AI for Web Devs: AI Image Generation
 Austin Gil
Austin Gil
Welcome back to this series where we are learning how to integrate AI products into web application.
In this post, we are going to use AI to generate images. Before we get to that, let’s add a dialog component to our app. This is a modal-like pop-up designed to show content and be dismissed with the mouse or keyboard.
Create A Dialog Component
Before showing an image, we need a place to put it. I think it would be nice to have a dialog that pops up to showcase the image. This is a good opportunity to spend more time with Qwik components.
By convention, our new component should go in the ./src/components folder. I’ll call mine Dialog.jsx (or .tsx if you prefer TypeScript). A Qwik component file should have a default export of a Qwick component. To create one, we use the component$ function from @builder.io/qwik. This function takes a function component that returns JSX:
import { component$ } from "@builder.io/qwik";
export default component$((props) => {
return (
<div>
<!-- component markup -->
</div>
)
})
At the moment, it’s not very useful. Let’s plan out the API design for this dialog. It should have the following characteristics:
Opened by clicking on a button.
Can be opened programmatically from the parent.
Closed by pressing Esc key.
Closed by clicking the dialog background.
Can be closed programmatically from the parent.
HTML has a <dialog> element which is great, but it doesn’t quite offer the API that I’m looking for. With a little bit of work, we can fill in the gaps.
Let’s start with a component that provides a <button> element for controlling the dialog and the <dialog> element that will contain any content you put inside. Clicking the button should trigger the dialog.showModal() method. Clicking outside the dialog should trigger the dialog.close() method. Pressing the Esc key closes the dialog already, so that’s sorted. To trigger the dialog methods, we need access to the DOM node, which we can get by using a ref and a signal. In our dialog component, we can add content using a <Slot>, a flexible space inside the dialog where you can put content. We should also provide a btnText prop, to allow for customization of the text on the button that opens the dialogue.
Here’s what I have so far:
import { component$, useSignal, Slot } from "@builder.io/qwik";
export default component$(({ btnText }) => {
const dialogRef = useSignal()
return (
<div>
<button onClick$={() => dialogRef.value.showModal()}>
{btnText}
</button>
<dialog
ref={dialogRef}
onClick$={(event) => {
if (event.target.localName !== 'dialog') return
dialogRef.value.close()
}}
>
<div class="p-2">
<Slot></Slot>
</div>
</dialog>
</div>
)
})
Note the additional <div> inside the <dialog>. This lets me add some padding, but more importantly, it helps me track whether a click on the dialog happened on the background (the dialog element) or on the content (the div and children). This lets us close the dialog only when the background is clicked.
That gets us some basic functionality, but for my use case, I want to be able to programmatically open the dialog from the parent, not just when the toggle button is clicked. For that, we need a small refactor.
To control the dialog from a parent, we need to add a new prop and trigger the dialog methods as it changes. Rather than repeat the open/close functionality for internal and external changes let’s create a local state with useStore() to track whether the dialog should be shown or not. Then we can simply toggle the state and respond to those changes using a Qwik task (it’s like useEffect in React). If the open prop from the parent changes, we need to respond to that change using another task, but this time we’ll use useVisibleTask$(). We also need to provide a way for the parent component to be aware of changes to the dialog’s visibility. We can do that by providing a custom onClose$ prop that will call the function whenever the dialog closes. And lastly, if we’re providing programmatic control from the parent, we may want to provide a way to hide the <button>.
import { component$, useSignal, Slot, useStore, useTask$, useVisibleTask$ } from "@builder.io/qwik";
export default component$(({ btnText, open, onClose$ }) => {
const dialogRef = useSignal()
const state = useStore({
isOpen: false,
})
useTask$(({ track }) => {
track(() => state.isOpen)
const dialog = dialogRef.value
if (!dialog) return
if (state.isOpen) {
dialog.showModal()
} else {
dialog.close()
onClose$ && onClose$()
}
})
useVisibleTask$(({ track }) => {
track(() => open)
state.isOpen = open || false
})
return (
<div>
{btnText && (
<button onClick$={() => state.isOpen = true}>
{btnText}
</button>
)}
<dialog
ref={dialogRef}
onClick$={(event) => {
if (event.target.localName !== 'dialog') return
state.isOpen = false
}}
>
<div class="p-2">
<Slot></Slot>
</div>
</dialog>
</div>
)
})
This is a lot better, but there’s still a little work to do. I like to make sure my components are accessible and typed. In this case, since we’re using a button to control the visibility of the dialog, it makes sense to add aria-controls and aria-expanded attributes to the button. To connect them to the dialog, the dialog needs an ID, which we can either take from the props or dynamically generate. Lastly, pressing escape will close the dialog, but we also need to track the dialog’s native "close" event by attaching an onClose$ handler.
Here is my finished component, including JSDoc type definitions:
import {component$, useSignal, Slot, useStore, useTask$, useVisibleTask$ } from "@builder.io/qwik";
import { randomString } from "~/utils.js";
/**
* @typedef {HTMLAttributes<HTMLDialogElement>} DialogAttributes
*
* @type {Component<DialogAttributes & {
* toggle: string|false,
* open?: Boolean,
* onClose$?: import('@builder.io/qwik').PropFunction<() => any>
* }>}
*/
export default component$(({ toggle, open, onClose$, ...props }) => {
const id = props.id || randomString(8)
const dialogRef = useSignal()
const state = useStore({
isOpen: false,
})
useTask$(({ track }) => {
track(() => state.isOpen)
const dialog = dialogRef.value
if (!dialog) return
if (state.isOpen) {
dialog.showModal()
} else {
dialog.close()
onClose$ && onClose$()
}
})
useVisibleTask$(({ track }) => {
track(() => open)
state.isOpen = open || false
})
return (
<div>
{toggle && (
<button aria-controls={id} aria-expanded={state.isOpen} onClick$={() => state.isOpen = true}>
{toggle}
</button>
)}
<dialog
ref={dialogRef}
id={id}
onClick$={(event) => {
if (event.target.localName !== 'dialog') return
state.isOpen = false
}}
onClose$={() => state.isOpen = false}
{...props}
>
<div class="p-2">
<Slot></Slot>
</div>
</dialog>
</div>
)
})
Cool! Now that we have a working dialog component, we need to put something in it.
Generate AI Images with OpenAI
Once the AI has determined a winner between opponent1 and opponent2, it would be cool to offer an image of them in combat. So why not add a button that says “Show me” after the results are available?
After the text in the template, we could add a conditional like this:
{state.winner && (
<button>
Show me
</button>
)}
Awesome! It’s just too bad it doesn’t do anything…
To actually generate the AI image, we need to make another API request to OpenAI, which means we need another API endpoint in our backend. We’ve already assigned a request handler to the current route. Let’s add a new route to handle GET requests to /ai-image by adding a new file in /src/routes/ai-image/index.js.
In many cases, a new route may need to return HTML from the server to generate a page. That’s not the case for this route. This will only ever return JSON, so it doesn’t need to be a JSX file or return a component.
Instead, we can export a custom middleware like we did for post requests on the first page. To do that, we create a named export called onGet that can look something like this:
export const onGet = async (requestEvent) => {
requestEvent.send(200, JSON.stringify({ some: 'data' }))
}
Now, to get the route working, we need to do the following:
Grab opponent1 and opponent2 from the request (we’ll use query parameters).
Use the opponents to construct a prompt using LangChain templates.
Create a body for the OpenAI API request containing the prompt and the image size we want (I’ll use
"512x512").Create the authenticated HTTP request to OpenAI.
Respond to the initial request with the URL of the generated image.
For more details on working with images through OpenAI, refer to their documentation.
Here’s how my implementation looks:
import { PromptTemplate } from 'langchain/prompts'
const mods = [
'cinematic',
'high resolution',
'epic',
];
const promptTemplate = new PromptTemplate({
template: `{opponent1} and {opponent2} in a battle to the death, ${mods.join(', ')}`,
inputVariables: ['opponent1', 'opponent2']
})
/** @type {import('@builder.io/qwik-city').RequestHandler} */
export const onGet = async (requestEvent) => {
const OPENAI_API_KEY = requestEvent.env.get('OPENAI_API_KEY')
const opponent1 = requestEvent.query.get('opponent1')
const opponent2 = requestEvent.query.get('opponent2')
const prompt = await promptTemplate.format({
opponent1: opponent1,
opponent2: opponent2
})
const body = {
prompt: prompt,
size: '512x512',
}
const response = await fetch('https://api.openai.com/v1/images/generations', {
method: 'post',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${OPENAI_API_KEY}`,
},
body: JSON.stringify(body)
})
const results = await response.json()
requestEvent.send(200, JSON.stringify(results.data[0]))
}
It’s worth noting that the response from OpenAI should look something like this:
{
"created": 1589478378,
"data": [
{
"url": "https://..."
},
{
"url": "https://..."
},
]
}
Also worth mentioning is the lack of validation for the opponents. It’s always a good idea to validate user input before processing it. Why don’t you try addressing that as an additional challenge?
Provide AI Images with Art Direction
In the code example above, you may have noticed the mods array that gets joined and appended to the end of the prompt. This is worth a callout.
Generative images are tricky because the same prompt can return drastically different results. You might get a cartoon or an oil painting or a sketch. So it’ important to include a couple of hints to the AI to match the aesthetic of your application.
I found that using an array with several different options allowed me to easily toggle off various features. In fact, in my actual project, I keep a much longer list of options, organized by style, format, quality, and effect.
const mods = [
/** Style */
// 'Abstract',
// 'Academic',
// 'Action painting',
// 'Aesthetic',
// 'Angular',
// 'Automatism',
// 'Avant-garde',
// 'Baroque',
// 'Bauhaus',
// 'Contemporary',
// 'Cubism',
// 'Cyberpunk',
// 'Digital art',
// 'photo',
// 'vector art',
// 'Expressionism',
// 'Fantasy',
// 'Impressionism',
// 'kiyo-e',
// 'Medieval',
// 'Minimal',
// 'Modern',
// 'Pixel art',
// 'Realism',
// 'sci-fi',
// 'Surrealism',
// 'synthwave',
// '3d-model',
// 'analog-film',
// 'anime',
// 'comic-book',
// 'enhance',
// 'fantasy-art',
// 'isometric',
// 'line-art',
// 'low-poly',
// 'modeling-compound',
// 'origami',
// 'photographic',
// 'tile-texture',
/** Format */
// '3D render',
// 'Blender Model',
// 'CGI rendering',
'cinematic',
// 'Detailed render',
// 'oil painting',
// 'unreal engine 5',
// 'watercolor',
// 'cartoon',
// 'anime',
// 'colored pencil',
/** Quality */
'high resolution',
// 'high-detail',
// 'low-poly',
// 'photographic',
// 'photorealistic',
// 'realistic',
/** Effects */
// 'Beautiful lighting',
// 'Cinematic lighting',
// 'Dramatic',
// 'dramatic lighting',
// 'Dynamic lighting',
'epic',
// 'Portrait lighting',
// 'Volumetric lighting',
];
I’ve also found that it’s better to include these modifiers at the end of the prompt, otherwise they can be forgotten.
Request an AI-Generated Image
Now that our endpoint is ready, we can start using it. We need to send an HTTP request with query parameters including opponent1 and opponent2. We can pull those values from the <textarea>s on demand, but I prefer to maintain some reactive state that gets updated any time a user types into the <textarea>s .
Let’s modify our state to include properties for opponent1 and opponent2:
const state = useStore({
isLoading: false,
text: '',
winner: '',
opponent1: '',
opponent2: '',
})
Next, let’s add an onInput$ event handler that will update the state. The event handler should probably also clear any previous text results and winners. Note that we need to do this for both inputs.
<Input
label="Opponent 1"
name="opponent1"
value={state.opponent1}
class={{
rainbow: state.winner === 'opponent1'
}}
onInput$={(event) => {
state.winner = ''
state.text = ''
state.opponent1 = event.target.value
}}
/>
Now that we have the values conveniently available, we can construct the HTTP request. We could do this when the “Show me” button is clicked, but we already made the jsFormSubmit function in the third post of the series. Might as well reuse it. All it needs is a <form> with the data to send.
Let’s create a form that submits to our /ai-image route, prevents the default behavior, and submits the data with jsFormSubmit instead. We can use hidden inputs to put the data in the form without impacting the UI.
{state.winner && (
<form
action="/ai-image"
preventdefault:submit
onSubmit$={async (event) => {
const form = event.target
console.log(await jsFormSubmit(form))
}}
class="mt-4"
>
<input
type="hidden"
name="opponent1"
value={state.opponent1}
required
/>
<input
type="hidden"
name="opponent2"
value={state.opponent2}
required
/>
<button type="submit">
Show me
</button>
</form>
)}
It looks the same as it did before, but now it actually does something. I would show you a screenshot, but it’s pretty much just a button. Unremarkable, but effective.
Show the Image in the Dialog
The last step is to put it all together.
The user submits the two opponents and the AI returns a winner.
The image generation
<form>will be available, showing the user the “Show me” button.When the user clicks the button, the API request gets submitted.
At the same time, we’ll programmatically open the dialog with some initial loading state.
When the request returns, we’ll display the image.
For that, I’ll create a new store for the image state using useStore. It’ll hold a showDialog state, an isLoading state, and the url. I’m also going to move the form’s submit handler into a dedicated function called onSubmitImg so it’s not nested in the template and all the logic can live together.
The body of the obSubmitImg function will activate the dialog, set the loading state, submit the form with jsFormSubmit, set the image URL from the results, and disable the loading state.
const imgState = useStore({
showDialog: false,
isLoading: false,
url: ''
})
const onSubmitImg = $(async (event) => {
imgState.showDialog = true
imgState.isLoading = true
const form = event.target
const response = await jsFormSubmit(form)
const results = await response.json()
imgState.url = results.url
imgState.isLoading = false
})
Man, I love that jsFormSubmit function! It lets the HTML provide the declarative HTTP logic and simplifies the business logic.
Ok – with the state setup, the last thing to do is connect the <Dialog> component. Since we’ll be opening it programmatically, we don’t need the built-in button. We can disable that by making the btnText prop falsy. We can connect the open prop to imgState.showDialog. We’ll also want to update that state when the dialog closes via the onClose$ event. And the contents of the dialog should either show something for the loading state or show the generated image.
<Dialog
btnText={false}
open={imgState.showDialog}
onClose$={() => imgState.showDialog = false}
>
{imgState.isLoading && (
"Working on it..."
)}
{!imgState.isLoading && imgState.url && (
<img src={imgState.url} alt={`An epic battle between ${state.opponent1} and ${state.opponent2}`} />
)}
</Dialog>
Unfortunately, we now have a button that programmatically opens a dialog element without accessibility considerations. I thought about including the same ARIA attributes as we have on the toggle, but if I’m honest, I’m not sure if a submit button should control a dialog.
In this case, I’m leaving it out because I don’t know the right approach, and sometimes doing accessibility wrong leads to a worse experience than doing nothing at all. Open to suggestions. :)
Closing
Okay, I think that’s as far as we’ll get today. It’s time to stop and enjoy the fruits of our labor.
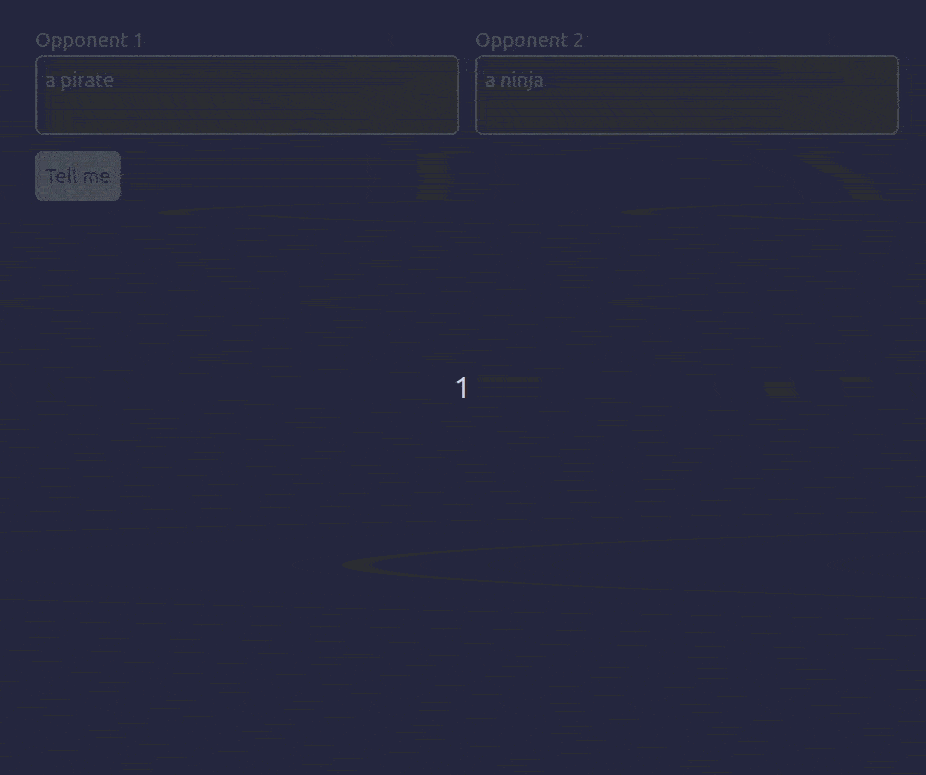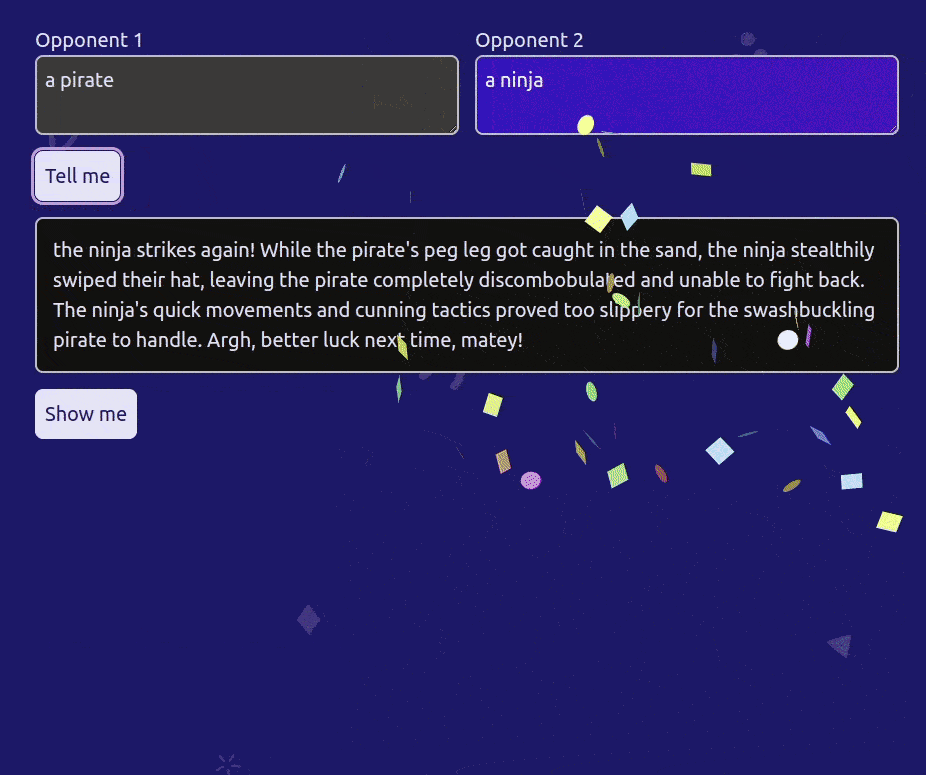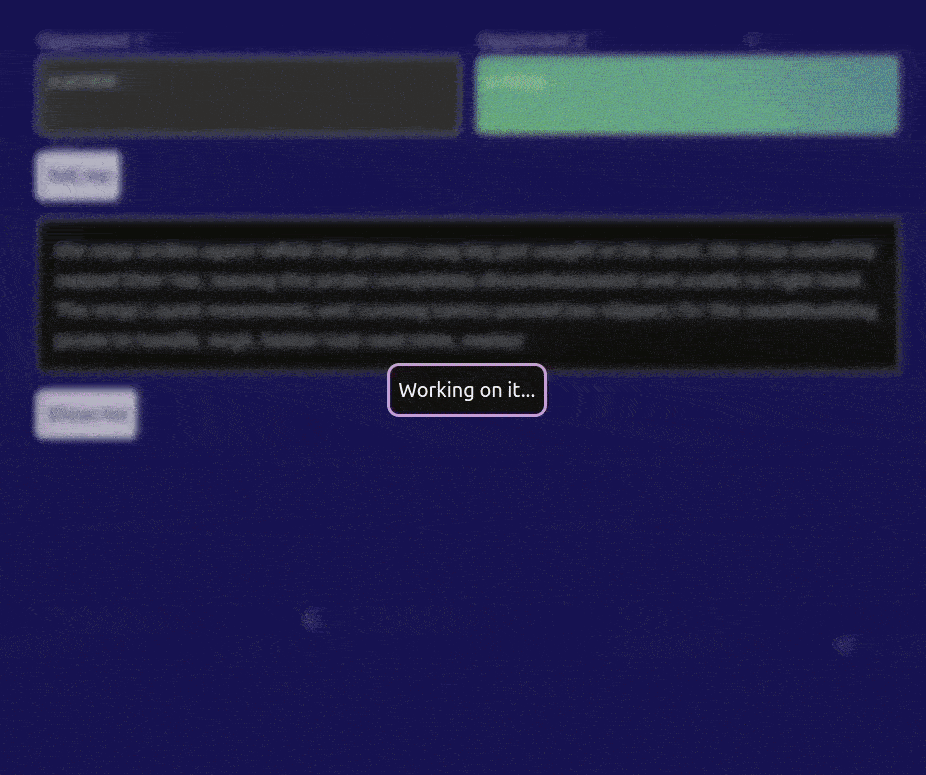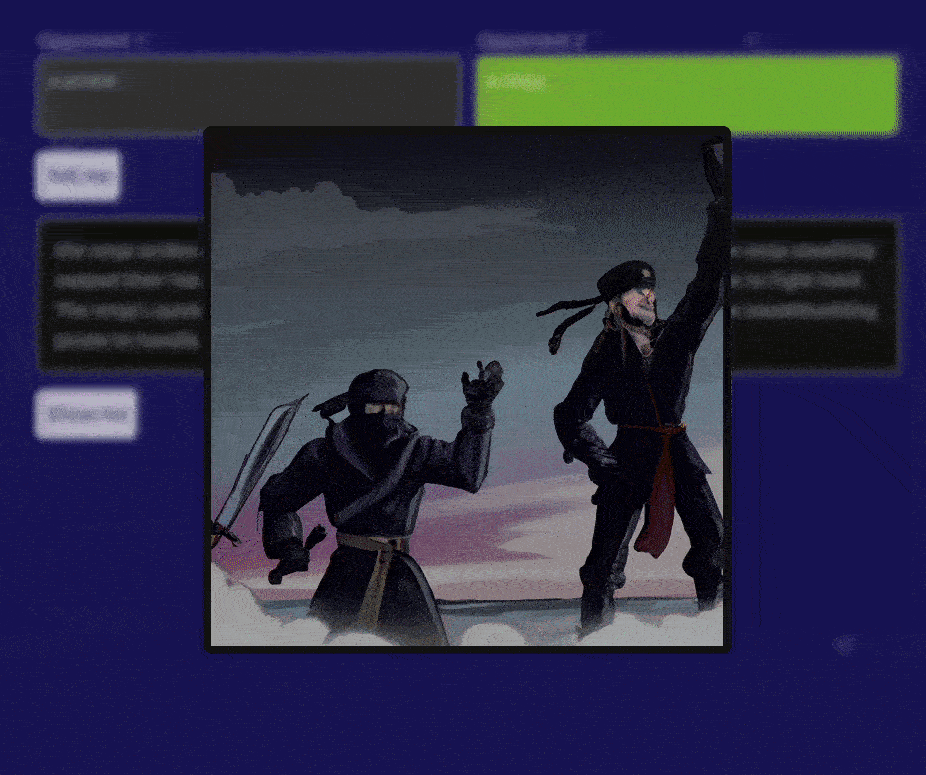
Okay, OpenAI isn’t the best AI image generator, or maybe my prompt skills need some work. I’d love to see how yours turned out.
A lot of the things we covered today were a review: building Qwik components, making HTTP requests to OpenAI, state, and conditional rendering in the template.
The biggest difference, I think, is how we treat prompts for AI images. I find they require a little more creative thinking and finagling to get right. Hopefully, you found this helpful.
In the video version, we covered a really cool SVG component that I think is worth checking out, but this post was already long enough.
Functionally, the app is as far as I want to take it, so In the next post, we’ll focus on reliability and security before we get into launching to production.
Thank you so much for reading. If you liked this article, and want to support me, the best ways to do so are to share it, sign up for my newsletter, and follow me on Twitter.
Originally published on austingil.com.
Subscribe to my newsletter
Read articles from Austin Gil directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Austin Gil
Austin Gil
I’m a web developer creating award-winning digital products for international nonprofits, growing startups, and government agencies. In my free time I write articles, contribute to open-source projects like Vuetensils and Particles CSS, live stream on YouTube and Twitch, host The Function Call podcast, and speak at events.