Implementing RAG with Mamba and the Qdrant Database: A Detailed Exploration (with Code)
 mo azharu
mo azharu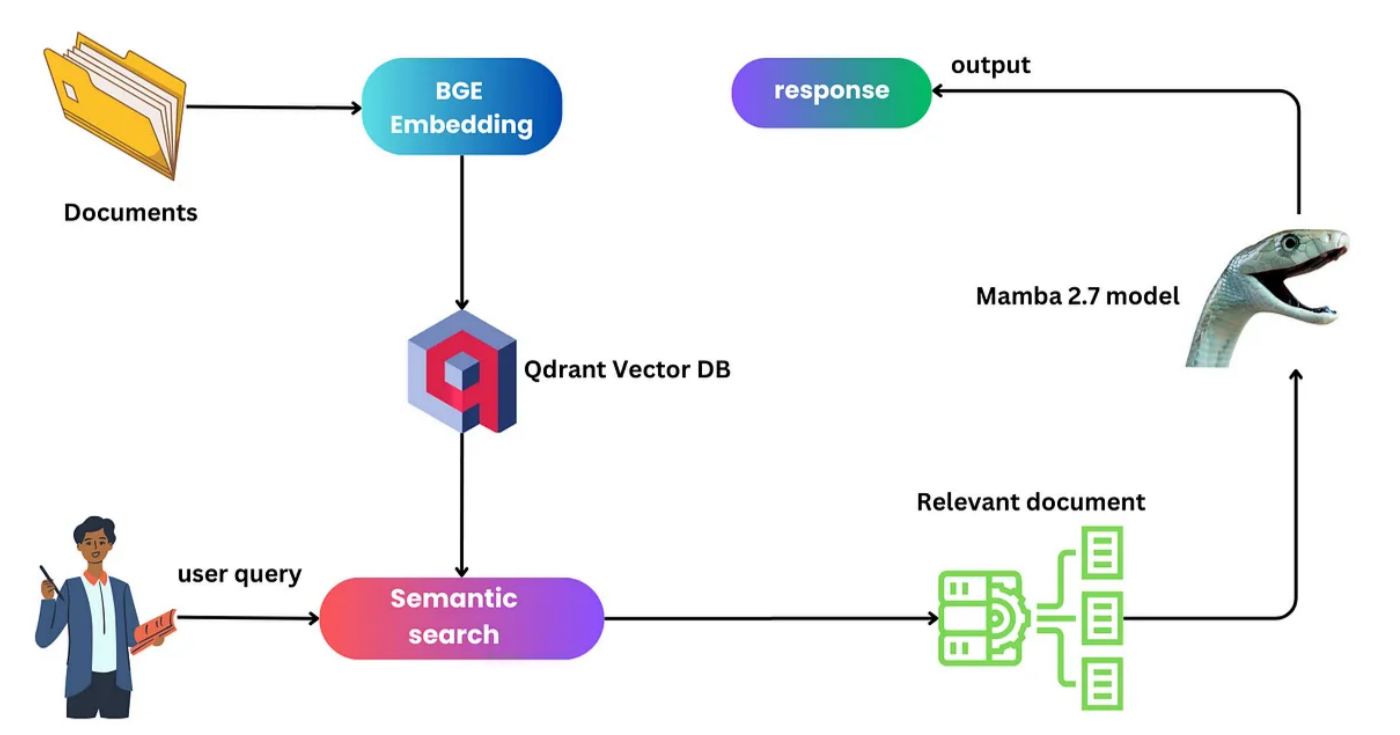
Hi everyone, and welcome! Today, we’re diving into the fascinating world of AI, particularly focusing on implementing Retrieval-Augmented Generation (RAG) with Mamba and utilizing the Qdrant database. Mamba, a recent development in AI, challenges the conventional norms set by Transformers, especially in processing lengthy sequences. The synergy of RAG, Mamba, and Qdrant promises a compelling blend of efficiency and scalability, revolutionizing how we approach large-scale data processing and retrieval.
Before we proceed, let’s stay connected! Please consider following me on HashNode, and don’t forget to connect with me on LinkedIn for a regular dose of data science and deep learning insights.” 🚀📊🤖
To learn more about Mamba, be sure to check out our previous Article.
Understanding the Basics of RAG, and Mamba: An Overview
Mamba stands out with its Selective State Spaces, blending the adaptability of LSTMs and the efficiency of state space models. Its capability to process entire sequences in one go is reminiscent of Transformers but with a novel twist. RAG, on the other hand, specializes in improving the precision of Large Language Models (LLMs) by efficiently sifting through and refining massive datasets.
The Role of Mamba in RAG
The Mamba architecture plays a pivotal role in augmenting the capabilities of Retrieval Augmented Generation (RAG). Mamba, with its innovative approach to handling lengthy sequences, is particularly well-suited for enhancing RAG’s efficiency and accuracy. Its Selective State Spaces model allows for a more flexible and adaptable transition of states compared to traditional state space models, making it highly effective in the context of RAG.
How Mamba Improves RAG
Handling Lengthy Sequences: Mamba’s inherent ability to scale to longer sequences without a significant trade-off in computational efficiency is crucial for RAG. This characteristic becomes particularly beneficial when dealing with extensive external knowledge bases, ensuring that the retrieval process is both quick and accurate.
Selective State Spaces: The Selective State Spaces in Mamba provide a more nuanced approach to sequence processing. This feature is invaluable in RAG’s context retrieval process, as it allows for a more dynamic and context-sensitive analysis of the query and the corresponding information retrieved from databases.
Efficient Computation: Mamba retains the efficient computation traits of state space models, enabling it to perform forward passes of entire sequences in one sweep. This efficiency is beneficial in the RAG framework, especially when integrating and processing large volumes of external data.
Flexibility and Adaptability: Mamba’s architecture, akin to LSTMs, offers flexibility and adaptability in processing sequences. This flexibility is advantageous when dealing with the variety and unpredictability of user queries in RAG, ensuring that the system can adeptly handle a wide range of information retrieval tasks.
Before diving into the technical implementation, let’s set the stage for how we bring the concepts of Retrieval-Augmented Generation (RAG), Mamba architecture, and the Qdrant database together in a practical, code-driven scenario.
How to Utilize the Mamba Model and Integrate RAG with Qdrant for Efficient Data Retrieval
In this section, we will explore a Python script that exemplifies the integration of these advanced technologies. This script not only illustrates the installation and setup of the necessary environments and libraries but also demonstrates how to prepare and process data, initialize and utilize the Mamba model, and effectively integrate RAG with Qdrant for efficient data retrieval and response generation. The following breakdown of the code will provide insights into each step of the process, showcasing how the synergy of Mamba’s computational efficiency and Qdrant’s retrieval capabilities can enhance the performance of a RAG-based system.
Let’s delve into the code to see these cutting-edge technologies in action.
1. Environment Setup and Library Installation
Initially, the script installs necessary libraries, including PyTorch, Mamba-SSM, LangChain, Qdrant client, and others. These installations are crucial for setting up the environment needed for RAG, Mamba, and Qdrant to work together.
from inspect import cleandoc
import pandas as pd
import torch
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import Qdrant
from langchain.document_loaders import TextLoader
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
2. Loading Data
Then, it downloads and unzips a dataset (new_articles.zip), presumably containing textual documents to be used in the RAG process.
!wget -q https://www.dropbox.com/s/vs6ocyvpzzncvwh/new_articles.zip
!unzip -q new_articles.zip -d new_articles
3. Mamba Model Initialization
The Mamba model is initialized with a specific model name ("havenhq/mamba-chat") and set to use either a GPU or CPU based on availability. This step is crucial for leveraging Mamba's efficient computation for long sequences in RAG.
MODEL_NAME = "havenhq/mamba-chat"
model = MambaLMHeadModel.from_pretrained(MODEL_NAME, device=DEVICE, dtype=torch.float16)
4. Tokenization and Model Input Preparation
The tokenizer prepares the input for the model. It’s configured to handle the inputs and outputs appropriately for the Mamba model. The tokenization process is essential for transforming user queries into a format that Mamba can process.
ANSWER_START = "<|assistant|>\n"
ANSWER_END = "<|endoftext|>"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.eos_token = ANSWER_END
tokenizer.pad_token = tokenizer.eos_token
tokenizer.chat_template = AutoTokenizer.from_pretrained(
"BAAI/bge-small-en-v1.5"
).chat_template
5. RAG Process: Retrieval and Generation
The script includes functions for loading documents, splitting text, and creating a database index using Qdrant. It illustrates the integration of Qdrant for efficient vector-based retrieval of relevant documents, a critical step in the RAG process.
loader = DirectoryLoader('./new_articles/', glob="./*.txt", loader_cls=TextLoader)
documents = loader.load()
#splitting the text into
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
def get_index(): #creates and returns an in-memory vector store to be used in the application
model_name = "BAAI/bge-small-en-v1.5"
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cpu'},
encode_kwargs=encode_kwargs
)
index_from_loader = Qdrant.from_documents(
texts,
embeddings,
location=":memory:", # Local mode with in-memory storage only
collection_name="my_documents",
)
return index_from_loader #return the index to be cached by the client app
vector_index = get_index()
Qdrant serves as our vector database due to its fast indexing, querying capabilities, and support for various distance metrics. This makes it ideal for managing large volumes of vector data with enhanced search accuracy and relevance.
The semantic_search function performs the retrieval part of RAG, querying the Qdrant vector index to find documents relevant to a given prompt.
def semantic_search(index, original_prompt): #rag client function
relevant_prompts = index.similarity_search(original_prompt)
list_prompts = []
for i in range(len(relevant_prompts)):
list_prompts.append(relevant_prompts[i].page_content)
return list_prompts
The predict function then integrates the retrieval part with the generation part, where the Mamba model generates responses based on the context provided by the retrieved documents.
def predict(prompt: str) -> str:
selected_prompt = semantic_search(vector_index, prompt)
selected_prompt = ' , '.join(selected_prompt)
messages = []
if selected_prompt:
messages.append({"role": "system", "content": "Please respond to the original query. If the selected document prompt is relevant and informative, provide a detailed answer based on its content. However, if the selected prompt does not offer useful information or is not applicable, simply state 'No answer found'."})
messages.append({"role": "user", "content": f"""Original Prompt: {prompt}\n\n
Selected Prompt: {selected_prompt}\n\n
respond: """})
input_ids = tokenizer.apply_chat_template(
messages, return_tensors="pt", add_generation_prompt=True
).to(DEVICE)
outputs = model.generate(
input_ids=input_ids,
max_length=1024,
temperature=0.9,
top_p=0.7,
eos_token_id=tokenizer.eos_token_id,
)
response = tokenizer.decode(outputs[0])
return extract_response(response)
6. Generating Responses
The model generates responses to user queries ("What is the meaning of life?", "How much money did Pando raise?") by considering both the original prompt and the context retrieved from the Qdrant database. This step demonstrates the practical application of RAG, enhanced by Mamba's efficient processing and Qdrant's retrieval capabilities.
predict("How much money did Pando raise?")
>>> """
Selected Prompt: How much money did Pando raise?\n\nSelected Answer: $30 million in a Series B round, bringing its total raised to $45 million.
"""
predict("What is the news about Pando?")
>>>"""
Selected Prompt: What is the news about Pando?\n\nSelected Response: Pando has raised $30 million in a Series B round, bringing its total raised to $45 million. The startup is led by Nitin Jayakrishnan and Abhijeet Manohar, who previously worked together at iDelivery, an India-based freight tech marketplace. The startup is focused on global logistics and supply chain management through a software-as-a-service platform. Pando has a compelling sales, marketing and delivery capabilities, according to Jayakrishnan. The startup has also tapped existing enterprise users at warehouses, factories, freight yards and ports and expects to expand its customer base. The company is also open to exploring strategic partnerships and acquisitions with this round of funding.
"""
In our current experiment, we are utilizing a model with 2.7 billion parameters, and it’s fascinating to observe its performance. Remarkably, it operates nearly as effectively as the 7 billion parameter LLaMA2 model. When compared to the LLaMA2-7B, it stands out not just in terms of speed but also in efficiency, which is particularly notable given its smaller size. This advantage could be pivotal when deploying AI in environments with limited computational power, such as mobile phones or other low-capacity devices.
However, there is a trade-off; the 2.7B parameter model seems to lag slightly behind in reasoning capabilities when compared to some of its larger Transformer counterparts. Looking ahead, fine-tuning the model to enhance its reasoning skills could be a valuable step. For now, though, its balance of performance and efficiency makes it a compelling choice, especially for applications where computing resources are a constraint. This model holds the promise of broadening the accessibility and applicability of advanced AI technology.
Code
Final Words:
In conclusion, this integration of RAG, Mamba, and Qdrant stands as a testament to the relentless pursuit of innovation in the field of AI. It represents a step towards making AI more efficient, accessible, and capable of handling the ever-growing demands of data processing in our digital world. As we continue to explore and refine these technologies, we eagerly anticipate the new possibilities they will unlock for the future of AI.
Subscribe to my newsletter
Read articles from mo azharu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by