"MongoDB's Data Ballet: Choreographing Brilliance with Aggregate Pipelines in Backend Mastery"
 Nishant Tomer
Nishant Tomer
Introduction:
In the realm of backend development, where data management and retrieval are paramount, MongoDB stands as a formidable choice. However, to truly harness its capabilities, developers turn to Aggregate Pipelines – a powerful tool for transforming, aggregating, and querying data in MongoDB. This comprehensive guide aims to delve deep into the intricacies of MongoDB Aggregate Pipelines, exploring their fundamental concepts, use cases, and best practices to empower developers in crafting robust and performant backend solutions.
Understanding Aggregate Pipelines:
Introduction to Aggregate Pipelines:
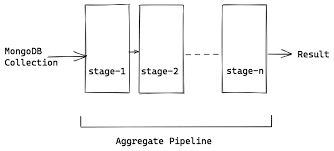
- Aggregate Pipelines in MongoDB provide a flexible framework for processing and transforming data within the database. It operates on the concept of a pipeline, where a sequence of stages is applied to the data to perform various operations.
Key Components:
- Breaking down the key components of an aggregate pipeline, including stages, operators, expressions, and the aggregation framework's syntax.
Aggregate Pipeline Stages:
$match Stage:
- Using the
$matchstage to filter and select documents based on specific criteria, optimizing data retrieval by eliminating unnecessary records.
- Using the
$group Stage:
- Employing the
$groupstage for grouping documents based on specified key criteria and performing various aggregation operations within these groups.
- Employing the
$project Stage:
- Leveraging the
$projectstage to reshape the documents in the pipeline, including or excluding fields, creating computed fields, and defining the document's structure.
- Leveraging the
$sort Stage:
- Utilizing the
$sortstage to arrange documents in a specified order, facilitating efficient sorting operations within the pipeline.
- Utilizing the
$limit and $skip Stages:
- Implementing the
$limitand$skipstages to control the number of documents returned, enabling paginated results in data retrieval.
- Implementing the
$unwind Stage:
- Exploring the
$unwindstage for deconstructing arrays within documents, transforming array fields into separate documents for more granular analysis.
- Exploring the
$lookup Stage:
- Harnessing the power of the
$lookupstage for performing left outer joins between documents in different collections, enriching data with information from related documents.
- Harnessing the power of the
$facet Stage:
- Introducing the
$facetstage to enable the parallel execution of multiple sub-pipelines, providing a powerful mechanism for aggregating and processing data in complex scenarios.
- Introducing the
Use Cases for Aggregate Pipelines:
Complex Data Transformations:
- Performing intricate data transformations that go beyond the capabilities of basic queries, aggregating data from multiple sources into a cohesive result set.
Real-time Analytics:
- Enabling real-time analytics by aggregating and summarizing large datasets, facilitating quick and efficient generation of reports and visualizations.
Data Denormalization:
- Implementing data denormalization strategies using the
$lookupstage to merge related information from different collections, optimizing query performance.
- Implementing data denormalization strategies using the
Pattern Recognition:
- Using aggregate pipelines to recognize patterns and trends within data, enabling intelligent decision-making based on historical or aggregated information.
Faceted Navigation:
- Facilitating faceted navigation in e-commerce or content management systems, allowing users to filter and explore data based on various dimensions.
Best Practices for Using Aggregate Pipelines:
Optimizing Pipeline Stages:
- Carefully crafting pipeline stages to minimize the computational load, choosing the most efficient operators and expressions for each operation.
Indexing for Performance:
- Implementing appropriate indexes to enhance the performance of aggregate pipelines, ensuring that the stages leverage indexed fields for faster data retrieval.
Projection Before Filtering:
- Utilizing projection stages early in the pipeline to reduce the amount of data processed by subsequent stages, improving overall pipeline efficiency.
Understanding Query Planner:
- Familiarizing oneself with the MongoDB query planner and using tools like
explain()to analyze and optimize query execution plans.
- Familiarizing oneself with the MongoDB query planner and using tools like
Awareness of Pipeline Order:
- Understanding the order of execution in aggregate pipelines, ensuring that stages are sequenced appropriately for the desired outcome.
Avoiding Large In-memory Sorts:
- Mitigating the risk of large in-memory sorts by strategically using indexing and
$sortstages, optimizing the overall performance of the pipeline.
- Mitigating the risk of large in-memory sorts by strategically using indexing and
Real-world Implementation Example:
Building a Recommendations System:
- Demonstrating the construction of a recommendation system using aggregate pipelines, aggregating user preferences, filtering data based on user behavior, and delivering personalized recommendations.
Conclusion:
MongoDB Aggregate Pipelines emerge as a cornerstone in backend development, empowering developers to perform sophisticated data transformations and aggregations directly within the database. This comprehensive guide has unraveled the intricacies of aggregate pipelines, exploring their stages, use cases, and best practices. As you embark on your journey with MongoDB, may your aggregate pipelines be robust, your queries be optimized, and your data transformations be seamless, paving the way for efficient and scalable backend solutions.
Thank you for your time. See you in the next one.
Subscribe to my newsletter
Read articles from Nishant Tomer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nishant Tomer
Nishant Tomer
I'm a seasoned backend web developer with a passion for crafting robust and scalable solutions. With expertise in languages such as C/C++, JavaScript, and Node.js and a keen eye for optimizing database performance, I specialize in building the backbone of web applications. I've successfully implemented and maintained various backend systems, ensuring seamless functionality and a positive user experience. I'm excited about the prospect of collaborating on impactful projects and contributing my skills to innovative solutions.