With Great Power Comes Great Responsibility: Mastering Snowflake's Advanced Performance Features
 Anand Gupta
Anand Gupta
Snowflake offers a suite of advanced features that empower organizations to handle terabytes of data more efficiently and effectively than ever before. Among these, the Zero Copy Clones, Cluster keys, and Query Acceleration Service stand out for their ability to improve query performance significantly against massive data volumes. However, these powerful capabilities come with cost implications that must be carefully managed.
In this article, we’ll briefly overview these incredible performance features, point out some potential risks, and discuss how best to avoid them.
Embracing Snowflake's Advanced Performance Capabilities
Query Acceleration Service
The Query Acceleration Service is designed to boost the performance of complex queries, reducing execution time and improving end-user experience. By accelerating queries, organizations can achieve faster insights, but it's important to understand the cost implications of using this service, as it consumes additional compute resources.
The diagram below illustrates the best use case for Query Acceleration Service. It shows the query workload during a typical 24-hour day running on a MEDIUM size warehouse.
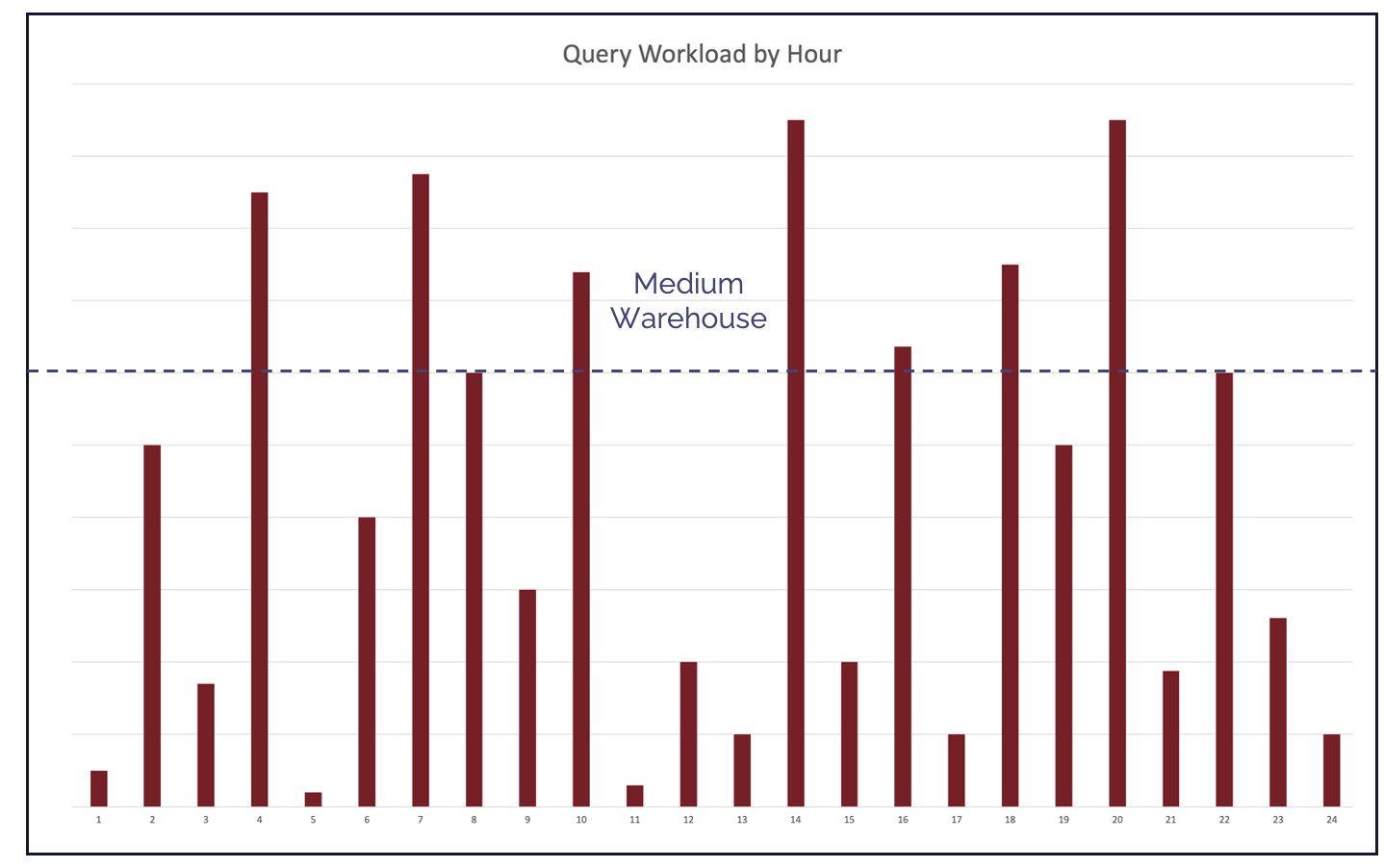
As you can see, the workload shows significant variation during the day, and most queries use 10-80% of machine capacity. However, there are several huge spikes in demand where complex, potentially long-running queries need more than 100% of warehouse capacity. Data Engineers often make the mistake of assuming Snowflake’s Multi-Cluster Warehouse feature will automatically resolve the issue, but that won’t help in this case.
One solution is to deploy Snowflake's Query Acceleration Service (QAS) which automatically provides additional compute power pulled from a serverless pool of Snowflake servers to further accelerate demanding queries. This helps transform queries taking hours to minutes or even seconds.
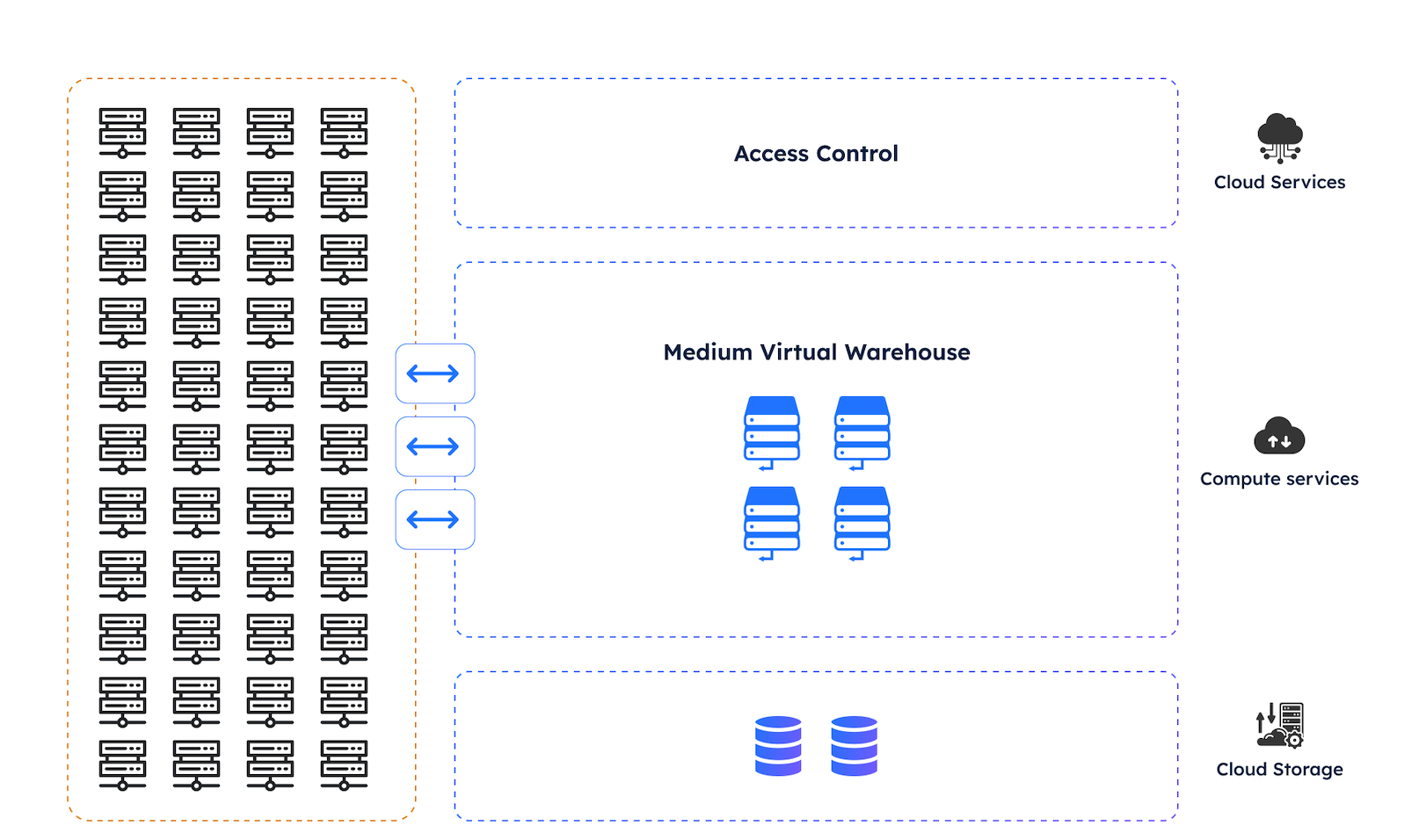
The diagram above illustrates how Query Acceleration Service works. Once the warehouse is configured to use QAS, the long running, more complex queries will automatically draw upon a pool of compute resources. This has the advantage that queries that only need a MEDIUM size warehouse run as usual, but Snowflake can offload long query scans and some sort operations to the Query Acceleration Service thereby improving query performance.
“With great power comes great responsibility” - Voltaire and Spider-man
However, as with any powerful tool, if misused, it can lead to an unexpectedly high credit spend, and it’s not advisable to deploy Query Acceleration Service against every Virtual Warehouse.
In one case, a Snowflake Data Engineer ran up a huge unexpected bill when they ran a query late one Friday on an X4-LARGE warehouse, accidentally including a cartesian join. By default, queries are allowed to execute for 172,800 seconds (2 days), and they only realized the mistake on Monday after running up a huge bill.
If, for example, you enabled Query Acceleration Service against an XSMALL warehouse, you’d be forgiven for thinking you’d avoid the risk of overspending because a long-running query on an XSMALL would spend a maximum of 48 credits, but of course, QAS might magnify that problem.
To be clear, you can avoid the risk of runaway queries by placing an automatic timeout on the user Session or Warehouse by setting the STATEMENT_TIMEOUT_IN_SECONDS. However, be careful not to accidentally kill important long-running queries on your production system. Another option to consider is a Snowflake Resource Monitor.
Zero Copy Cloning
Zero Copy Clone allows users to create copies of databases, schemas, or tables without physically copying the underlying data, enabling rapid provisioning of development and testing environments. While this feature does not incur additional storage costs, it's essential to manage the compute resources used by these clones to ensure cost efficiency.
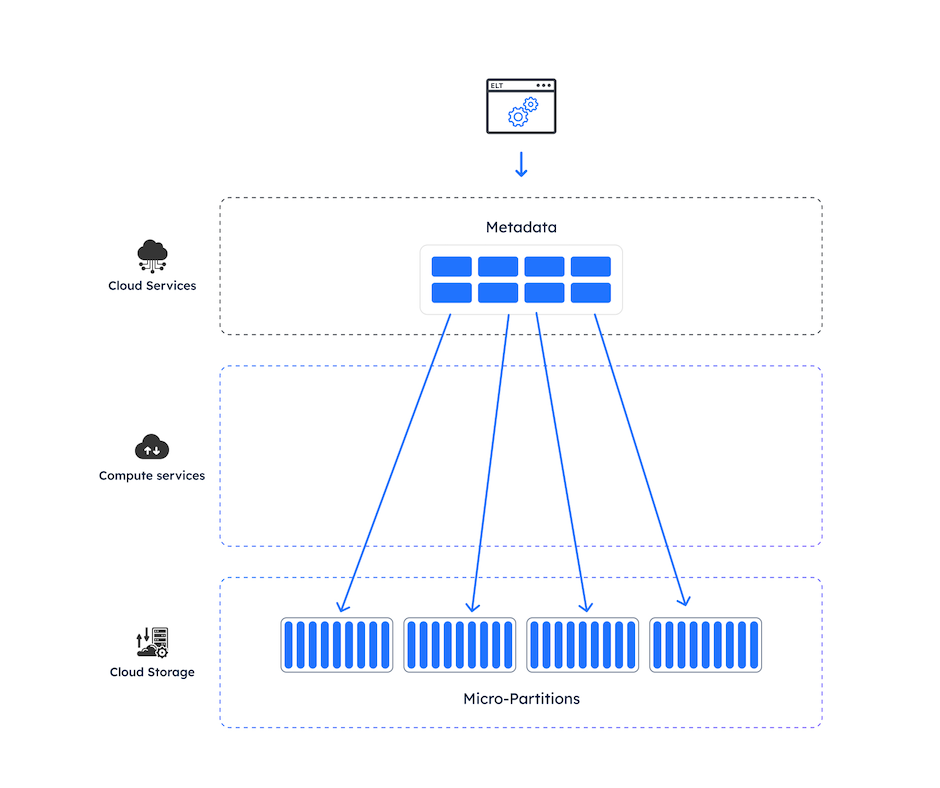
The diagram above illustrates how Snowflake physically stores data with a set of tiny metadata pointers in Cloud Services while the physical data is stored in 16MB micro-partitions in the storage layer. This innovative architecture makes it possible to replicate Gigabytes to Terabytes of data within seconds.
Zero-copy cloning rapidly creates fully read/write copies of production data to provide non-prod environments for experimentation, testing, and development. For example:
An analyst could clone the past year of customer data to test an ML model safely.
A dev team might clone a snapshot of production data to use during application development.
However, while cloning is an incredibly powerful Snowflake feature, it can lead to excessively high storage costs because although the initial cloning operation doesn’t add any physical storage, as data in the source table is updated or deleted and micro-partitions aged out, this can lead to unexpectedly high storage costs.
Thankfully, there is a solution to help identify redundant Snowflake storage caused by cloning, a technique that involves identifying clones over a few months old and highlighting the potential storage cost savings. The article Snowflake Zero Copy Clones and Data Storage explains the technique in detail.
Clustering Keys
Clustering is one of the most misunderstood Snowflake performance tuning features, and while it has the potential for huge performance improvements, customers sometimes find the cost outweighs the benefits - most often because cluster keys have been inappropriately used.
Adding clustering keys to large Snowflake tables optimizes the table storage layout based on the clustering key columns.
The screenshot below illustrates the potentially massive query performance gains from clustering, which can dramatically speed up query filtering by clustered columns.
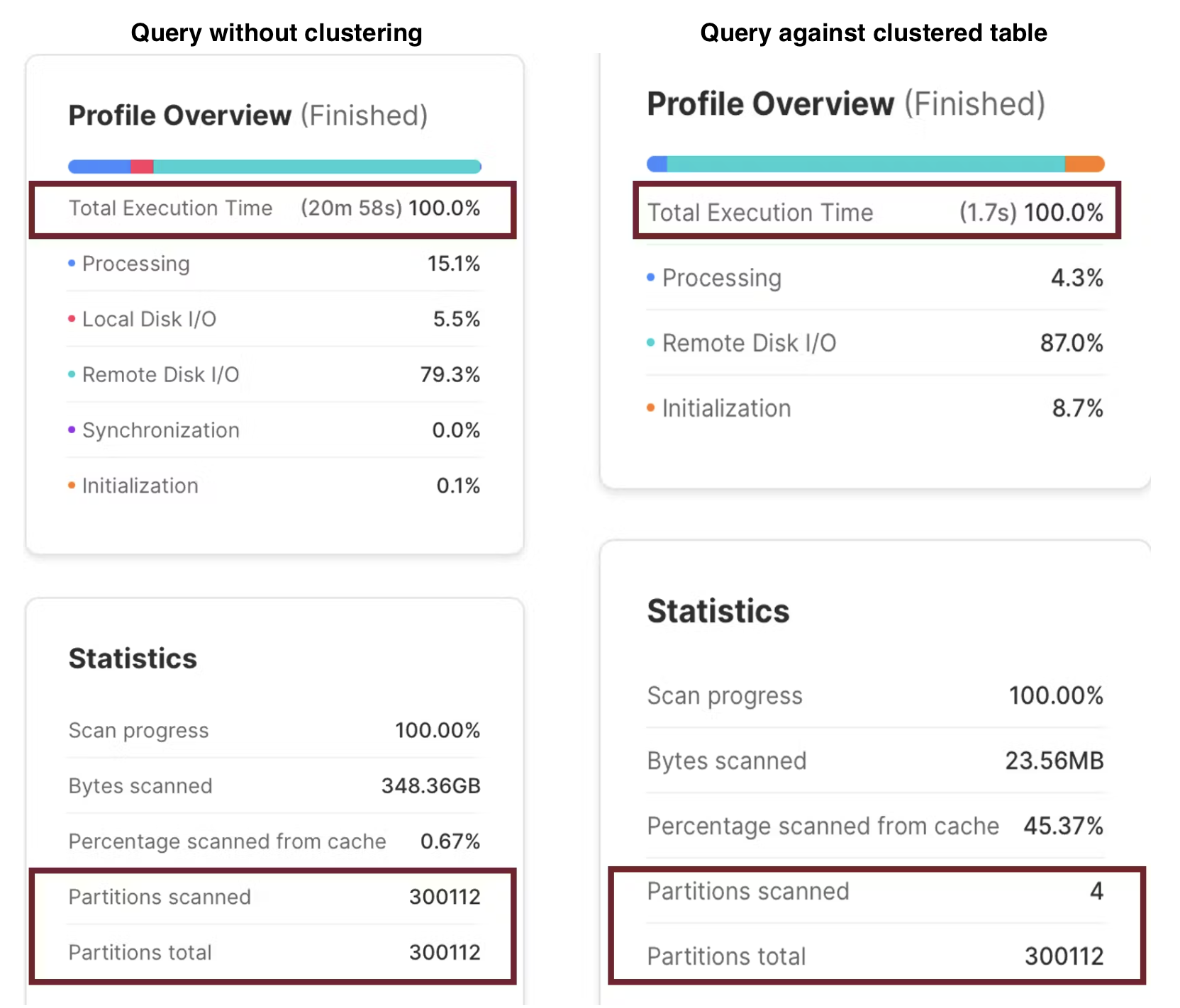
The above results were produced by the same SQL statement below.
select *
from web_sales
where ws_sold_date_sk = 2451161
and ws_item_sk = 463520;
The example above illustrates a situation in which a table of over a billion Customer Sales Transactions was clustered by the Date and Item, and the results were returned over 700 times faster. The only difference was the query, which ran in 1.7 seconds, was clustered by WS_SOLD_DATE_SK and WS_ITEM_SK, which appeared as a filter in the SQL WHERE clause.
However, while clustered tables often lead to faster query performance, this technique comes with a risk of higher cost if not correctly deployed, as Snowflake needs to continually maintain the cluster keys as a background task which in turn consumes credits.
If the clustering key is chosen poorly - for example, clustering on a very low cardinality column with lots of duplicate values (for example, GENDER) the table will still lead to background clustering cost but provide almost no performance benefit.
Paradoxically, the reverse is also true. Deploying a clustering key against a table with a unique key often leads to remarkable performance benefits, but transformation operations (inserts, updates, and deletes against the table) can lead to high background clustering costs, outweighing the performance benefits.
The Best Practices for Snowflake Clustering include:
Carefully select the Clustering Key which should often be included as a predicate in the WHERE clause. For example, a large Fact Table is often queried by a DATE field or DATE_KEY. This often makes the “Date” column a good candidate for clustering.
Avoid Clustering on small tables as clustering works best on larger tables, (Snowflake recommends table sizes over 1TB in size).
Avoid Clustering Keys on tables with many merge, update, or delete operations, as the cost of automatic background re-clustering operations can outweigh the performance gains.
The bottom line is clustering can work miracles for query response times, but should be applied judiciously!
Search Optimization Service
While misunderstandings of Snowflake Cluster Keys are common, those surrounding the Search Optimization Service are even more prevalent. This tool aims to improve query performance against a few highly selective rows from tables containing millions of entries.
Unlike Data Clustering that physically sorts rows in place, Search Optimization Service builds an index like structure alongside the table and performs a lookup operation against the table. Often described as a technique to find a needle in a haystack, this tool is deployed to find a small number of rows from millions or even billions of rows.
The diagram below illustrates how it works, whereby a SQL query uses the index-like structure to reduce the volume of data scanned, which in turn can lead to significant performance improvements.
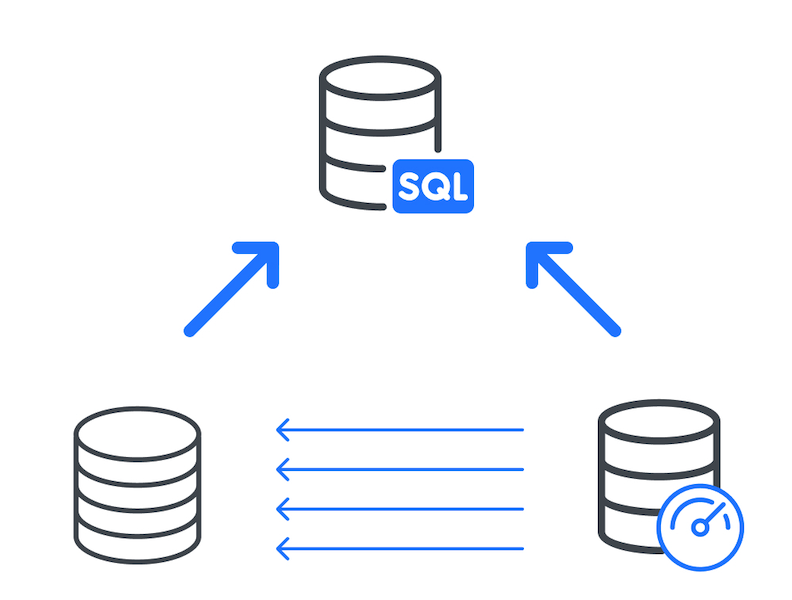
To help understand Search Optimization, let’s compare it to Clustering. Whereas Snowflake clustering keys are often deployed against columns with many duplicate values (for example, to return thousands of sale records for a given day), Search Optimization is designed to return a tiny number of rows from a similarly large table.
Likewise, while Cluster Keys work well with RANGE QUERIES (for example where DATE > ‘22-May-2024’, Search Optimization needs query filters with EQUALITY filters.
Take for example the query below:
select *
from customer_sales
where date_sold > '14-JUN-2003'
and date_sold <= '30-JUN-2003';
Assuming this returns 250,000 rows from a table with over a billion entries, the DATE_SOLD column might be a good candidate for a Clustering Key. However, it would be a poor candidate for Search Optimization Service.
A good example query for Search Optimization Service includes equality filters against one or more columns that return relatively few rows. For example:
select *
from store_sales
where ss_customer_sk = 41657562;
Assuming the above query returns just a few hundred rows from a table with over a billion entries, this can lead to huge performance improvements. The screenshot below shows the results with and without Search Optimization Service:
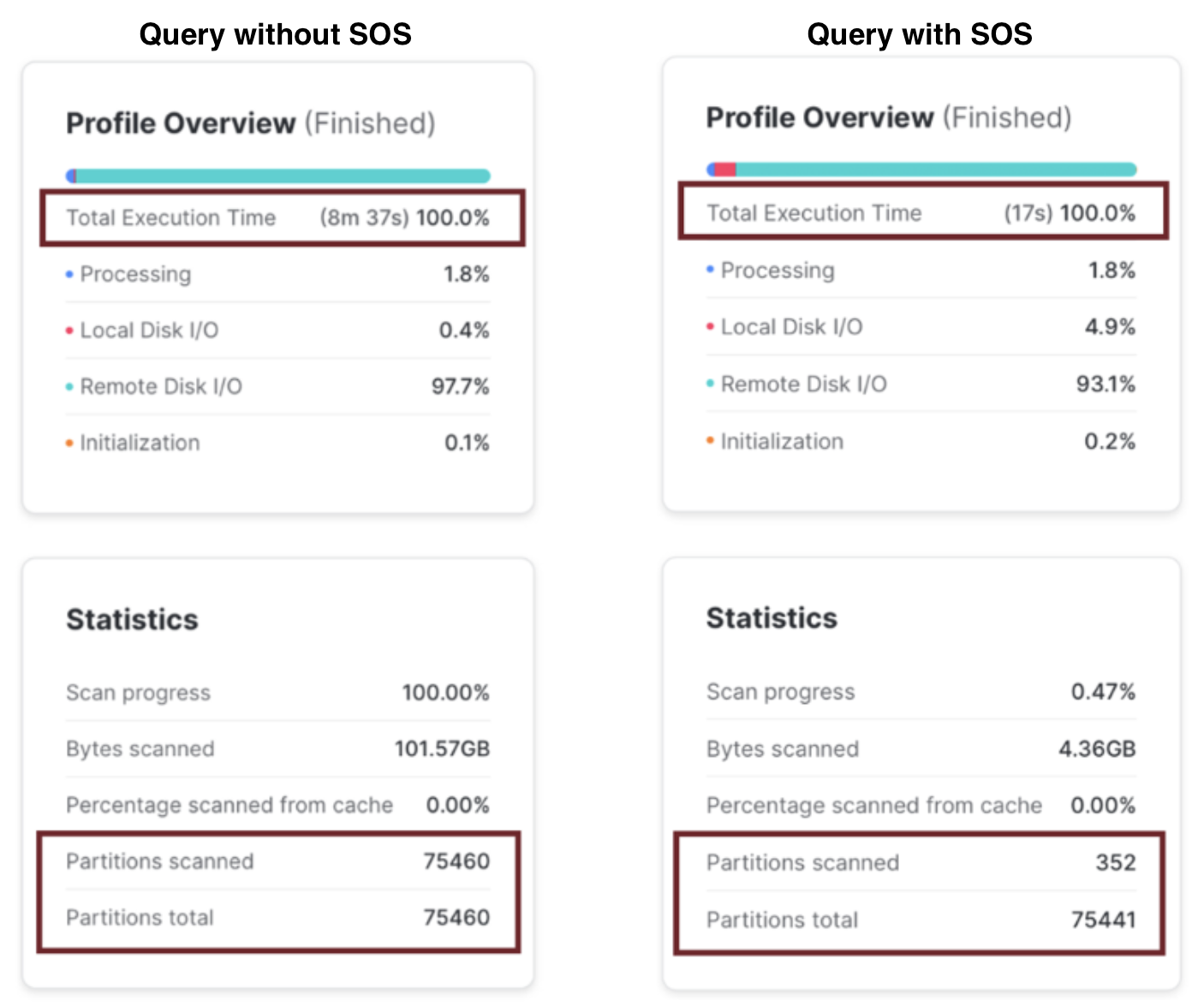
Notice the query without Search Optimization performed a Full Table Scan of over 75,000 micro-partitions, taking around 8 1/2 minutes, whereas using Search Optimization scanned just 352 micro-partitions, returning in just 17 seconds. That’s a 30 times performance improvement.
However, it’s important to understand that, like Snowflake Clustering Keys, the index-like structure (not to be confused with an index) needs to be initially built and subsequently automatically maintained by a background Snowflake process. This means there’s a risk of both unexpectedly high storage costs (the structure can sometimes grow to the size of the original table) and also high credit costs to maintain.
Similar to Clustering, the cost of both storage and compute credits can sometimes outweigh the performance benefits. Worst still, because Search Optimization is a quite specialized feature for point lookup queries, there’s a risk it is inappropriately deployed leading to relatively high cost for no performance gain.
The Best Practices to deploy Snowflake Search Optimization include:
Deploy SOS on tables with many equality or IN filters or queries against text strings using substring and regular expressions to filter results.
Avoid deploying on small tables with few micro-partitions, as this feature works using partition elimination. The more partitions in the table, the greater the benefits of partition elimination.
This feature works best when queries return a few rows as a percentage of the total micro partition count on the table. For example, a query that returns (on average) 200 entries from a table with 50,000 micro partitions leads to excellent query performance.
The bottom line is that you should carefully evaluate your use case. Search Optimization can be an incredibly powerful feature if correctly deployed.
Managing Costs with Advanced Features
To leverage these advanced features without incurring unnecessary costs, organizations should adopt a strategic approach:
Monitor Usage: Keep a close eye on the usage of these advanced features to understand their impact on your Snowflake costs.
Set Usage Limits: Implement resource monitors and query timeouts to prevent runaway costs associated with high compute usage.
Optimize Configurations: Regularly review and adjust the configurations of your virtual warehouses, clones, and data clustering to ensure they are aligned with your performance and cost objectives.
Conclusion
Snowflake's advanced features, like the Query Acceleration Service, Zero Copy Clones, and Clustering Keys, offer powerful tools for enhancing data analytics capabilities. However, with great power comes great responsibility.
By understanding and judiciously managing the costs associated with these features, organizations can fully harness their benefits while maintaining control over their Snowflake expenditure. Better still, they can avoid the risk of an unexpectedly high bill.
Deliver more performance and cost savings with Altimate AI's cutting-edge AI teammates. These intelligent teammates come pre-loaded with the insights discussed in this article, enabling you to implement our recommendations across millions of queries and tables effortlessly. Ready to see it in action? Request a recorded demo by just sending a chat message (here) and discover how AI teammates can transform your data teams.
Subscribe to my newsletter
Read articles from Anand Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anand Gupta
Anand Gupta
I am co-founder at Altimate AI, a start-up that is shaking up the status quo with its cutting-edge solution for preventing data problems before they occur, from the moment data is generated to its use in analytics and machine learning. With over 12 years of experience in building and leading engineering teams, I am passionate about solving complex and impactful problems with AI and ML.