Getting under the hood: "Git Internals"
 Pranshu
Pranshu
General Overview
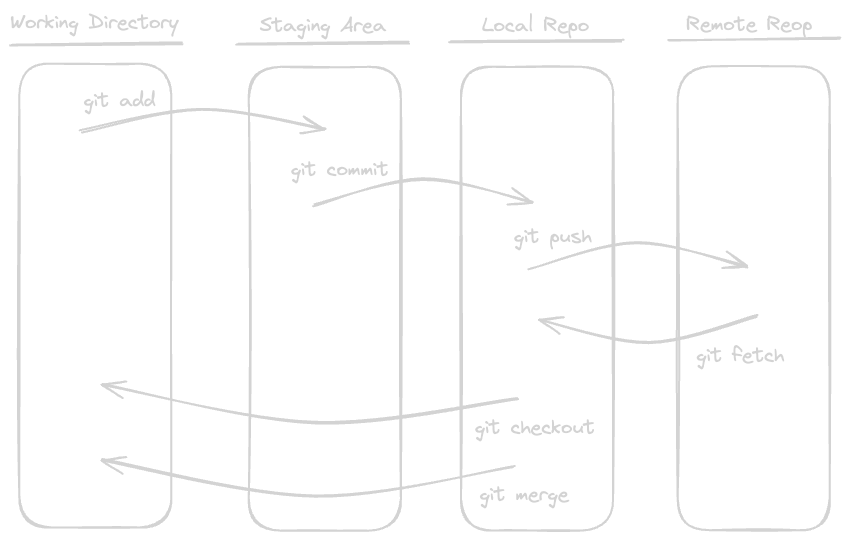
Basically whenever we create a Git repo using the command git init, it creates a hidden folder named .git. This folder contains all the necessary files and folders in order to facilitate the management of the repository. Basic git workflow on a local machine consists of three areas, the working directory, the staging area, the local repo.
Most people when implementing a version control system would go about doing so, by taking snapshots of the entire code base and storing them somewhere else for fault safety like in a hidden folder. To reduce the disk space used they may use symlinks for the unchanged files between each snapshot. While this strategy works mostly fine in normal and relatively small code-bases, it can lead to various problems in large code-bases, most of would be majorly related to the use of large disk space due to multiple copies of the files. Thus git does it in a better way by instead of storing the file, it majorly stores BLOBs (Binary Large OBjects). These blobs contain the snippets of code changes i.e. the content of the file without any metadata. These are connected to Trees and commits.
Lets get under the hood
Before we begin, it is important to understand that almost everything in git is hashed. You can consider git to be a content addressable file system i.e. a key value store. Where the SHA-1 hash value is the key and the contents is the value. Git also compresses the contents of the objects in order to minimize the usage of disk space. Another point to note is that inside the .git folder, the objects are stored further in different folders decided by the first 2 characters of their SHA-1 hash value. The rest 38 are kept as the file names. This is done because some older file systems like the FAT32 only allow approximately about 65K files in one folder.
Git object types
Commit - Represents a snapshot of the repository at a specific point in time. They contain data like the tree object hash, parent commit hash, author, committer, date, message.
Tree - They are used to organize files and directories inside the git repository. They point to the file name, file permissions, other metadata, and the blobs that make up the content or the change.
Blob - Represents a file or a piece of content. These are named with the SHA-1 checksum of the content and its header.
Tags and Branches - These in their simplest forms can be considered to be like aliases for the various commits for better developer experience. So that the developers do not have to keep using the extremely random and long hash value to get to a specific commit.
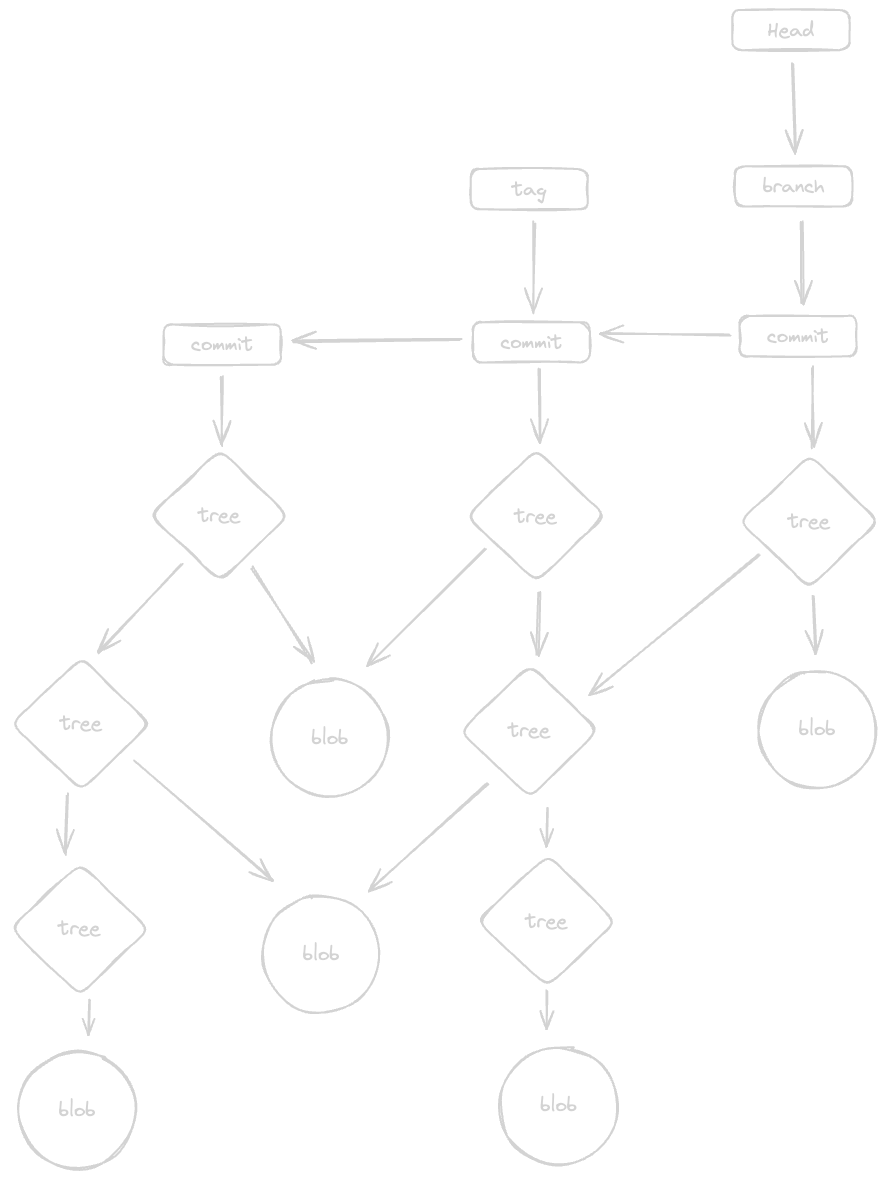
Explanation
From the above model we can easily understand the basic underlying working of git. So, whenever we change a file, and stage it, git stores the value of that file i.e. the contents without any metadata inside a blob. Whenever we commit a change, a commit object is created that stores various metadata about the commit like the message, committer, author, pointer to previous commit, etc and also points to a tree object type which in turn can point to various other trees and blobs. So this in turn forms a sort of self referencing structure where the tree of a commit points to other trees that describe the previous state of the repo, and to blobs which represent the changes made to the content.
Resources for more knowledge
For the above official git documentation, the Plumbing commands will be extremely useful in learning about git internals
Subscribe to my newsletter
Read articles from Pranshu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by