How Database works under to hood. So you know which one to use
 Arya Lanjewar
Arya Lanjewar
So, what's your intuition? The simplest database you can build uses a bash script to write data to a file and retrieve data from that file. If you need to update data, just append the updated data with the same key but a different value. Essentially, there's no direct update of data, just appending (Append-only).
The advantage of using an append-only scheme is that it significantly speeds up writes. You don't need to search through the entire file, which would take O(n) time. The solution is to add indexing, like hash maps. Many databases allow you to add/remove indexes without affecting the database's contents; it only impacts query performance. Writes might slow down due to the additional index, but reads speed up.
This is why databases don't index everything by default—write speed may decrease because of the additional index. However, read speed improves, striking a balance in performance.
Hash Map Indexes:
Let's delve into hash indexes. The concept involves storing keys in memory and values on hard drives, with the address offset stored in memory alongside the keys.
In this setup, keys reside in memory, while values are stored on the disk. When a value is updated, we follow the same append-only process. You might be curious: if we're using hash indexing, why not update instead of appending? I'll address that question after covering some key concepts. Bitcask, a storage engine, employs hash indexing.
Now, you might wonder if only appending would lead to space issues. Yes, and to address this, we've developed background algorithms known as Compaction and merging. However, before delving into these processes, let's first understand segmentation, as it lays the groundwork for compactions and merging.
Segmentation:
Segmentation involves breaking the log into segments of a certain size by closing a segment file when it reaches a specified size and redirecting subsequent writes to a new segment file.
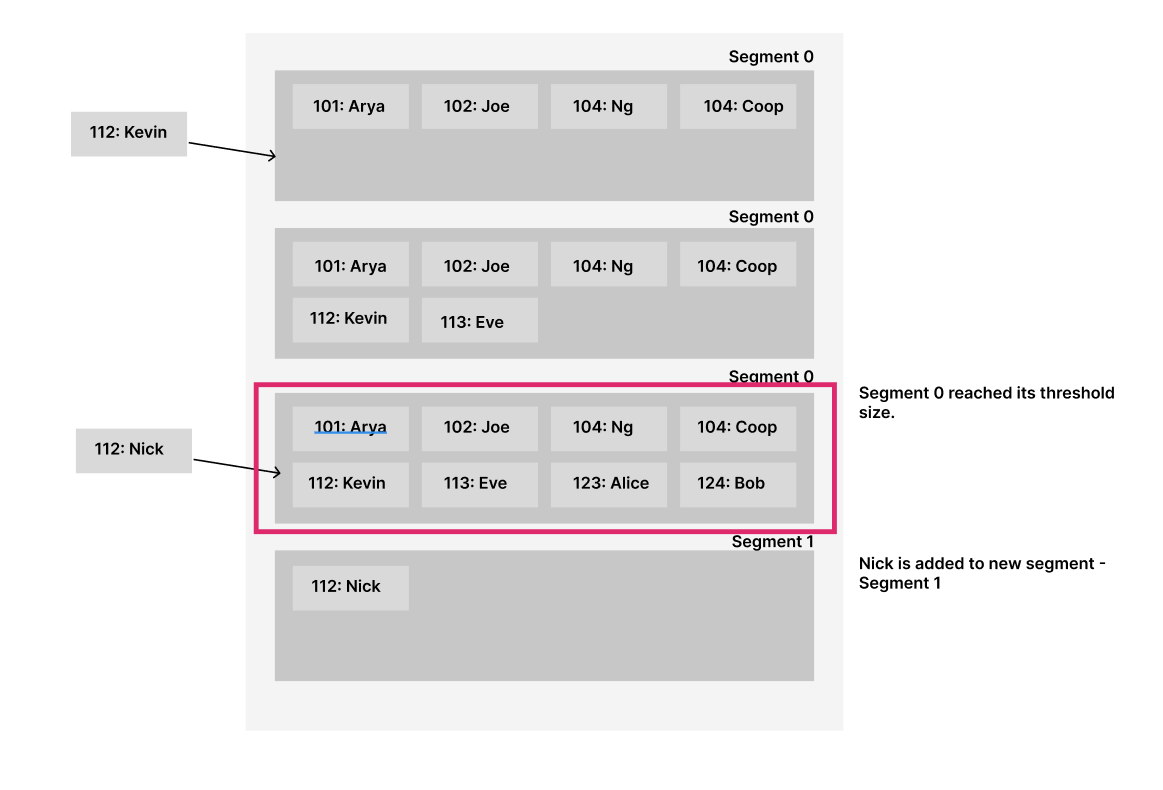
For example, if we set the segment size to 64 KB, once it reaches this size, the segment closes, and the next file is added to a new segment.
Compaction and merging:
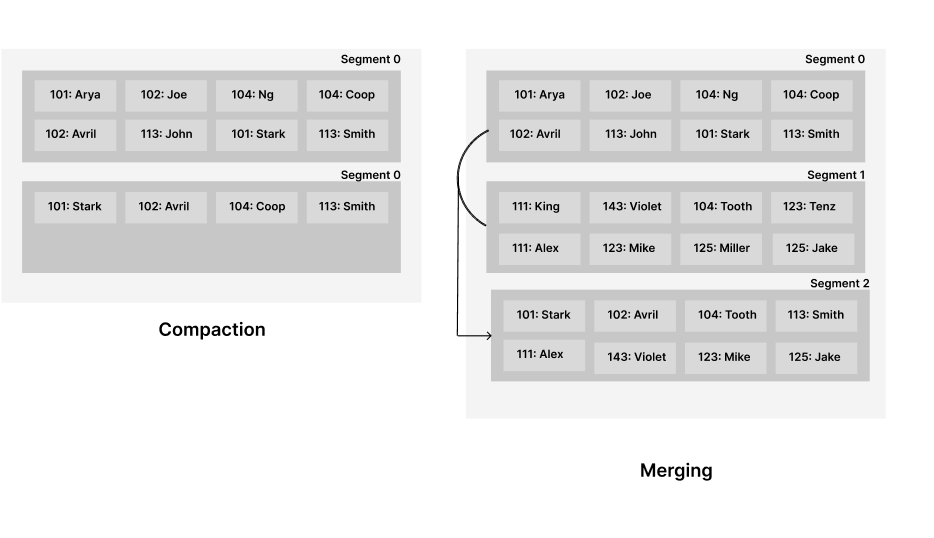
Compaction involves discarding duplicate keys in the log and retaining only the most recent update for each key. Essentially, old keys are deleted, and recently updated keys are kept. Compactions are performed on individual segments. As the compaction process often reduces segment sizes significantly, we can merge all the segments simultaneously while conducting compaction. The merged segment is written to a new file.
Compaction and merging occur in the background, while read requests are served by the old segment. When compaction and merging finish, reads are then served by the new merged segment.
Limitations of Hash Indexes:
Hash indexes have certain constraints that should be considered:
Memory Requirements: Hash tables must fit entirely in memory. Even with compaction and merging, large databases may run out of memory. Storing everything on disk can introduce issues, such as extensive random access demands. This becomes particularly challenging with spinning disks, as the hard disk head moves around, consuming considerable time. Additionally, expanding storage when nearing capacity is costly, and managing hash collisions involves intricate logic.
Inefficiency with Range Queries: Hash indexes are not optimized for range queries. For instance, efficiently scanning through all keys between "cat0000" and "cat9999" is not straightforward. Each key needs to be individually looked up in the hash maps, leading to suboptimal performance.
SSTables and LSM-trees
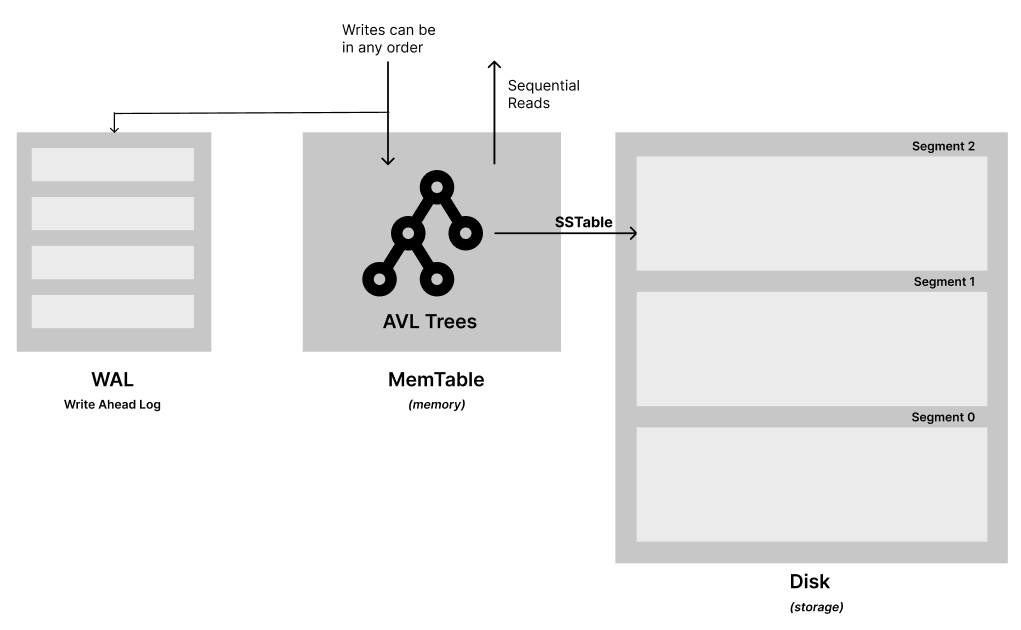
Building on the limitations of hash indexes, we have another data structure that addresses some of the issues with hash maps by sorting the data with respect to keys. The idea is to maintain an in-memory sorted log file that stores writes and, after reaching a certain point, sends that data to the disk in sorted order.
To store data in sorted order in memory, there are effective tree data structures where writes can be in any order, but reads will be sequential. Data structures like AVL trees or Red-Black trees maintain data in a sorted order. This in-memory tree is called a memtable. When the memtable exceeds a certain threshold, typically a few megabytes, it is written out to disk as an SSTable file. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memory instance.
To serve a read request, first try to find the key in the memtable, then in the most recent segment, and subsequently in the next-older segment, and so on.
In the event of a database crash, the most recent writes will be lost. To mitigate this, we can keep a separate log on disk to which every write is immediately appended. Every time the memtable is written out to an SSTable, the corresponding log can be discarded.
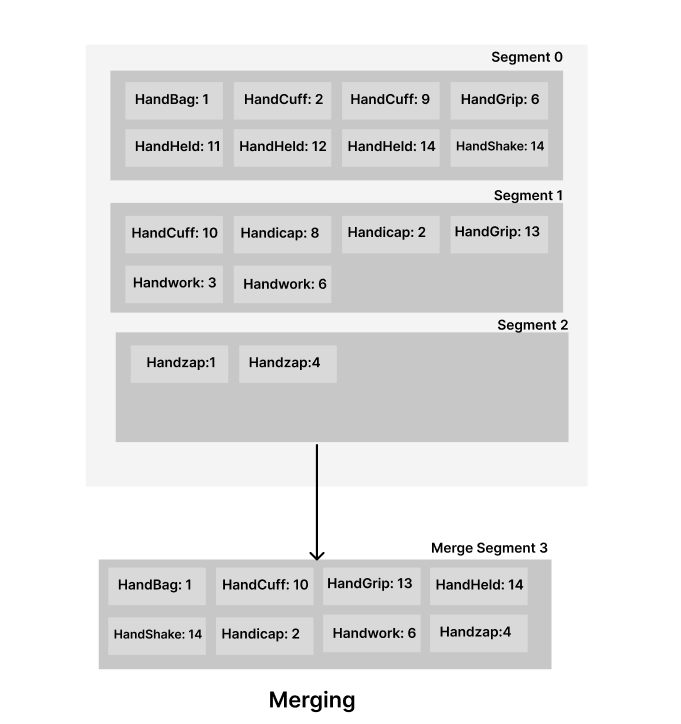
Merging segments in this structure is straightforward, resembling a merge sort. Take your segments and initially select keys in sorted order (for example, 'handBag' comes before 'handCuff' due to the 'B' and 'C', so 'handBag' is chosen first). Then, retrieve the latest value of each key from within the selected segments and write it to the new merged segment. Repeat this process for all the keys. The example below illustrates how this works.
Reading in LSM trees is very easy, you do not have to have the keys for all the data in memory, you can have something like range offset table (in the below example). Let’s say you want to find Alan. You know that to find alan, we need to search between Alice and Bob. The blue shaded region is compressed block. With compressed block you can make range offset tables.
There are some problems in this approach as well like if you search for a key which does not exist, you have to look through the memtable then all the SSTables in the segments all the way back to the oldest segment so that you can surely say that the key does not exist. In order to optimize this kind of access storage engines often use additional Bloom filters.
LevelDB (by Google), RocksDB, HBase and Cassandra uses LSM trees.
B-Trees
B-Trees are another data structure known for their faster reads. Similar to SSTables, B-Trees store keys in sorted order, but their design philosophy sets them apart from LSM trees.
While LSM trees break down memory segments and perform sequential writes, B-Trees break the database into fixed-size blocks or pages and read or write one page at a time. This means we now have an algorithm that is not strictly append-only.
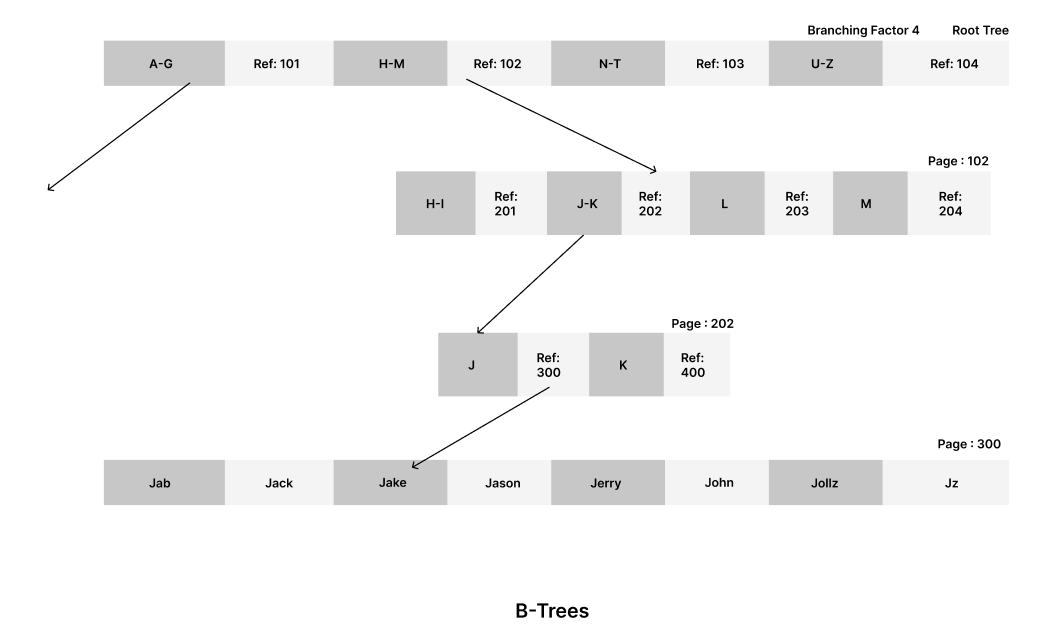
This example illustrates how B-Trees are designed. One page is designated as the root of the B-Tree, and when you want to look up a key, you start at the root. Each page contains some keys and references to child nodes. For example, if you want to find "Jake," you start with the root node, find the reference that leads you to "Jake," and continue until you reach the node where "Jake" is located (a leaf page, as only leaf pages contain individual values). It's akin to a depth-first search.
The number of references to a child page in one page is called the branching factor.
For updating in B-Trees: Go to the key as you would for reading a key and change the value, then write it to the disk.
For inserting in B-Trees: Find the page whose range encompasses the new key and add it to that page. If there isn't enough free space in the page to accommodate the new key, it is split into two half-full pages, and the parent page is updated to account for the new subdivision of key ranges. This algorithm ensures that the tree remains balanced.
Comparing B-Trees and LSM-Trees:
As a rule of thumb, LSM-Trees are typically faster for writes, whereas B-Trees are considered faster for reads. Reads are generally slower on LSM-Trees because they have to check several different data structures and SSTables at different stages of compaction.
Advantages of LSM-Trees:
First, let me explain what write amplification is. Write amplification measures how much data is written to storage compared to the actual data that needs to be updated or inserted. In other words, it quantifies the scenario where one write to the database results in multiple writes to the disk over the course of the database's lifetime.
Which data structure do you think generally exhibits high write amplification?
The answer is LSM-Trees due to their compaction and merging processes. In a write-intensive application, write amplification can incur a direct performance cost: the more a storage engine writes to disk, the fewer writes per second it can handle within the available disk bandwidth.
However, LSM-Trees are typically capable of sustaining higher write throughput than B-Trees. This is partly because they sometimes have lower write amplification (based on the configurations) and partly because of the sequential writes, especially in the case of a magnetic spinning disk where sequential writes are more efficient than random access I/O writes.
Downsides of LSM-Trees:
The compaction process can occasionally interfere with the performance of ongoing reads and writes. Despite efforts by storage engines to perform compaction incrementally and without disrupting concurrent access, disks have limited resources. Consequently, there is a possibility that a request may need to wait while the disk completes an expensive compaction operation.
High write throughput can pose challenges in terms of disk bandwidth when dealing with compaction in databases. The finite write bandwidth of the disk needs to be shared between the initial write (logging and flushing a memtable to disk) and the background compaction threads. While an empty database allows for full disk bandwidth utilization during the initial write, as the database grows, more disk bandwidth is required for compaction.
Poorly configured compaction in high write throughput scenarios can result in a situation where compaction cannot keep up with the incoming writes. This leads to an increasing number of unmerged segments on disk, potentially causing disk space exhaustion. Additionally, read performance is impacted as more segment files need to be checked. SSTable-based storage engines typically do not throttle incoming writes, even when compaction lags behind. Therefore, explicit monitoring is necessary to detect such situations.
B-trees offer an advantage in that each key exists in a single location in the index, unlike log-structured storage engines that may have multiple copies of the same key in different segments. This characteristic makes B-trees appealing for databases aiming to provide strong transactional semantics. In relational databases, where transaction isolation relies on locks on key ranges, B-trees enable direct attachment of locks to the tree.
Despite the consistent and established performance of B-trees for various workloads, log-structured indexes are gaining popularity in new datastores. Determining the better storage engine for a specific use case requires empirical testing, as there is no one-size-fits-all rule. B-trees remain deeply ingrained in database architecture, ensuring their continued relevance, but log-structured indexes offer an alternative worth exploring.
Conclusion
In this blog post, we explored how databases work under the hood, focusing on the concepts of append-only schemes, hash map indexes, SSTables, and LSM-trees. We discussed the advantages and limitations of each approach, as well as their impact on read and write performance.
Append-only schemes provide fast write speeds by avoiding the need to search through the entire file for updates. Hash map indexes allow for efficient data retrieval, but they have memory requirements and are less optimized for range queries.
SSTables and LSM-trees address some of the limitations of hash indexes by sorting data and using merge operations to improve read performance. They introduce concepts like segmentation, compaction, and merging to manage space and optimize read operations.
On the other hand, B-Trees offer faster read performance and a balanced structure that allows for efficient updates and inserts. They operate on fixed-size blocks or pages and provide a depth-first search approach for key lookups.
When comparing LSM-trees and B-Trees, LSM-trees are generally faster for writes, while B-Trees are faster for reads. However, LSM-trees can exhibit higher write amplification due to their compaction process.
Overall, the choice between LSM-trees and B-Trees depends on the specific requirements of the application, such as the read-to-write ratio and the performance trade-offs that can be made.
Understanding how databases work under the hood can help us make informed decisions when designing and optimizing database systems for various use cases.
If you have any feedback or corrections regarding the content of the blog post, please let me know. I would be happy to make any necessary updates or revisions. Your input is valuable in ensuring the accuracy and quality of the information provided. So please don't hesitate to point out any mistakes or areas that need improvement. Thank you for your help in making this blog post as informative and reliable as possible.
Follow me on LinkedIn: www.linkedin.com/in/lanjewar-arya | X : https://twitter.com/AryaLanjew3005
Reference: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann
Subscribe to my newsletter
Read articles from Arya Lanjewar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arya Lanjewar
Arya Lanjewar
3rd year (B.Tech) Computer Science, IIT Bhilai. Full stack web-developer Solidity smart contract developer