Map Reduce: Framework for Big Data
 Binal Weerasena
Binal Weerasena
The Problem with Data Storage and Analysis
In a previous article, we discussed What is Big Data? and how big data actually can be. With the 3V's concept, we understood the key parameters of big data which is the volume, velocity, and variety. The huge volume raises new problems in handling and processing these data since conventional methods would consume a lot of time to process millions and billions of data.
Although the storage capacities of hard drives have increased over the past centuries, the access speed has not developed accordingly. The norm today is in Terabytes (1 TB storage disk is the most common) of data while still the access speed of drives relies around 100MB/s. It takes quite a lot of time which is in terms of hours to read a bunch of terabytes at this speed.
What could be the best approach to mitigate this problem? Imagine if we had 100 drives holding one-hundredth of the data in each, the data retrieval time would be super fast and the total data volume can be read in under two minutes for the above-brought example.
So working in parallel among multiple storage units is the answer.
The Birth of Big Ideas
Scaling 'out' not 'up'
Big data has been around since the 90s and supercomputers were a sound solution to tackle huge datasets at that time. Scaling up is what we call increasing the computational power and trying to tackle the big data problem that way, which obviously is way more cost-ridden and reaches a bottleneck nonetheless. Scaling out is the cost-effective and more practical solution for the growing data need. It's simple yet genius. Now these huge dataset operations are tackled by commodity-level computers but thousands of them play parallel together.
Move the processing to the data.
When something is big enough, you really don't want to move it. Moving it would be a catalyst for a sequence of problems. You don't move the gas station to your car, the car goes towards the gas station. You don't ask your 300-pound girlfriend to come towards you, you go to her. Similarly, in big data, the data volume is so huge that moving the processing to the storage is easier than tackling the movement of these data storages which would cause many problems.
The storage and processing units are co-located in the same machines.
This is an extension of the above. If the storage and processing are located in two different locations, it would be a nightmare to work with big data.
Process data sequentially. Avoid Random Access.
Seeking refers to the process by which a particular data record is looked for in a dataset using B-tree or similar methods. Scanning is the process that goes through each record of the dataset to execute an action on them. Although seeking is notionally faster in our context of the day today small data handling operations, when it comes to Big Data seeking cause much more delay than scanning through each record of the data set.
Consider a 1 TB database with 100-byte records.
1 TB = 10^12 bytes
The number of 100-byte records in 1 TB is 10^10 records.
We need to update 1% of the records(10^8 records). What if we choose to random access these 1% and update them? Each update takes 30ms to seek, read, and then write. If so to update 1% it would take us roughly 35 days to update.
What if we rewrite all the records? It would only take 5.6 hours. So the lesson is to avoid random seeks.
This is the most crucial idea that we need to pause and think about. It is the fundamental idea behind the birth of MapReduce Framework for handling big data queries.
Seamless Scalability
Big data often grows substantially fast and therefore we need to scale the data storage every minute. The code written by a programmer for a data processing operation distributed across 3 commodity machines should be perfectly fitting even if the scale increases to 300 machines or so. The idea is that the programmer cannot change the code with the volume and velocity of the data.
What is MapReduce?
MapReduce is a distributed programming framework for processing large amounts of data over a cluster of machines.
Following are the abstract steps to perform a MapReduce on a dataset.
Iterate over a large number of records
Extract something of interest from each - Map
Group intermediate results
Aggregate intermediate results - Reduce
Write final output
MapReduce Framework
The number one rule here is that every record is a key value pair. The programmer has to take care of the Map function and the Reduce function to attain the necessary output from the data.
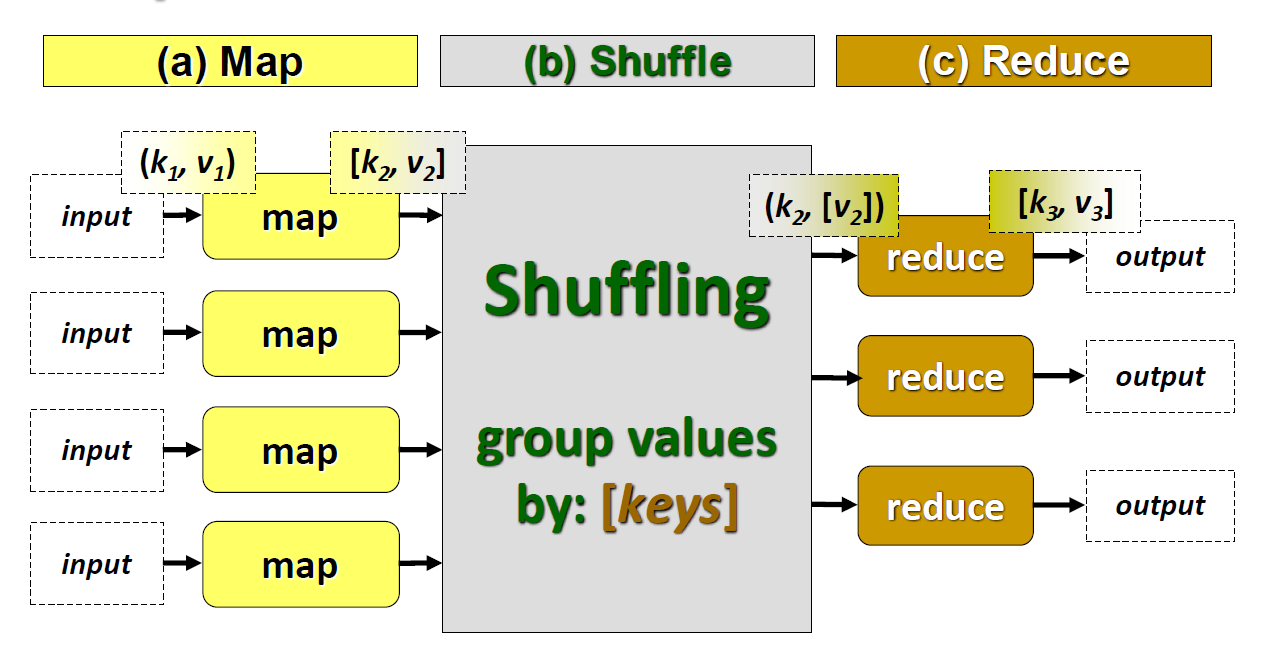
To better understand the framework we can go through a simple counting example as follows.
Word Count: "Hello World!" of Map Reduce
The first-ever program on MapReduce is usually a word count problem. That is why I named it the "Hello World!" of Map Reduce. Take for example the following task to better overview the framework.
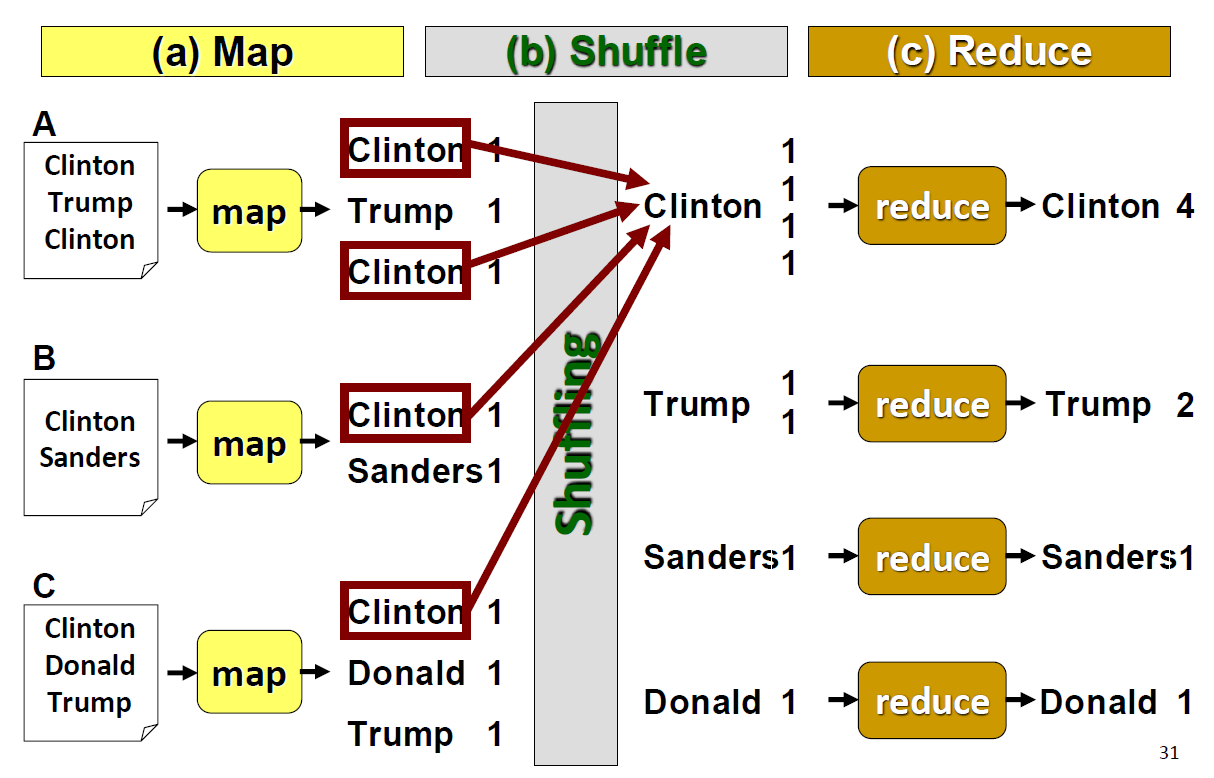
The input dataset is a textual dataset containing the candidate names. A, B, and C are different machines containing the data. The programmer of the MapReduce framework needs to think of a Map function to get the word count each time the word appears in the dataset. The output of the Map stage should be a key-value pair. Mark that the words are not aggregated in this stage. The shuffling is done automatically by the framework itself. It groups by whatever the unique keys it gets while the value is the list of values of the previous stage. Remember after shuffling, Clinton has four 1's but not a single 4. This is taken care of by the programmer in the Reduce stage. The Reduce code needs to be written to get the count out of it in this particular scenario. The output of the reduce stage thus will be the desired output.
Hope you understand the basics behind the fundamental framework in handling Big Data. We will dive more into Map Reduce and Hadoop in the next articles.
Subscribe to my newsletter
Read articles from Binal Weerasena directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by