Try MinIO with Python
 Kumar Rohit
Kumar Rohit
This blog is the continuation of our previous blog from Hello MinIO series where we created docker-compose.yml file and our first MinIO buckets in our localhost using docker. Please refer to the article to refer to docker-compose.yml file which we will use in this exercise as well to define and manage our MinIO service in docker.
In this exercise, we will create a small ETL using only Python (boto3) where we will perform below tasks:
Create MinIO S3 bucket (
test-bucket-1)Upload sample data to MinIO (
sample_data.csvtotest-bucket-1)Check if an object exists (
sample_data.csvintest-bucket-1)Copy object from one bucket to another (from
test-bucket-1totest-bucket-2)Download from MinIO to localhost (from
test-bucket-2tolocalhost)Delete object from MinIO bucket (from
test-bucket-1)
We will ship a code files which performs the above tasks as an ETL job. To accomplish this, we would need 4 files:
1.
try_minio_with_python.py- python script which performs the above tasks2.
sample_data.csv- sample dataset that will go from local to s3 bucket3.
pyproject.toml- dependency/package management for python poetry4.
Dockerfile.etl- docker compose specifications to define ETL job
Note: We do not need to install this library in our localhost for this exercise, because we will be installing this on the containers instead. But for your own curiosity, if you want to install boto3 on your localhost, you can do so by running this command in your linux terminal - pip3 install boto3. Verify if your installation was successful terminal using command - pip3 list | grep "boto3". If boto3 is installed already, you would see an output like this:
$ pip3 list | grep "boto3"
boto3 1.29.6
1. Building try_minio_with_python.py file
In order to interact with S3 bucket, we are using boto3.client() method to create a low level service client for interacting with MinIO bucket via s3 protocol. Note that we are supplying the keys (access-key, secret-key)and minio_endpoint URL as specified in the docker-compose.yml file we created for MinIO service.
import traceback
import boto3
from botocore.exceptions import NoCredentialsError
# Set your MinIO credentials and endpoint
minio_access_key = 'minioaccesskey'
minio_secret_key = 'miniosecretkey'
minio_endpoint = 'http://minio-server:9000'
# Create an S3 client
def get_s3_client():
try:
s3 = boto3.client(
's3',
endpoint_url=minio_endpoint,
aws_access_key_id=minio_access_key,
aws_secret_access_key=minio_secret_key
)
return s3
except NoCredentialsError:
print("Credentials not available")
except Exception as e:
print(f"Exception occurred while creating S3 client!\n{e}")
traceback.print_exc()
Now let's go step by step and try to execute the tasks we listed at the beginning of this section.
Create MinIO S3 bucket
# Create a bucket if not exists def create_minio_bucket(bucket_name): # Create a bucket in MinIO try: s3 = get_s3_client() # Check if the bucket already exists response = s3.list_buckets() existing_buckets = [bucket['Name'] for bucket in response.get('Buckets', [])] if bucket_name in existing_buckets: print(f"Bucket {bucket_name} already exists") else: s3.create_bucket(Bucket=bucket_name) print(f"Bucket {bucket_name} created successfully") except NoCredentialsError: print("Credentials not available")In the code snippet above, we are checking if the bucket with
bucket_namealready exists. Only if the bucket does not exist, we will create a new one.Upload sample data to MinIO
# Upload data from local to S3 bucket def upload_to_s3(file_path, bucket_name, object_name): # Upload a file to MinIO try: s3 = get_s3_client() # Create bucket if not exists create_minio_bucket(bucket_name) # Upload the file to s3 bucket s3.upload_file(file_path, bucket_name, object_name) print(f"File uploaded successfully to {bucket_name}/{object_name}") except FileNotFoundError: print("The file was not found") except NoCredentialsError: print("Credentials not available")The code snippet above defines a function
upload_to_s3which takes three argumentsfile_path: the path on the localhost for the file to be uploadedbucket_name: the name of the s3 bucket to upload the file toobject_name: the key or path of the object in the S3 bucket
The bucket must already exist! If the bucket does not exist, the upload_file method will raise an S3.ClientError with the error message similar to "NoSuchBucket: The specified bucket does not exist."
Check if an object exists (on s3 bucket)
# Check if an object exists in a bucket def check_object_exists(source_bucket_name, object_name): # Check if an object exists in MinIO try: s3 = get_s3_client() response = s3.head_object(Bucket=source_bucket_name, Key=object_name) print(f"Object {object_name} exists in {source_bucket_name}") except NoCredentialsError: print("Credentials not available") except s3.exceptions.NoSuchKey: print(f"Object {object_name} does not exist in {source_bucket_name}")The above code snippet defines a method which takes s3 bucket name and object name as inpout and checks if the object exists or not.
Copy object from one bucket to another
# Check if an object from one bucket to another def copy_object( source_bucket_name, source_object_name, destination_bucket_name, destination_object_name): # Copy an object in MinIO try: # Ensure the destination bucket exists create_minio_bucket(destination_bucket_name) s3 = get_s3_client() s3.copy_object( Bucket=destination_bucket_name, CopySource={'Bucket': source_bucket_name, 'Key': source_object_name}, Key=destination_object_name ) print(f"Object {source_bucket_name}/{source_object_name} copied to {destination_bucket_name}/{destination_object_name}") except NoCredentialsError: print("Credentials not available")Above code snippet defines a method which moves an object from one s3 bucket to another. This method takes following arguments:
source_bucket_name: bucket name where source file residessource_object_name: object key (path) of source file in source bucketdestination_bucket_name: bucket name where file needs to be copieddestination_object_name: object key (path) of file in destination bucket
Download from MinIO to localhost
# Download data from S3 bucket to local def download_from_s3(source_bucket_name, object_name, local_file_path): # Download a file from MinIO try: s3 = get_s3_client() s3.download_file(source_bucket_name, object_name, local_file_path) print(f"File downloaded successfully to local [{local_file_path}]") except NoCredentialsError: print("Credentials not available")The above code snippet defines a method to download a file from s3 bucket to localhost. It takes three arguments:
source_bucket_name: name of the bucket where the file residesobject_name: object key (path) of file on source bucketlocal_file_path: target location for the downloaded file
Delete object from MinIO bucket
# Delete an object from bucket def delete_object(bucket_name, object_name): # Delete an object from MinIO bucket try: s3 = get_s3_client() s3.delete_object(Bucket=bucket_name, Key=object_name) print(f"Object {object_name} deleted from {bucket_name}") except NoCredentialsError: print("Credentials not available")The above code snippet defines a method which deletes an object from s3 bucket and it takes two arguments:
bucket_name: name of the bucket where the file residesobject_name: object key (path) of the file
Putting it all together in file try_minio_with_python.py:
import traceback
import boto3
from botocore.exceptions import NoCredentialsError
# Set your MinIO credentials and endpoint
minio_access_key = 'miniousername'
minio_secret_key = 'miniopassword'
minio_endpoint = 'http://minio-server:9000'
source_bucket_name = 'test-bucket-1'
destination_bucket_name = 'test-bucket-2'
# FUNCTIONS
# =========
# Create an S3 client
def get_s3_client():
try:
s3 = boto3.client(
's3',
endpoint_url=minio_endpoint,
aws_access_key_id=minio_access_key,
aws_secret_access_key=minio_secret_key
)
return s3
except NoCredentialsError:
print("Credentials not available")
except Exception as e:
print(f"Exception occurred while creating S3 client!\n{e}")
traceback.print_exc()
# Create a bucket if not exists
def create_minio_bucket(bucket_name):
# Create a bucket in MinIO
try:
s3 = get_s3_client()
# Check if the bucket already exists
response = s3.list_buckets()
existing_buckets = [bucket['Name'] for bucket in response.get('Buckets', [])]
if bucket_name in existing_buckets:
print(f"Bucket {bucket_name} already exists")
else:
s3.create_bucket(Bucket=bucket_name)
print(f"Bucket {bucket_name} created successfully")
except NoCredentialsError:
print("Credentials not available")
# Check if an object exists in a bucket
def check_object_exists(source_bucket_name, object_name):
# Check if an object exists in MinIO
try:
s3 = get_s3_client()
response = s3.head_object(Bucket=source_bucket_name, Key=object_name)
print(f"Object {object_name} exists in {source_bucket_name}")
except NoCredentialsError:
print("Credentials not available")
except s3.exceptions.NoSuchKey:
print(f"Object {object_name} does not exist in {source_bucket_name}")
# Check if an object from one bucket to another
def copy_object(
source_bucket_name,
source_object_name,
destination_bucket_name,
destination_object_name):
# Copy an object in MinIO
try:
# Ensure the destination bucket exists
create_minio_bucket(destination_bucket_name)
s3 = get_s3_client()
s3.copy_object(
Bucket=destination_bucket_name,
CopySource={'Bucket': source_bucket_name, 'Key': source_object_name},
Key=destination_object_name
)
print(f"Object {source_bucket_name}/{source_object_name} copied to {destination_bucket_name}/{destination_object_name}")
except NoCredentialsError:
print("Credentials not available")
# Delete an object from bucket
def delete_object(bucket_name, object_name):
# Delete an object from MinIO bucket
try:
s3 = get_s3_client()
s3.delete_object(Bucket=bucket_name, Key=object_name)
print(f"Object {object_name} deleted from {bucket_name}")
except NoCredentialsError:
print("Credentials not available")
# Upload data from local to S3 bucket
def upload_to_s3(file_path, bucket_name, object_name):
# Upload a file to MinIO
try:
s3 = get_s3_client()
# Create bucket if not exists
create_minio_bucket(bucket_name)
# Upload the file to s3 bucket
s3.upload_file(file_path, bucket_name, object_name)
print(f"File uploaded successfully to {bucket_name}/{object_name}")
except FileNotFoundError:
print("The file was not found")
except NoCredentialsError:
print("Credentials not available")
# Download data from S3 bucket to local
def download_from_s3(source_bucket_name, object_name, local_file_path):
# Download a file from MinIO
try:
s3 = get_s3_client()
s3.download_file(source_bucket_name, object_name, local_file_path)
print(f"File downloaded successfully to local [{local_file_path}]")
except NoCredentialsError:
print("Credentials not available")
# ACTION
# ======
# 1. Create MinIO bucket
create_minio_bucket(source_bucket_name)
# 2. Upload to MinIO
# Note: we copied our sample data (local) /opt/sample_data/sample_data.csv in Dockerfile.etl
upload_to_s3('/opt/sample_data/sample_data.csv', source_bucket_name, 'sample_data/sample_data.csv')
# 3. Check if an object exists (on source bucket)
check_object_exists(source_bucket_name, 'sample_data/sample_data.csv')
# 4. Copy object from one bucket to another
copy_object(source_bucket_name, 'sample_data/sample_data.csv', destination_bucket_name, 'sample_data/sample_data.csv')
# 5. Download from MinIO
download_from_s3(source_bucket_name, 'sample_data/sample_data.csv', '/opt/sample_data/sample_data1.csv')
# 6. Delete object from MinIO bucket
delete_object(source_bucket_name, 'sample_data/sample_data.csv')
2. Creating sample_data.csv file
Create a file in project root directory with name sample_data.csv and add the contents as provided below:
1,A,100
2,B,200
3,C,300
3. Creating pyproject.toml file
This file is needed to define and manage the dependencies that a python application requires. It's a neat way of managing libraries in Python applications, something akin to Maven does for Java applications.
Create the file pyproject.toml in project root directory and add the below lines to the file:
[tool.poetry]
name = "spark-etl"
version = "0.1.0"
description = "This is Spark ETL"
authors = ["Kumar Rohit"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.11"
pyspark = "^3.5.0"
psycopg2-binary = "^2.9.9"
boto3 = "^1.29.7"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
4. Creating Dockerfile.etl file
This is the most important file because this will define how to create the container application to execute our ETL. This would define what dependencies to install in the container, where the code and data files are supposed to be and how the execution needs to happen. Create this file in the project root directory itself with following contents:
FROM python:3.11
# Adding JDK - Required for PySpark
COPY --from=openjdk:8-jre-slim /usr/local/openjdk-8 /usr/local/openjdk-8
ENV JAVA_HOME /usr/local/openjdk-8
RUN update-alternatives --install /usr/bin/java java /usr/local/openjdk-8/bin/java 1
# Adding general shell commands
# Useful for debugging the container
RUN apt-get update && apt-get install -y wget vim cron
RUN echo "alias ll='ls -lrt'" >> ~/.bashrc
WORKDIR /opt/
# Install python libraries
RUN pip install poetry pyspark boto3
COPY pyproject.toml /opt/pyproject.toml
RUN poetry install
# Copying our read/write code
COPY try_minio_with_python.py try_minio_with_python.py
RUN chmod +x /opt/try_minio_with_python.py
# Adding sample data in container's local storage
RUN mkdir -p /opt/sample_data/
COPY sample_data.csv /opt/sample_data/
RUN chmod 777 /opt/sample_data/sample_data.csv
After adding all the above 4 files, we should have a folder structure similar to this:
$ tree .
.
├── Dockerfile.etl
├── data
│ └── first-bucket
├── docker-compose.yml
├── pyproject.toml
├── sample_data.csv
└── try_minio_with_python.py
3 directories, 5 files
Once all 4 files are in place, open the docker-compose.yml file and define an etl service like this:
etl:
build:
context: .
dockerfile: Dockerfile.etl
container_name: etl
environment:
- PYTHONUNBUFFERED=1
depends_on:
- minio
After adding the above snippet, the new docker-compose.yml file would look like this:
version: '3'
services:
minio:
image: minio/minio
container_name: minio-server
ports:
- "9000:9000"
- "9090:9090"
environment:
MINIO_ACCESS_KEY: minioaccesskey
MINIO_SECRET_KEY: miniosecretkey
volumes:
- /Users/kumarrohit/blogging/minio/data:/data
command: server /data --console-address ":9090"
etl:
build:
context: .
dockerfile: Dockerfile.etl
container_name: etl
environment:
- PYTHONUNBUFFERED=1
depends_on:
- minio
Now, let us execute our python ETL to play around with MinIO buckets. We need to execute this command to trigger the ETL image build and execution:
$ docker compose run -it etl python /opt/try_minio_with_python.py
Successful execution would result in something like this (observe last few lines which are consle outputs from our python application):
[+] Creating 1/0
✔ Container minio-server Running 0.0s
[+] Building 4.4s (23/23) FINISHED docker:desktop-linux
=> [etl internal] load build definition from Dockerfile.etl 0.0s
=> => transferring dockerfile: 932B 0.0s
=> [etl internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [etl internal] load metadata for docker.io/library/python:3.11 3.8s
=> [etl internal] load metadata for docker.io/library/openjdk:8-jre-slim 2.3s
=> [etl auth] library/python:pull token for registry-1.docker.io 0.0s
=> [etl auth] library/openjdk:pull token for registry-1.docker.io 0.0s
=> [etl] FROM docker.io/library/openjdk:8-jre-slim@sha256:53186129237fbb8bc0a12dd36da6761f4c7a2a20233c20d4eb0d497e4045a4f5 0.0s
=> [etl internal] load build context 0.0s
=> => transferring context: 5.11kB 0.0s
=> [etl stage-0 1/14] FROM docker.io/library/python:3.11@sha256:63bec515ae23ef6b4563d29e547e81c15d80bf41eff5969cb43d034d333b63b8 0.0s
=> CACHED [etl stage-0 2/14] COPY --from=openjdk:8-jre-slim /usr/local/openjdk-8 /usr/local/openjdk-8 0.0s
=> CACHED [etl stage-0 3/14] RUN update-alternatives --install /usr/bin/java java /usr/local/openjdk-8/bin/java 1 0.0s
=> CACHED [etl stage-0 4/14] RUN apt-get update && apt-get install -y wget vim cron 0.0s
=> CACHED [etl stage-0 5/14] RUN echo "alias ll='ls -lrt'" >> ~/.bashrc 0.0s
=> CACHED [etl stage-0 6/14] WORKDIR /opt/ 0.0s
=> CACHED [etl stage-0 7/14] RUN pip install poetry pyspark boto3 0.0s
=> CACHED [etl stage-0 8/14] COPY pyproject.toml /opt/pyproject.toml 0.0s
=> CACHED [etl stage-0 9/14] RUN poetry install 0.0s
=> [etl stage-0 10/14] COPY try_minio_with_python.py try_minio_with_python.py 0.0s
=> [etl stage-0 11/14] RUN chmod +x /opt/try_minio_with_python.py 0.1s
=> [etl stage-0 12/14] RUN mkdir -p /opt/sample_data/ 0.3s
=> [etl stage-0 13/14] COPY sample_data.csv /opt/sample_data/ 0.0s
=> [etl stage-0 14/14] RUN chmod 777 /opt/sample_data/sample_data.csv 0.1s
=> [etl] exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:2c81890887f1d080b46625f3282fd570e1555680a6107e7c3fd31db3cca815ed 0.0s
=> => naming to docker.io/library/minio-etl 0.0s
Bucket test-bucket-1 created successfully
Bucket test-bucket-1 already exists
File uploaded successfully to test-bucket-1/sample_data/sample_data.csv
Object sample_data/sample_data.csv exists in test-bucket-1
Bucket test-bucket-2 created successfully
Object test-bucket-1/sample_data/sample_data.csv copied to test-bucket-2/sample_data/sample_data.csv
File downloaded successfully to local [/opt/sample_data/sample_data1.csv]
Object sample_data/sample_data.csv deleted from test-bucket-1
And with this, we are able to pay around with MinIO Buckets. We can double check the new buckets were created from the MinIO Browser at: http://localhost:9090/browser
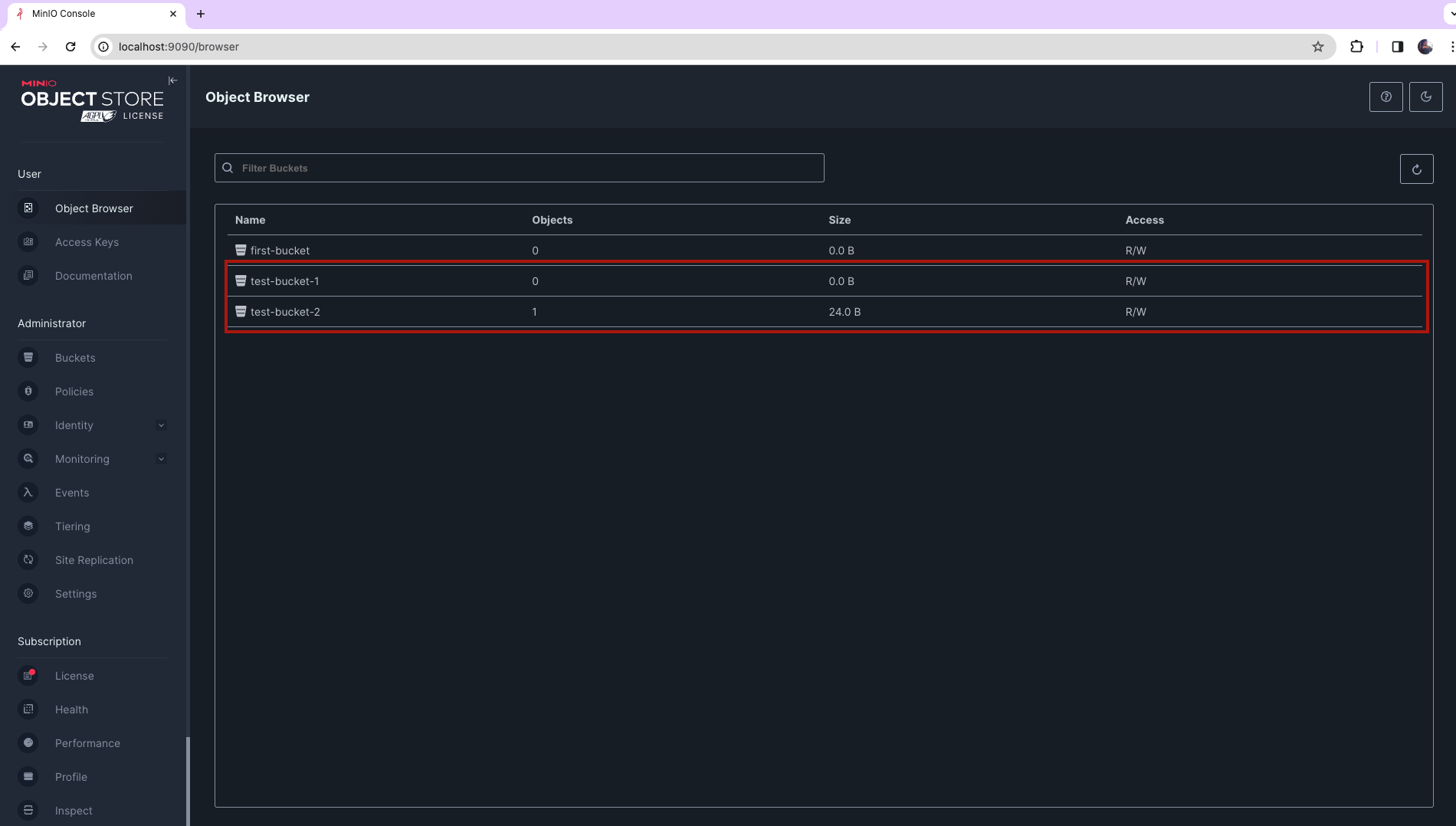
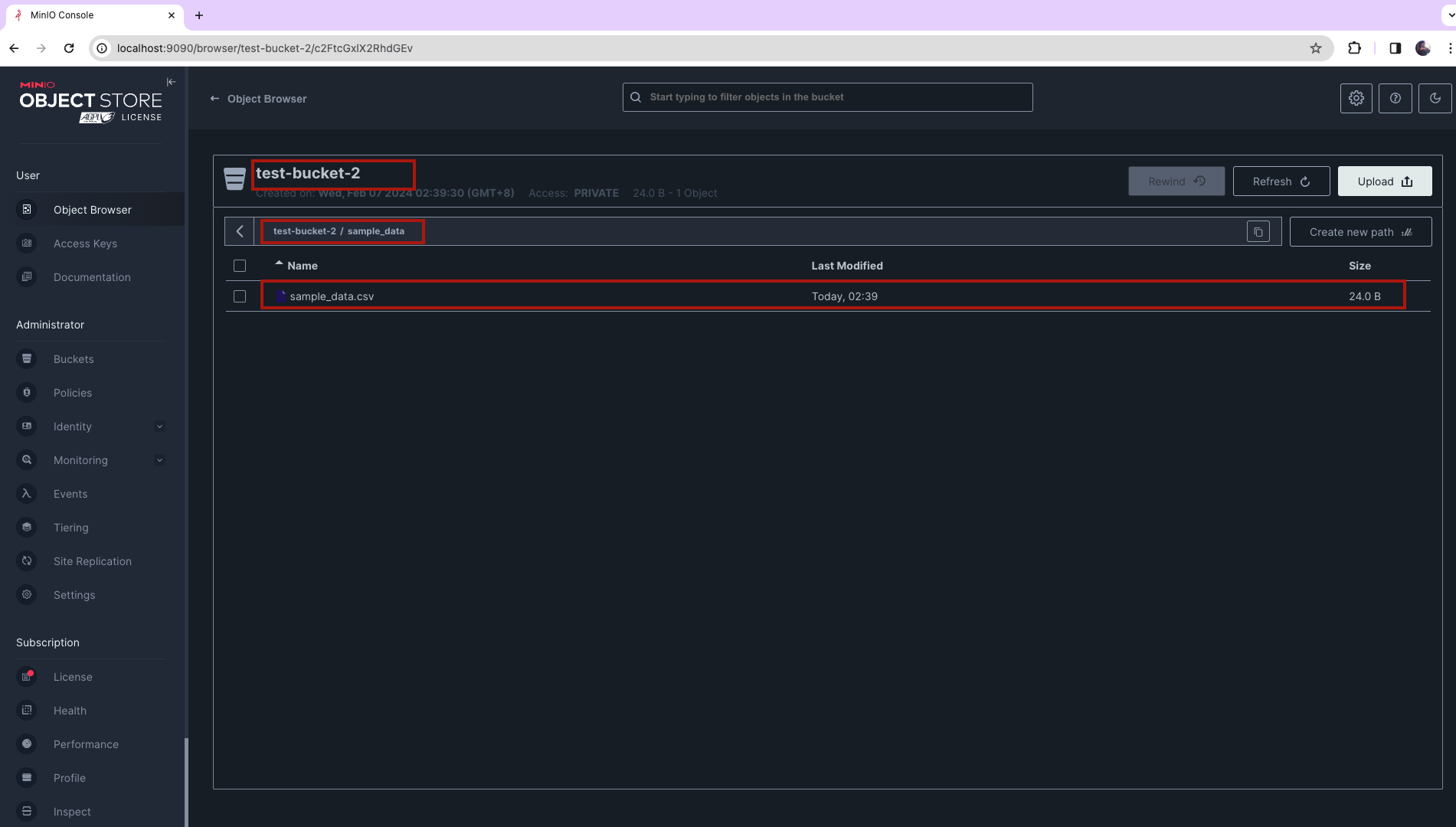
sample_data.csv got moved to test-bucket-2 and this was executed by our python ETL.
With this we are concluding the second installment of the Hello MinIO series. In the next blog, we will discuss interacting with MinIO bucket using PySpark. You can find all the files created for this blog post article in my GitHub.
Thank you again for reading till the end. Hope this post was as exiting for you as it was for me!
Subscribe to my newsletter
Read articles from Kumar Rohit directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kumar Rohit
Kumar Rohit
I am a Data Engineer by profession and a lifelong learner by passion. To begin, I'd like to share some of the problems that have kept me pondering for a while and the valuable lessons I have learnt along the way.