How to choose a database for optimal performance of your application.
 Rahul Gupta
Rahul Gupta
There are 300+ databases out there in the tech world, choosing ideal one for your application can be very challenging. Working with a database you’re already familiar with is a great option and absolutely fine only if optimal performance is not considered, but consider a scenario where your application expands and after couple of years your app starts facing some issues related to data leakage or data corruption or may be late response. then it becomes a tedious tasks for developers to handle it and fix the issues on the phase when your application is already live and has grown to large scale.
There is no fixed set of rules to be followed while choosing database but some key steps can be kept in consideration while choosing database for optimal performance.
Table of Content
What is a database ?
Different types of database.
What points to consider while choosing database?
Scaling (vertical scaling & horizontal scaling).
Performance.
CAP Theorem.
Database selection based on CAP theorem.
1.What is a Database?
A database is an electronically stored, systematic collection of data. It can contain any type of data, including words, numbers, images, videos, and files. You can use software called a Database Management System (DBMS) to store, retrieve, and edit data.
2.Different types of database.
Databases can be classified under various categories based on data modal, user numbers ,distribution and etc.
A . Relational Databases (RDBMS):
Description: Relational databases organize data into tables with rows and columns. They use SQL (Structured Query Language) for defining and manipulating the data. Relationships between tables are established using keys.
Examples: MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server.
B . NoSQL Databases:
Description: NoSQL databases are designed to handle unstructured or semi-structured data and can scale horizontally. They are suitable for large-scale distributed systems.
e.g.
MongoDB (document-oriented),
Cassandra (wide-column store),
Redis (key-value store),
Neo4j (graph database).
C . NewSQL Databases:
Description: NewSQL databases aim to combine the benefits of traditional relational databases with the scalability and performance of NoSQL databases.
Examples: Google Spanner, CockroachDB.
D . Document-Oriented Databases:
Description: Document databases store data in flexible, JSON-like documents, allowing for the easy representation of hierarchical relationships and nested data structures.
Examples: MongoDB, CouchDB.
E . Key-Value Stores:
Description: Key-value stores use a simple key-value pairing for data storage. They are highly efficient for read and write operations but may lack advanced querying capabilities.
Examples: Redis, DynamoDB.
F . Column-Family Stores:
Description: Column-family stores organize data into columns instead of rows, making them suitable for analytical queries and large-scale data storage.
Examples: Apache Cassandra, HBase.
G . Graph Databases:
Description: Graph databases are designed to represent and query relationships between data entities. They are efficient for scenarios where relationships are as important as the data itself.
Examples: Neo4j, Amazon Neptune.
H . In-Memory Databases:
Description: In-memory databases store data in RAM, allowing for extremely fast read and write operations. They are suitable for applications that require low-latency access to data.
Examples: Redis (can also be classified as a key-value store), SAP HANA.
I . Time-Series Databases:
Description: Time-series databases are optimized for handling data points indexed by time. They are commonly used in applications that deal with time-stamped data, such as IoT and financial systems.
Examples: InfluxDB, OpenTSDB.
J . Object-Oriented Databases:
Description: Object-oriented databases store data in the form of objects, which encapsulate both data and the methods that operate on the data. They are suitable for applications with complex data structures.
Examples: db4o, ObjectDB.
3. What points to consider while choosing database?
How much data do you expect to store when the application grows to larges scale?
How many users do you expect to handle simultaneously at peak load?
What availability, scalability, latency, throughput, and data consistency does your application need?
How often will your database schemas change?
What is the geographic distribution of your user population?
What is the natural “shape” of your data?
Does your application need online transaction processing (OLTP), analytic queries (OLAP), or both?
What ratio of reads to writes do you expect in production?
What are your preferred programming languages?
Do you have a budget? If so, will it cover licenses and support contracts?
How strict are you with invalid data being sent to your database? (Ideally, you are very strict and do server-side data validation before persisting it to your database)
4. Scaling.
Consider a scenario where you realized that your database needs to extend its capacity and handle large amount of requests simultaneously, scaling can be done vertically or horizontally to achive your database related goals.
A. Vertical scaling
In vertical scaling resources are added to the existing system to meet the expectation, it is known as vertical scaling. e.g. Add or reduce the CPU or memory capacity of the existing machine.
Examples of databases that can be easily verticaly scaled- MySQL, Amazon RDS
Pros :-
Cost-effective – Upgrading a pre-existing server costs less than purchasing a new one. Additionally, you are less likely to add new backup and virtualization software when scaling vertically. Maintenance costs may potentially remain the same too.
Less complex process communication – When a single node handles all the layers of your services, it will not have to synchronize and communicate with other machines to work. This may result in faster responses.
Less complicated maintenance – Not only is maintenance cheaper but it is less complex because of the number of nodes you will need to manage.
Less need for software changes – You are less likely to change how the software on a server works or how it is implemented.
Cons:-
Higher possibility for downtime – Unless you have a backup server that can handle operations and requests, you will need some considerable downtime to upgrade your machine.
Single point of failure – Having all your operations on a single server increases the risk of losing all your data if a hardware or software failure was to occur.
Upgrade limitations – There is a limitation to how much you can upgrade a machine. Every machine has its threshold for RAM, storage, and processing power.
B. Horizontal scaling
The horizontal scaling approach, sometimes referred to as "scaling out," entails adding more machines to further distribute the load of the database and increase overall storage and/or processing power. There are two common ways to perform horizontal scaling — they include sharding, which increases the overall capacity of the system, and replication, which increases the availability and reliability of the system.
Examples of databases that can be easily horizontally scaled- Cassandra, MongoDB, Google Cloud Spanner
Pros:-
Scaling is easier from a hardware perspective – All horizontal scaling requires you to do is add additional machines to your current pool. It eliminates the need to analyze which system specifications you need to upgrade.
Fewer periods of downtime – Because you’re adding a machine, you don’t have to switch the old machine off while scaling. If done effectively, there may never be a need for downtime and clients are less likely to be impacted.
Increased resilience and fault tolerance – Relying on a single node for all your data and operations puts you at a high risk of losing it all when it fails. Distributing it among several nodes saves you from losing it all.
Increased performance – If you are using horizontal scaling to manage your network traffic, it allows for more endpoints for connections, considering that the load will be delegated among multiple machines.
Cons:-
Increased complexity of maintenance and operation – Multiple servers are harder to maintain than a single server is. Additionally, you will need to add software for load balancing and possibly virtualization. Backing up your machines may also become a little more complex. You will need to ensure that nodes synchronize and communicate effectively.
Increased Initial costs – Adding new servers is far more expensive than upgrading old ones.
Use vertical scaling when:
You’ve verified with your engineers and other stakeholders that increasing a machines capabilities, such CPUs and memory capacity, will deliver the price-performance level your workloads require
If you’re just starting out; you don’t know how consistent the traffic is or how many users you’ll get
Want to use your existing system internally and a cloud provider services for the bulk of customer-facing solutions
You know redundancy is not feasible or required to operate optimally
Upgrades are few and far between, so there is little downtime to worry about
You have a legacy app that doesn’t require distributed or high scalability
Use horizontal scaling when:
Providing high-quality service requires high performance
Backup machines are necessary to reduce single points of failure
You want more flexibility to configure your machines in different ways in order to increase efficiency, such as price-performance ratio
You need to run your application or services across different geographical locations at low latency
Updating, upgrading, and optimizing your system regularly is imperative — all without increasing downtime
You are sure that your usage, users, or traffic are consistently high or will be growing exponentially soon
You have the people and resources to buy, install, and maintain additional hardware and software
You are using a micro-services architecture or containerized applications, which achieve better performance on a distributed system
5. Performance
When it comes to database performance, it is all about the time it takes for a database to pass a query – latency. The lower the latency – the faster a read or write operation goes through. the other factors that affects it are network connection and query complexity.
A way to reduce latency in network connectivity is by hosting our application closer to our database, in the same region, for example. As for the query complexity – it’s closely related to the data types and schemas we are using and how “compatible” they are. we can expect low latency from a relational database when handling two-dimensional data that fits well into a row-column order. But once we need to process more data dimensions, our data transactions may get too hard for an RDBMS to operate fast. In such a case, we can shift our attention to NoSQL.
6. CAP Theorem.
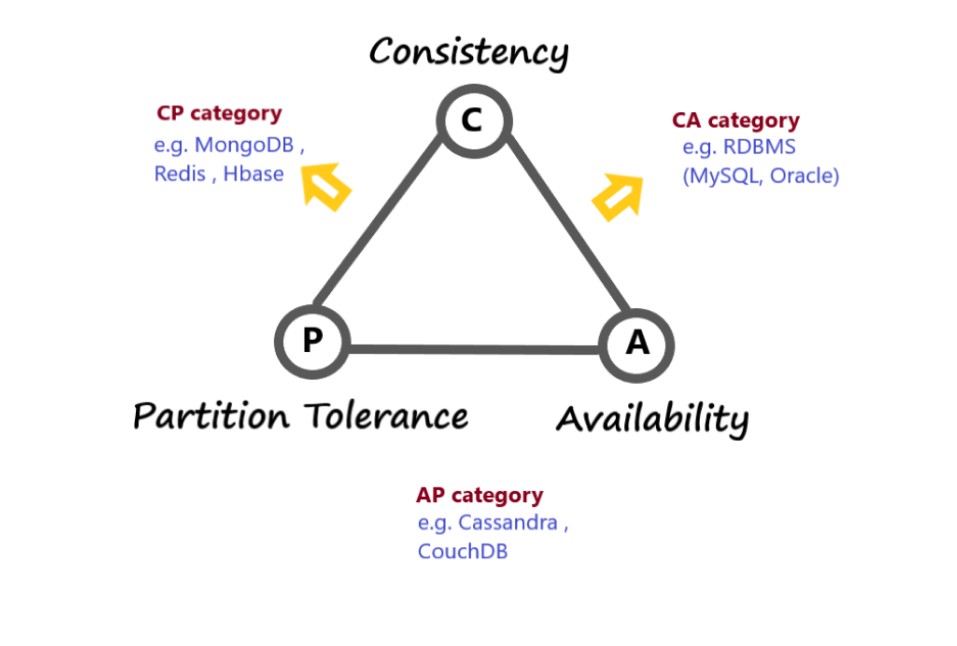
CAP stands for Consistency, Availability, and Partition tolerance. The theorem states that you cannot achieve all the properties at the best level in a single database, as there are natural trade offs between the items. You can only pick two out of three at a time and that totally depends on your prioritize based on your requirements.
Consistency.
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful.’
Availability.
Availability means that any client making a request for data gets a response, even if one or more nodes are down. Another way to state this—all working nodes in the distributed system return a valid response for any request, without exception.
Partition tolerance.
A partition is a communications break within a distributed system—a lost or temporarily delayed connection between two nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
8. Database selection based on CAP theorem.
CA database
These databases, as the name suggests utilize consistency and availability of data across all connected nodes. However, this means the system does not have partitional tolerance which means that a node failure can lead to unavailability of data.
This makes CA databases pretty much redundant since node failures are bound to occur in any type of connected system.
In some cases, databases do allow CA, most notably in SQL databases such as PostgreSQL which we will discuss as we move forward.
Now let’s look at the properties of CAP theorem and how they work together in various scenarios.
CP Database
These databases prioritize consistency and partitional tolerance between all connected nodes. This means that if a partition or node failure occurs, these particular nodes, also known as inconsistent nodes, will be turned off.
This is done to maintain the consistency of written data across all working nodes. Data is generally replicated across the primary nodes so if they fail, the secondary nodes step in. However, since availability isn’t prioritized, write operations are restricted till the primary node is rectified.
CP databases are NoSQL databases and asynchronously update themselves based on the primary node. MongoDB is an example of a NoSQL database management system (DBMS).
AP Database
AP databases prioritize availability during a partition or node failure. This means that if a node fails, it is still available for use. However, the data from these failed nodes will not be the most recent version.
Apache Cassandra, similar to MongoDB is a NoSQL database, but since it’s an AP database, it does not have a primary node and keeps all nodes available.
Once the partition is rectified, it allows the user to sync their data to maintain overall consistency.
Subscribe to my newsletter
Read articles from Rahul Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by