Building Advanced RAG Applications Using FalkorDB, LangChain, Diffbot API, and OpenAI
 Akriti Upadhyay
Akriti Upadhyay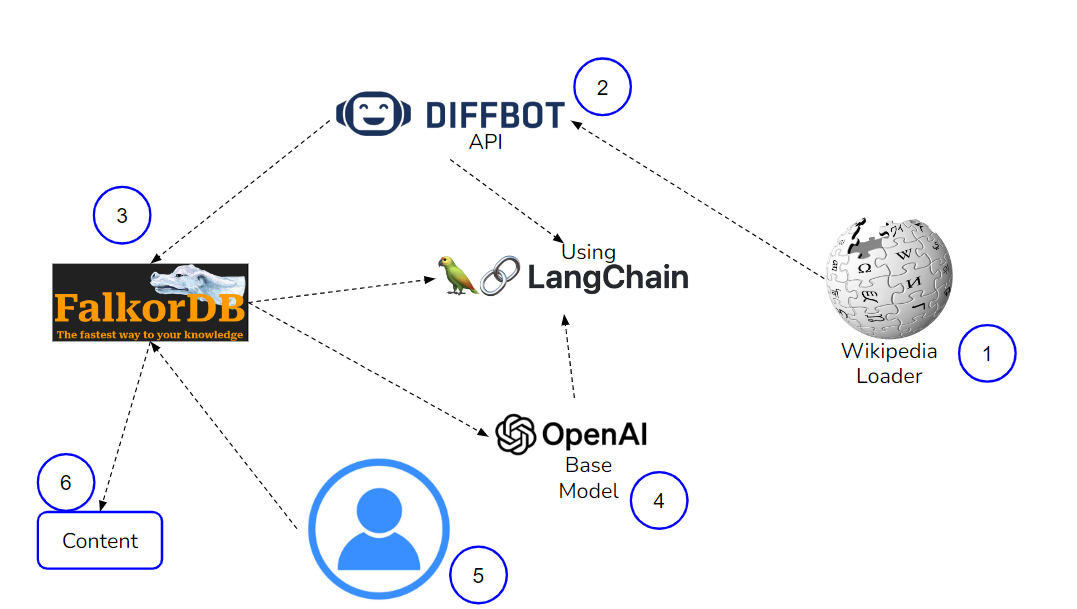
Introduction
The introduction of the Knowledge Graph Database in the realm of evolving Large Language Models has changed the way RAG applications are getting built. Since RAG mitigates knowledge limitations like hallucinations and knowledge cut-offs, we use RAG to build QA chatbots. Knowledge Graphs store and query the original data and capture different entities and relations embedded in one’s data.
With the help of a Knowledge Graph, we’ll build an advanced RAG application using the OpenAI base model.
Before diving deeper, let’s understand more about Knowledge Graphs!
What Is a Knowledge Graph?
The knowledge graph is centered around a knowledge model, which consists of interconnected descriptions of concepts, entities, relationships, and events. These descriptions have formal semantics, enabling human and computer processing efficiently and unambiguously. The descriptions contribute to one another and form a network, where each entity represents part of the description of the related entities. Based on the established knowledge model, diverse data is linked and described through semantic metadata.
Knowledge graphs integrate features from various data management paradigms. It functions as a database, a network, and a knowledge base simultaneously. They serve as a database by allowing structured queries on the data, operate as a network for analysis like any other network data structure, and function as a knowledge base due to the formal semantics of the data. The formal semantics enable the interpretation of data and the inference of new facts. In essence, a knowledge graph is a unified platform where the same data can assume different roles.

Knowledge graphs function as databases when users utilize query languages for creating complex and structured queries to extract specific data. Unlike relational databases, knowledge graph schemas are dynamic, not requiring a predefined structure, and they avoid data normalization constraints. Additionally, knowledge graphs operate like any other graph, with vertices and labeled edges, which make them amenable to graph optimizations and operations. However, the true power of knowledge graphs lies in the formal semantics attached to vertices and edges, which allows both humans and machines to infer new information without introducing factual errors into the dataset.
Why Knowledge Graphs?
Knowledge graphs stand out as a dynamic and scalable solution that effectively meets enterprise data management needs across various industries. Going beyond that, they act as central hubs for data, metadata, and content, providing a unified, consistent, and unambiguous perspective on data distributed across diverse systems. Moreover, knowledge graphs enhance their proprietary information by incorporating global knowledge as context for interpretation and as a source for enrichment, which adds intelligence to the data.
Knowledge graphs offer a comprehensive solution to challenges in the global data ecosystem faced by organizations of all sizes. These challenges include dealing with diverse data sources and types, often spread across legacy systems used beyond their original purposes. Knowledge graphs provide a higher-level abstraction, by separating data formats from their intended purpose.
Traditional data management solutions created a gap between real-world information and the limitations of software and hardware, making them less intuitive. Knowledge graphs bridge this gap by replicating the connective nature of how humans express and consume information by adapting to changes in understanding and information needs.
The concept of rigid and unchanging data schemas becomes a challenge as business cases evolve. Knowledge graphs offer flexibility by allowing dynamic adjustments to schemas without altering the underlying data. This adaptability proves invaluable in a constantly changing world, where maintaining a fixed schema is impractical.
Knowledge Graph vs Vector Database
Vector databases have become the default choice for indexing, storing, and retrieving data which would be later used as context for questions or tasks presented to Large Language Models. This involves chunking data into smaller pieces, creating embeddings for each piece, and storing the data and its embeddings in a vector database. However, this approach has a major limitation as it relies on semantically similar vectors from the database, which lacks essential information for the LLM.

Knowledge graph provides an alternative approach to storing and querying original documents while capturing entities and relations within the data. The process starts with constructing a knowledge graph from documents and identifying entities and relationships. This graph serves as a knowledge base for LLMs, which allows richer context constructions. User questions are translated into graph queries, which leverage all connections within the graph for a more comprehensive context. This enriched context, combined with the original question, is presented to LLMs to generate more informed answers. This alternative approach surpasses the limitations of relying solely on semantically similar vectors.
RAG Architecture with KGLLMs
Knowledge Graphs serve as potent tools for structuring and querying data, capturing relationships, and enriching information from external sources. However, Knowledge Graphs face challenges with unstructured natural language data, which is often ambiguous and incomplete. Large Language Models, adept at generating natural language, offer a solution by understanding syntactic and semantic patterns. Yet, LLMs have limitations, including generating inaccurate or biased texts.
An interaction between Knowledge Graphs and LLMs proves powerful. By combining them, we can address the weaknesses and leverage the strengths. A framework called Knowledge Graphs with LLMs (KGLLM) showcases practical applications like question-answering, text summarization, and creative text generation. KGLLM not only uses Knowledge Graphs to inform LLMs but also employs LLMs to generate Knowledge Graphs, which helps in achieving bidirectional communication. Techniques like entity linking, embedding, and knowledge injection enhance accuracy and diversity, while knowledge extraction, completion, and refinement expand Knowledge Graph coverage and maintain quality.
We have seen how RAG works with vector databases. Let’s understand how RAG works with Knowledge Graphs.

In the context of the Knowledge Graph Large Language Model working with Retrieval-Augmented Generation, the process involves the following:
Documents: Start with a diverse corpus of documents from various sources containing extensive information. Data from external sources like Wikipedia and DBPedia could be used.
Entity Extractor: Employ an entity extractor using Natural Language Processing techniques to identify and extract entities (people, places, events) and their relationships from the documents.
Knowledge Graph: Utilize the extracted entities and relationships to construct a structured and semantic knowledge graph, by forming a network of interconnected entities.
LLM: Train a Large Language Model on broad text corpora encompassing human knowledge. LLMs simplify information retrieval from Knowledge Graphs, which offers user-friendly access without requiring a data expert.
Graph Query: The LLM retrieves relevant information from the Knowledge Graph using vector and semantic search when a query is passed. It augments the response with contextual data from the Knowledge Graph.
Content: Generate the final content using the RAG LLM process, ensuring precision, accuracy, and contextually relevant output while preventing false information (LLM hallucination).
This high-level overview explains how a Knowledge Graph LLM functions with RAG, which acknowledges potential variations based on specific implementations and use cases.
FalkorDB: An Open Knowledge Graph
FalkorDB is a high-performance Graph Database designed for applications prioritizing fast response times and refusing to compromise on data modeling. It succeeds RedisGraph and is recognized for its exceptionally low latency. Users trust FalkorDB for its uncompromising performance. It can be easily run using Docker.

FalkorDB stands out as the preferred Knowledge Database for Large Language Models due to its distinctive features:
Super Low Latency: FalkorDB's exceptionally low latency is well-suited for applications that require rapid response times.
Powerful Knowledge Graphs: FalkorDB employs powerful knowledge graphs by efficiently representing and querying structured data, and capturing relationships and attributes of entities like people, places, events, and products.
Combination with LLMs: By integrating Knowledge Graphs with LLMs, FalkorDB capitalizes on the strengths of both, which mitigates their weaknesses. Knowledge Graphs offer structured data to LLMs, while LLMs contribute natural language generation and understanding capabilities to Knowledge Graphs.
LLM Context Generation: FalkorDB constructs a knowledge graph from documents to serve as a knowledge base for LLMs that identify entities and their relationships. Interestingly, LLMs can be employed in this process.
These features make FalkorDB an influential tool for LLMs, which provides them with a structured, low-latency knowledge base. This integration enables LLMs to produce high-quality and relevant texts that establish FalkorDB as the top KnowledgeDB for LLMs. To get started with FalkorDB, visit their website.
Implementing RAG with FalkorDB, Diffbot API, LangChain, and OpenAI
To get started, first install all the dependencies.
%pip install langchain |
Start FalkorDB locally using docker.
docker run -p 6379:6379 -it -rm falkordb/falkordb:edge |
Login into Diffbot by visiting its website to get the API key. You’ll see the API token on the upper right side. To know more about using Diffbot API with FalkorDB, visit this blog.
The Diffbot API is a robust tool designed to extract structured data from unstructured documents like web pages, PDFs, and emails. Users can utilize this API to build a Knowledge Graph, by capturing entities and relationships within their documents and storing it in FalkorDB. To query and retrieve information from the Knowledge Graph, LangChain can be employed. LangChain is capable of handling intricate and natural language queries, by providing accurate and relevant answers based on the stored data.
from langchain_experimental.graph_transformers.diffbot import DiffbotGraphTransformer |
Here, we’ll use WikipediaLoader, which is an external source to load the data using LangChain. The loader retrieves text from Wikipedia articles by utilizing the Python package called Wikipedia. It accepts inputs in the form of page titles or keywords that uniquely identify a Wikipedia page. As it stands, the loader exclusively focuses on extracting text and does not consider images, tables, or other elements. I am querying here about ‘Washington’; let’s see what knowledge it can provide with this query.
from langchain.document_loaders import WikipediaLoader |
Then, we’ll use FalkorDBGraph to create and store a Knowledge Graph.
from langchain.graphs import FalkorDBGraph |
We’ll need an OpenAI API key, so pass your key to the environment.
import os |
Now, we’ll pass the graph that we created and the LLM which we’re using here, OpenAI. We’re using a very basic model of OpenAI with temperature=0, which can be used with a free-tier OpenAI API key.
from langchain_openai import ChatOpenAI |
After that, pass your question in the chain.
chain.run("Which university is in Washington") |
The following will be the results:
> Entering new FalkorDBQAChain chain... |
Let’s try another question in the chain.
chain.run("Is Washington D.C. and Washington same?") |
The following will be the results:
> Entering new FalkorDBQAChain chain... |
The results were quite good even using the basic model of OpenAI.
Conclusion
With the introduction of Knowledge Graphs, it’s easy to implement RAG to reduce LLM hallucinations. Knowledge Graphs are simple as compared to vector databases. It’s fascinating that your data is not only stored and queried but also the relationships between the entities are being captured.
It was interesting for me to build an RAG application with Open Knowledge Graph FalkorDB. Now, it’s your turn. Enjoy and have fun!
Thanks for reading!
This article was originally published here: https://medium.com/@akriti.upadhyay/building-advanced-rag-applications-using-falkordb-langchain-diffbot-api-and-openai-083fa1b6a96c
Subscribe to my newsletter
Read articles from Akriti Upadhyay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by