Synthetic Control Matching
 Arvindh
Arvindh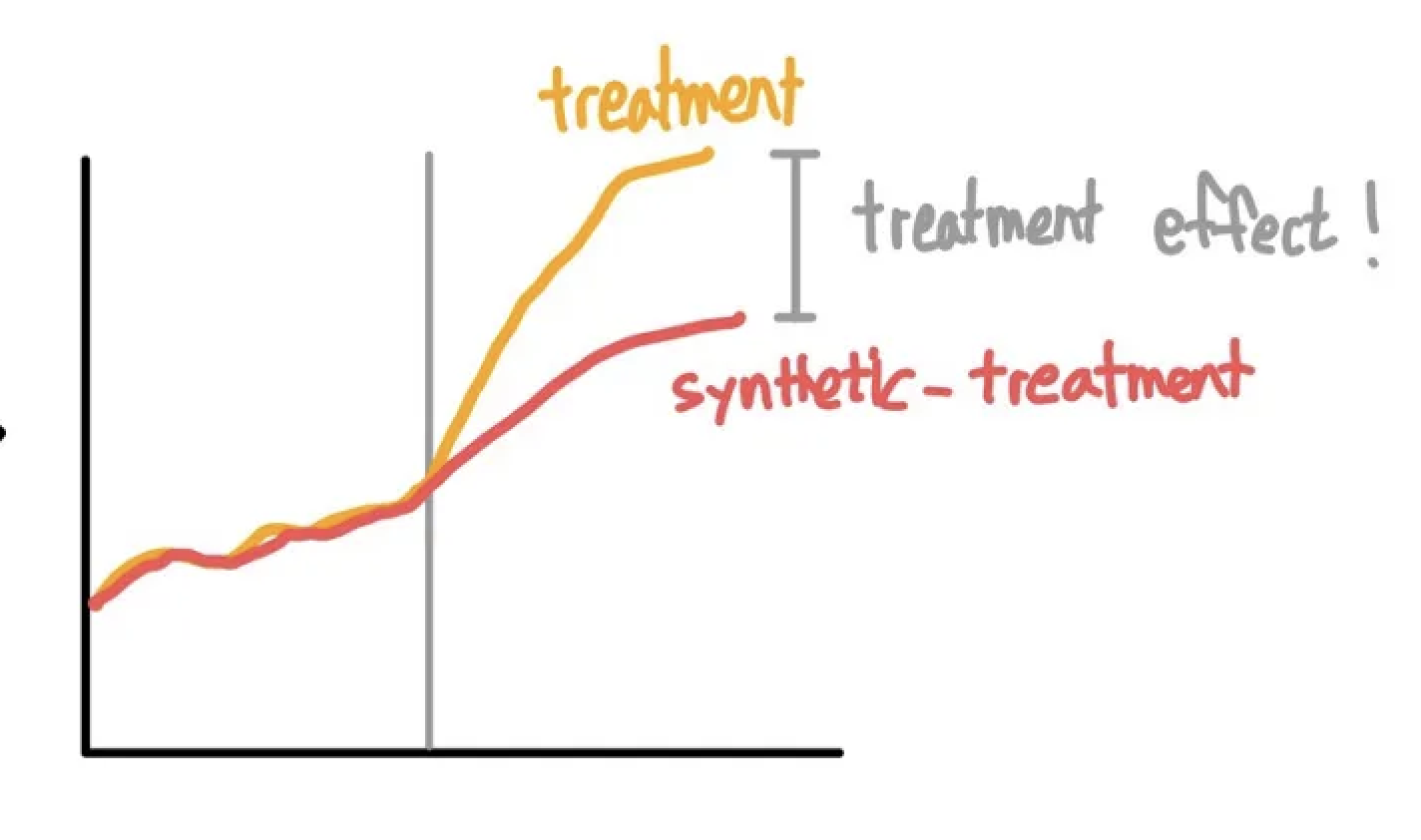
When measuring the impact of a change we tend to compare the effects before and after an experiment. But this overly simplifies our ability to truly estimate the difference. To truly understand the impact we need to understand what would have happened without the experiment.
In scientific trial we do this with help of comparing groups who undergo a treatment with those who don't (A/B Testing). In economics, where conducting experiments is challenging and costly, researchers resort to natural experiments.
A notable example is the study by economists David Card and Alan Krueger on New Jersey's minimum wage increase in 1992. Initially, they found no significant employment change in the state. However, comparing New Jersey to neighboring Pennsylvania revealed a different story: while employment declined in Pennsylvania despite no minimum wage change, it increased in New Jersey. This comparison highlighted the positive impact of New Jersey's policy change.
This study, often cited in minimum wage debates, challenges the conventional belief that raising the minimum wage leads to job losses. Nevertheless, it's not immune to criticism, particularly regarding the similarity of Pennsylvania counties to New Jersey as factors other than the minimum wage increase could have influenced employment trends.
The major disadvantage in natural experiments is that we don't have control over the environment or other variables, so researchers can't always accurately assess the effects of the independent variable. Natural experiments are also extremely difficult to replicate, making it hard to test for reliability.
Synthetic Control
In recent years, economists have refined their methodologies for conducting research, particularly in selecting control groups. One pioneering approach, spearheaded by economist Alberto Abadie and his team, involves the creation of synthetic control groups—a technique that has revolutionized the field.
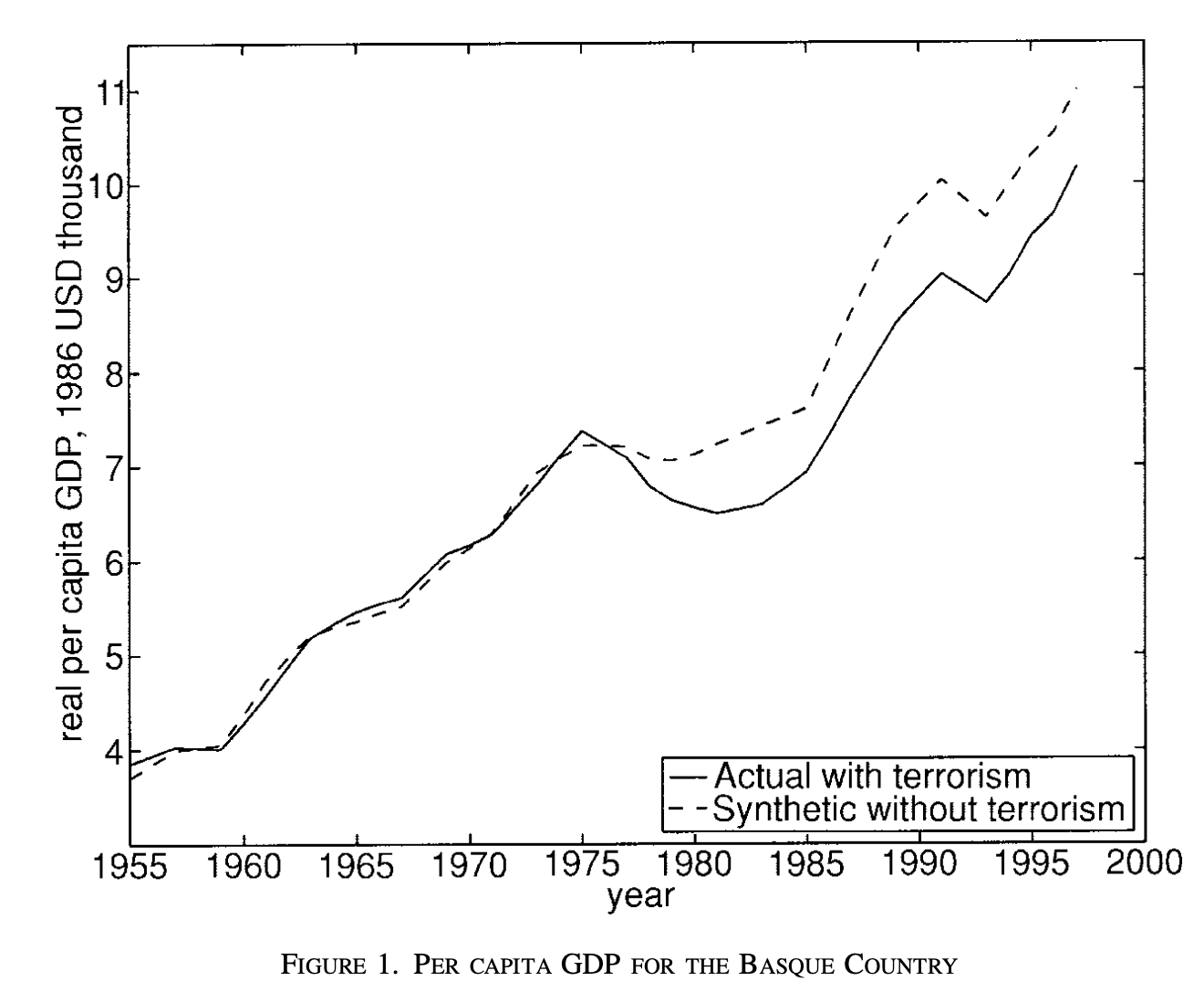
Abadie's inspiration for this innovative method stemmed from his study on the impact of terrorism on the Basque region's economy in Spain. Faced with the challenge of finding a suitable control group for Basque country, which differed significantly from other regions, Abadie and his colleague, Javier Gardeazabal, devised a creative solution. They created a weighted combination of various regions to construct a synthetic control group that closely mirrored Basque country's economic profile before the emergence of terrorism.
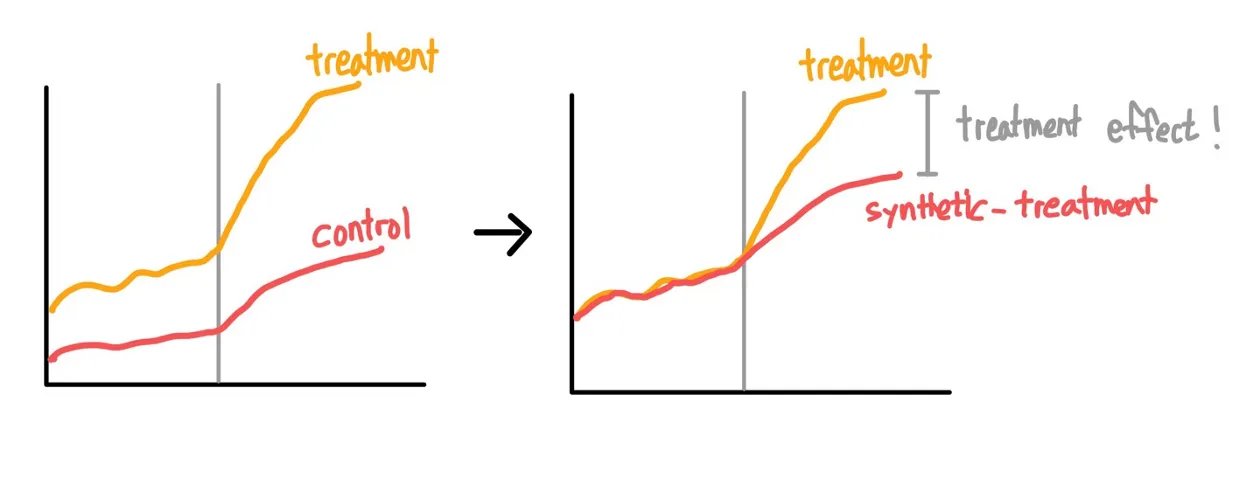
Termed a "synthetic" control, this method enabled researchers to compare the actual economic trajectory of Basque country with that of its synthetic counterpart. The results unveiled valuable insights into how terrorism affected the region's economy, showcasing the efficacy of innovative techniques in advancing economic research.
Designing a Synthetic Control Experiment
Identify relevant Similar units
The first step in designing a synthetic control experiment is to identify at least 5 to 10 relevant similar units to the treatment unit. These units should exhibit at least approximate co-movement behavior with the treated unit regarding the target metric. Another rule of thumb is to have at least as many control units as you have pre-intervention time periods. So if you have 10 years of pre-intervention data, you would want at least 10 control units. But more is generally better, as long as the controls meet the comparability criteria.
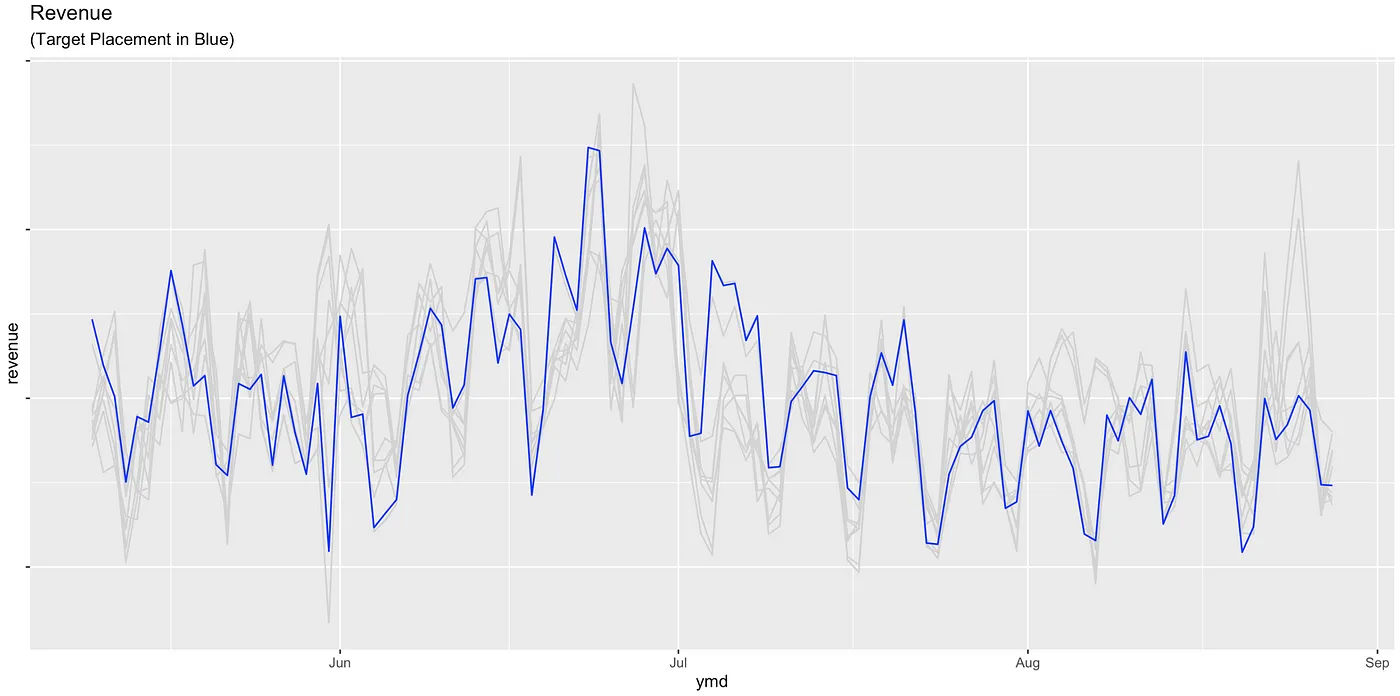
Treatment Revenue(Blue) and Control Group (in grey)
The groups should also not have spill over effects among them. A spill over effect in a synthetic control group refers to when the treatment effect "spills over" and affects the control units as well as the treated unit. This can happen through different mechanisms:
Contagion: The treatment effect spreads from treated unit to control units through social or economic interactions. For example, a policy in one state may influence behaviors or outcomes in neighboring states.
Displacement: The treatment redirects activity from treated unit to control units. For example, a crackdown on crime in one city displaces crime to other cities.
Anticipation: Control units change behaviors in anticipation of future treatment. For example, control states anticipating a future policy change.
Interference: The treatment in one unit directly interferes with outcomes in control units. For example, conservation efforts in one area affecting animal migration patterns elsewhere.
Market effects: Treatment changes market prices or other equilibria which affect control units. For example, a regulation in one state affecting prices nationwide.
Spillover effects violate the key assumption in synthetic control that the control units remain unaffected by the treatment. This can bias the estimated treatment effect if the spillover is positive (control units also improve) or negative (control units suffer).
To deal with spill overs, it may help to use control units that are geographically distant or economically independent from the treated unit. Or estimate spillover effects and adjust for them. But substantial spillovers may limit the viability of the synthetic control method.
Perform the desired treatment/intervention on the treatment unit.
Fit the model
Train the method on the pre-intervention period, which creates the synthetic control group. SCMs match on the pre-treatment outcomes in each period while other Matching Methods match based on the covariates. Eg Propensity Score Matching.
$$\hat \beta = \arg \min_{\beta} || \boldsymbol X_t - \boldsymbol \beta \boldsymbol Xc || = \sqrt{ \sum{p} \left( X{t, p} - \sum{i \in c} \beta{p} X{c, p} \right)^2 } \quad \text{s.t.} \quad \sum_{p} \beta_p = 1 \quad \text{and} \quad \beta_p \geq 0 \quad \forall p$$
This formula implies a set of weights β such that
weighted observable characteristics of the control group Xc, match the observable characteristics of the treatment group Xₜ, before the treatment
they sum to 1
and are not negative.
Libraries to Use
Its very straightforward to use R's Synth Library : LINK
In Python, we need to define the loss function and optimize using fmin_slsqp function under scipy.optimize library.
We cant use ML methods like linear regression, which perform extrapolation as it assigns negative weight to control group units leading to overfitting issue. Whereas Interpolation prevents the synthetic control group from deviating too much from the units in the control group into regions where we don’t have any data points. That being said, however, sometimes it can make sense to ease this restriction and allow extrapolation (to balance extrapolation and interpolation bias).
Interpret the results
Observe the pre-intervention and post-intervention fits; the latter shows you the causal effect. A good fit indicates that the synthetic control represents the target well. If not, we cannot trust the control group, which means we should go back to improving the model and/or the data. It should follow the seasonality and trends of the treatment unit quite well.
Limitations
Synthetic control methods are used when the pre-treatment fit between the treated unit and synthetic control is nearly perfect. As a result, synthetic controls have often been applied to long-term aggregate metrics like GDP and unemployment, where values fluctuate less noise from period to period.
It can't detect effects that are small in comparison to the noise around them.
The method relies heavily on having a long pre-treatment period to fit the synthetic control, so may not work well with shorter pre-treatment series.
Lets see in Action
Case Study: Estimating the effect of cigarette taxation on its consumption
To evaluate its effect, we can gather data on cigarette sales from multiple states and across a number of years. In our case, we got data from the year 1970 to 2000 from 39 states. Other states had similar Tobacco control programs and were dropped from the analysis. The idea of synthetic control is to exploit the temporal variation in the data instead of the cross-sectional one (across time instead of across units).
Python Notebook : https://matheusfacure.github.io/python-causality-handbook/15-Synthetic-Control.html
R Notebook : https://bookdown.org/mike/data_analysis/synthetic-control.html
Reference:
https://medium.com/data-science-at-microsoft/causal-inference-using-synthetic-controls-d96a890c83a7
https://bookdown.org/mike/data_analysis/synthetic-control.html
https://matheusfacure.github.io/python-causality-handbook/15-Synthetic-Control.html
Subscribe to my newsletter
Read articles from Arvindh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arvindh
Arvindh
I am Sr Data Scientist at Target, working at the intersection of optimization and machine learning. I got my Masters in Business Analytics from University of Texas at Dallas. 💻 Currently in pursuit to learn more about Deep Learning and Generative AI You can reach me at : https://www.linkedin.com/in/arvindh-arul/