How to Achieve Real Zero-Downtime in Kubernetes Rolling Deployments: Avoiding broken client connections
 Tokede Akinkunmi
Tokede Akinkunmi
The popular idiom nothing is constant except change was from a Greek philosopher named Heraclitus. Although Heraclitus lived around 500 BCE, this quote remains valid. Thanks to super-efficient orchestration tools like Kubernetes, making changes to our applications has become more seamless.
In software engineering, we make changes almost every day, but how do we avoid these changes from impacting users negatively? One of the negative impacts on users is through broken connections. I would have loved to discuss the impact of broken client connections, but not in this article.
By default, the Kubernetes deployment strategy involves rolling deployments. Yes! Rolling deployment sounds very interesting, but there is more to that. We need to ask ourselves some questions. What happens during rolling deployments?
Rolling deployments means incrementally replacing the current pods with new ones. During this process, there is always downtime spanning from microseconds to seconds. It might be insignificant for applications with a low user base. But it is significant for big applications, especially payment gateways, where every second counts.
Note: There are other ways to achieve zero downtime while deploying to production in Kubernetes, such as utilising a service mesh like Istio or implementing a blue-green deployment. These options consume more resources than rolling deployments, leading to an increase in infrastructural costs.
The question, “What happens during rolling deployments?” can be broken into two.
First, what happens when a pod starts up, and what happens when a pod shuts down?
Before we continue, here are the pre-requisites for this tutorial:
Kubernetes knowledge
Experience using Docker
The startup stage of a pod
When a pod starts in a rolling deployment without the readiness probe configured, the endpoint controller updates the corresponding service objects with the pod’s endpoints, which means the pod starts receiving traffic even though the pod is not ready. The absence of a readiness probe makes the application unstable.
Having a readiness probe set is recommended for applications. The implication is that it only receives traffic when it is ready; the endpoint controller continues to monitor the pods based on the pod’s readiness probe result. When the probe is successful, the endpoints are updated on the service objects to receive traffic.
Below is an example of a Kubernetes deployment file with a readiness probe configured:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-highly-available-app
spec:
replicas: 3 # Define desired number of replicas
selector:
matchLabels:
app: highly-available
template:
metadata:
labels:
app: highly-available
spec:
containers:
- name: highly-available
image: highly-available-image:latest
ports:
- containerPort: 80
readinessProbe: # Readiness probe configuration
httpGet:
path: /health-check
port: 80
initialDelaySeconds: 5 # Wait 5 seconds before starting probes
periodSeconds: 10 # Check every 10 seconds
failureThreshold: 3 # Mark unhealthy after 3 consecutive failures
We have established what happens during the startup stage of a pod; it is time to analyse what happens in the shutdown stage.
The shutdown stage of a pod
It is crucial to understand that components in a Kubernetes cluster are more like micro-services and not monolithic. The way micro-services work is different from how monolithic processes run. In microservices, it takes more time for all the components to sync.
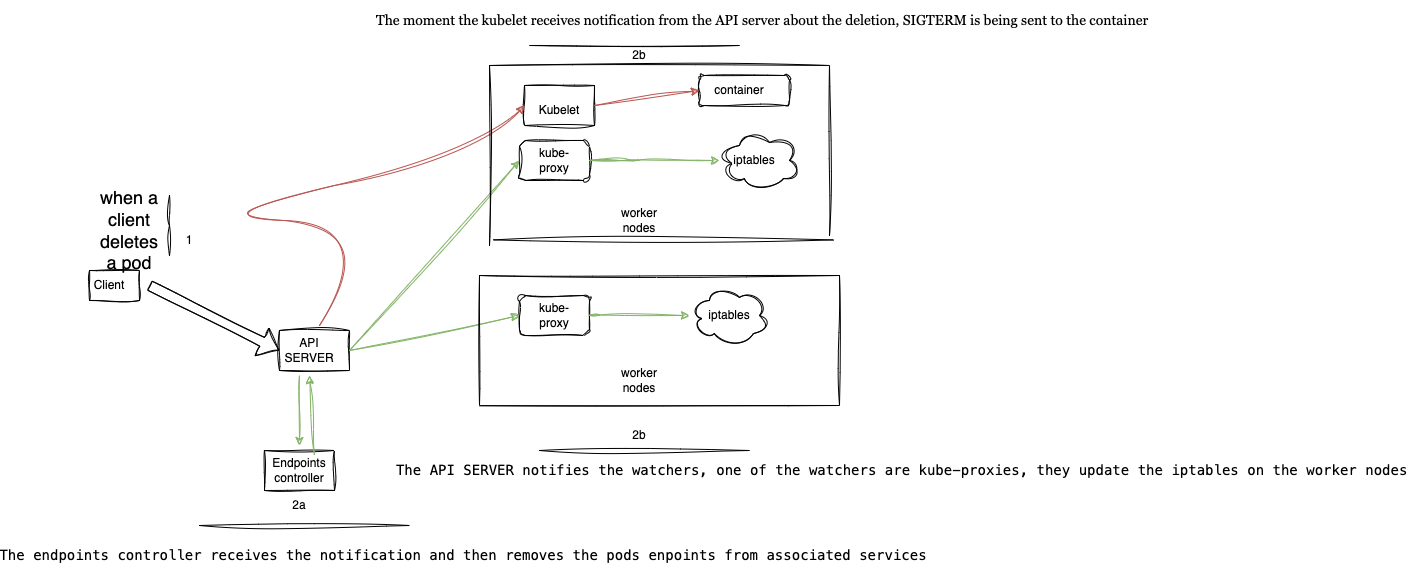
When the API server receives a notification of a pod deletion from a client or during rolling deployment, it first modifies the state of the pod in etcd, then notifies the endpoint controller and the Kubelet. Upon receiving the pod deletion notification from the API server, the endpoint controller removes the pod endpoint from every Service with which the pod is associated.
The endpoint controller on the control plane does this by sending a REST API to the API server. The API server then notifies its watchers, of which Kube-proxies are one; the Kube-proxies update the iptables rules to reflect the changes in the set of endpoints associated with that Service. Updating the iptables rules will prevent new traffic from being directed to the terminating pods.
The scenario described above is where the downtime occurs because it takes more time to update the iptables rules than for the containers to be terminated by the Kubelet. These phases happen concurrently. When a request to delete a pod is received from a client or during a rolling deployment, this request reaches the API server on the control plane. The Kubelet and the endpoint controller watch the API server for changes once the Kubelet and the endpoint controller receive a deletion notification. The Kubelet immediately sends a SIGTERM signal to the container, and the endpoints controller sends a request back to the API server for the pod endpoints to be removed from all service objects, a task performed by Kube-proxies on the worker nodes.
The reason for this downtime is that the containers would have been terminated by Kubelet (which is a shorter process and therefore takes less time) before the pod endpoints are updated on the corresponding Service (which involves more processes and thus takes more time). Due to the difference in task completion time, Services still route traffic to the endpoints of the terminating pods, leading to messages like “connection error” or “connection refused.”
The diagram below provides a pictorial view of what happens internally within the Kubernetes architecture.
We have been able to establish reasons for broken connections during rolling deployments; how then do we solve this issue?
The Solution
Kubernetes was never designed as a “plug and play” orchestration tool; it requires proper configuration to suit every use case accordingly. Since we have discovered that the difference in task completion time is the main issue, the simple solution is to define a wait time for the proxies to update the iptables.
We can achieve this by adding a preStop hook to the deployment configuration. Before the container shuts down completely, we will configure the container to wait for 20 seconds. It is a synchronous action, which means the container will only shut down when this wait time is complete. By then, the Kube-proxies would have updated the iptables, and new connections would be routed to running pods instead of terminating pods.
Note: The preStop hook is a mechanism used in pod lifecycle management to execute a specific command or action before a pod terminates
It is crucial to understand that when the iptables are updated, connections to the old pods (pods that are terminating) are still maintained, and client connections are not broken until all processes are complete and the pod shuts down gracefully, but new connections are directed to stable pods.
Below is an example of a deployment file with the preStop hook configured:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-highly-available-app
spec:
replicas: 3 # Define desired number of replicas
selector:
matchLabels:
app: highly-available
template:
metadata:
labels:
app: highly-available
spec:
containers:
- name: highly-available
image: highly-available-image:latest
ports:
- containerPort: 80
readinessProbe: # Readiness probe configuration
httpGet:
path: /health-check
port: 80
initialDelaySeconds: 5 # Wait 5 seconds before starting probes
periodSeconds: 10 # Check every 10 seconds
failureThreshold: 3 # Mark unhealthy after 3 consecutive failures
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "sleep 20"]
With the configuration above, rolling deployments will no longer cause downtime on our infrastructure.
Finally, we should always ensure that the sleep time given is less than terminationGracePeriodSeconds, which is 30 seconds by default. A higher value will only cause the container to shut down forcefully.
Conclusion
To sum up, we have made significant progress in ensuring stable user connections during rolling deployments, regardless of the number of deployment versions released daily. We have modified our deployment file to include a readiness probe and a pre-stop hook. These changes enable us to manage traffic during pod startup and shutdown more effectively.
It has indeed been a productive time with you. Happy automating!
Subscribe to my newsletter
Read articles from Tokede Akinkunmi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by