Drifts in Machine Learning
 Abhishek
Abhishek
Drift refers to the phenomenon of misalignment in the underlying purpose and objective of a machine learning application. A machine learning model is typically trained using historical data or a closed sample of data. Now, when this model is deployed in production and is ready to make inferences on new unseen data (live data), this application might encounter several challenges. This article will try to address some of these challenges.
Drifts eventually contribute to type 1 and type 2 errors and depending upon the business, this can severely affect the efficacy of the intended objective.
What happens if the distribution of the independent variables changes?
It is quite obvious to expect that the statistical characteristics of a sample data may start changing in the live environment. For instance, there is a classification model that predicts whether the user will buy a fancy product or not by looking at features like age, income, etc. Now, if the user base starts to change from what was observed in the training sample then, the new sample data and the training data may not represent themselves to be sampled from the same population. This event can be referred to be a Data Drift (also called covariate shift).
In case of a data drift, the model is not able to make predictions as confidently as it did with the data distribution similar to its training data.
What happens if the Objective/Task of a trained model has changed over time?
Considering a scenario where a model was trained to detect fraudulent messages, and lately, new subtler methods of committing fraud have been introduced to the market. In such a scenario, the model may not have ever seen such a new fraud technique and hence will fail to capture the fraud event. Neither the training data nor the model were at fault but practically the concept had evolved (drifted or changed) over time. This type of event can be referred to be a Concept Drift or Model Drift.
Concept Drift can occur in three situations:
SITUATION 1: If there is drift in the independent features (or data drift). This is also called Virtual drift where the decision boundary does not necessarily change but there is a shift in the feature distribution and it may serve as an early evaluation of how the model might get affected.
SITUATION 2: The features may not show changes in their distribution, but the target (label) data distribution will change which directly affects the decision boundary. This is an actual case of Model Drift/Concept Drift.
SITUATION 3: This is an extension to the above situations where a combination of situations 1 and 2 contribute to the change in decision boundary.
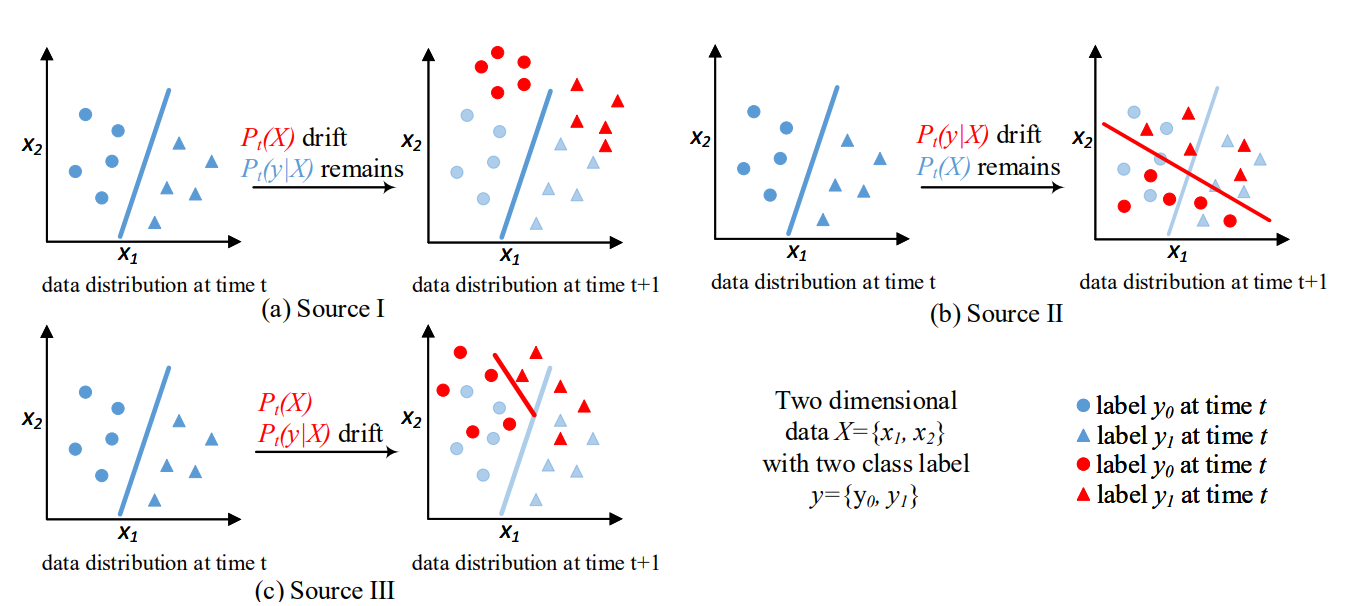
The types of Concept Drift can also be categorized as below:
This is by the nature of distribution changes in target (label) data.
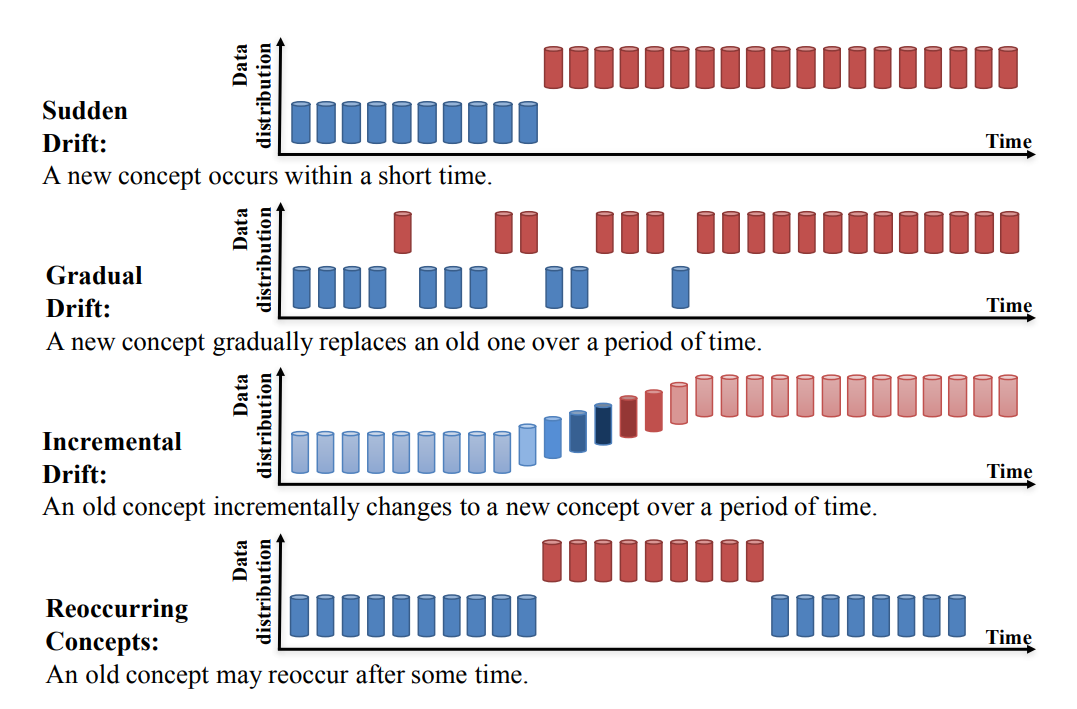
image source: https://arxiv.org/pdf/2004.05785.pdf
Other Drifts:
Other reasons for a drift to occur can simply be because of upstream data changes. This would include scenarios such as certain feature information stopped getting generated from applications which resulted in nulls for a particular column or feature loss.
Observing the meaning and contribution of both data drift and concept drift, it is trivial to monitor both aspects so that an overall degradation in machine learning models can be captured. This information will aid in taking steps in model retraining, continual training, etc.
References:
Subscribe to my newsletter
Read articles from Abhishek directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by