Git Decoded: Exploring the Core Mechanics for Streamlined Version Control and Collaboration
 Aditya Mohan
Aditya Mohan
As someone deeply involved in modern software development, I've witnessed firsthand the widespread adoption and powerful capabilities of Git for version control. Yet, I understand how Git's inner workings can appear opaque to many users, with its cryptic SHA-1 hashes and intricate branching structures. That's why I'm excited to share my comprehensive understanding of Git which delves deep into its internals, demystifying its underlying mechanisms and shedding light on how it efficiently manages version control.

Understanding Git Basics
At its core, Git is a distributed version control system that excels in managing code changes across multiple contributors and branches. While Git's user-friendly commands make everyday tasks like committing, branching, and merging intuitive, understanding its internals unlocks a deeper level of proficiency and confidence in its usage.
Let's take a look at what a typical Git's folder structure looks like inside our project:

As we can observe Git saves its contents inside the .git folder in our project directory.
The .git folder is a critical component of every Git repository, housing all the necessary information for tracking code changes. Here's a breakdown of its key contents:
HEAD File: This text file stores the SHA hash of the currently checked-out commit, effectively tracking the current branch.
refs Folder: Contains references to commits and branches, with subfolders like
headsfor branch heads andtagsfor tags.objects Folder: Here, Git stores the codebase as a series of snapshots, with two subfolders:
packfor compressed snapshots andinfofor metadata.config File: Stores repository configuration settings, including user information and default branch settings.
hooks Folder: Allows users to add custom scripts to run at specific points in the Git workflow, such as before committing or after checking out.
Deciphering the SHA-1 Hash

I've always found one of the most intriguing aspects of Git to be its reliance on SHA-1 hashes for uniquely identifying commits, trees, and blobs. These 40-character strings might initially seem arbitrary, but they're actually at the heart of Git's architecture. SHA-1 hashes are generated based on the content of an object, ensuring each one is entirely unique. This means that even the slightest change in content results in a completely different SHA-1 hash, thus ensuring data integrity and preventing accidental duplication. The Three Git Object Types
Optimizing Storage with SHA-1 Hashes
Git's use of SHA-1 hashes enables efficient storage optimization. Identical file contents result in the same SHA-1 hash, allowing Git to store them as a single blob, even if they appear in multiple commits or branches. This deduplication mechanism minimizes disk space usage while preserving the integrity of the repository.
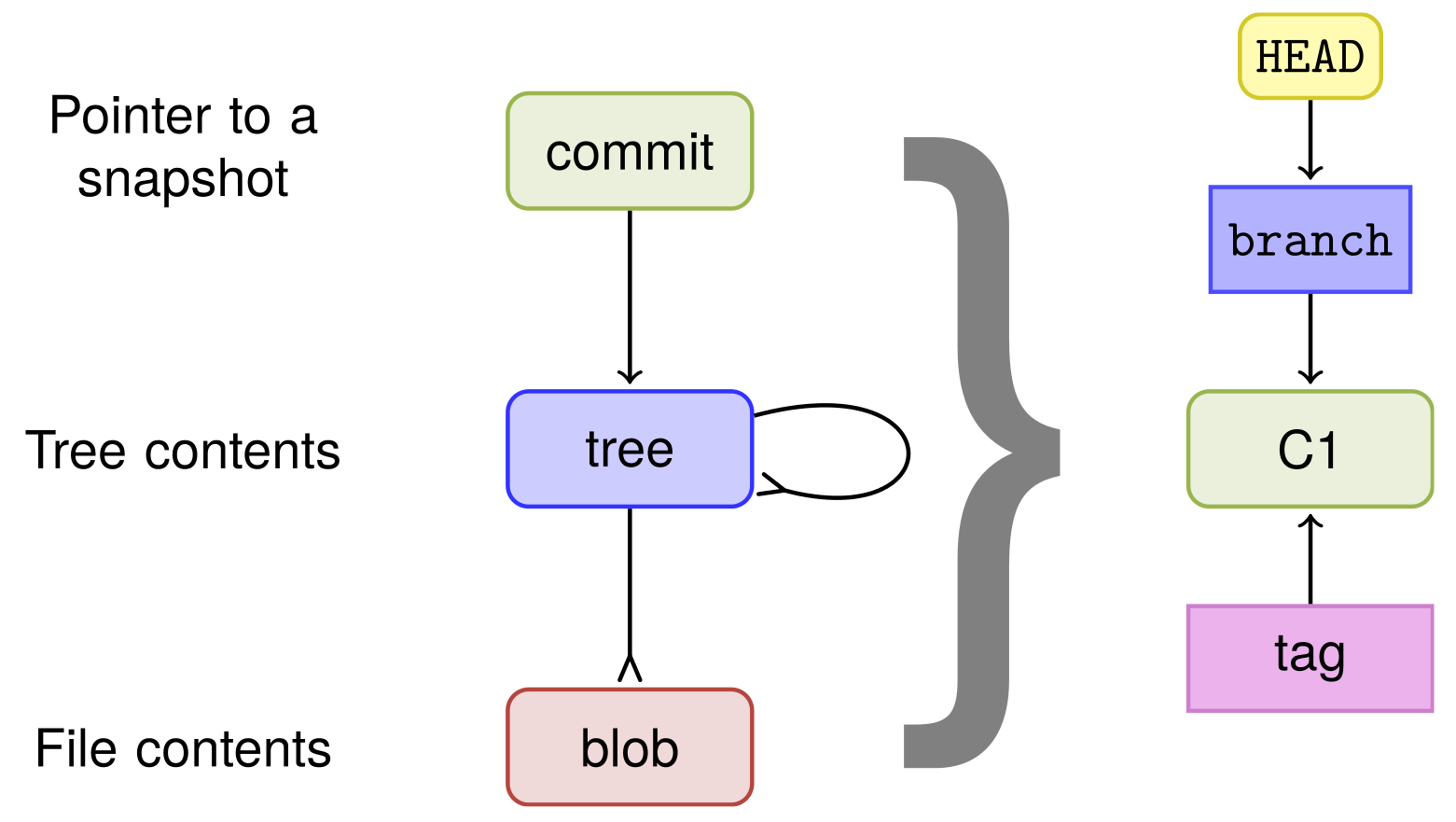
Git operates on three main object types: commits, trees, and blobs. A commit represents a snapshot of changes made to files along with metadata such as author, timestamp, and commit message. Each commit points to a tree object, which in turn references the file structure. Finally, blobs contain the actual file contents. Together, these objects form a directed acyclic graph, tracing the history of changes in a Git repository.
What makes git so special and different from other version-control tools out there?

SNAPSHOTS MANAGEMENT!The concept of a "snapshot" is crucial for understanding how the version control system operates. When we commit changes to a file, Git creates snapshots of the entire file rather than just the differences between the new and old versions. This approach, known as the "loose object format," means that even a minor change to file results in a new snapshot being saved to disk. While this may consume more disk space compared to systems like Subversion that save only the delta between versions, it streamlines the commit process and ensures integrity.
🎞️ Snapshot storage saves the entire state of a file or system as a single instance, known as a snapshot. Each snapshot represents the system at a given time and serves as a reference point for future changes. This method is simple, efficient, and straightforward, but it can consume a lot of storage space over time if there are frequent changes to the system. | Δ Delta storage, on the other hand, saves only the changes made to a file or system rather than the entire state. Each change is stored as a delta or a difference from the previous version, and the system's current state is reconstructed by combining all the deltas. This method is more efficient in terms of storage space, as it only stores the differences between versions but can be more complex to implement and manage. |
To illustrate it better here's an example of a snapshot from my own project that I did before:

In the above screenshot, we can observe that we are using this command git cat-file -p for gaining information about the weird hash strings we see on maybe Github or Bitbucket or any application that you might be using along with git.
The 0ee3f59 bit that we can observe up there in the first line is the value of hash present at the commit currently at my HEAD of the branch(SNAPSHOT of the whole project). The 40-character hash string in the next command is the hash value of the tree that we can observe in the first command's output. We are using that command to gain more information about what contents it is harbouring inside it in a nutshell!
Similarly to inspect a blob we can further use the same command on the hash value of a blob and depending upon the options we are using with git cat-file command we will get the desired results.
Packfiles and efficiency?
Git optimizes disk usage through periodic processes like "git gc" (garbage collection), which creates "Packfiles" and removes redundant snapshots. Packfiles consolidate similar snapshots, reducing disk space usage to levels comparable to other version control systems that use delta compression.

This balance between performance and disk space efficiency is one of Git's strengths, allowing it to outpace other VCS systems in commit speed while keeping disk usage in check. The Packfiles, located under ".git/objects/pack," are generated through the "git gc" command, demonstrating Git's continuous optimization efforts.
Exploring Branches and Tags
In Git, I see branches and tags as valuable pointers to specific commits. Branches are especially handy for branching workflows since they're lightweight and easy to create. Typically, the "master" branch is the go-to starting point for new projects, acting as the mainline branch. On the other hand, tags offer named references to significant commits like release points or milestones, adding clarity and context to the repository's history.

Git Internals in Action
Let's dive into the inner workings of Git by applying it to our project. Through hands-on experimentation, we'll create a sequence of commits and examine the underlying objects, gaining a deeper understanding of how Git handles version history. With each commit, we capture a snapshot of the entire project, showcasing the interconnectedness of commits, trees, and blobs.

Here's what the commit history should look like. Using the command mentioned earlier we can go over each snapshot and see how the files are being tracked and how blobs are created.
Conclusion
By understanding how Git manages version control through commits, trees, and blobs, we can navigate complex workflows with confidence. Embracing Git's decentralized architecture and leveraging its branching features empowers our teams to collaborate effectively and deliver high-quality software iteratively.
More things I'll be covering in future articles -
Branching Strategies
Workflows
Subscribe to my newsletter
Read articles from Aditya Mohan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Mohan
Aditya Mohan
I am a student at Georgia State University, pursuing a Master's in Computer Science. Passionate software developer, cinephile, and music lover.