Building a Simple Yet Powerful Search Feature with Redis
 Melvin
Melvin
While numerous software options exist for building search features, they can often be overkill for simpler use cases, especially when dealing with less voluminous data. This article presents a solution for constructing a search feature using Redis. We will compare it with other solutions, such as ElasticSearch, and explore various options for data ingestion into Redis.
Requirements
To objectively evaluate a solution, understanding the requirements is crucial. The solution was devised with specific constraints and features in mind.
In my case, the solution must support searches in both English and French, accommodating accented characters (é, è, ê, etc.).
The search execution must also be quick enough so that it can be displayed as autocomplete results.
Maintain architectural simplicity is paramount. I aim to minimize components in our software stack to reduce operational overhead and maintenance work.
Crucially, the search should not create any noticeable performance impact to our transactional database (OLTP).
Proposed Solution With Redis
During my research, RediSearch captured my attention. It is a Redis module providing advanced querying features, including full-text search. Using Redis for search is compelling, especially since many web services already use Redis for caching. Leveraging Redis for search allows me to avoid introducing another component to the stack, aligning with one of the set requirements.
With RedisInsight, I inserted some JSON documents into a locally spawned Redis instance in Docker. The JSON documents' structure resembled:
{
"id": "<id>",
"textEn": "<English text goes here>",
"textFr": "<French text goes here>"
...
}
I then created a full-text index for English and French:
FT.CREATE docsEn ON JSON LANGUAGE English SCHEMA $.id AS id NUMERIC $.textEn AS text TEXT
FT.CREATE docsFr ON JSON LANGUAGE French SCHEMA $.id AS id NUMERIC $.textFr AS text TEXT PHONETIC "dm:fr"
The Redis full-text index allows distinguishing contents of different languages. For the French index, I added PHONETIC "dm:fr" for improved handling of homophones.
To search the indexed documents:
FT.SEARCH docsEn '@text:(<my_term_here>)'
RETURN 2 id text
SUMMARIZE FIELDS 1 text FRAGS 1 LEN 10
HIGHLIGHT FIELDS 1 text TAGS '<b>' '</b>'
LANGUAGE English
FT.SEARCH docsEn '@text:(<my_term_here>)'
RETURN 2 id text
SUMMARIZE FIELDS 1 text FRAGS 1 LEN 10
HIGHLIGHT FIELDS 1 text TAGS '<b>' '</b>'
LANGUAGE French
I separated the commands into multiple lines to enhance readability. You should still run each of them in one line.
With a limited dataset of around 120 documents, each averaging 300 words in English and French, search performance was satisfactory. The average search execution time ranged from 2 to 6ms, even with fuzzy search.
Searching In A Larger Dataset
Curious about the performance with a larger dataset, I conducted a test with a subset of the "English-French translation dataset" from Kaggle, which contains over 22.5 millions English-French sentences.
With some scripting, I managed to insert the first 8.5 millions lines of the dataset into my local Redis instance.
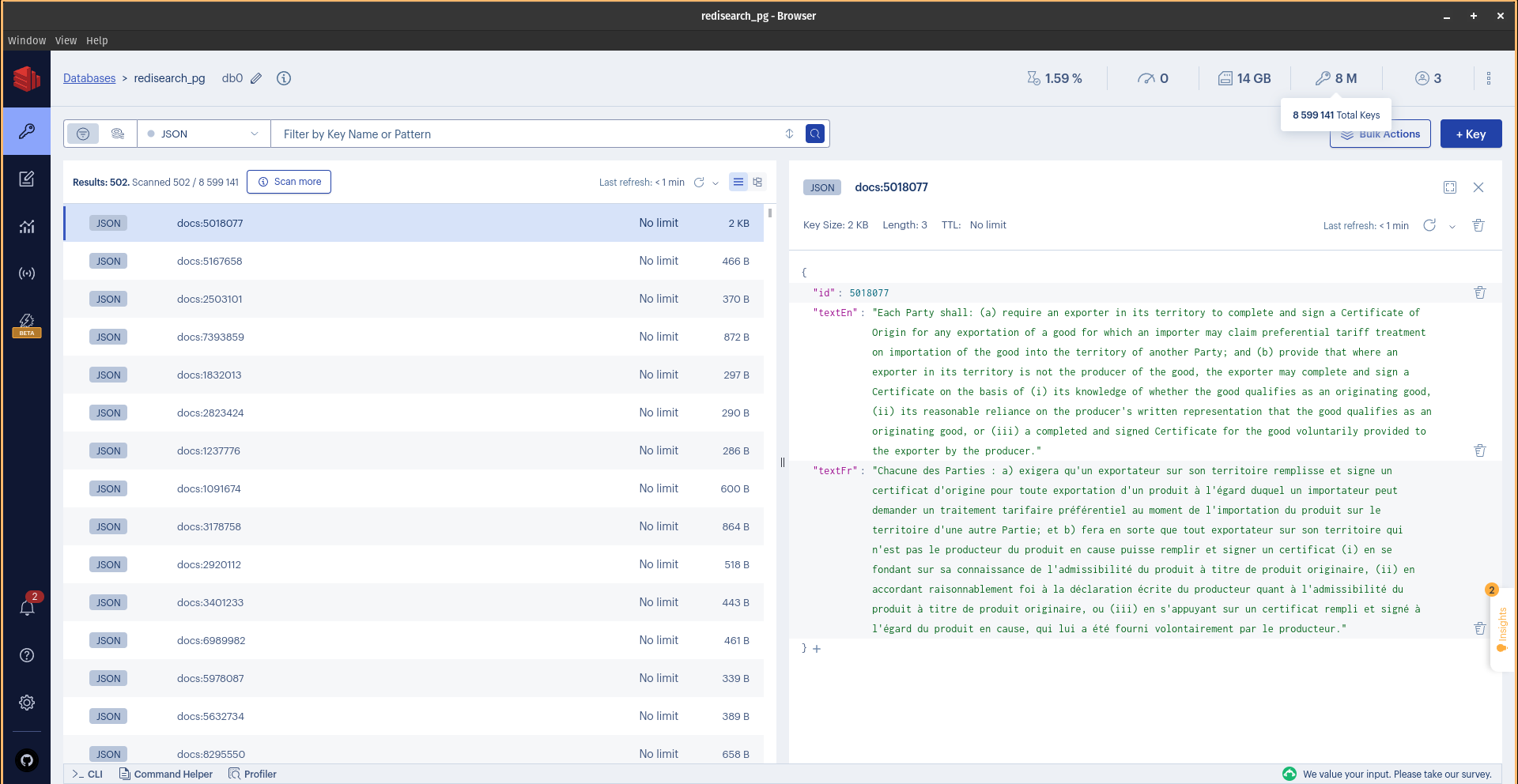
Now, it's time for some searches. First, I searched the term "brain*" in English, and it took about 6ms to complete:
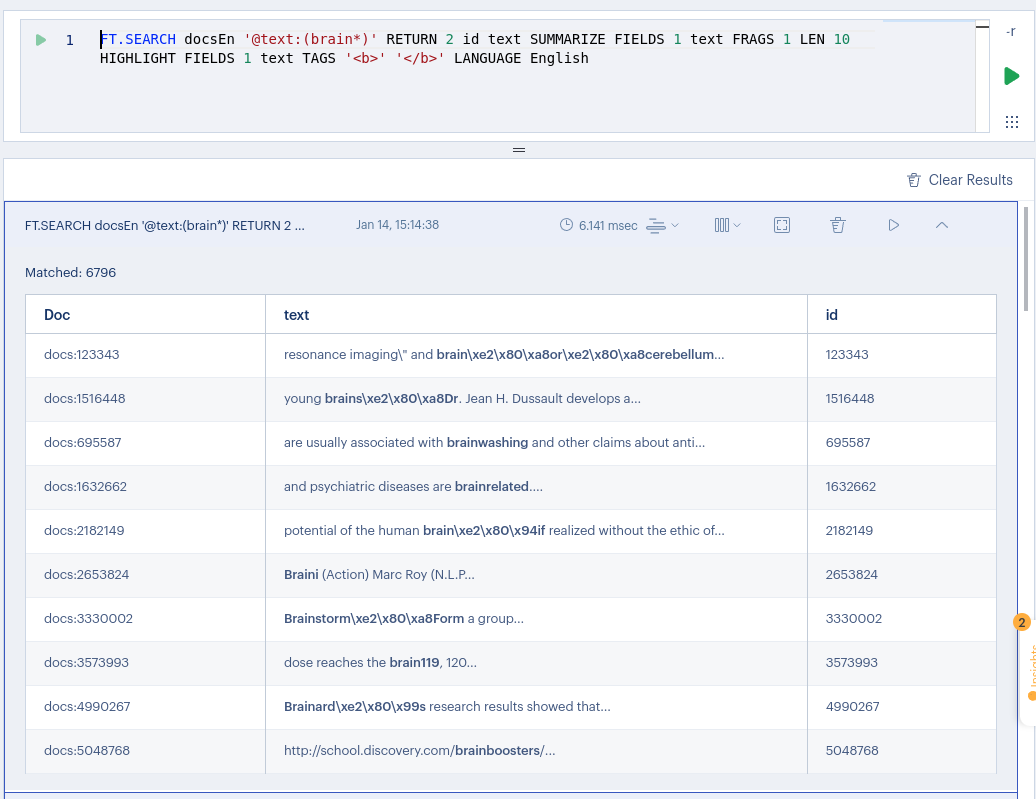
Next, in French, it took slightly less time, approximating to 4ms:
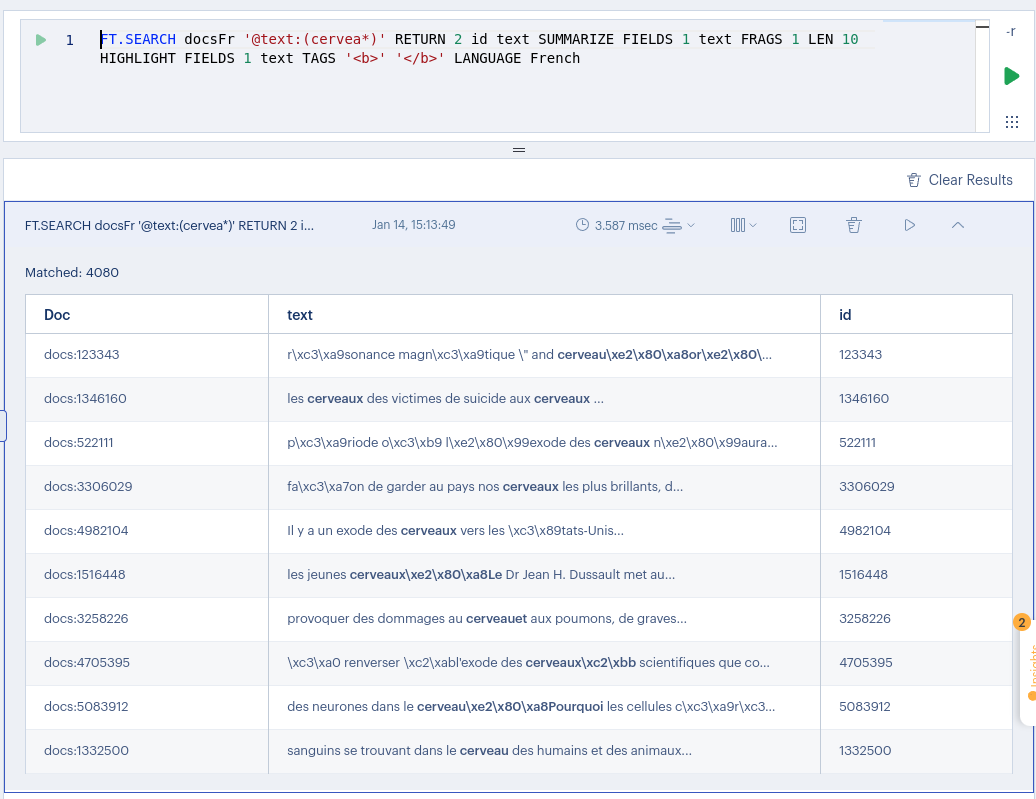
To provide you with an idea of how Redis performs, these were the results of running the same query repeatedly. The execution time hovered between 5-6ms.
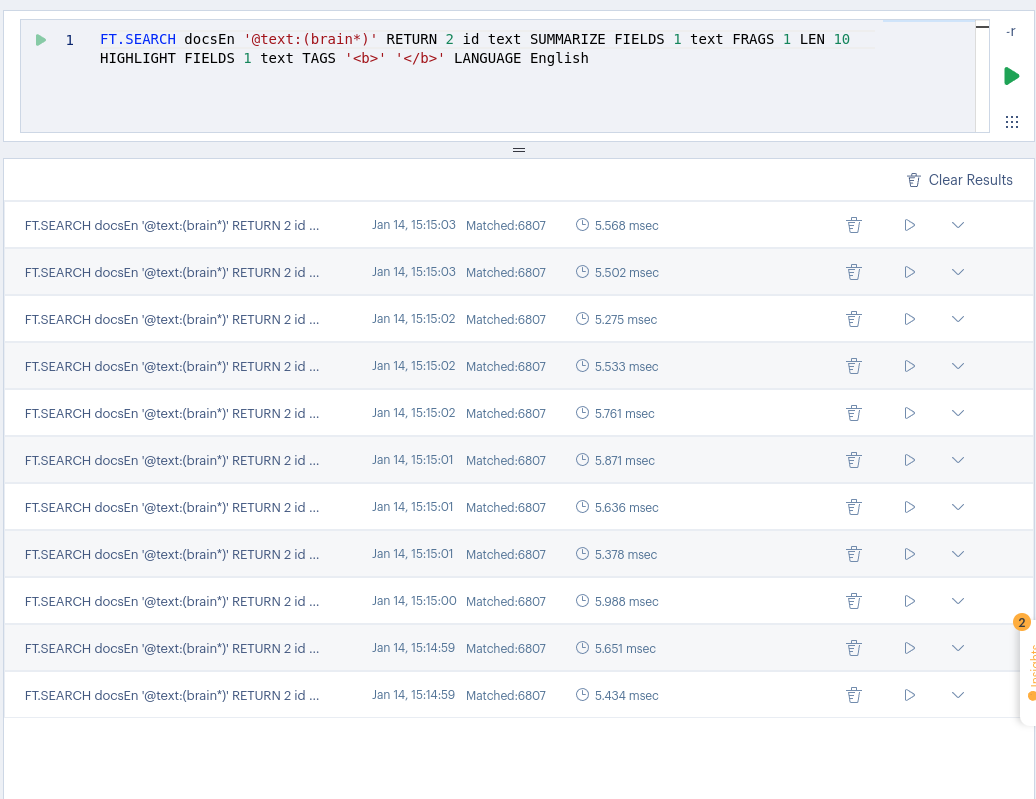
With a large dataset, the search performance remained robust. Despite the lack of scientific design in the tests, the results provided me a quick performance overview.
Potential Downsides
Although I was excited about the performance Redis provides, it's essential to acknowledge some drawbacks.
A significant concern is that Redis functions as an in-memory datastore. While this characteristic may or may not pose a problem, the Redis solution may prove unsuitable for handling large datasets.
The results of fuzzy search with accented characters can be inconsistent. In my testing, I observed that searching for declaration and déclaration did not yield the expected results. However, this may not be a concern for everyone.
Alternative Solutions
If you've made it this far, you should have a good understanding of the solution I proposed and how well it will work for your use cases.
Alternatively, you might want to look into using more advanced search engine such as ElasticSearch and Solr. They are more suitable when you need to search through a much larger dataset. However, unless you're already using it, it will be an extra piece of software in your stack that you have to manage, which means additional costs.
Another solution that I had in mind was to use the full-text search feature provided by RDBMS. However, full-text search in most RDBMS is relatively limited. For instance, wildcard search is not possible in MySQL. You'll find no scarcity of problems on the internet shared by fellow developers regarding full-text search in RDBMS. In addition, performing a full-text search is akin to an OLAP operation. I am reluctant to perform search queries against an OLTP database. The fact that searches are done in Redis, instead of in the source DB, means that a unified search feature can be easily built to allow us to search through data sourced from multiple databases.
Feeding Data Into Redis
With my proposed solution, I needed to decide on how documents will be fed into Redis initially and how on-going data changes will be streamed into Redis.
To initialize the Redis instance, an one-off script can be executed to retrieve existing data from the source DB and subsequently write it into Redis.
For continuous data changes, I considered several approaches:
Change Data Capture (CDC): A CDC approach integrates well with RDBMS, allowing changes to be seamlessly streamed into Redis without altering the source DB. However, this method introduces additional complexity due to the need for an extra software such as Debezium.
Outbox pattern : Alternatively, the outbox pattern involves updating the application layer to generate an event alongside any update operations. A relay service is then created to process the events and update Redis accordingly. While effective, this solution is more verbose compared to CDC.
Dual-write strategy: The third idea involves using a dual-write strategy. In this scenario, any changes made to the documents must pass through a web API. Adjusting the API to write to Redis after persisting changes in the DB ensures synchronization. Although this strategy may introduce potential data inconsistencies, it can be mitigated by failing the HTTP request unless both writes are successfully executed.
A dual-write strategy best suits my situation, but you may prefer another approach that is more appropriate for your needs.
Conclusion
In summary, the proposed solution for building a search feature using Redis meets my specified requirements, offering efficient multilingual searches and maintaining architectural simplicity. However, it's crucial to acknowledge potential downsides. When dealing with much larger datasets, alternative solutions like ElasticSearch should be seriously considered.
As with any technology decision, a thorough understanding of your requirements and a careful evaluation of alternatives will guide you to ensure the selection of the most suitable solution.
I hope this article provides some insights for you. Feel free to share your thoughts and feedback.
Subscribe to my newsletter
Read articles from Melvin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by