Open-Source Prompt-Tuned Encoder for Token Classification
 Steve Ka
Steve KaRelevance in the Current ML Landscape
Revolutionizing NLP: Knowledgator's Breakthrough in Encoder-Based Models for Zero-Shot Universal Token Classification
In the dynamic realm of Natural Language Processing (NLP), Knowledgator, a pioneering tech entity, has emerged as a game-changer with its introduction of open-source encoder-based models for Zero-Shot Universal Token Classification (UTC). This innovative approach marks a significant shift from the prevailing focus on decoder architectures, positioning encoders at the forefront of information extraction tasks.
Understanding the Encoder Edge in NLP
Encoders, unlike decoders which are tailored for generating text, excel in interpreting and encoding information. This capability makes them more adept at comprehending context and extracting pertinent information from text. Knowledgator's encoder-focused models leverage self-attention mechanisms, enabling a comprehensive understanding of textual relationships. This advancement addresses the lag in encoder innovation since the development of BERT by Google in 2018 and its subsequent optimizations by Facebook and Microsoft.
Introducing Knowledgator's Encoder Models
Knowledgator has unveiled a suite of models, including the UTC-DeBERTa (small, large, and base) and UTC-T5-large, each fine-tuned on approximately 1 billion tokens. These models stand out for their focus on encoders, prompt-based design, versatility in NLP tasks, and efficiency in zero-shot settings. They excel in a variety of tasks, including Named Entity Recognition (NER), Question Answering, and more experimental applications like Text Cleaning and Relation Extraction.
Zero-Shot Learning and Token Classification
A pivotal feature of these models is their proficiency in Zero-Shot Learning, where they accurately perform tasks without specific prior training. For example, in a zero-shot NER scenario, the models can identify entities like "Tesla" and "Berlin" in sentences about domains they haven't been explicitly trained on. This capability stems from the models' comprehensive language understanding and entity recognition.
Practical Applications and Future Prospects
The practical applications of these models are vast, extending from corporate customer service enhancements to academic research facilitation. They promise to revolutionize tasks such as coreference resolution and text cleaning, previously challenging for smaller models. Their potential in relation extraction and summarization points towards a future where complex Information Extraction tasks become more streamlined and efficient.
Usage and Accessibility
Knowledgator encourages users to test these models in their Space on Hugging Face, an interactive platform for machine learning applications. The models are designed for ease of integration into various applications, using a simple prompt-based approach.
Concluding Thoughts
Knowledgator's introduction of encoder-based models for Zero-Shot Universal Token Classification is not just a step forward for open-source NLP; it represents a paradigm shift in the field. These models demonstrate the untapped potential of encoders in efficiently handling diverse NLP tasks, challenging the dominance of decoder architectures and paving the way for more generalized and versatile machine learning models.
The machine learning community needs new, more effective encoder-based models, and we provided them with a universal solution that covers many Information Extraction tasks. Please read about the solutions, their application, and usage guidance below.
Understanding Token Classification, Zero-Shot Learning, and Encoder Architectures
Before delving into the models themselves, it’s essential to clarify some key concepts:
Token Classification: This involves assigning labels to individual tokens (like words or subwords) in a text. The tasks usually solved with Token Classification are Named Entity Recognition (NER), Question Answering, and part-of-speech tagging. However, we demonstrated the universality of this technology by applying it to Text Cleaning, Relation Extraction, Coreference Resolution, and Text Summarization (some applications are still experimental, yet promising).
Zero-Shot Learning: In the context of NLP, this refers to the model’s ability to perform tasks it hasn’t explicitly been trained on accurately. It’s a step towards building more generalized and versatile models.
A simple example of zero-shot Named Entity Recognition (NER) involves using a model to identify entities in a sentence that it has not been explicitly trained to recognize. For instance, consider the sentence:
“Tesla plans to buy batteries from LG Chem for its factory in Berlin.”
In a zero-shot NER scenario, a model that has not been specifically trained on automotive or technology-related texts would still be able to identify:
“Tesla” as an Organization
“LG Chem” as an Organization
“Berlin” as a Location
This capability arises from the model’s general understanding of language and entity types, enabling it to recognize entities in contexts or domains it hasn’t been explicitly trained on. The model leverages its broad knowledge base and contextual understanding acquired during its initial training on diverse datasets.
3. Encoder Architectures: Unlike decoders that generate text, encoders are better designed to understand or encode information. They’re adept at comprehending context and content, such as extracting relevant information from text. In contrast, decoders are designed to generate output based on given inputs, focusing more on production rather than analysis. This fundamental difference in architecture and purpose makes encoders more efficient and effective for information extraction tasks.
Our Models: Features and Capabilities
We’ve launched a collection of models based on two distinct architectures: T5 and DeBERTa. Each model has been fine-tuned on approximately 1 billion tokens, encompassing public datasets and those annotated by our team. The lineup includes:
UTC-DeBERTa-small (142M parameters)
UTC-DeBERTa-large (445M parameters)
UTC-DeBERTa-base (184M parameters)
UTC-T5-large (391M parameters)
These models stand out for several reasons:
Encoder Focus: In an era leaning towards decoders, focusing on encoders allows us to tackle NLP tasks from a different angle, with a strong emphasis on understanding and analyzing text to yield better performance at lower cost;
Prompt-Based Design: Mirroring the simplicity of popular LLMs, these models use prompts in Natural Language to guide their operation, simplifying their integration into various applications.
Versatility in NLP Tasks: From NER to question answering, and even in developing areas like relation extraction and text summarization, these models demonstrate a broad scope of utility. Our research corroborates the idea that numerous tasks can be solved with token classification. For our time, it’s just the beginning;
Efficiency: Despite their relatively smaller size, these models are designed to outperform larger counterparts in zero-shot settings.
Practical Applications and Future Prospects
The practical applications for these models are extensive. In the corporate sector, they can enhance customer service through user query categorization and automated FAQs. In academia, they can aid in research by extracting and summarising information from large volumes of text by identifying genes, proteins, and diseases to build knowledge graphs for future inference and drug discovery. Moreover, their generalization to applications like relation extraction and summarisation points to a future where complex Information Extraction tasks become more accessible and efficient.
These models, particularly in zero-shot settings, offer a new paradigm in handling tasks like coreference resolution and text cleaning, areas traditionally challenging for smaller models. Their performance uncovers the forgotten potential of encoder architectures in efficiently handling diverse NLP tasks, even with limited training on specific datasets.
In the following sections, we will provide you with guidance on using our models for these tasks:
Named entity recognition (NER);
Question answering;
Relation extraction;
Coreference resolution;
Text cleaning;
Summarisation;
How to test
Before downloading the models, you can quickly test them in our Space on Hugging Face!
For those who don’t know what the Space is: A Space on Hugging Face is a platform feature that allows users to create, share, and collaborate on machine learning applications. Our Space is an interactive web-based demo where you can conveniently test the NER capabilities of one of our UTC models.
We recommend using the model with transformers ner pipeline:
The code may seem too long, but don’t worry, just copy-paste!
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
def process(text, prompt, treshold=0.5):
"""
Processes text by preparing prompt and adjusting indices.
Args:
text (str): The text to process
prompt (str): The prompt to prepend to the text
Returns:
list: A list of dicts with adjusted spans and scores
"""
# Concatenate text and prompt for full input
input_ = f"{prompt}\n{text}"
results = nlp(input_) # Run NLP on full input
processed_results = []
prompt_length = len(prompt) # Get prompt length
for result in results:
# check whether score is higher than treshold
if result['score']<treshold:
continue
# Adjust indices by subtracting prompt length
start = result['start'] - prompt_length
# If indexes belongs to the prompt - continue
if start<0:
continue
end = result['end'] - prompt_length
# Extract span from original text using adjusted indices
span = text[start:end]
# Create processed result dict
processed_result = {
'span': span,
'start': start,
'end': end,
'score': result['score']
}
processed_results.append(processed_result)
return processed_results
tokenizer = AutoTokenizer.from_pretrained("knowledgator/UTC-DeBERTa-small")
model = AutoModelForTokenClassification.from_pretrained("knowledgator/UTC-DeBERTa-small")
nlp = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy = 'first')
To use the model for zero-shot named entity recognition, we recommend to utilize the following prompt:
prompt = """Identify the following entity classes in the text:
computer
Text:
"""
text = """Apple was founded as Apple Computer Company on April 1, 1976, by Steve Wozniak, Steve Jobs (1955–2011) and Ronald Wayne to develop and sell Wozniak's Apple I personal computer.
It was incorporated by Jobs and Wozniak as Apple Computer, Inc. in 1977. The company's second computer, the Apple II, became a best seller and one of the first mass-produced microcomputers.
Apple went public in 1980 to instant financial success."""
results = process(text, prompt)
print(results)
To try the model in question answering, just specify the question and text passage:
question = """Who are the founders of Microsoft?"""
text = """Microsoft was founded by Bill Gates and Paul Allen on April 4, 1975 to develop and sell BASIC interpreters for the Altair 8800.
During his career at Microsoft, Gates held the positions of chairman, chief executive officer, president and chief software architect, while also being the largest individual shareholder until May 2014."""
input_ = f"{question} {text}"
results = process(text, question)
print(results)
For the text cleaning, please specify the following prompt, it will recognize the part of the text that should be erased:
prompt = """Clean the following text extracted from the web matching not relevant parts:"""
text = """The mechanism of action was characterized using native mass spectrometry, the thermal shift-binding assay, and enzymatic kinetic studies (Figure ). In the native mass spectrometry binding assay, compound 23R showed dose-dependent binding to SARS-CoV-2 Mpro, similar to the positive control GC376, with a binding stoichiometry of one drug per monomer (Figure A).
Similarly, compound 23R showed dose-dependent stabilization of the SARS-CoV-2 Mpro in the thermal shift binding assay with an apparent Kd value of 9.43 μM, a 9.3-fold decrease compared to ML188 (1) (Figure B). In the enzymatic kinetic studies, 23R was shown to be a noncovalent inhibitor with a Ki value of 0.07 μM (Figure C, D top and middle panels). In comparison, the Ki for the parent compound ML188 (1) is 2.29 μM.
The Lineweaver–Burk or double-reciprocal plot with different compound concentrations yielded an intercept at the Y-axis, suggesting that 23R is a competitive inhibitor similar to ML188 (1) (Figure C, D bottom panel). Buy our T-shirts for the lowerst prices you can find!!! Overall, the enzymatic kinetic studies confirmed that compound 23R is a noncovalent inhibitor of SARS-CoV-2 Mpro."""
results = process(text, prompt)
print(results)
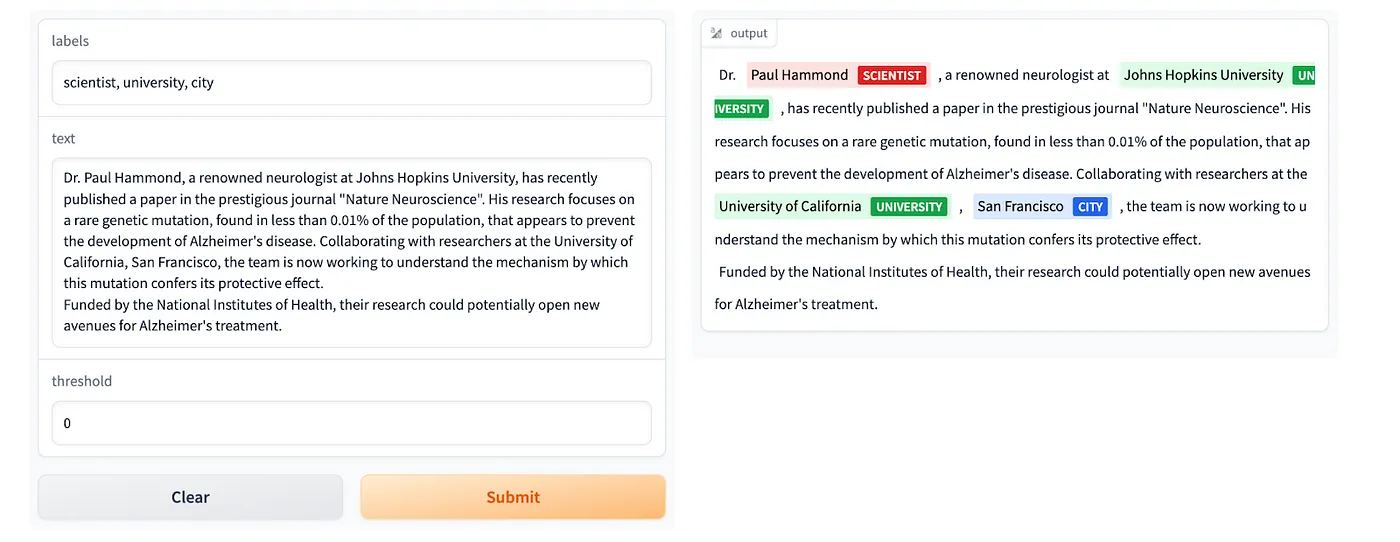
It’s possible to use the model for relation extraction, in N*C operations, it extracts all relations between entities, where N — number of entities and C — number of classes:
rex_prompt="""
Identify target entity given the following relation: "{}" and the following source entity: "{}"
Text:
"""
text = """Dr. Paul Hammond, a renowned neurologist at Johns Hopkins University, has recently published a paper in the prestigious journal "Nature Neuroscience". """
entity = "Paul Hammond"
relation = "worked at"
prompt = rex_prompt.format(relation, entity)
results = process(text, prompt)
print(results)
To find similar entities in the text, consider the following example:
ent_prompt = "Find all '{}' mentions in the text:"
text = """Several studies have reported its pharmacological activities, including anti-inflammatory, antimicrobial, and antitumoral effects. The effect of E-anethole was studied in the osteosarcoma MG-63 cell line, and the antiproliferative activity was evaluated by an MTT assay. It showed a GI50 value of 60.25 μM with apoptosis induction through the mitochondrial-mediated pathway. Additionally, it induced cell cycle arrest at the G0/G1 phase, up-regulated the expression of p53, caspase-3, and caspase-9, and down-regulated Bcl-xL expression. Moreover, the antitumoral activity of anethole was assessed against oral tumor Ca9-22 cells, and the cytotoxic effects were evaluated by MTT and LDH assays. It demonstrated a LD50 value of 8 μM, and cellular proliferation was 42.7% and 5.2% at anethole concentrations of 3 μM and 30 μM, respectively. It was reported that it could selectively and in a dose-dependent manner decrease cell proliferation and induce apoptosis, as well as induce autophagy, decrease ROS production, and increase glutathione activity. The cytotoxic effect was mediated through NF-kB, MAP kinases, Wnt, caspase-3 and -9, and PARP1 pathways. Additionally, treatment with anethole inhibited cyclin D1 oncogene expression, increased cyclin-dependent kinase inhibitor p21WAF1, up-regulated p53 expression, and inhibited the EMT markers."""
entity = "anethole"
prompt = ent_prompt.format(entity)
results = process(text, prompt)
print(results)
Currently, summarisation with the UTC model works purely; however, we want to highlight the potential of such an approach and use cases when it’s beneficial:
prompt = "Summarize the following text, highlighting the most important sentences:"
text = """Apple was founded as Apple Computer Company on April 1, 1976, by Steve Wozniak, Steve Jobs (1955–2011) and Ronald Wayne to develop and sell Wozniak's Apple I personal computer. It was incorporated by Jobs and Wozniak as Apple Computer, Inc. in 1977. The company's second computer, the Apple II, became a best seller and one of the first mass-produced microcomputers. Apple went public in 1980 to instant financial success. The company developed computers featuring innovative graphical user interfaces, including the 1984 original Macintosh, announced that year in a critically acclaimed advertisement called "1984". By 1985, the high cost of its products, and power struggles between executives, caused problems. Wozniak stepped back from Apple and pursued other ventures, while Jobs resigned and founded NeXT, taking some Apple employees with him.
Apple Inc. is an American multinational technology company headquartered in Cupertino, California. Apple is the world's largest technology company by revenue, with US$394.3 billion in 2022 revenue. As of March 2023, Apple is the world's biggest company by market capitalization. As of June 2022, Apple is the fourth-largest personal computer vendor by unit sales and the second-largest mobile phone manufacturer in the world. It is considered one of the Big Five American information technology companies, alongside Alphabet (parent company of Google), Amazon, Meta Platforms, and Microsoft.
As the market for personal computers expanded and evolved throughout the 1990s, Apple lost considerable market share to the lower-priced duopoly of the Microsoft Windows operating system on Intel-powered PC clones (also known as "Wintel"). In 1997, weeks away from bankruptcy, the company bought NeXT to resolve Apple's unsuccessful operating system strategy and entice Jobs back to the company. Over the next decade, Jobs guided Apple back to profitability through a number of tactics including introducing the iMac, iPod, iPhone and iPad to critical acclaim, launching the "Think different" campaign and other memorable advertising campaigns, opening the Apple Store retail chain, and acquiring numerous companies to broaden the company's product portfolio. When Jobs resigned in 2011 for health reasons, and died two months later, he was succeeded as CEO by Tim Cook"""
results = process(text, prompt)
print(results)
Join our Discord to contribute or discuss https://discord.com/invite/KJ4nQ7mD5z
Conclusion
The introduction of Knowledgator’s prompt-tuned Encoder Models for Zero-Shot Token Classification represents a significant leap in Natural Language Processing (NLP), particularly in open-source environments. Based on T5 and DeBERTa architectures, these models excel in understanding text and relationships between words, addressing a gap in a field traditionally dominated by decoder architectures.
These models demonstrate remarkable capability in Zero-Shot Learning, allowing them to perform tasks without specific prior training, as seen in Named Entity Recognition (NER), Q&A, REX, and others. With high-quality data and effective training, they outperform much larger encoders and decoders in numerous tasks and domains, corroborating the significance of developing the new fundamental encoder-based model. Just as modern decoders, like GPT4, are universal text generation tools, such a model may solve limitless tasks related to information extraction.
Subscribe to my newsletter
Read articles from Steve Ka directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by