A sophisticated instagram scraper – A case study of Instadata
 Davide Wiest
Davide Wiest

Photo by Fabio Ballasina on Unsplash
About
Instadata is my own personal project to gather from instagram to use in future data science. I also developed a web version (called Instadata Web Wrapper) for ease of use, and to control it remotely.
Problem Statement & Solution
I – and many others – want quality data for data-science projects. A scraper for instagram would be a great solution for that. It should be able to capture all useful data and extract additional data points, such as links from the user‘s biography. This data can later be used for research purposes, e.g. training a machine learning model to recommend common email addresses for a given name.
My Role in the Projects
Mainly backend Developer. A bit of front-end too.
Work Process
- Building the Fundamentals (Database module, Scraper modules, core functions)
- Adding parser and analytics
- Wrapping the program in a web app
Data Journey
- Scraping data from instagram pages
- Validating the user is not a bot
- Deleting unnecessary data points
- Filtering out additional data fields (e. g. a list of found links)
- Saving the data in the database
Technologies used
Database: MongoDB (pymongo module)
Main language: Python
Web app: Django + Django REST Framework
Locator service: Nominatim (locator package)
Language parsing: NLTK Package
Additional data extraction: Regex
Instagram scraper modules: Instagram_private_api, instagrapi
Research & Sketches
Basic data pipeline sketch
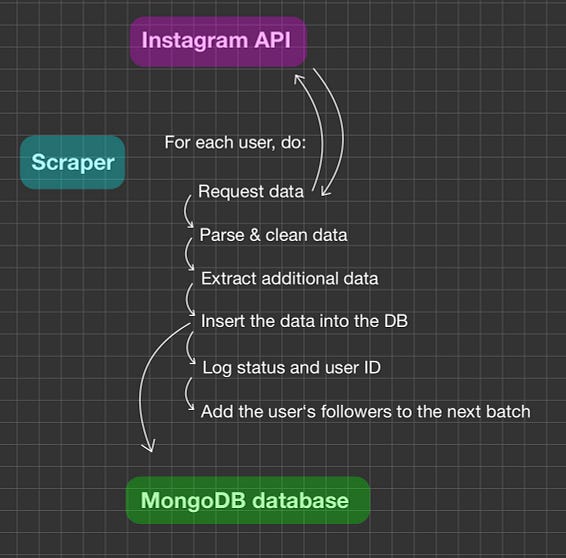
Research
- Testing different scraper libraries
- Stress testing instagrams api to figure out the maximal possible frequency under which to scrape (it’s roughly 1 account every 8 seconds)
Data journey/data pipeline
- Scraping data from instagram pages
- Validating the user is not a bot
- Removing unnecessary data points
- Parsing data (E.g. text normalization)
- Filtering out additional data fields (e. g. a list of found links)
- Determining quality of data found
- If high quality: Scrape the user‘s previous posts
- Saving the data in the database
Scalability
Instagram rate limits url requests. To counteract the consequent sleep time after each request, the scraper should be scalable, thus allow for multiple accounts to scrape with at once. Instadata tries to log into every given account and then cycle through this list of accounts, at the same time dividing the sleeping time after each request by the number of accounts.
Scraping pattern avoidance
In order to not be picked up by the platforms pattern-recognizing anti-scraping measures, instadata has random sleep states that are in the range of 1.5–2.5 hours. Additionally, I found that instagram rate limits accounts at around 2 am. That‘s why the scraper will plan another sleep state from roughly 1–3 am.
Furthermore, since the accounts used for each request are cycled around, the scraping patterns will seem random and harder to predict.
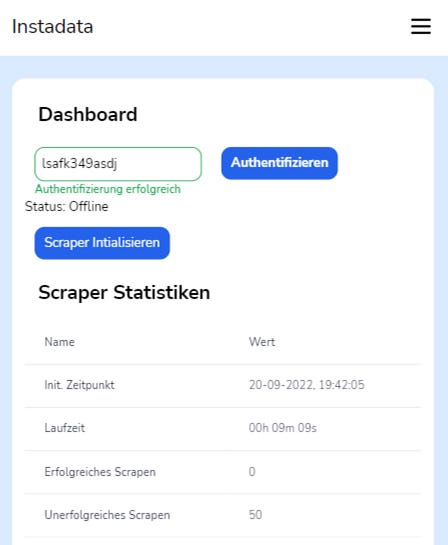
The final version
Scraper stats page
Scraper error log page
You can see the final versions github repository here. If you are interested, this is the preceding terminal version (which is more stable).
Result
Instadata can make the most out of the data it scrapes, and that’s why I am very happy with how the scraper turned out. Since I‘m currently learning data science concepts, I’m sure it will help me in the time coming, especially teaching me how to work with my own datasets.
Info
If you want to use this scraper, there are a number of things required before starting. They are documented in the readme of instadatas github repository. Since this scraper is complex, its stable-ness will depent on you, as you are the one adjusting it to your usage profile.
Learnings
- Python‘s feature-rich libraries make it great for data science and engineering.
- Relying on too much libraries threatens the scraper‘s independence. A possible risk to consider is the deprecation of one of these libs.
- Beware of your countries scraping-regulations. In some countries it is legal for research purposes only.
Next Steps
- Check out my website. I‘m open to freelancing requests
- You can see the project‘s repo here
- I try to write regularly, and have a few other interesting case studies. If you want, you can check out my medium profile.

A sophisticated instagram scraper – A case study of Instadata was originally published in The Modern Scientist on Medium, where people are continuing the conversation by highlighting and responding to this story.
Subscribe to my newsletter
Read articles from Davide Wiest directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Davide Wiest
Davide Wiest
I'm a German-Croatian student & developer. I primarly like to build systems or products that make life easier.