, I thought that after Spark 3.0 and it's bevy of improvements, any major structural improvements for Spark and it's query engine were mostly done and that it was headed towards smaller improvements of functionality and usability. It's clear that there's still scope to improve performance without drastic changes to the execution engine.
Even for basic spark functions, read the docs from time to time. In retrospect, this could've been avoided without resorting to techniques that solve it in an inadvertent way.
The spark community keeps adding new features that are native to the platform and don't require your work-arounds. I truly think this is where the platform will continue to deliver more value. For instance, there may have been a UDF to perform AES encryption on a column or a series of operations to test whether a value can be cast to timestamp. Both of these operations are now natively supported by spark and it is definitely worth upgrading your spark apps to use these functions.
Embrace the debugging and documentation rabbit-hole you may end up in, I've learned a lot by doing so!
Further reading
The two blogs that helped me along the way, along with their other content, are fantastic must-reads:
MungingData by Matthew Powers - https://mungingdata.com/pyspark/rename-multiple-columns-todf-withcolumnrenamed/
waitingforcode by Bartosz Konieczny - https://www.waitingforcode.com/apache-spark-sql/beware-withcolumn/read
https://spark.apache.org/releases/spark-release-3-5-0.html - has been crucial to stay up-to-date with all the amazing new features that come out each release. As an exercise, you can check to see if there's features introduced here that can help you modernize some old code which will improve overall maintainability of your platform.
TL;DR:
Replace multiple .withColumn calls with fewer .withColumns to boost your Spark application performance 🚀 🤩.
Subscribe to my newsletter
Read articles from Anees Shaikh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by