Fundamental Machine Learning Algorithms
 Sudhin Karki
Sudhin KarkiLinear Regression
It is a supervised learning algorithm used to predict continuous outcome based on number of input features.
It assumes a linear relationship between input features and output variable.
It tries to minimize the sum of squared difference between predicted and actual values.
$$Formula: y = mx + c$$
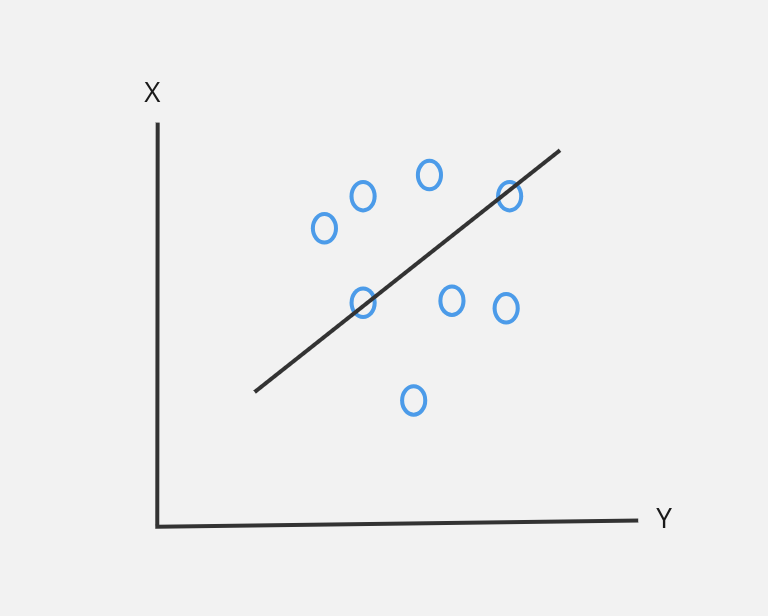
In the above figure, X is dependent variables and Y is independent variable.
Advantages:
- Provides coefficients that can be used to interpret feature importances.
Limitations:
Assumes linear relationship which may not be true for complex data.
Sensitive to outliers.
Example use cases:
Estimating sales on the basis of advertisement expenditures.
Predicting stock prices based on various financial indicators.
Logistic Regression
It is used for binary classification problems i.e. (0 or 1)
It predicts the probability of event that can occur based on number of predictor variables.
$$Formula: 1 / (1+e^{-(mx + c)})$$
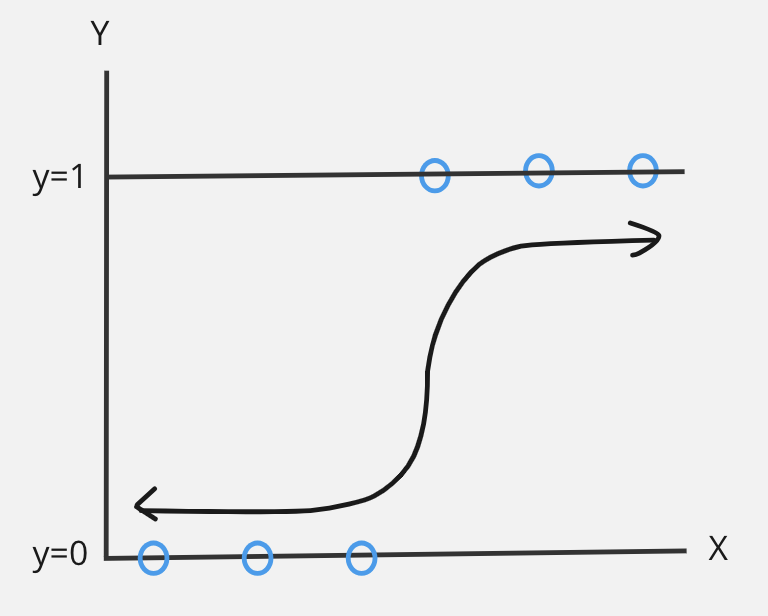
Advantages:
Efficient for binary classification tasks.
Can handle high dimensional data.
Limitations:
- May not perform well on highly non-linear data.
Example use cases:
Predicting whether a patient has a particular disease or not based on medical test results.
Predicting the likelihood of customer buying a product.
Decision Trees
Decision Trees are nothing but giant structure of nested if else conditions.
Decision trees are versatile hence can be used for both regression and classification tasks.
Decision trees makes decision by recursively splitting the data based on features.
Mathematically, Decision trees uses hyperplanes parallel to one of axes to cut data coordinate system.
For example:
Lets assume, Boys with age greater than 5 love to play cricket and age smaller than 5 love to play with toy cars. Girls love to study.
Then how decision trees works is:
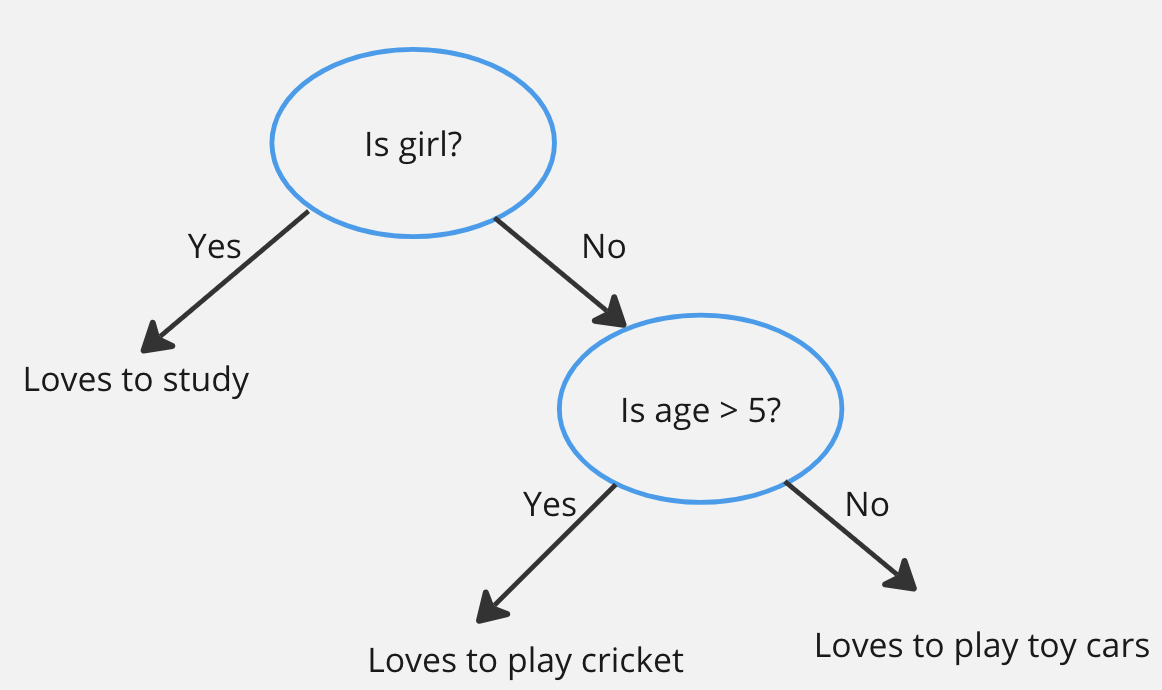
The splits(Is girl? , Is age > 5?) are determined to maximize information gain.
Our goal is to make set of data after split as pure as possible. The impurity in set of data is called entropy. The reduction of entropy is called information gain.
Advantages:
Can handle both categorical and numerical data.
Requires less data preprocessing (like normalization and scaling.)
Limitations:
Sensitive to noisy data.
Small variations in data can lead to totally different tree structure.
Example use cases:
Predicting whether a patient is at risk of certain disease on the basis of family history, age, lifestyle and so on.
Determining whether to play sports like cricket based on weather conditions such as humidity, wind speed, temperature and so on.
K-Nearest Neighbors
K-Nearest Neighbors(KNN) is a supervised learning algorithm which can be used for both classification and regression tasks.
For classification, KNN classifies the new data point based on the classes of its k nearest neighbors based on distance metrics(e.g. Euclidean distance). The class with the highest frequency determine the classification.
For regression, KNN computes the average of the k nearest neighbors points.
Shortly, this algorithm memorizes the entire dataset and then predicts the class or value of the new point inserted according to its k nearest neighbors.
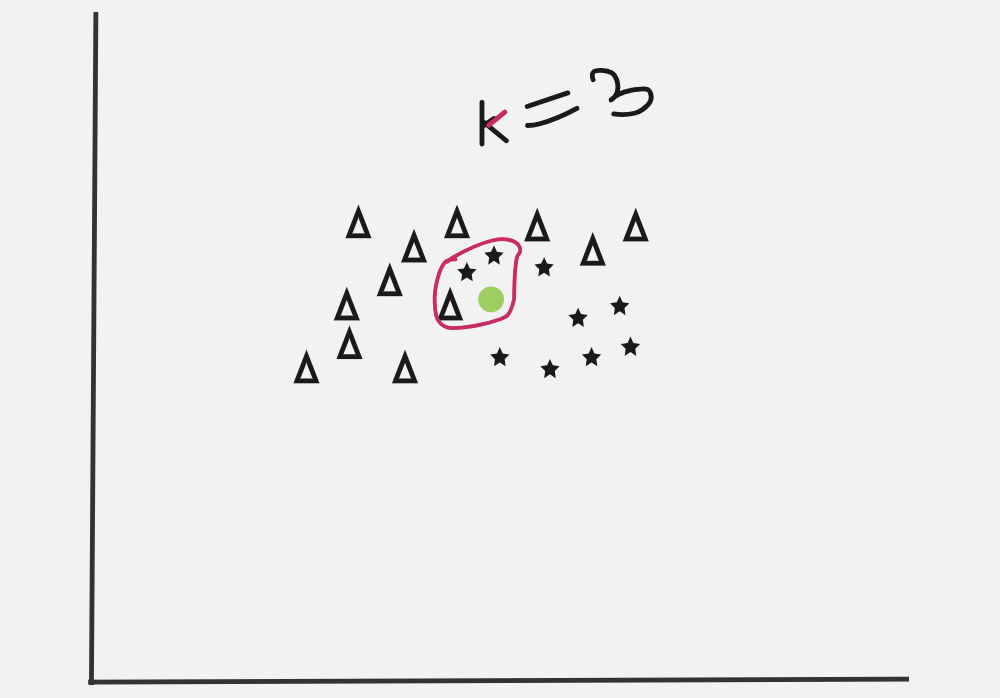
Let k=3, then the nearest three neighbors for green dot calculated using certain distance metrics is enclosed in red circle.
The frequencies are: star -> 2 and triangle -> 1.
Hence, the class of green dot is determined to be star.
Advantages:
No training phase, the model memorizes entire dataset.
Effective when decision boundaries are complex and non-linear.
Limitations:
Computationally expensive for large datasets.
Performance can be affected by the choice of distance metrics and value of k.
Example use cases:
It can be used in identification of handwritten digits in digits recognition systems.
It is used for anomaly detection(e.g. unusual patterns in network traffics, unusual amount withdrawal using credit card, etc.).
Conclusion
These are the overview of fundamental ML algorithms in supervised learning. There are other advanced supervised ML algorithms such as Support Vector Machines (SVMs), Random Forests, Gradient Boosting (XGBoost, LightGBM). Make sure to know the advantages and limitations of each algorithms.
Subscribe to my newsletter
Read articles from Sudhin Karki directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sudhin Karki
Sudhin Karki
I am a Machine Learning enthusiast with a motivation of building ML integrated apps. I am currently exploring the groundbreaking ML / DL papers and trying to understand how this is shaping the future.