Right Sizing Collected Streams
 Lee Carver
Lee CarverTable of contents

Java’s streaming APIs have a lot of advantages when processing Collections. Their semantics include several good safety guarantees, and the stream operators can be easy to use and compose.
The ease of use comes with a bit of cost in the final “terminal” operation. One very common need is collecting the results from the operations on individual stream elements. The simple Collector.toList() method allows us to sweep up those elements into a single neat easily manipulated object.
List result = source.stream()
.collect(Collectors.toList());
The Collector provided by Collectors.toList() is prepared to terminate any stream, regardless of the stream’s final number of elements. A consequence is the recurring resizing of the underlying ArrayList.
We can do better by “right sizing” the result in advance. If the final size is known in advance, the result never needs to be resized. For the common cases of duplicate, transform, or extract streams, the final size is simply the number of elements in the source stream.
List result = new ArrayList<>(source.size());
source.stream()
.forEach(result::add);
The performance benefits of using right sized ArrayLists and the forEach() termination method are easily demonstrated. Simple tests show ~20% timing improvement with the forEach() termination method. The performance ratio would be reduced when there is more meat in the middle (e.g. map()s), but an absolute advantage of ~2ms / 10K copies (for streams > 20 elements) should persist.
There are also strong benefits based on memory usage, but these are more challenging to measure. Theory suggests a 25% reduction of allocated ArrayList space. Code with right sized ArrayLists will tend to allocate a few large data blocks, with somewhat less thrashing of smaller blocks.
These benefits support the use of right-sized ArrayLists and the forEach() termination method in most cases where they apply.
Why You Care
I’m not normally a huge advocate for functional code, but streams work well for a number of common cases. Compared to classic for loops, there is little risk of overrunning the array bounds. The semantics of the map() and filter() methods prevent some null pointer mistakes. The list of supplied elements is intrinsically non-mutable.
Despite these advantages, some of the common tools for working with streams come with curious side effects. One of my concerns has been memory allocation and usage.
In a simple form, streams and collectors can be used to duplicate a source of date into a list.
List result = source.stream()
.collect(Collectors.toList());
This statement demonstrates the very common practice of terminating a stream expression with a .collect(Collectors.toList()) invocation.
Although a .collect(Collectors.toList()) expression is easy, it can also create extra memory load. Mindlessly easy does not come for free, and ArrayList pays the price for us.
The toList() method provides an ArrrayList as the underlying collector. Typically, an ArrrayList starts at a relatively small size (10 entries), and doubles in size every time its capacity is exceeded. Although the amortized insertion cost for n elements is O(n), an insertion on a resize boundary will be slower than the others.
Since ArrrayLists amortize their memory allocations, they are somewhat wasteful with memory. Immediately after a resize, barely 50% of the allocated space is used. With random numbers of elements, approximately 25% of the entries in an average ArrrayList will be unused. For small ArrrayLists with only one element, 90% of the entries are unused.
One easy memory optimization technique is to “right size” the result ArrrayList from the beginning. Although filtering and other stream operations can modify the number of entries in a stream, many use cases provide one result element for each input element.
Stream expressions that duplicate, transform, or extract data from each element of a stream are very common. In these cases, the size of the input stream can be used to allocate the entire result ArrrayList.
But neither the collect() method nor the methods of the Collectors class make it easy to specify the expected size of the collected results.
The forEach() method provides an alternate idiom that works well with right sized ArrrayLists. Instead of working with a resizable collector, the forEach() method can populate a rightsized ArrrayList.
List result = new ArrayList<>(source.size());
source.stream()
.forEach(result::add);
With this approach, the result is allocated in advance of using the source’s stream. The add() invocation within the forEach() method will never need to reallocate the underlying array. This idiom has the potential to provide a modest performance increase and better memory utilization than the use of .collect(Collectors.toList()).
Does It Really?
Oh my, yes it does! The use of a forEach() method to accumulate the results is readily demonstrated. The advantages were apparent from the very first test run. The advantages are so striking that I expanded the testing protocol to gain additional understanding.
The very first simple test with the two duplication statements above indicated a big advantage with the forEach() aggregation of stream results. It takes a while for the JVM to stabilize, but the last 4 trials in a ten trial set show fairly stable timings.
…
Test complete
asCollector nano time 4986700
asForEach nano time 3506200
Test complete
asCollector nano time 4667300
asForEach nano time 4403100
Test complete
asCollector nano time 4974500
asForEach nano time 3350300
Test complete
asCollector nano time 4542900
asForEach nano time 1338200
Wow! I have rarely seen raw benchmark statistics that were this convincing. Even for small samples, before the optimizer can really kick-in, the advantages of right sizing the collector list is dramatic.
The forEach() aggregation clearly beats the collector aggregation. The forEach()aggregation ranges from 95% to 30% of the execution time for the collector aggregation, averaging about a 20% performance improvement on execution time.
These advantages were so striking, I had to convince myself with more testing. There are a few edge cases, but the initial results are strongly confirmed. If you can pre-allocate the List for the result, using forEach() to aggregate the elements saves time and memory.
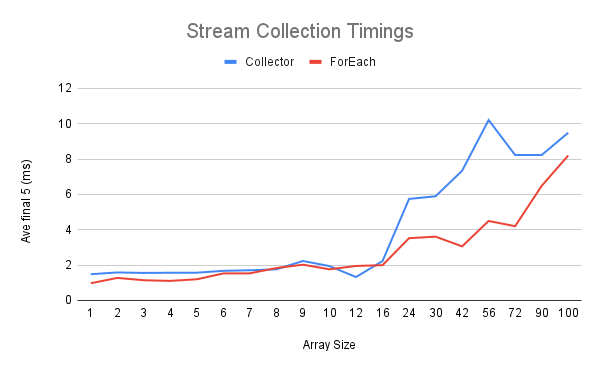
The Stream Collection Timings graph shows millisecond timings for 10,000 duplications of a stream of various sizes into a List. Since ArrayList pre-allocates 10 entries, the time advantages are very modest for small collections. Once the source stream exceeds two dozen elements, the performance advantages of the forEach() method with a right sized ArrayList are quite apparent.
Testing Protocol
The latest version of the test application has a simple command line interface (CLI) to define test conditions. It also outputs memory statistics in addition to nanoTime() based execution timings. This is available via GitHub in the StreamDemo repository.
Java performance tests are known to be twitchy, so these measurements have their limits. Individual tests with 1,000 iterations run for a few milliseconds, which can have a lot of jitter.
The Stream Collection Timings graph was constructed from data collected on multiple runs of the test application. In the hopes of stabilizing the JVM behavior, each test run consisted of 30 trials, and only the timing data from the last 5 trials was used for analysis. Each trial consisted of copying a fixed sized collection 10,000 times. The size of the collection was varied for each test run.
The test data is also available at the StreamDemo repository in the directories capture_A_1736 (collet timing data) and capture_B_1736 (forEach timing data). I loaded these results into a spreadsheet and pushed the results into a simple graph. The picture looks compelling to me.
Longer runs with more iteration and trial confirm the advantages of forEach() aggregation, but the ratios narrow. With 100,000 iterations and 30 trials, the forEach() aggregation remains advantageous but only by 3% to 5% over collector based aggregation. I suspect that the simplicity of the test code allows the JIT to inline and optimize the straightforward execution paths.
All of the tests were run on an older development class laptop (Intel i7, 2.7GHz, 32GB RAM, Window 10 Pro 64 bit, cygwin64 2.924, OpenJDK 64-Bit Server VM Temurin-17.0.7+7). The test program is available at the StreamDemo repository.
Closing Thoughts
One of the hidden performance holes in many software systems is memory allocation. The new operator looks atomic, seemingly comparable to + in operational complexity. This is incorrect. The complexities and cost of managing dynamic memory can be very significant.
During the early stages of development for a scripting engine, I once achieved a 3x speed-up simply by changing the token scanner from dynamic allocated tokens to reusing a single static buffer. The lesson was clear. Stay out of the memory allocator if you can.
In Java, the memory allocator is unavoidable for simple objects. One of the few areas where a Java developer can exert control is array allocation. Preallocating ArrayLists to their final size provides an effective way to improve Java execution performance and memory utilization.
Subscribe to my newsletter
Read articles from Lee Carver directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lee Carver
Lee Carver
Experienced Software Engineer. User interfaces, distributed services, software tools. Software development and operation at scale in multiple application domains.