Choosing the Right Spark: Unraveling the Dynamics of Sigmoid, Tanh, and ReLU in Neural Networks
 Saurabh Naik
Saurabh Naik
Introduction:
In the intricate realm of deep learning, activation functions are the unsung heroes, shaping the behavior of neural networks. Each activation function brings its own set of characteristics, advantages, and pitfalls. In this blog post, we embark on an exploration of three fundamental activation functions—Sigmoid, Tanh, and ReLU—unveiling their mathematical underpinnings and dissecting their strengths and weaknesses.
1. Sigmoid Activation Function:
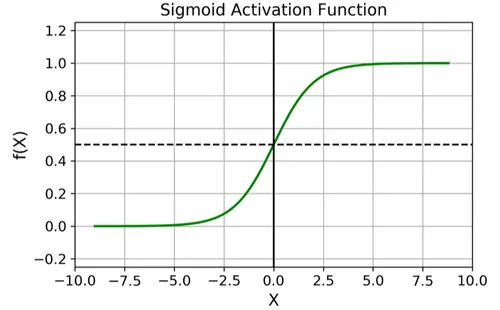
Mathematical Formula:
\([ \text{Sigmoid}(x) = \frac{1}{1 + e^{-x}} ]\)
Ranges:
\([ 0 \leq \text{Sigmoid}(x) \leq 1 ]\)
Advantages:
a. Binary Classification Output: The output between 0 and 1 makes Sigmoid ideal for binary classification, representing probabilities.
b. Differentiability: Sigmoid is differentiable, facilitating gradient-based optimization algorithms.
c. Non-linearity: Sigmoid introduces non-linearity, enabling the network to learn complex relationships.
Disadvantages:
a. Vanishing Gradient: Sigmoid is prone to the vanishing gradient problem due to saturation.
b. Not Zero-Centered: Lack of zero-centering makes convergence slow and computationally expensive.
c. Slow Convergence: The exponential component in the formula contributes to slow convergence.
2. Tanh Activation Function:
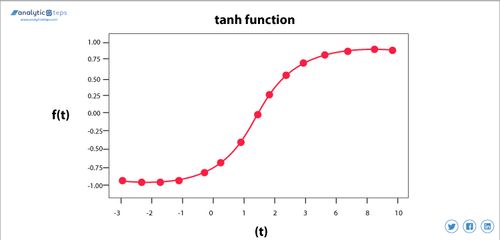
Mathematical Formula:
[ \(\text{Tanh}(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}\) ]
Ranges:
[ \(-1 \leq \text{Tanh}(x) \leq 1\) ]
Advantages:
a. Differentiability: Tanh is differentiable, crucial for backpropagation during training.
b. Non-linearity: Tanh introduces non-linearity, enhancing the network's capacity to model complex relationships.
c. Zero-Centered: Being zero-centered helps in faster convergence.
Disadvantages:
a. Saturating Function: Tanh suffers from saturation, similar to the sigmoid function.
b. Computational Expense: The exponential component makes Tanh computationally expensive.
3. ReLU Activation Function:

Mathematical Formula:
[ \(\text{ReLU}(x) = \max(0, x)\) ]
Ranges:
[ \(0 \leq \text{ReLU}(x) < +\infty\) ]
Advantages:
a. Non-linearity: ReLU is a non-linear function, crucial for capturing complex patterns.
b. Not Saturated in Positive Region: Avoids saturation in the positive region, mitigating vanishing gradient issues.
c. Computationally Inexpensive: Simple computation enhances efficiency.
d. Faster Convergence: Generally converges faster than saturating activation functions.
Disadvantages:
a. Non-Differentiability: ReLU is not differentiable at zero, potentially causing issues during optimization.
b. Not Zero-Centric: Lacks zero-centering, potentially slowing convergence.
Conclusion:
In the dynamic landscape of deep learning, choosing the right activation function is a critical decision that can significantly impact the performance of neural networks. Sigmoid, Tanh, and ReLU each bring their own strengths and weaknesses to the table, offering a diverse toolkit for practitioners to navigate the complexities of model training and optimization. Understanding these activation functions empowers data scientists and engineers to make informed choices tailored to the specific requirements of their neural network architectures.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com