ETL: Testing of Extraction Process
 Yogendra Porwal
Yogendra PorwalIn this article, we will focus on testing of the first step of the ETL process: Extraction. We will explore what extraction is, different types of sources, how to test the extraction process, the support QA needs from developers or product teams, and best practices to follow. Additionally, we will explore real-life examples for each testing scenario.
What is Extraction?
Extraction is the process of gathering data from different sources to be used in the subsequent stages of the ETL process. It involves identifying, accessing, and retrieving data from various systems, databases, files, or streams.

Different Types of Sources in Extraction
Flat Files: These are structured files where data is stored in plain text, such as CSV or TSV files.
Excel Files: Excel files contain tabular data in spreadsheets, often used for storing and manipulating data.
Databases: Extraction from databases involves retrieving data from tables, views, or stored procedures in database management systems like MySQL, Oracle, or SQL Server.
Websocket Stream Input: Websockets enable real-time communication between a client and a server. Extracting data from a websocket stream involves capturing and processing data as it is being transmitted.
Why Testing of Extraction is Important
Most of the time, QA may focus on testing of transformation layer but miss out the testing of extraction which is equally important.
As we Already know, that ETL often involves merging data from multiple sources. There Can be many challenges and issues that can be introduced in extracted data. For Example Data inconsistency , incorrect mapping of data in destination, data loss and duplicate data are few that can impact extracted data in warehouse.
Let's assume there is a retail company having multiple departments such as sales, HR, Inventory Management, CRM and supplier. All these departments have separate databases which they use to maintain information w.r.t. their work and each database has a different technology, landscape, table names, columns, etc.

Now Lets see, what kind of issues or challenges can occurs in Extraction process of ETL.
Data Inconsistency: The retail company receive monthly sales flat files(i.e. CSV) or excel from third party sales vendor. From their physical stores they also receive daily sales data in the database itself. While merging sales data from both sources it is crucial to maintain data is consistent across different sources and discrepancies or conflicts that could impact downstream processes and analysis.
Data mapping issues: When the extraction process does not correctly map the source data to the target data structures, data mapping issues can arise. Let's say the employee data is coming from HR department, but mapped incorrectly. Which can cause incorrect or corrupted data in target system.

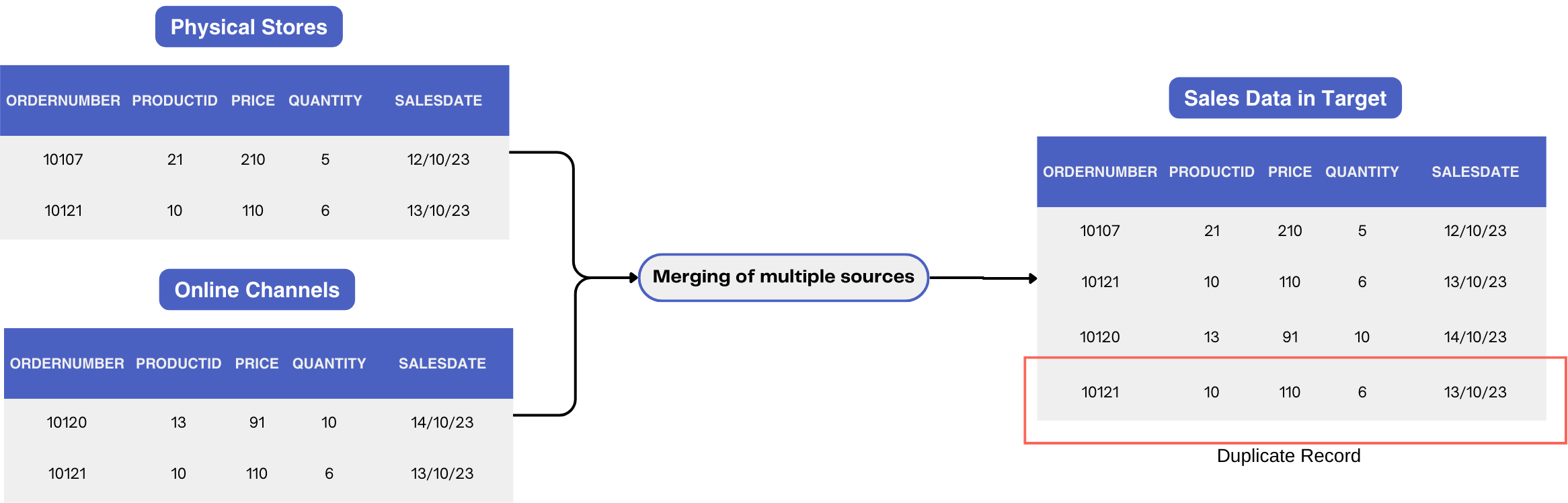
Data duplication: The retail company may receive sales data from various sources, such as physical stores, online channels, and third-party marketplaces. If the extraction process does not handle data duplication properly, the same sales transactions could be extracted from different sources and loaded into the target system, resulting in duplicate records. This can lead to inaccurate sales reporting and skewed analytics.
Data loss: During the extraction process, connectivity issues or system failures can occur, resulting in data loss. For example, if the extraction process fails midway, some sales transactions from a specific time period may not be extracted and loaded into the target system. This can result in missing sales data for that period, potentially impacting inventory management and financial reporting.
Incorrect data type: In the extraction process, the retail company may extract customer data from various sources like CRM systems, loyalty programs, and social media platforms. For instance, if a customer's birth date is incorrectly mapped as a string instead of a date data type, it can affect age calculations or targeted marketing campaigns. Another example of having "total" in "orders" table is mapped to integer instead of decimal.

Issue in incremental load(ingestion) of data: After initial migration of data , ETL pipeline need to ingest data in incremental load to keep system up to date. Let's assume, the retail company may extract daily sales data from different sources. If the extraction process fails to accurately identify and extract only the new or changed sales transactions, it can result in inconsistent or redundant data in the target system. For example, if the extraction process mistakenly loads previously extracted sales data again, it can lead to overcounting of sales and inaccurate revenue calculations.
How to Test Extraction Process
Now we understand why testing of extraction process in ETL is equally important as transformation. Now lets explore how we can over come issues and challenges faced in extraction.
Structure Validation
Review the Data Model, i.e. the structure of the data model, including the schema and data types of columns.
Let's say if the source data model for the product catalog table includes columns such as product ID, name, price, and description, with the appropriate data types assigned to each column. Target table schema should also match the source to correctly accommodate all required values.
Validating Mapping
Verify that the mapping between the source and target systems is accurate, ensuring correct data transformation and mapping of columns.
For example, if the source system's "order_date" column is mapped to the target system's "purchase_date" column. Then we need to ensure, that extraction process is correctly transferring the date values.
Validate Constraints
Ensure that table relationships, such as joins and keys i.e. foreign key, primary key, are maintained throughout the ETL process to maintain data integrity.
For instance, if there is foreign key relationship between the "order" table's "customer_id" column and the "customer" table's "customer_id" column. Then it should preserved during the extraction. That will ensure that each order is associated with a valid customer.
Sample data comparison
Comparing a few samples of data between the source and the target system, can find many mapping issues early in the stag. That will also save some time to run thorough column to column mapping check, which is time consuming.
For example, Compare a randomly selected set of product records from the source system with the corresponding records in the target system to verify that the data has been accurately transformed and loaded.
Data Completeness
Data loss: Validate that no records are lost during extraction process. Lets consider below-
Count Validation: Validate the counts of records or data elements in the source and target systems to ensure consistency and accuracy.
It can be done by writing the following queries.SELECT count (1) FROM db_source.product; SELECT count (1) FROM db_target.product;Data Profile Validation: Validate the overall data characteristics and profile, including statistical analysis, distributions, and patterns in the target systems should match with source.
For Example, Perform data profiling on the "order_amount" column to analyze the minimum, maximum, average, and standard deviation values in the source and target systems, ensuring that the data is consistent and within expected ranges.Column Data Profile Validation: It involves comparing the distinct values and their count in source and target. Let's say in source "orders" table have 22 distinct "order_date" values and "20-01-24" have 10 count. That means we have 10 orders on 20th Jan 24. It should match with target data as well after extraction.
SELECT order_date, count (1) FROM db_source.orders group by order_date; SELECT order_date, count (1) FROM db_target.orders group by order_date;
Missing Data Check: Check for null columns in the target system that should have valid values, ensuring that no data is missing where it should be present.
For instance, Email is a required field in CRM customer records, then we need to validate if the "customer_email" column in the target system contains valid email addresses extracted from the source system, without any missing or null values.SELECT customer_id FROM customers where customer_email is null or customer_email = ''Validate deduplication: After Extraction target system should not have duplicate values. Let's say in CRM there should not be any duplicate record for a customer, We can validate the same by checking for duplicate email entries.
select first_name, last_name, email, count (1) FROM customers GROUP BY first_name, last_name, email HAVING count(1)>1;
Data Correctness
There might be transformation while extracting and storing data in target. That require verification of data accuracy and correctness.
Let's say, in product table the "price" column should not be "0" or less. That kind of checks are necessary to ensure consistency and integrity of data. Lets refer to below query for the same validation.
select product_id FROM products where price <= 0;
Validation of Incremental Load
In ETL, the full load of data is performed only once, and thereafter, most of the ETL processes involve daily incremental loads from sources. In such cases, testing ensures that only CDC records from sources are ingested or updated in the target.
Let's say, If the incremental load is only append mod, then if there are changes like price of product, then it will create a duplicate record for product in target. So each operation (insert/ update / delete) should be exactly performed in target.
Performance Check
Measure the performance of the ETL process by assessing the time taken to extract, transform, and load data, comparing against predefined performance targets. Measure the time taken to extract and load a large volume of inventory data into the target system, ensuring that the ETL process meets the required performance criteria and completes within the specified time frame.
Challenges in different type of sources:
There can be many challenges in testing of extraction process of ETL due to multiple source type such as flat files, Excel files, databases, and WebSocket streams. Overcoming them requires understanding the unique challenges associated with each type and implementing appropriate strategies. Here are few of the many challenges for each source type:
Flat Files
Lack of standardized schema and metadata.
Variations in file formats (CSV, TSV, etc.).
Large file sizes and performance issues.
Excel Files
Multiple sheets within a single file.
Data inconsistencies and formatting issues.
Limited data type support.
Database Source
Different database types (relational, NoSQL, etc.).
Varying database schemas and data models.
Handling complex SQL queries and joins.
Websocket Stream Input
Real-time data streaming with continuous updates.
Handling high data volumes and velocity.
Ensuring data consistency and integrity.
To overcome the same, we need to prepare strategy for each separately. Most common issue is accessibility of data and to have common validation checks. For example, we can use one method to check for null values in flat files and Excel files, but the same method cannot be used for WebSocket streams.
Collaborate with Dev and Product:
To effectively test the extraction process, QA teams definitely need support from developers or product teams.
Below are few of many areas where dev and product can help in ETL testing of extraction:
Clear documentation of the extraction requirements and specifications. Like detailed source to target mapping of tables and columns, behaviour and structure of different data, data profile, relationship between various datasets etc.
Access to sample data or test environments to simulate different extraction scenarios. This will help QA to prepare their test plan & use cases in advance, which in result help in finding various egde-cases. Involving dev and product in review of this cases will greatly reduce feedback time on process testing as well.
Collaboration and communication channels for addressing any issues or clarifications during testing. As ETL testing is not same as testing of any web app, there might be many occurrence of false bug due to incomplete understanding or sudden requirement change. Having a common communication channels can minimise such cases.
Let's Conclude:
Testing Extraction process of ETL is a critical aspect of ensuring data quality and accuracy in the data integration process. It is as important as testing of transaction process. The challenges posed by different types of data sources, such as flat files, Excel files, databases, and WebSocket streams, require careful consideration and appropriate strategies.
Overall, addressing these challenges requires technical expertise, proper planning, and the use of suitable tools or frameworks. By understanding the unique characteristics and requirements of each data source, organizations can ensure the success of their ETL testing efforts. That will resulting in improved data quality, reliability, and integrity throughout the data integration process.
By following these best practices and incorporating real-life examples, you can enhance your ETL testing efforts and ensure the reliability and accuracy of the data extraction process in your projects.
Subscribe to my newsletter
Read articles from Yogendra Porwal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yogendra Porwal
Yogendra Porwal
As an experienced Test Automation Lead, I bring over 9 years of expertise in Quality Assurance across diverse software domains. With technical proficiency in multiple verticals of testing, including automation, functional, performance and security testing among others, my focus is on applying this knowledge to enhance the overall quality assurance process. I also like to go on long journeys with my bike , do sketching in my free time and have keen interest in video games.