Contextualised and Responsibilized Eventing on AWS
 Omid Eidivandi
Omid Eidivandi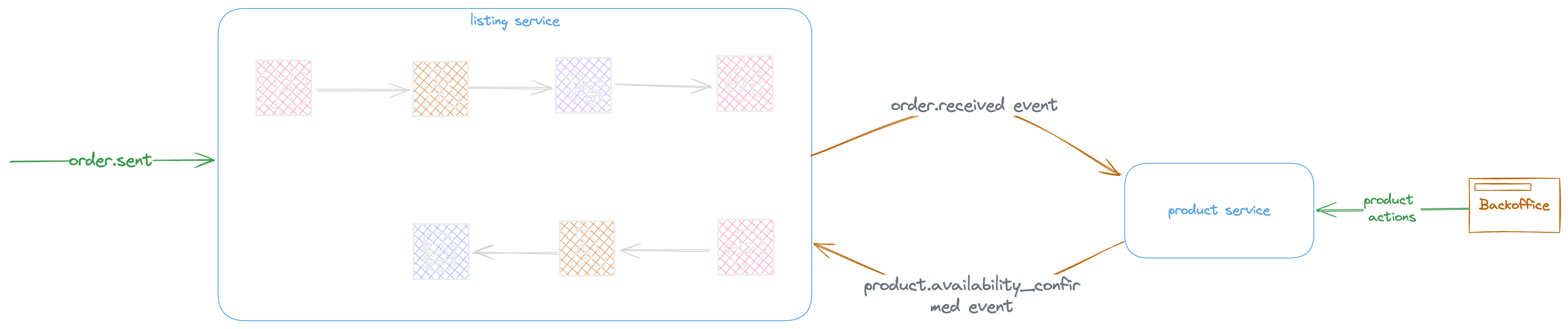
The adoption of event driven architecture became a real challenge of many enterprises since some years and lately raised this adoption bar. The companies achieve the principal pillars of a well architected system by relying on decoupled and asynchronous services communication in real time to keep the overall system state consistent. This approach improves very important bottlenecks of traditional distributed systems like reliability, scalability and performance.
Adoption of micro services was a finer level of improvement in distributed systems but actually those fine grained services behind achieving localised scalability , reliability and performance couldn't solve the overall system experience. Cascading latencies , Cascading failures , cascading downtimes was yet present and hard to resolve. The micro-service design approach was again relied on Request / Response communication over unfair network with its potential drawbacks in terms of system experience.
The actual Distributed system problems was at communication boundaries and putting a huge amount of effort to make every thing service scalable at 10x higher rate seemed overkill. The resolution to those challenges was putting all puzzle pieces together and find from where the local problems are propagated all over the system and the response was the Request / response lines.
The simplest part of these distributed system complexities is achieving the localised improvements. and the hardest part was solving the communication problems.s
Event Driven Challenges
The event driven design is distributed design like traditional distributed and micro service design has some complexities to solve, solving the above mentioned distributed bottlenecks just guided the softwares to the localised optimised state but the synchronous communication bottlenecks became an obstacle. Adopting EDA was a solution to improve those communication bottlenecks but added some inter-component and localised complexities.
The EDA biggest deal, when comes to overall system state and inter-component communication, is the state consistency. delayed propagated state and duplication.
Event Streaming
Event streaming is an operational approach relying on a number of events representing small changes in different services. Event Streaming helps to resolve the Consistency problem as the most important system level challenge in EDA. The delayed and duplication challenges mentioned earlier will be kept localised at service level and must be handled by any context Owner.
Event Streaming on AWS can be achieved using kinesis data streams as a Pull based solution:
The pull based streaming can be achieved by using Kinesis Data Streams with its own pros and cons.
Here an example figure showing the pulling from Kinesis
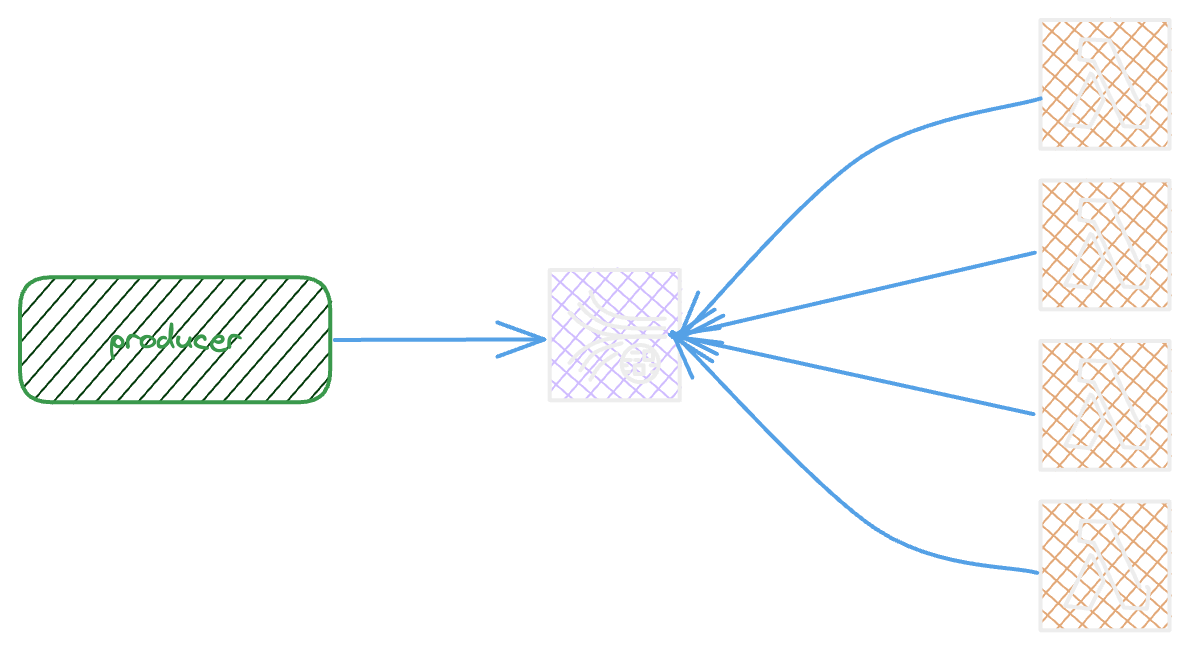
The producer write records in stream
Lambda event source mapping pull the records
Some details :
ESM pulls the kinesis data streams once per second
The Data Streams Guarantee the ordering per partition key
Kinesis has a 2 MB/S , 5 RPS shared by all consumers.
Kinesis Share limits are per shard , adding new shards can be a solution
Let's add some new consumers and run a test to see what happens. imagine we add some consumers up to 15 ( 15 seems enough for this test )
Creating a kinesis Data stream and 15 consumes using CDK
const functionRole = new Role(this, 'FunctionRole', {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole')
]
});
const dataStream = new Stream(this, 'DataStream', {
shardCount: 1,
});
for(let i = 0; i < 15; i++) {
const functionName = `function-${i}`;
const logGroup = new LogGroup(this, `Function-${i}-LogGroup`, {
logGroupName: `/aws/lambda/${functionName}`,
....
});
const consumerFunction = new NodejsFunction(this, `Function-${i}`, {
.....
});
consumerFunction.addEventSource(new KinesisEventSource(dataStream, {
startingPosition: StartingPosition.LATEST,
batchSize: 10,
bisectBatchOnError: true,
retryAttempts: 3
}));
}
dataStream.grantRead(functionRole);
}
Now it can be interesting to see how this solution behaves at build and runtime
Build time:
During the deploy randomly you will face consumer source mapping errors as you reach some small limits but at longterm this will not be a problem
If you have a batch of related records all consumers are implementing the same logic to consume, evaluate last state and processing those events, again this can not be a problem at a given time but think of presenting a new Pending event state between Created and Validated , here all consumers need to reevaluate the logic of state evaluation.
Run time:
How the consumers behave from a latency point of view that is absolutely possible with the known kinesis data streams limits , 5 RPS, 1 second Polling per consumer by ESM. when a throttle happens this leads to a delay in consumer polling.
A single malformed record can act as a poison pill and stop the sequence of records being consumed.
The DLQ does not have the record data, passing the record retention period the event will be completely lost.
If two consumers communicate together after processing of initial reception of an event from kinesis the delay represented above about throttling and latency can initiate problems or add extra communication complexity.
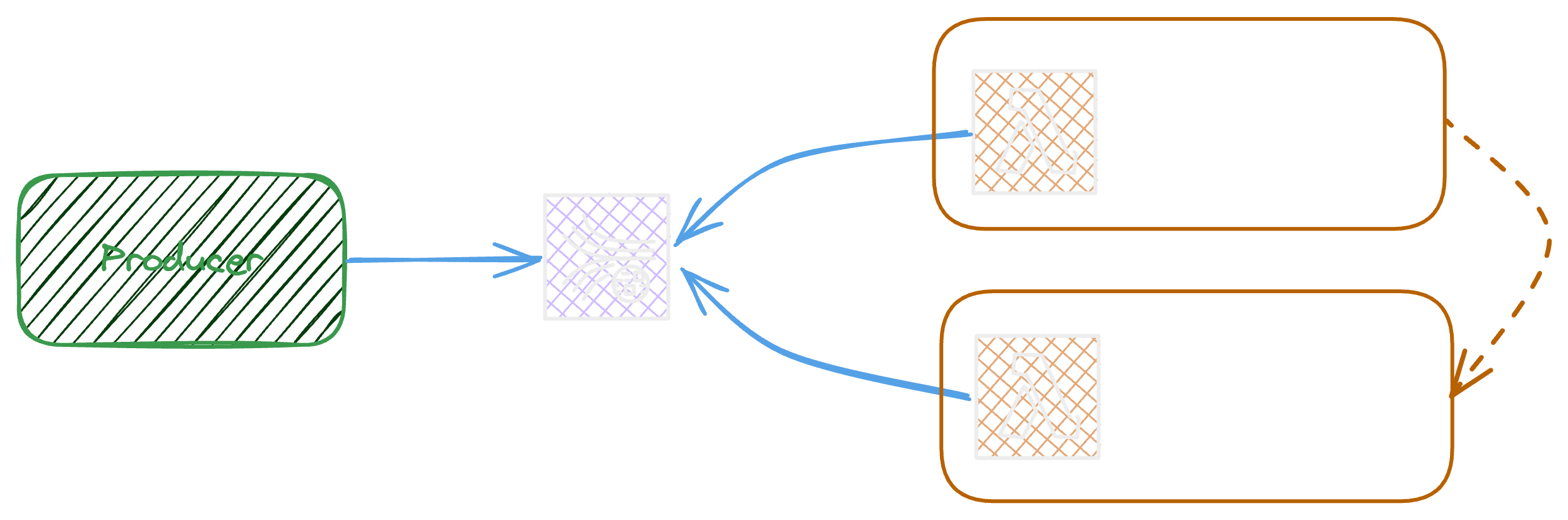
Broadcasting
The event broadcasting is another way of distributing events in an event driven system, this can be achieved using amazon SNS or event bridge bus.
The following figure represents the event broadcasting using SNS
The producer publish events to the topic
The sns will send a copy of event to all subscribers
The sns can distribute the events to different type of subscribers as Lambda, SQS, Http/2, SMS, Mobile Platform and email.
Some details :
The SNS Standard guarantees at least once delivery and does not guarantee ordering
The SNS FIFO guarantees the ordering and partitioning of group of related events.
SNS Quota indicates 100 TPS for subscribe action per account
SNS has a 256KB event size limit
SNS FIFO supports deduplication
Creating a above design using CDK
const functionRole = new Role(this, 'FunctionRole', {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole')
]
});
const topic = new Topic(this, 'Topic');
for(let i = 0; i < 15; i++) {
const functionName = `function-${i}`;
const logGroup = new LogGroup(this, `Function-${i}-LogGroup`, {
logGroupName: `/aws/lambda/${functionName}`,
...
});
const consumerFunction = new NodejsFunction(this, `Function-${i}`, {
...
});
consumerFunction.addEventSource(new SnsEventSource(topic, {}));
}
Build time:
During the deploy randomly you will face subscription errors if number of consumers reach limits but at longterm this will not be a problem
Having the same problem of KDS earlier the consumers can have a duplicated logic to evaluate events, but using SNS this will be harder at consumer side as the SNS distribute events one by one and has no supported batching. a new Pending event state between Created and Validated , here all consumers need to reevaluate the logic of state evaluation but to be able to execute that logic they need to persist the events first and fetch them per batch to evaluate.
The SQS can subscribe to the SNS topic so this can be a serverless and managed way of having Offloading, Batching, Temporary Storage.
Run time:
The SNS event distribution is fast and near realtime.
The events are distributed based on filter policy if configured
The failures are handled in a exponential way and up to 23 days if the subscriber is not reachable.
Each subscription can have a DLQ
The latency and performance of distribution is near realtime even a significant number of subscribers.
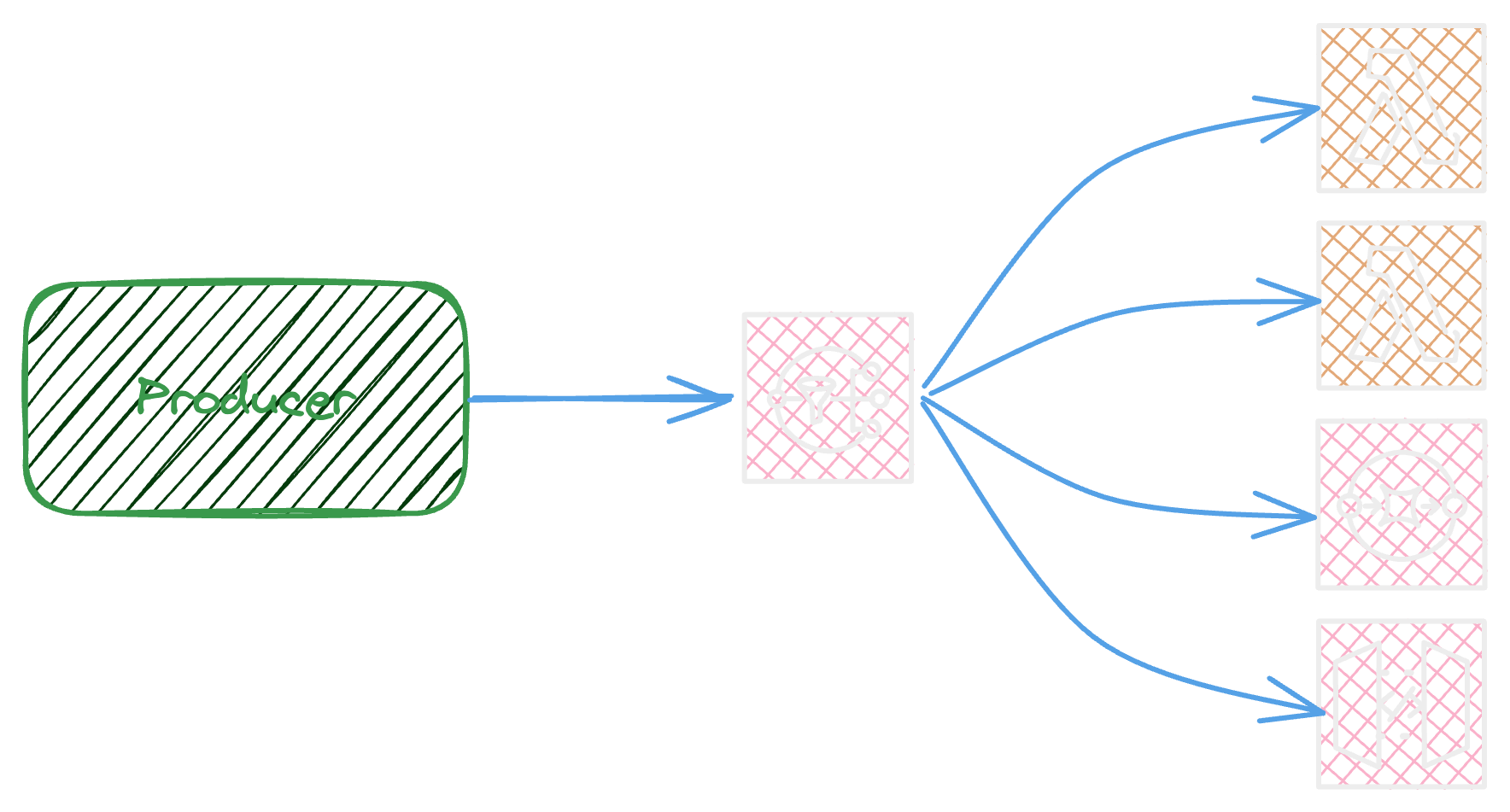
EventBridge is a powerfull service that helps to achieve the event broadcasting, it is a highly scalable and managed service.
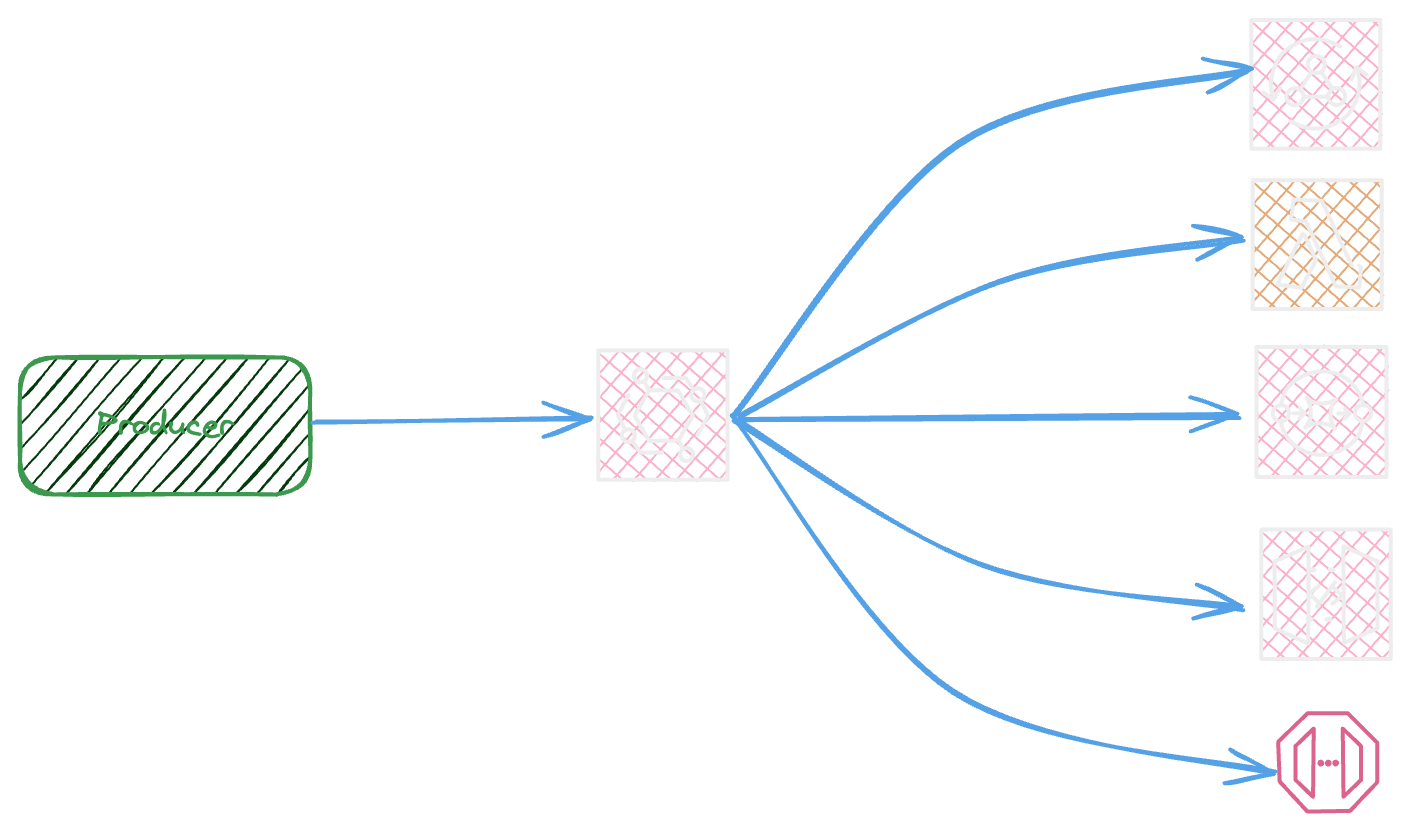
The producer put an event into the bus
The event bus will send a copy of event to each subscriber via rules
The event bridge supports a wide variety of services as a rule target like Api gateway, Api destination, SQS, Kinesis Data Streams, Lambda ( ASYNC ) , AppSync and etc ..
Some details :
The EventBridge provides a at-least-once delivery and does not guarantee ordering
EventBridge Quota indicates 18,750 TPS for rule targeting beyond that the throttling cause delays in event distribution.
EventBridge has 100 rule per bus limit
EventBridge has a 10,000 TPS for put event into the bus
Creating a above design using CDK
const functionRole = new Role(this, 'FunctionRole', {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole')
]
});
const eventbus = new EventBus(this, 'EventBus');
for(let i = 0; i < 15; i++) {
const functionName = `function-${i}`;
const logGroup = new LogGroup(this, `Function-${i}-LogGroup`, {
logGroupName: `/aws/lambda/${functionName}`,
...
});
const consumerFunction = new NodejsFunction(this, `Function-${i}`, {
...
});
new Rule(this, `EventBridgeLambdaInvokeRule-${i}`, {
eventBus: eventbus,
eventPattern: {
detailType: ['my.custom.detailtype'],
},
targets: [ new LambdaFunction(consumerFunction) ]
});
}
Build time:
The duplicated logic problem again persists fro event evaluation, The complexity is same as using SNS per distribution of events one by one and has no supported batching.
The SQS can a target of rule so this can be a serverless and managed way of having Offloading, Batching, Temporary Storage.
Run time:
The events are distributed fast
The events are distributed based on filter policy if configured
The failures are handled in a exponential way and up to 24 hours and up to 185 times if the target is not reachable.
Each rule target can have a DLQ, and each rume can have up to 5 targets.
The latency and performance of distribution is near realtime.
Responsibilities in Design
When designing Event driven architecture the requirements are different based on requirements and the rate of changes by entity that application manages. When designing EDA the relevant questions to ask and brainstorm are somehow as below:
The Rate of changes on a single entity
The variety of event types
The relation or ordered priority between event types
Who are the consumers?
What does care a consumer about?
Is the consumer in the same cell or business domain?
Defining each software responsibilities and how it manages the value to other participants in a distributed system is one of the important pillars of a design, actually this is important to define how we operate.
Ecommerce Example
The example provides a simple scenario to demonstrate a distributed system and how responsibilities around events are shared between different applications.
The operational process will be as illustrated, from the order arrival until the product delivery. it s clear that in operational perspective this design works.
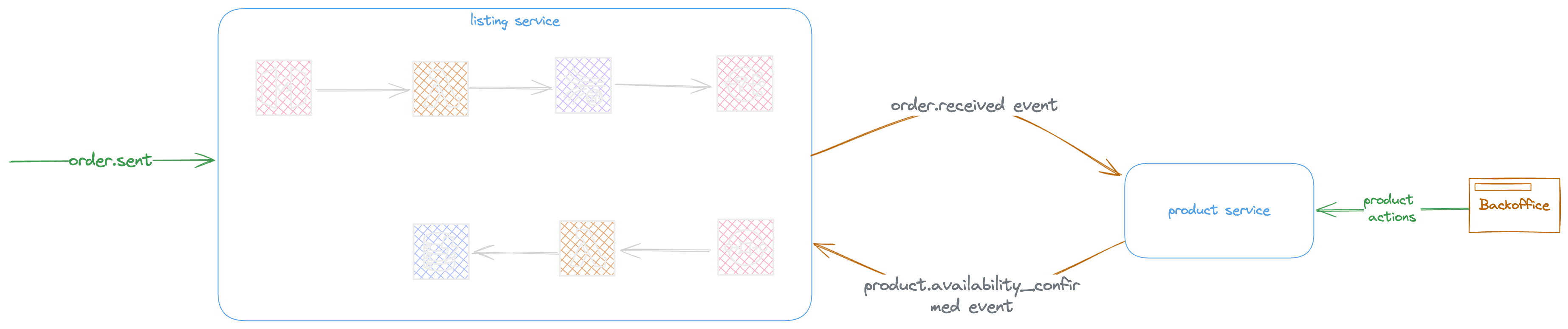
Zooming and focusing on Product and order service shows more details about the details.
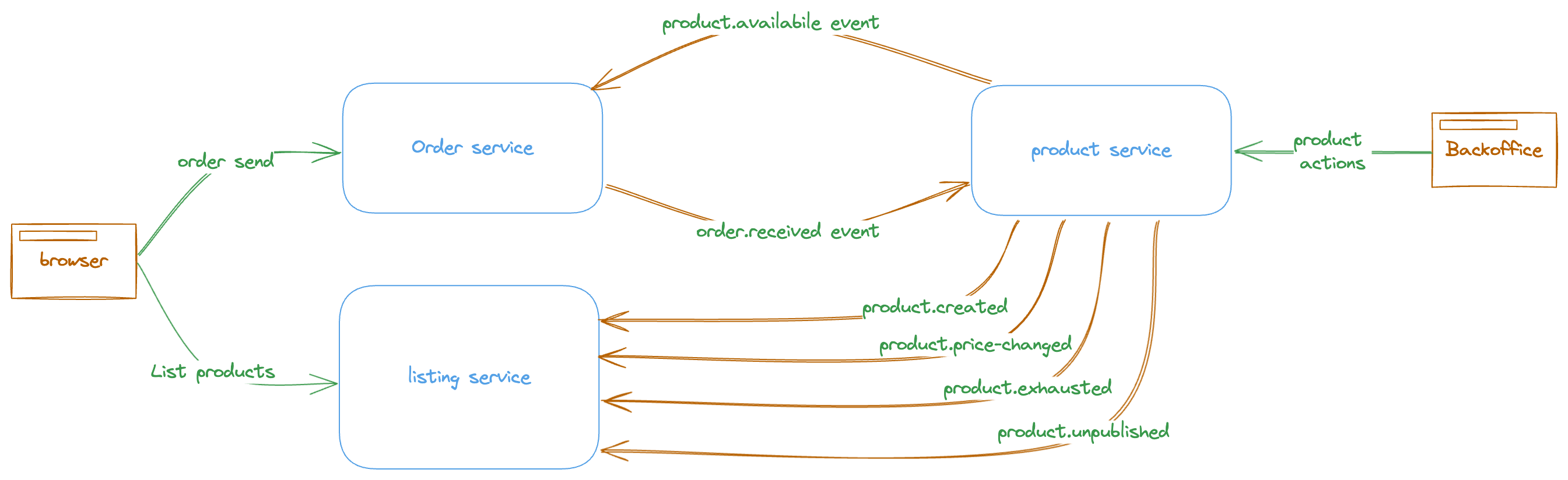
In this level the e-commerce website process will be:
The website shows the products listing
The order sent from website for selected products
Order service notifies product service by reception of order
The product service sends a replay to confirm the availability of product
Looking at Order and Product communication.

The Order service disseminates the order events and listen to product availability response.
The Product service by reception of order.recieved event verifies the availability of product and update the product stock availability
The product service send the product.available response message to notify the order service by availability of products in order
The order service updates the order status to IN_PROGRESS and
The product lifecycle will be:
The sellers add products via backoffice
The product service sends events to listing service
The listing service updates its local datasource to respond to website listing and search options.
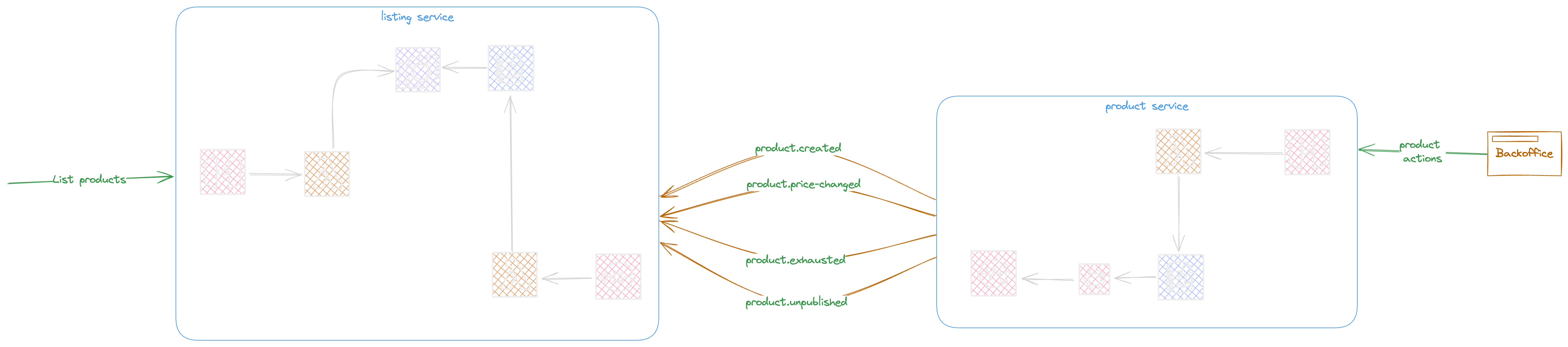
Edge cases
If the user modifies the order by removing an item, the order system need to notify the the product service to avoid the stock being exhausted this is achievable by sending a new order.modified*event letting the product service to reattribute the canceled product count to the product stock. but a better approach will be sending a meaningful event behind a real fact, so order service will be responsible of verifying the change in the modified order and send the corresponding event to the product service like order.product_canceled giving the product id and the original count.*
If the user send in really short duration of time the creation and modification demands this can be useless to distribute both events to the product service, lets imagine the modification arrives before creation to the product service. it is clear this situation brings a lot of inconsistency to the product service.
Responsibilities
Order service must guarantee the health of order reception, handling the change tracking and notify product service at a highest rate of trust. this means the order service must be able to react behind a stream of commands and take the best decision internally before distributing the events.
The product service must be able to delay the distribution, merge or abandon an event due to its actual internal state.
Using right services
To accomplish some sort of tradeoffs discussed in Edge cases and avoid giving the responsibility to event consumers take decision out of their domain context, choosing the write services and design is important and in cases can be a vital decision.
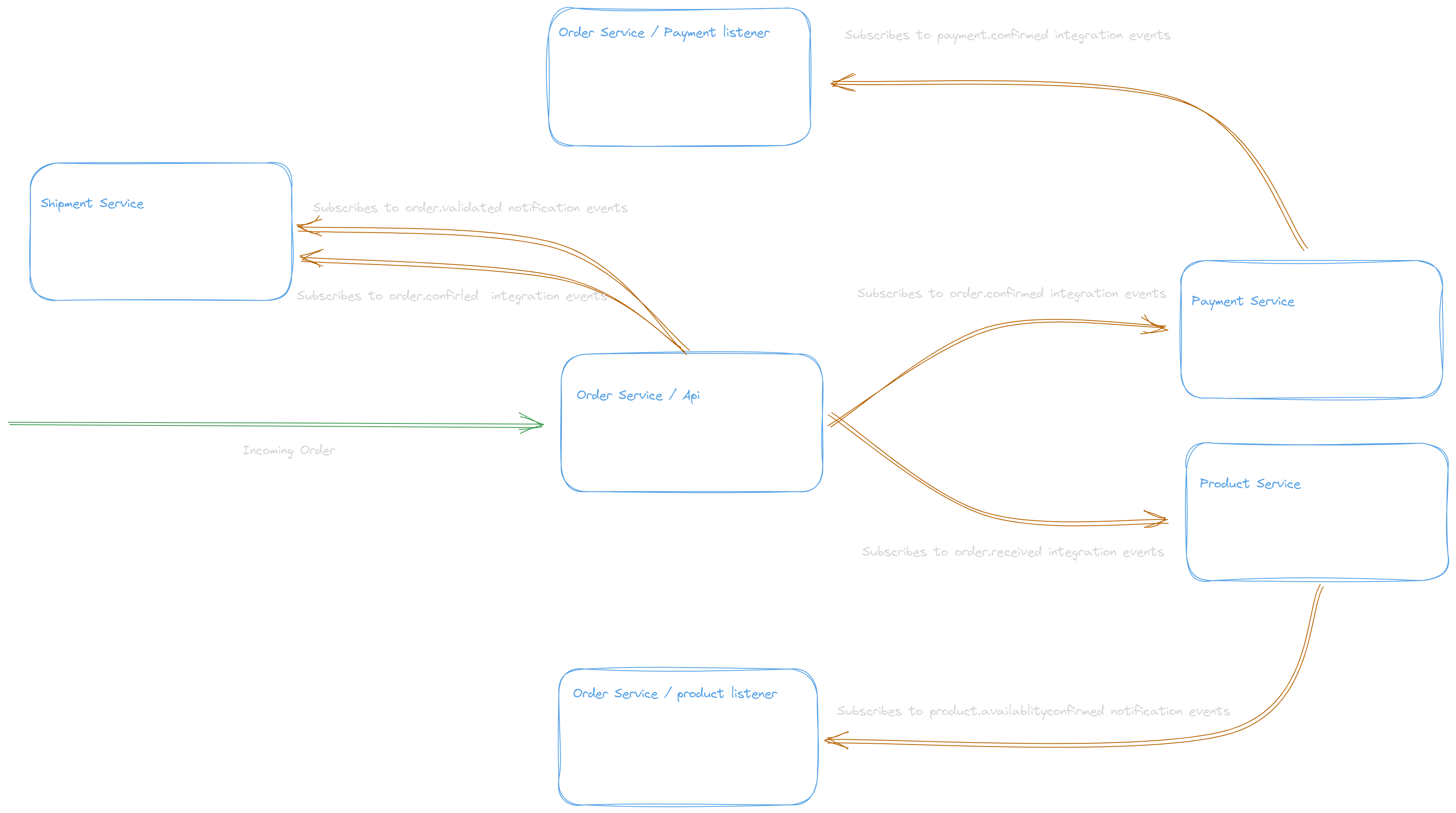
The following diagram shows how the Order service can adopt a design to cover those tradeoffs and become a self-serving microservice.
In this design the order service treat the stream of orders , this let the order service internally use the techniques like batching to verify a batch of related events and verify them and validate if any event state must be calculated or refined before broadcasting the notifications or integration events to other systems.
Source Code
Summary
In this article i tried to show some characteristics of the Evenbridge, SNS, Kinesis that are highly used when it comes to event distribution and represent the detailed limits to help better you see the tradeoffs when deciding the best service or a combination.
Walking through the examples, some real representative scenarios are explored to help better understand the core problem behind the technical consideration and help align the Bounded contexts, softwares and responsibilities related to them at enterprise level.
Thinking about responsibilities any service has in a distributed design can bring a lot of advantages in long-term and protect the software to be more contextualised and well mastered on a single business problem, avoiding producing a high level of technical debt related to a miss of well definition of context and responsabilities.
Subscribe to my newsletter
Read articles from Omid Eidivandi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by