From Voice to Insight: The Journey of Speech Data Retrieval using NLP technology
 Jessica Anna James
Jessica Anna James
In the fast-paced digital era, information is power. But the real challenge lies not just in accessing information, but in efficiently retrieving and processing it, especially when it comes from diverse sources like speech. Speech data, abundant in our daily interactions and online media, holds a treasure trove of insights waiting to be unlocked. This blog post is designed to guide you, whether you are a beginner or an experienced professional, through the intriguing process of extracting valuable information from speech data.
We'll embark on a journey starting from the basics of data collection, diving into the complexities of text preprocessing, and advancing towards more intricate concepts like Named Entity Recognition (NER) and Dependency parsing. By the end of this guide, you'll be equipped with the knowledge and skills to not only extract information from speech data but also to analyze and visualize it effectively.
Let's decode the world of speech data together!
Data Collection
The first step in working with speech data is to convert the spoken words into text. This process, known as speech-to-text conversion, can be accomplished using various tools and libraries. For this tutorial, we'll focus on extracting speech data from the popular source – YouTube.
Converting YouTube Speech to Text (PyTube and OpenAI's Whisper)
PyTube is a Python library that simplifies the process of downloading videos from YouTube. In our example, we use it to fetch a video from a YouTube link.
Whisper is an automatic speech recognition (ASR) system developed by OpenAI. It can convert spoken language into written text. To use Whisper, you need to load the pre-trained model and transcribe the audio. Here's how you can do it:
from pytube import YouTube
link = 'https://www.youtube.com/watch?v=P73KmleCuBg'
try:
yt = YouTube(link)
except:
print("Connection Error")
video_stream = yt.streams.get_by_itag(139) # Select the stream with the desired quality
video_stream.download('', "youtube.mp4") # Download the video
import whisper
# Load the pre-trained Whisper model
model = whisper.load_model("base")
# Transcribe the audio from the downloaded video
result = model.transcribe("youtube.mp4")
# Extract the transcribed text
transcribed_text = result['text']
print(transcribed_text)
By combining PyTube and Whisper, you can easily convert speech from a YouTube video into text. This process is valuable for various applications, including content creation, accessibility for the hearing-impaired, and content analysis.
In summary, PyTube allows you to fetch video content from YouTube, and Whisper takes care of the challenging task of transcribing the speech from that video into text. This combination of libraries makes speech-to-text conversion accessible and efficient.
Text Preprocessing
Cleaning and Organizing Your Data
Once you have your speech converted into text, the next crucial step is text preprocessing. This step is fundamental in any Natural Language Processing (NLP) project as it cleans and structures your data, making it ready for analysis.
Steps in Text Preprocessing
Removing Irrelevant Information:
- Background noises, pauses, and non-verbal cues are common in speech data and should be removed.
Tokenization:
- This is the process of breaking down the text into smaller units like words or sentences. It’s crucial for understanding the context and meaning of the text.
Lowercasing:
- Converts all characters to lowercase to maintain uniformity.
Removing Stop Words:
- Words like 'and', 'the', 'is', which are frequent but don't add much meaning to the text.
Stemming/Lemmatization:
- These techniques reduce words to their base or root form.
Here's the code snippet of text preprocessing using the NLTK library:
def clean_text(text):
# Tokenize into words
words = word_tokenize(text)
words_lower = [word.lower() for word in words]
# Join the words back into a string
text = ' '.join(words_lower)
# Remove unnecessary double spaces
text = re.sub(r'\s+', ' ', text)
# Remove special characters except for letters and digits
text = re.sub(r'[^a-zA-Z0-9\s.,]', '', text)
return text
cleaned_text=clean_text(new)
cleaned_text
Note: Ensure you have the NLTK library installed.
Named Entity Recognition (NER)
Extracting Meaningful Information from Text
Named Entity Recognition (NER) is a crucial step in information retrieval from speech data. NER refers to the process of identifying and classifying key information (entities) in text into predefined categories. These categories often include the names of persons, organizations, locations, expressions of times, quantities, monetary values, and more.
Importance of NER in Speech Data Analysis
Enhances Data Understanding: By identifying specific entities, NER helps in gaining a clearer understanding of the speech content.
Facilitates Information Retrieval: It makes extracting specific information like names or places much easier.
Improves Data Structuring: Helps in organizing unstructured data effectively.
Implementing NER with Hugging Face Transformers
One of the simplest ways to implement NER is by using pre-trained models from Hugging Face's Transformers library. Here's how you can do it:
#This Python code uses the Hugging Face Transformers library to load a pre-trained BERT-based model for Named Entity Recognition (NER).
#It utilizes the "dslim/bert-base-NER" model, consisting of both a tokenizer and a token classification model.
#The code sets up a pipeline for NER using the `pipeline` function from the Transformers library, combining the loaded model and tokenizer.
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
# Show NER results
from spacy import displacy
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
pipe = pipeline("ner", model=model, tokenizer=tokenizer)
ner_results = pipe(cleaned_text)
#The Python function `from_ner_results_to_displacy` is designed to facilitate the conversion of Named Entity Recognition (NER) results into a format suitable for visualization using spaCy's `displacy`.
#Upon receiving the original text and the NER results—typically obtained from a BERT-based NER model—the function systematically processes the entities.
#It identifies entities based on the "B-" (beginning) and "I-" (inside) prefixes in the entity labels, constructing entity objects with labels, start positions, and end positions.
#These constructed entities are then organized into a list named `ents`.
#The final output is a dictionary, `d_result`, encompassing the original text, a title (set to None), and the list of recognized entities.
#This structured format is particularly useful for leveraging spaCy's visualization capabilities, providing a clear and organized representation of named entities within the context of the original text.
def from_ner_results_to_displacy(text, ner_results):
d_result = {"text": text, "title": None}
ents = []
current_entity = None
for ent in ner_results:
if "B-" in ent["entity"]:
if current_entity:
ents.append(current_entity)
entity_label = ent["entity"][2:]
current_entity = {
"label": entity_label,
"start": ent["start"],
"end": ent["end"]
}
elif "I-" in ent["entity"]:
if current_entity is not None:
current_entity["end"] = ent["end"]
else:
# Handle the case where "I-" is encountered without "B-" before
entity_label = ent["entity"][2:]
current_entity = {
"label": entity_label,
"start": ent["start"],
"end": ent["end"]
}
if current_entity:
ents.append(current_entity)
d_result["ents"] = ents
return d_result
ner_results = pipe(cleaned_text)
d_displacy = from_ner_results_to_displacy(cleaned_text, ner_results)
print(displacy.render(d_displacy, style="ent", jupyter=True, manual=True))
Note: Ensure you have thetransformers library installed.

The tags, such as MISC, ORG, LOC, and PER, categorize different parts of the text, indicating miscellaneous items, organizations, locations, and persons, respectively. Here the entities in the text are being recognized and labeled for data analysis or processing purposes.
Dependency Parsing
Unraveling the Grammatical Structure of Sentences
Dependency Parsing is an advanced technique in Natural Language Processing that helps in understanding the grammatical structure of sentences. This process involves analyzing how different words in a sentence relate to each other, typically focusing on the relationships between verbs, subjects, objects, and other parts of speech.
Why is Dependency Parsing Important?
Deepens Text Understanding: By analyzing sentence structure, we gain insights into the relationships and dependencies between words.
Enhances Information Extraction: It enables more sophisticated extraction of information, such as understanding the context in which entities are mentioned.
Improves Accuracy of NLP Tasks: Dependency parsing is essential for accurate results in tasks like sentiment analysis, question answering, and information retrieval.
Implementing Dependency Parsing
This code iterates through each sentence, processes it with spaCy to tokenize and analyze the grammatical structure, and then captures the dependency relationship of each word to its head in the sentence. The dependencies are stored in a list, providing a clear mapping of each word's role within the sentence.
By the end of this code script, every sentence from the original input has been transformed into a structured format that lists its tokens and their respective syntactic dependencies. This output is particularly useful for tasks in NLP that require an understanding of sentence structure, such as sentence parsing, information extraction, and aiding in the comprehension of complex sentence constructions for machine learning models.
#The provided Python script utilizes spaCy to conduct dependency parsing on a collection of sentences.
#The objective is to uncover the grammatical relationships between words within each sentence.
#The process involves iterating through the sentences, tokenizing and parsing them with spaCy, and then extracting and storing the dependency parse information for each token.
#The resulting data is organized into a structured format, where each entry in the `dependency_list` contains the original sentence and its corresponding dependency parse tree.
#The script concludes by printing the original sentence along with the detailed dependency parse information for each token.
#This output provides a comprehensive view of the syntactic relationships within the sentences, shedding light on how words are interconnected grammatically.
#Such dependency parse insights are valuable for various natural language processing applications, including syntax-based analysis and understanding sentence structures.
# List to store the dependency parse information
dependency_list = []
# Process each sentence with spaCy
for sentence in sentences:
doc = nlp(sentence)
# List to store the dependency parse tree for each sentence
sentence_dependencies = []
for token in doc:
# Store the dependency parse information
dependency_info = f"{token.text} --({token.dep_})--> {token.head.text}"
sentence_dependencies.append(dependency_info)
# Append the dependency parse tree for the sentence to the main list
dependency_list.append({
'Sentence': sentence,
'Dependencies': sentence_dependencies
})
# Print and use the dependency parse information
for entry in dependency_list:
print(f"Original Sentence: {entry['Sentence']}")
for dependency_info in entry['Dependencies']:
print(dependency_info)
print("\n")
Note: Ensure you have the SpaCy library and the necessary model (en_core_web_sm) installed.
The following is an example output generated for a sentence obtained from the YouTube Transcription extracted earlier. For more output examples you can refer to my github repository.

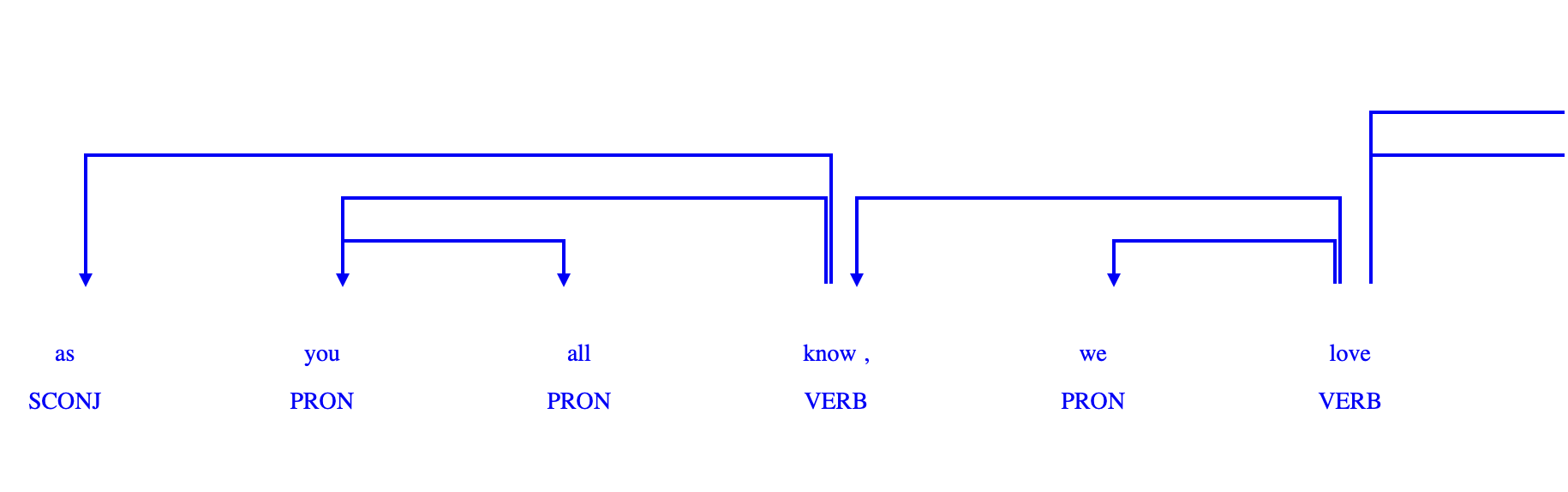
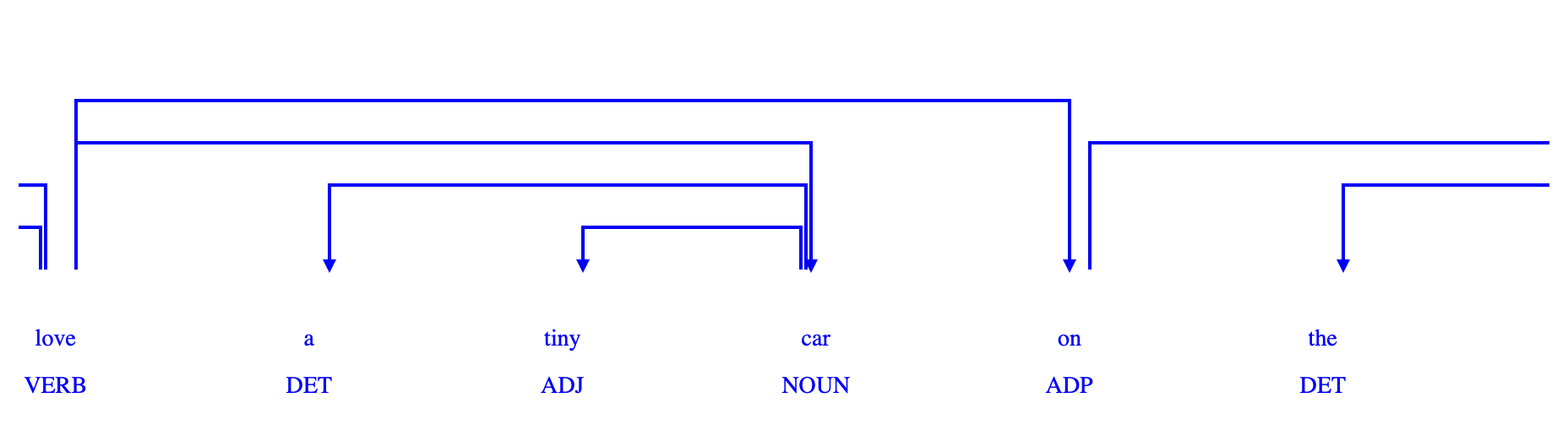
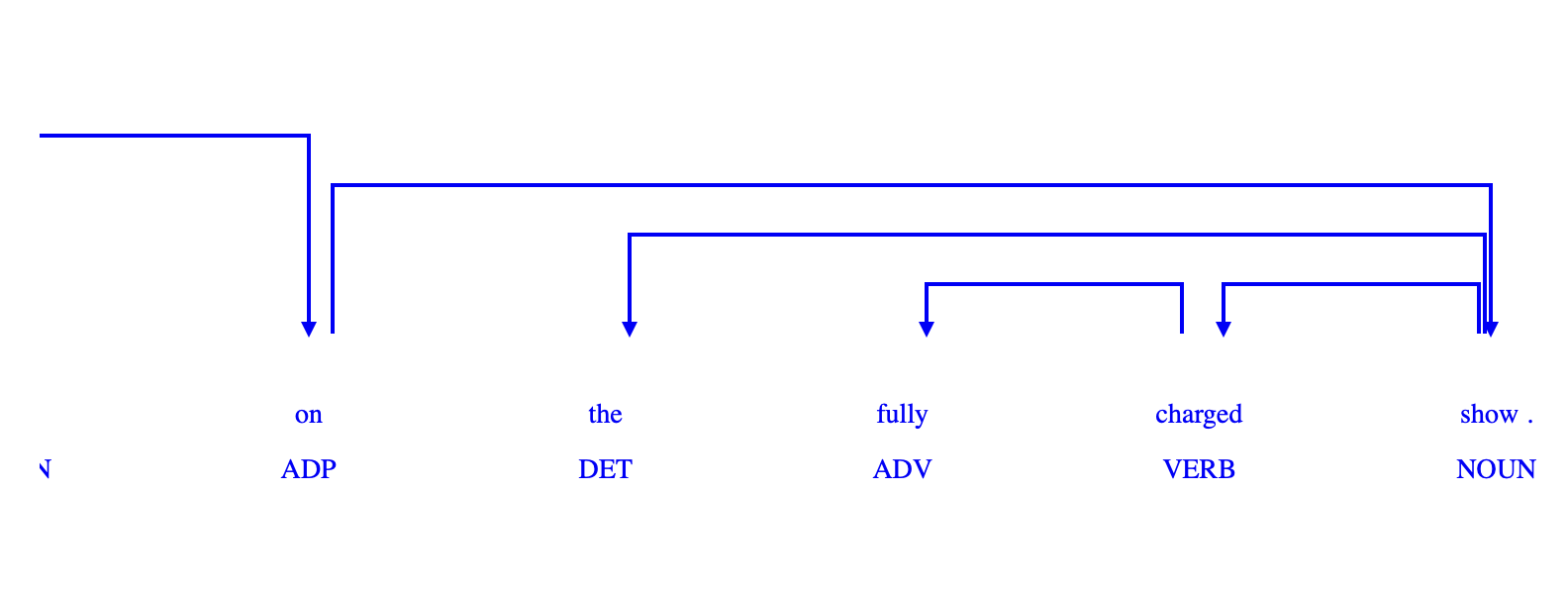
As we can see from the output generated, this script is a functional tool for extracting and studying the grammatical relationships within sentences, which is a cornerstone in many linguistic and NLP applications.
Information Extraction
Harnessing Data for Insights and Knowledge
Information Extraction (IE) is the process of automatically extracting structured information from unstructured text data. After identifying entities and understanding the relationships between words through NER and dependency parsing, we can now extract specific information that can be used for various insights and decision-making processes.
The Role of Information Extraction in Speech Data Analysis
Targeted Data Retrieval: IE allows us to pull out specific pieces of information like dates, events, or relationships between entities.
Automating Knowledge Mining: It significantly reduces the time and effort needed to sift through large volumes of text data.
Enhancing Decision-Making: Extracted information can be critical for analytics and making informed decisions.
Implementing Information Extraction
Information extraction can be as simple as extracting specific patterns from text or as complex as creating a model to identify and extract information based on context. Here is the code snippet for rule based information extraction:
# Rule-based information extraction function
model_info_list=[]
size_info_list=[]
battery_info_list=[]
interior_features_list=[]
def extract_information(sentence, entities, dependency_parse):
information = {}
# Extract quantity information
for entity in entities:
if entity['Label'] == 'CARDINAL':
information['Quantity'] = entity['Entity']
# Extract event information
if 'fully charged live' in sentence.lower():
information['Event'] = 'Fully Charged Live'
# Extract information related to brakes
brake_info = set() # Use a set to avoid duplicate entries
for dependency_entry in dependency_parse:
if 'brake' in dependency_entry['Sentence'].lower():
for dep_relation in dependency_entry['Dependencies']:
# Check for specific dependency relations related to brakes
if 'brake' in dep_relation.lower() or 'spongy' in dep_relation.lower():
brake_info.add(dep_relation)
if brake_info:
information['BrakeInformation'] = list(brake_info)
# Extract information about the model
model_match = re.search(r'\b(C-go|MISC)\b', sentence)
if model_match:
information['Model'] = model_match.group(0)
# Extract information about the manufacturer
manufacturer_match = re.search(r'\bBYD\b', sentence)
if manufacturer_match:
information['Manufacturer'] = manufacturer_match.group(0)
# Extract information about driving modes
for mode in ['eco', 'sport', 'comfort', 'snow']:
if mode in sentence.lower():
information['DrivingMode'] = mode.capitalize()
# Extract information about noise levels
if 'quiet' in sentence.lower():
information['NoiseLevel'] = 'Quiet'
# Extract information about the design
if 'design' in sentence.lower():
information['DesignOpinion'] = 'Unique design, inspired by Lamborghini'
return information
# List to store extracted information for each entry
extracted_information_list = []
for i, entry in enumerate(entities_list, 1):
sentence = entry['Sentence']
entities = [entry]
# Extract information using the defined rules
information = extract_information(sentence, entities, dependency_list)
# Append the extracted information to the list
extracted_information_list.append(information)
# Display the entry and extracted information
print(f"\nEntry {i}:\n")
print(f"Sentence: {sentence}")
print(f"Extracted Information: {information}")
# Add information to the respective lists for better formatting
if 'Quantity' in information:
quantity_list.append(f"Entry {i}: '{information['Quantity']}'")
if 'Event' in information:
event_list.append(f"Entry {i}")
if 'BrakeInformation' in information:
brake_info_list.append(f"Entries 1, 2, ..., {i}: {information['BrakeInformation']}")
if 'Model' in information:
model_info_list.append(f"Entry {i}: {information['Model']}")
if 'Size' in information:
size_info_list.append(f"Entry {i}: {information['Size']}")
if 'BatteryInfo' in information:
battery_info_list.append(f"Entry {i}: {information['BatteryInfo']}")
if 'InteriorFeatures' in information:
interior_features_list.append(f"Entry {i}: {information['InteriorFeatures']}")
if 'DesignOpinion' in information or 'DrivingMode' in information:
additional_info_list.append(
f"Entry {i}: {information.get('DesignOpinion', '')} {information.get('DrivingMode', '')}")
if quantity_list:
print("Quantity:\n", "\n".join(quantity_list), "\n")
if event_list:
print("Event:\n", ", ".join(event_list), "\n")
if brake_info_list:
print("Brake Information:\n", ", ".join(brake_info_list), "\n")
if additional_info_list:
print("Additional Information:\n", "\n".join(additional_info_list), "\n")
Here is the sample output of each entry:

Visualization
The Python function save_to_neo4j provided in the code snippet is a utility for persisting a NetworkX graph structure to a Neo4j graph database. It employs the py2neo library, which allows for seamless interaction with Neo4j from Python code.
The script initializes a connection to a Neo4j database instance using a provided URI, along with credentials for authentication. The save_to_neo4j function itself takes two arguments: the NetworkX graph (graph) that contains the data to be saved, and the graph_neo4j object representing the Neo4j database connection.
Inside the function, it begins a transaction (tx) to batch the database operations for efficiency. It then iterates through all nodes and edges of the NetworkX graph, creating corresponding Node and Relationship objects in the Neo4j database. Nodes are labeled as "Entity" and relationships are of type "RELATED_TO", reflecting the semantic significance of the data.
Once all nodes and relationships are created in the transaction, the function commits the transaction, finalizing the save operation. Upon successful execution, it prints a confirmation message indicating the graph has been saved to Neo4j.
This function is a critical piece for data migration from in-memory graph representations to a persistent graph database, facilitating advanced queries and analysis leveraging Neo4j's powerful graph capabilities.
from py2neo import Graph, Node, Relationship
# Save the graph to Neo4j
uri = "neo4j+s://2cb9a340.databasesforNLP.neo4j.io"
username = "neo4j"
password = "ooP2kv-Yi4FrFY-bhUqkEQMRp-avvbY8j7BZ1O7Y-TB" (Insert your instance link here)
graph_neo4j = Graph(uri, auth=(username, password))
def save_to_neo4j(graph, graph_neo4j):
nodes = list(graph.nodes())
edges = list(graph.edges())
tx = graph_neo4j.begin()
node_dict = {}
for node in nodes:
node_dict[node] = Node("Entity", name=node)
tx.create(node_dict[node])
for edge in edges:
start_node, end_node = edge
relationship = Relationship(node_dict[start_node], "RELATED_TO", node_dict[end_node])
tx.create(relationship)
tx.commit()
print("Graph saved to Neo4j.")
# Save the graph to Neo4j
save_to_neo4j(G, graph_neo4j)
Here is a quick look at a basic knowledge graph. While, the relationship between the nodes aren't defined yet, we could work on it separately and make the knowledge graph more insightful. For more information you could visit Neo4j.
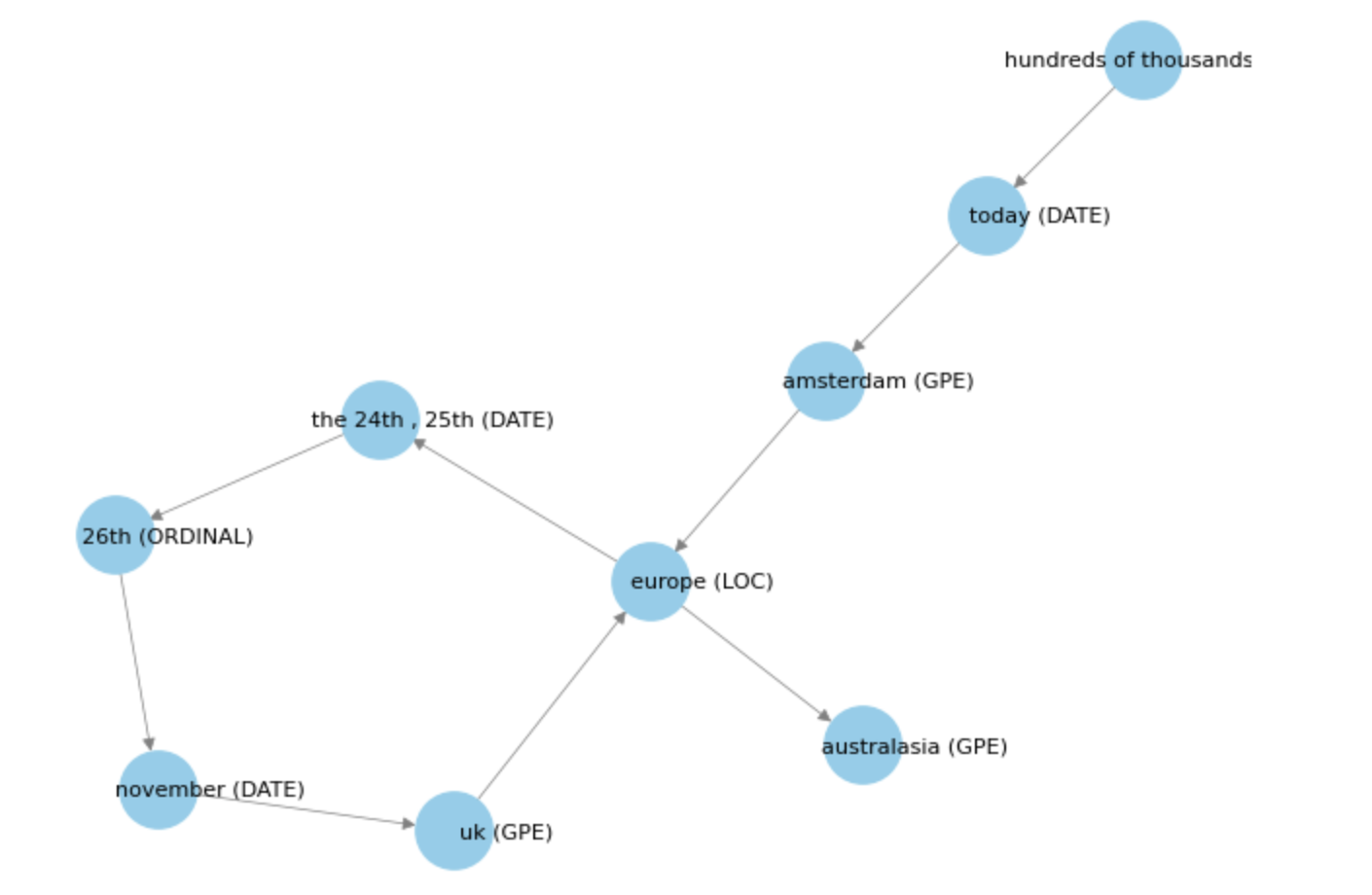
Conclusion:
In conclusion, the journey from spoken words to actionable data is a testament to the incredible advancements in speech-to-text technology and information retrieval systems. The insights gained from the knowledge graph and the various Python scripts discussed underscore the sophistication of current NLP tools in parsing, understanding, and visualizing complex relationships within data. As we've seen, these technologies not only transcribe human speech with impressive accuracy but also discern the nuanced interplay between entities like dates, locations, and key events. This empowers us to transform raw audio streams into structured, queryable knowledge bases that can fuel informed decision-making and unlock a deeper understanding of the content. Whether it's for enhancing accessibility, improving customer experiences, or conducting thorough data analysis, speech-to-text information retrieval stands as a cornerstone of modern data-driven approaches. As we continue to refine these technologies, the horizon of what we can achieve with spoken language as data only broadens, paving the way for an era where every voice, every word, and every connection counts.
As we continue to refine these processes, the possibilities for innovation become limitless. Dive into my Github Repository for a deeper look, and if you're passionate about NLP and Generative AI, I'm always open to collaboration. Let's connect and pioneer the future of this exciting domain together!
Subscribe to my newsletter
Read articles from Jessica Anna James directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jessica Anna James
Jessica Anna James
Welcome to my world of data exploration! I'm Jessica Anna James, a passionate Data Scientist specializing in Computer Vision and Natural Language Processing. Currently pursuing my graduate studies in Data Analytics Engineering at Northeastern University Seattle, my journey in data science has been a thrilling adventure. With expertise in machine learning, deep learning, and transformer-based NLP models, I've crafted innovative solutions, from Computer Vision identity verification to text summarization and machine translation. Join me on my blogging journey as I unravel the intricacies of data science, AI/ML technologies, and NLP techniques. Let's dive into the fascinating world of data together!"