Mixture of Experts : A Highly Efficient Approach for LLMs
 Akash Gss
Akash GssTable of contents
- What it is
- Mistral AI's Adoption of the MoE Model
- Deep Dive
- Breaking down the Router used in Mixture of Experts
- How Training Exactly Takes Place in a Mixture of Experts Model
- Benefits
- Problems And Solutions
- Benefits of using the MoE Model
- Research to improve the Mixture of Expert Models.
- Benchmarks
- Conclusion
- Sources

What it is
The Mixture of Experts also known as the MoE Model is a form of an ensemble model that has been introduced to improve the accuracy while reducing the amount of computations that are required to be performed by a full-fledged transformer architecture by the number of Experts available as a part of the specific model's architecture aka it reduces the amount of compute by 1/Nth the cost where N is the number of sub-models or experts that are a part of the architecture.
Mistral AI's Adoption of the MoE Model
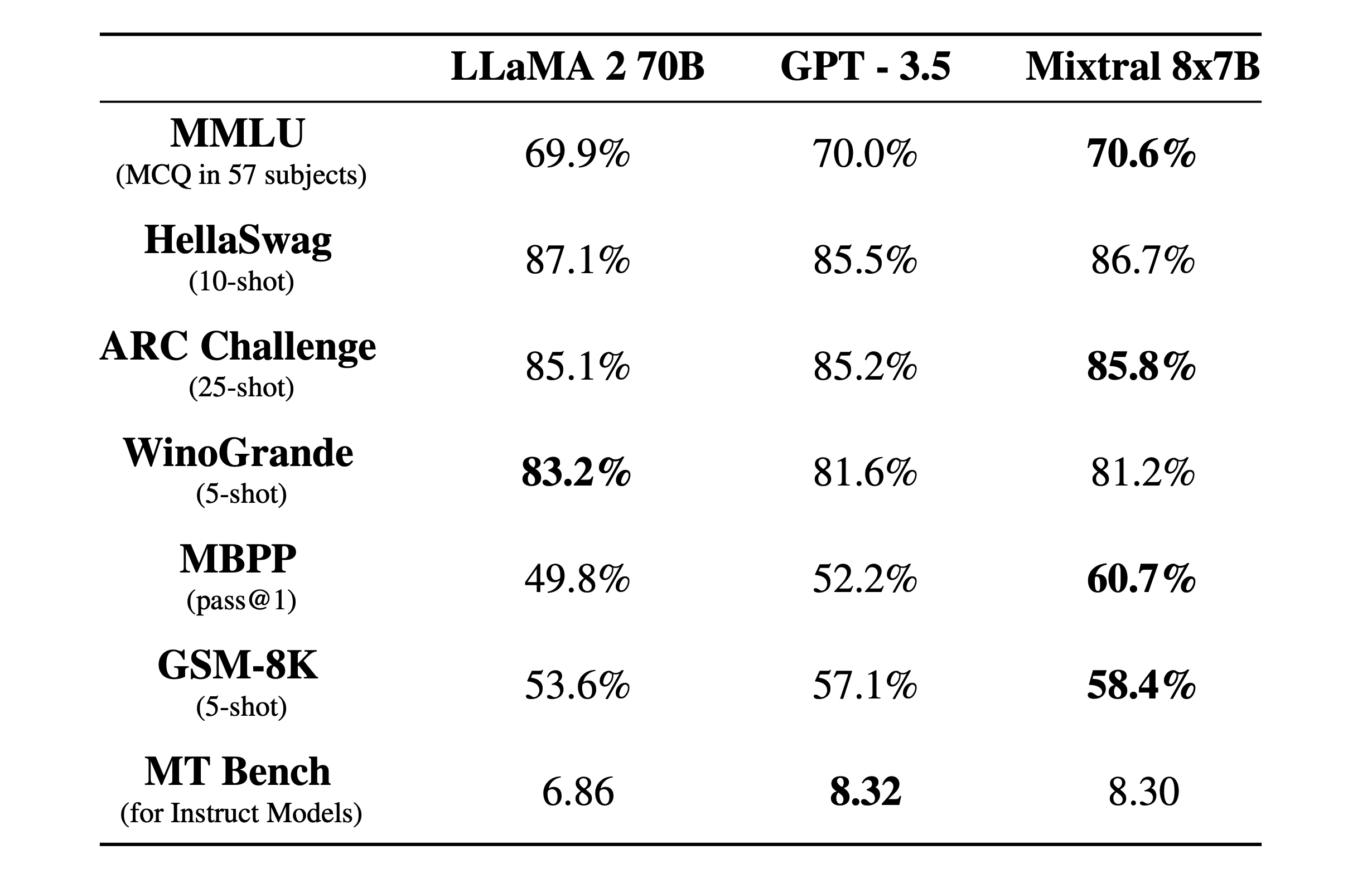
Mistral AI was one of the early adopters of this age-old concept of a Mixture of Experts for its LLM Model dubbed the Mixtral 8x7B model.
The Model released by the company can handle a context window of around 32k tokens, can be fine-tuned to follow specific instructions, and has achieved a remarkable score of 8.3 on MT-Bench and competes and beats Meta's LLama 2 at code generation and so much more. The company also tells us that the model is pre-trained on data extracted from the open Web and finally informs us that both the Experts and the Router responsible for the routing have been trained together or simultaneously.
Deep Dive
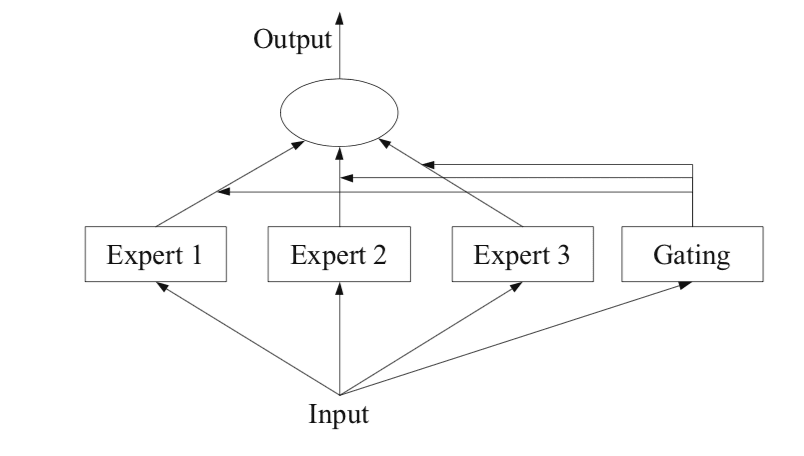
The Mixture of Experts is a model that runs multiple models inside of it that have been "stacked" together and depending on the user's request, a "Router" picks out the particular model that is best suited to the user's question and which can give the best output.
Before we go full speed ahead, let's understand why we even need this sophisticated model which is pretty much larger than the traditional types of transformer model.
In the case of a normal transformer, all of the neurons on the transformer are used to get the desired output. These LLM Models that are transformers contain a ton of neurons and are just a neural network at a higher level. And, during the process of inference or the prediction of the next token based on probability [The core concept being used by GPT and other LLMs] a normal transformer model for the most part uses ALL of its neurons and as you need more and more parameters especially in the billions like the Mistral Model itself and Google's Gemini 1.5 which recently came out, this might be an extremely in-efficient way of doing this and will require a significant level of compute.
Now, since the weights are always scattered and distributed in an LLM model, let's flip the mentality and instead of computing at such a high level, what if we could re-distribute and re-arrange the weights of the model such that now, depending on your request, the weights most appropriate to it will be picked and your output will be given to you in a much faster time. So, essentially we narrow down the search space and the number of weights/neurons required for you to get the answer back for your query and this proves to be very very efficient rather than using about all of the available neurons, especially in the case of very large scale models with billions of parameters.
This gave birth to the concept of Mixture of Experts and getting started utilizing it to reduce the amount of overhead and computing that is in general required by LLM Models. Please note that this concept of Mixture of Experts is about 10 years old and matter of fact it was worked upon by one of the higher-ups of OpenAI - Ilya Sutskever which is now being finally used to make LLMs faster and reduce the computing required.
Coming back to the topic at hand. So, in the case of a Mixture of Experts or an MoE model, we take a model and split it into several experts that contain weights for knowledge specific to some categories and then we have an intermediary known as a router between the user's request and the model that is responsible for the re-direction and choosing the best expert aka the sub-model that is the most likely to give you the best answer possible for your question instead of using all of the model's compute, only this sub-model will start working and this is a very very big performance gain!
Breaking down the Router used in Mixture of Experts
In general, your request and the output received back as well as in traditional machine learning models, neural networks, and also LLMs are always represented in the form of an array or a vector of numbers known as embeddings. So, what takes place is that first your query is converted into an input vector which is just a 1D representation with floating point numbers. And, after this, it goes to the Router or the "Gating Network" which is essentially a neural network of its own represented in the form of a matrix of weights which then is responsible for the prediction of the best model to pick out of the list of sub-models available and it does this through probability.
Probability is utilized by the router to pick the optimal expert or sub-model that is the most likely to answer your question to the best of its ability and after this, your input weights or input vector is fed into the sub-model that is picked by the Router.
The router acts like a map that can re-direct your requests to the sub-model that has the highest chance/probability of answering your query to the best of its abilities.
How Training Exactly Takes Place in a Mixture of Experts Model
At the start, we have a Mixture of Experts model where the weights of each model are segregated and arranged based on their weight similarity and then after this, your input vector is first sent to the router which then chooses between these sub-models to find out which one is the best suited to fulfill your request.
After this, your input vector makes it to the designated sub-model picked by the router and the output tokens [in the form of a vector similar to the input] are calculated and after this, a loss value is also calculated. This loss value returned from the loss function is used heavily in a lot of ML Models and it is used to backpropagate through all of the weights of the specific sub-model chosen and both the model and the Router as well utilize these to learn and train themselves.
This is how both the sub-models and the router become better at both re-direction and optimally answering your query and this strategy of back-propagation is utilized heavily for this purpose.
Benefits
The MoE model is much much faster as compared to a traditional transformer like an LLM Model where essentially almost all of the neural networks inside come together and work to produce an optimal output for your request. But in the case of a MoE model, we essentially slash this time taken by 1 / N where N is the number of sub-models or experts available as a part of your MoE architecture.
For example, in the case of the Mistral 7-B model, there are 8 experts as a part of the architecture and you can perform inference [the prediction of the next token] and get to the result required to answer the user query in 1/8th of the time! This is an extremely significant boost of over 85% as compared to the normal LLM models that run on the Transformer architecture.
Problems And Solutions
Problems
This high performance comes with problems as well and this model is not the final solution to optimize LLM Models some of the problems that could be exhibited by the MoE architecture are -
Router Bias: A Sub-Model or an Expert might be much stronger and far more accurate to be precise as compared to the others thus leading to a bias or favoritism by the Router causing it to route a ton of user requests just to this one model despite other models being better catered towards the user request despite being slightly less accurate.
Skewed Dataset: This strong bias of picking one model can also stem from the source dataset where the data is mainly focused on only one label while ignoring the other labels for example if a router that is trained on languages as a whole is skewed mainly towards Spanish, there is a chance of user's requests in Portuguese not even making it to the Portuguese Expert but instead to the Spanish expert due to how similar these languages are.
Solutions
Solving the Router Bias: An easy step to solve this problem is to make sure that the router is uniformly trained to route to all of the experts instead of just a few of the experts.
Secondly, This bias from the router can also be solved by introducing noise or randomness to the router's computed weights once it is about to route the user's request to the designated expert. These random weights can help the router increase its search space and prevent it from becoming biased instead and it'll at least consider a few more of the experts available.
Finally, The router can also be penalized when it picks the wrong expert which will prevent it from doing so in the future through the process of adding a penalty to the loss calculated that is the main component required for back-propagation which is subsequently required for the model to become better. This will de-incentivize the router from picking the wrong experts and help it course-correct or route to the appropriate expert.
Solving the Skewed Dataset: Ensuring that the dataset considers all of the different types of requests a user can make on a widely known topic and having the data as equally distributed among all these labels as possible would prevent any inherent bias from affecting the router where it ends up preferring to choose one expert which is not related to the user's query.
Benefits of using the MoE Model
The MoE Model could potentially run on your laptop and the inference can entirely be possible just in a laptop due to the 1/N time taken by it to compute the output tokens through inference. However, one caveat is that the size of the model cannot be reduced but it will be much faster and cheaper to run computations and all this could be potentially done through your laptop itself.
The MoE model could reduce costs at scale due to the number of tokens required being only 1/N. So, combined with batching and assigning every single expert as a part of this model a GPU, your performance can skyrocket and essentially due to the distributed nature of these models, it'll be much faster to perform inference even when the dataset is large.
Research to improve the Mixture of Expert Models.
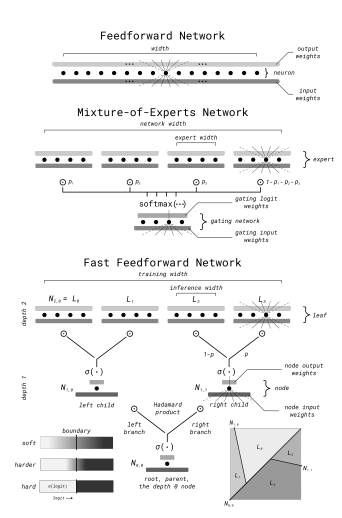
Considering the case of the traditional Mixture of Experts model where you have N Models which are routed to by the router and essentially run parallel, you could instead model this router vs expert architecture into a tree instead which is known as a Binary Tree Mixture of Experts that used Fast feed-forward neural networks.
With a tree modeling, you could have multiple routers acting on only 2 experts at one point and this could become like a binary decision tree where you cut down your search space by running through multiple routers until you locate the most optimal sub-model or Expert that can answer your query to the best of its ability. Essentially, this form of branching of the MoE model between multiple routers routing to the optimal expert using probability is from Fast Feed Forward Neural Networks which tend to be much faster than traditional neural networks due to the branching mechanism and so much more.
Overall, this architecture due to the usage of fewer connections and smaller accuracy loss proves to be more accurate and fast than the traditional MoE architecture and is being experimented upon.
Benchmarks
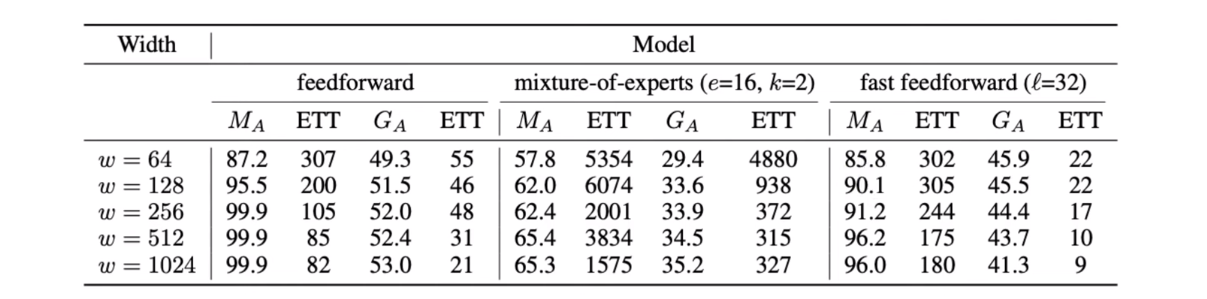
Here are some of the benchmarks and tests comparing the performance of the feed-forward used with the MoE model, normal MoE model, and the fast feed-forward variants [binary tree] of the MoE model where Ma stands for Memorization and Ga for Generalization.
Conclusion
Overall, the Mixture of Experts model acts as a transformer model that performs everything an LLM Model using the traditional transformer architecture can perform in 1/Nth of the time where N is the number of sub-models or experts and it proves to be much more efficient and accurate potentially reducing the amount of compute required for several cases while maintaining high performance. This Model is in use by a wide variety of LLM Models like Mixtral 8X7B and more!
Sources
This blog post was written referring to several articles and mainly the below youtube video all of which are linked below for your kind perusal.
Trellis Research - https://www.youtube.com/watch?v=0U_65fLoTq0&t=1350s
Mistral AI - https://mistral.ai/news/mixtral-of-experts/
Machine Learning Mastery - https://machinelearningmastery.com/mixture-of-experts/
Binary MoE Model using FNNs - https://arxiv.org/pdf/2308.14711.pdf
MoE Model - https://arxiv.org/abs/1312.4314
Subscribe to my newsletter
Read articles from Akash Gss directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by