How To Deal With Big Data in Distributed System, Its MapReduce
 I Len
I Len
Data generation was once limited to a single format. It could be managed with one storage unit and one processor. Data generation gradually started increasing, and new varieties of data emerged. This started happening at high speed, making it more difficult for a single processor to handle.
Data generation has increased by leaps and bounds in the last decade. This includes large volumes of various formats of data being generated at a very high speed. In the earlier days, it was not a hard task to manage data, but with the increase in data, it has become more difficult to store, process, and analyze it. This is also known as Big Data.
Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them. Big data challenges include capturing, storage, analysis, search, sharing, transfer, visualization, querying, updating and information privacy.
Lately, the term big data tends to refer to the use of predictive analytics, user behavior analytics, or certain other advanced data analytics methods that extract value from data, and seldom to a particular size of data set.
Challenges of Big Data
Scalability: being able to accommodate (rapid) changes in the growth of data, either in traffic or volume.
Scaling up, or vertical scaling, involves obtaining a faster server with more powerful processors and more memory.
Scaling out, or horizontal scaling, involves adding servers for parallel computing.
Complexity: scalable systems are more complex than traditional ones.Techniques like Shards (or partitioning), Replicas, Queues, Resharding scripts can be difficult to setup and maintain. Parallel programming is complex.
Reliability: Corrupted data, downtime, human mistake, etc. are more likely to happen on a complex system.
How to deal with them?
In 2003, Google released a whitepaper called “The Google File System”. Subsequently, in 2004, Google released another whitepaper called “MapReduce: Simplified Data Processing on Large Clusters”. At the same time, at Yahoo!, Doug Cutting (who is generally acknowledged as the initial creator of Hadoop) was working on a web indexing project called Nutch.
The Google whitepapers inspired Doug Cutting to take the work he had done to date on the Nutch project and incorporate the storage and processing principles outlined in these whitepapers. The resultant product is what is known today as Hadoop.
In January 2008, Hadoop was made its own top-level project at Apache, confirming its success and its diverse, active community.
Today, Hadoop is widely used in mainstream enterprises.
What is Hadoop
Hadoop is a framework that allows for distributed storage and distributed processing of large data sets across clusters of computers using simple programming models.
A software framework is an abstraction in which common code providing generic functionality can be selectively overridden or specialized by user code providing specific functionality.
A computer cluster is a set of loosely or tightly connected computers that work together so that, in many respects, they can be viewed as a single system. Individual computers within a cluster are referred to as nodes.
Hadoop is designed to scale out from a single server to thousands of machines, each machine offers local computing and storage capabilities.
Hadoop Ecosystem
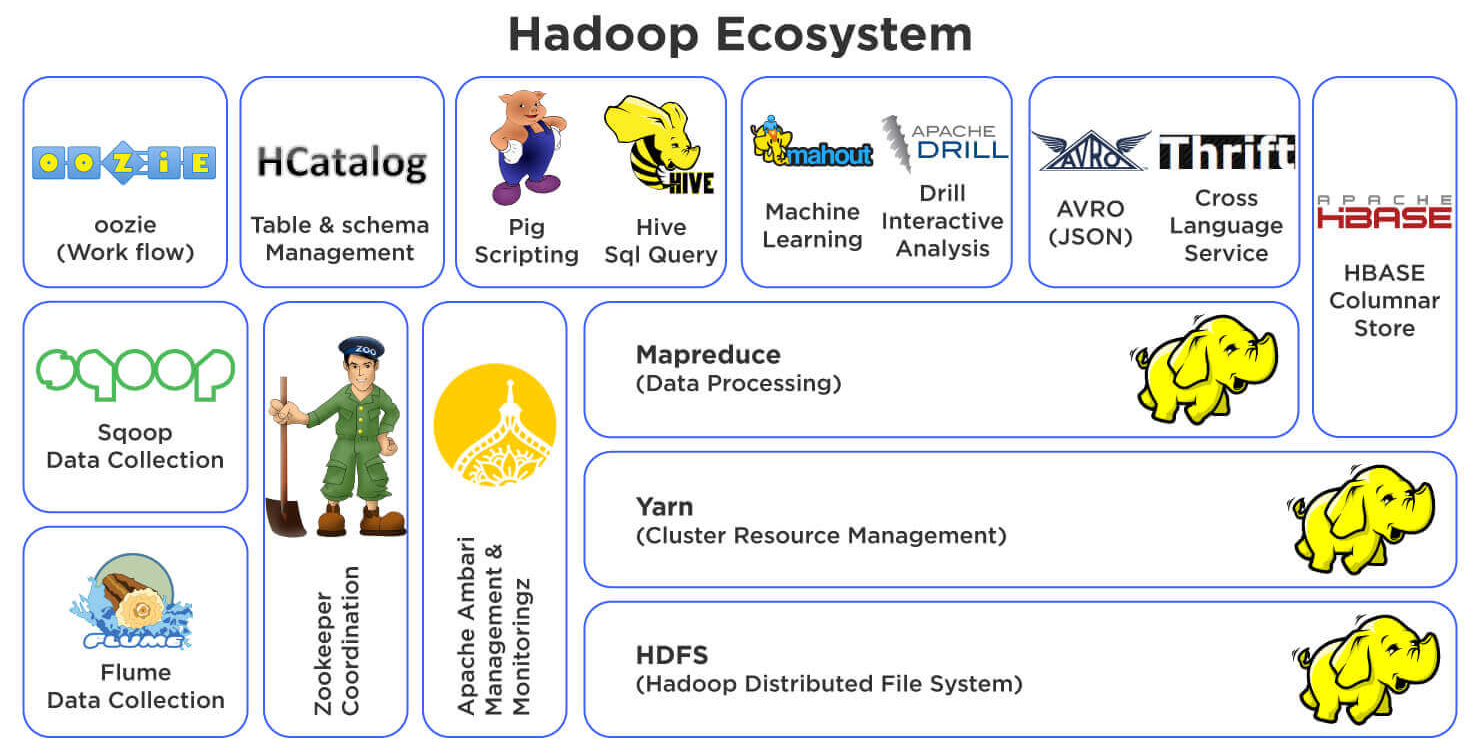
With other components such as:
Sqoop: used to transfer bulk data between Apache Hadoop and structured datastores such as relational databases.
Flume: is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into HDFS.
Oozie: is a workflow scheduler system to manage Apache Hadoop jobs
Kafka: is a highly scalable, fast and fault-tolerant messaging application used for streaming applications and data processing.
Hue: is a Web application for querying and visualizing data by interacting with Apache Hadoop.
Ambari: provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Hadoop Commercial Landscape
Hadoop is an open source project but there are many commercial vendors who supply commercial distributions, support, management utilities and more.
In 2008, the first commercial vendor, Cloudera, was formed by engineers from Google, Yahoo!, and Facebook. Cloudera subsequently released the first commercial distribution of Hadoop, called CDH (Cloudera Distribution of Hadoop).
In 2009, MapR was founded as a company delivering a “Hadoop-derived” software solution implementing a custom adaptation of the Hadoop filesystem (called MapRFS) with Hadoop API compatibility.
In 2011, Hortonworks was spun off from Yahoo! as a Hadoop vendor providing a distribution called HDP (Hortonworks Data Platform).
Cloudera, Hortonworks, and MapR are referred to as “pure play” Hadoop vendors as their business models are founded upon Hadoop. Many other vendors would follow with their own distribution—such as IBM, Pivotal, and Teradata.
Apache Hadoop HDFS Architecture
Big Data usually outgrows the storage capacity of a single physical machine. It becomes necessary to partition the data across a network of machines, or cluster. Hence we need a file system that manage the storage across a network of machines. Such file systems are called distributed file systems.
Distributed file systems are more complex than regular disk file systems, since they are network based. One of the biggest challenges is to tolerate node failure without suffering data loss.
Hadoop comes with a distributed file system called HDFS, which stands for Hadoop Distributed File system.
HDFS Design
HDFS was inspired by the GoogleFS whitepaper released in 2003. Google outlined how they were storing the large amount of data captured by their web crawlers.
There are several key design principles which require that the file system
is scalable.
is fault tolerant.
uses commodity hardware.
supports high concurrency.
HDFS appears to a client as if it is one system, but the underlying data is located in multiple different locations. HDFS gives a global view of your cluster. HDFS is immutable, meaning it has the inability to update data after it is committed to the file system.
HDFS Drawbacks
HDFS does not work well for some applications, including:
Low-latency data access: Applications that require low-latency access to data, in the tens of milliseconds range, will not work well with HDFS.
Lots of small files: Because filesystem metadata is hold in memory, the limit to the number of files in a filesystem is governed by the amount of memory available. Each file, directory, and block takes about 150 bytes metadata in memory, e.g. one million files, each taking one block, would need at least 300 MB of memory.
Multiple writers: Files in HDFS may be written to by a single writer. Writes are always made at the end of the file, in append-only fashion. There is no support for multiple writers or for modifications at arbitrary offsets in the file.
MapReduce
Google released a paper on MapReduce technology in December 2004. This became the genesis of the Hadoop Processing Model. So, MapReduce is a programming model that allows us to perform parallel and distributed processing on huge data sets.
Hadoop MapReduce is a opensource software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters(thousands of nodes) of commodity hardware in a reliable, perform parallel fault-tolerant manner.
Parallel Processingin Traditional Way
When the MapReduce framework was not there, how parallel and distributed processing used to happen in a traditional way. So, let's take an example where I have a weather log containing the daily average temperature of the years from 2000 to 2015. Here, I want to calculate the day having the highest temperature in each year.
So, just like in the traditional way, I will split the data into smaller parts or blocks and store them in different machines. Then, I will find the highest temperature in each part stored in the corresponding machine. At last, I will combine the results received from each of the machines to have the final output.
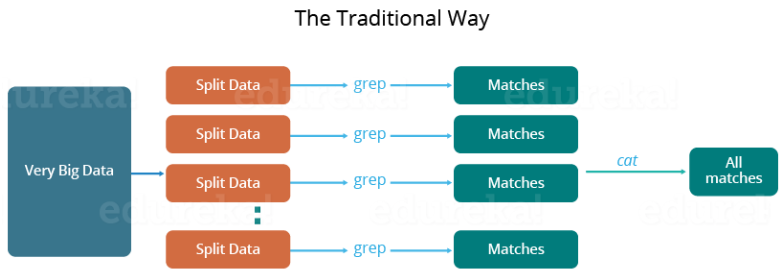
Let's look at the challenges associated with this traditional approach:
Critical path problem: It is the amount of time taken to finish the job without delaying the next milestone or actual completion date. So, if, any of the machines delay the job, the whole work gets delayed.
Reliability problem: What if, any of the machines which are working with a part of data fails? The management of this failover becomes a challenge.
Equal split issue: How will I divide the data into smaller chunks so that each machine gets even part of data to work with. In other words, how to equally divide the data such that no individual machine is overloaded or underutilized.
The single split may fail: If any of the machines fail to provide the output, I will not be able to calculate the result. So, there should be a mechanism to ensure this fault tolerance capability of the system.
Aggregation of the result: There should be a mechanism to aggregate the result generated by each of the machines to produce the final output.
These are the issues which I will have to take care individually while performing parallel processing of huge data sets when using traditional approaches.
Parallel Processingin Modern Way
To overcome these issues, we have the MapReduce framework which allows us to perform such parallel computations without bothering about the issues like reliability, fault tolerance etc. Therefore, MapReduce gives the flexibility to write code logic without caring about the design issues of the system. MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
MapReduce distributes the processing of data on the cluster.
MapReduce works by breaking the processing into two phases: the map phase (transforming) and the reduce phase (aggregating).
Each phase has key-value pairs as input and output, the types of which may be chosen by the programmer.
Let's understand more about MapReduce and its components.
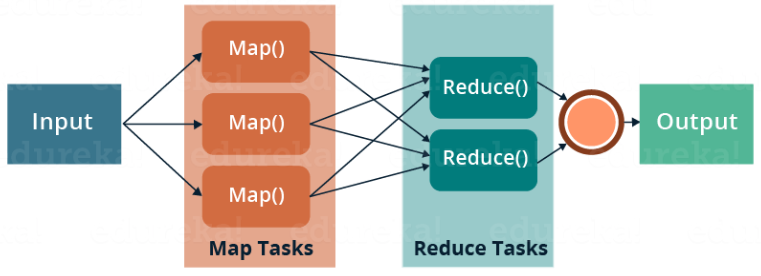
MapReduce majorly has the following three phases. They are:
Map Phase
The Map phase is the initial phase of processing in which we will use an input dataset as a data source for processing. Here, RecordReader processes each Input record and generates the respective key-value pair. Hadoop’s Mapper store saves this intermediate data into the local disk.
Input Split:
It is the logical representation of data. It represents a block of work that contains a single map task in the MapReduce Program.
RecordReader:
It interacts with the Input split and converts the obtained data in the form of Key-ValuePairs.
Key-Value Pairs
The key is an identifier; for instance, the name of the attribute. In MapReduce programming in Hadoop, the key is not required to be unique which may be chosen by the programmer.
Reduce Phase
Each Reduce task (or Reducer) executes a reduce() function for each intermediate key and its list of associated intermediate values.
The output from each reduce() function is zero or more key-value pairs considered to be part of the final output.
This output may be the input to another Map phase in a complex multistage computational workflow.
Shuffle and Sort
Between the Map phase and the Reduce phase, there is the Shuffle and Sort phase.
Intermediate data from completed Map tasks (keys and lists of values) is sent to the appropriate Reducer, depending upon the partitioning function specified.
The keys and their lists of values are then merged into one list of keys and their associated values per Reducer, with the keys stored in key-sorted order according the key datatype.
The Shuffle-and-Sort phase is the entire process of transferring intermediate data from Mappers to Reducers and merging the lists of key-value pairs into lists in key-sorted order on each Reducer.
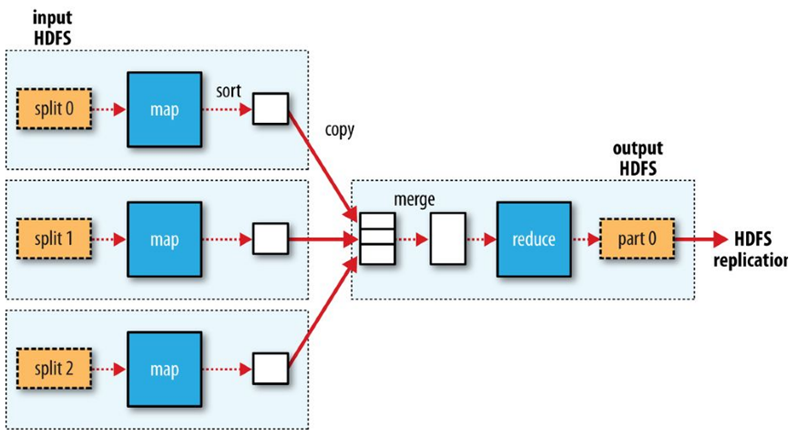
Reduce Tasks
Reduce tasks don’t have the advantage of data locality.The input to a single reduce task is normally the output from all mappers.
The sorted map outputs have to be transferred across the network to the node where the reduce task is running, where they are merged and then passed to the user-defined reduce function.
The output of the reduce is normally stored in HDFS for reliability.
For each HDFS block of the reduce output, the first replica is stored on the local node, with other replicas being stored on off-rack nodes for reliability (remember HDFS block replication).
Writing the reduce output does consume network bandwidth, but only as much as a normal HDFS write pipeline consumes.
Data flow with a single reduce task
When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task.
There can be many keys (and their associated values) in each partition, but the records for any given key are all in a single partition.
The partitioning can be controlled by a user-defined partitioning function.
Each reduce task is fed by many map tasks (“Shuffle” from the “Shuffle and Sort”).
Data flow with multiple reduce tasks

MapReduce Example
Let's understand, how a MapReduce works by taking an example where I have a text file called example.txt whose contents are as follows:
Dear, Bear, River, Car, Car, River, Deer, Car and Bear
Now, suppose, we have to perform a word count on the sample.txt using MapReduce. So, we will be finding the unique words and the number of occurrences of those unique words.
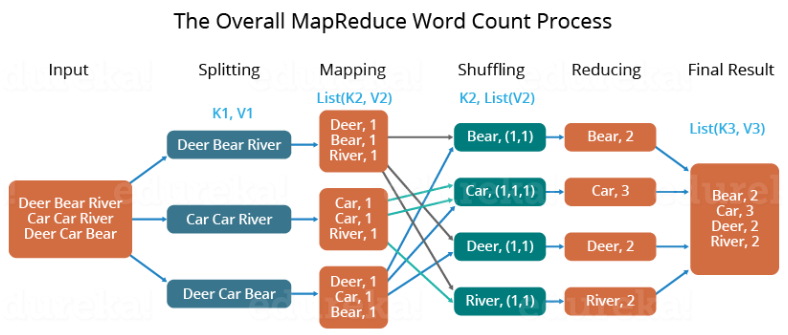
First, we divide the input into three splits as shown in the figure. This will distribute the work among all the map nodes.
Then, we tokenize the words in each of the mappers and give a hardcoded value (1) to each of the tokens or words. The rationale behind giving a hardcoded value equal to 1 is that every word, in itself, will occur once.
Now, a list of key-value pair will be created where the key is nothing but the individual words and value is one. So, for the first line (Dear Bear River) we have 3 key-value pairs – Dear, 1; Bear, 1; River, 1. The mapping process remains the same on all the nodes.
After the mapper phase, a partition process takes place where sorting and shuffling happen so that all the tuples with the same key are sent to the corresponding reducer.
So, after the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1].., etc.
Now, each Reducer counts the values which are present in that list of values. As shown in the figure, reducer gets a list of values which is [1,1] for the key Bear. Then, it counts the number of ones in the very list and gives the final output as – Bear, 2.
Finally, all the output key/value pairs are then collected and written in the output file.
Advantages of MapReduce
The two biggest advantages of MapReduce are:
Parallel Processing:
In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously. So, MapReduce is based on Divide and Conquer paradigm which helps us to process the data using different machines. As the data is processed by multiple machines instead of a single machine in parallel, the time taken to process the data gets reduced by a tremendous amount as shown in the figure below (2).
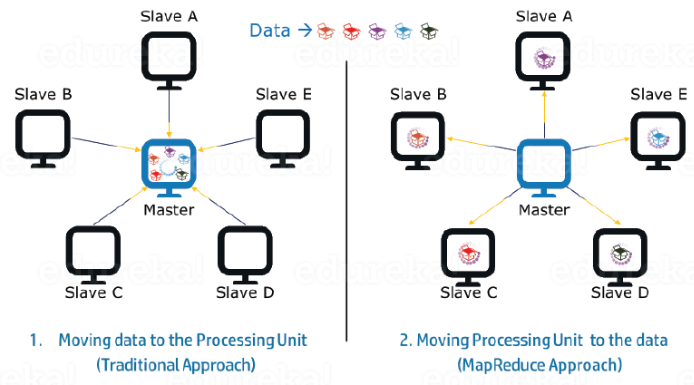
Data Locality
Instead of moving data to the processing unit, we are moving the processing unit to the data in the MapReduce Framework. In the traditional system, we used to bring data to the processing unit and process it. But, as the data grew and became very huge, bringing this huge amount of data to the processing unit posed the following issues:Moving huge data to processing is costly and deteriorates the network performance.
Processing takes time as the data is processed by a single unit which becomes the bottleneck.
The master node can get over-burdened and may fail.
Now, MapReduce allows us to overcome the above issues by bringing the processing unit to the data. So, as you can see in the above fingure that the data is distributed among multiple nodes where each node processes the part of the data residing on it. This allows us to have the following advantages:
It is very cost-effective to move processing unit to the data.
The processing time is reduced as all the nodes are working with their part of the data in parallel.
Every node gets a part of the data to process and therefore, there is no chance of a node getting overburdened.
Explanation of MapReduce Program
The entire MapReduce program can be fundamentally divided into three parts:
Mapper Phase Code
Reducer Phase Code
Shuffle and Sort Code
Mapper code:
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
Created a class Map that extends the class Mapper which is already defined in the MapReduce Framework.
Define the data types of input and output key/value pair after the class declaration using angle brackets.
Both the input and output of the Mapper is a key/value pair.
Input:
The key is nothing but the offset of each line in the text file: LongWritable
The value is each individual line (as shown in the figure at the right): Text
Output:
The key is the tokenized words: Text
We have the hardcoded value in our case which is 1: IntWritable
Example – Dear 1, Bear 1, etc.
Written a Java code where we have tokenized each word and assigned them a hardcoded value equal to 1.
Reducer Code:
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values) {
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
Created a class Reduce which extends class Reducer like that of Mapper.
Define the data types of input and output key/value pair after the class declaration using angle brackets as done for Mapper.
Both the input and the output of the Reducer is a key-value pair.
Input:
The key nothing but those unique words which have been generated after the sorting and shuffling phase: Text
The value is a list of integers corresponding to each key: IntWritable
Example – Bear, [1, 1], etc.
Output:
The key is all the unique words present in the input text file: Text
The value is the number of occurrences of each of the unique words: IntWritable
Example – Bear, 2; Car, 3, etc.
Aggregated the values present in each of the list corresponding to each key and produced the final answer.
In general, a single reducer is created for each of the unique words, but, you can specify the number of reducer in mapred-site.xml.
Shuffle and Sort Code
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
In the driver class, set the configuration of our MapReduce job to run in Hadoop.
Give specify the name of the job, the data type of input/output of the mapper and reducer.
Specify the names of the mapper and reducer classes.
The path of the input and output folder is also specified.
The method
setInputFormatClass()is used for specifying how a Mapper will read the input data or what will be the unit of work. Here, chosenTextInputFormatso that a single line is read by the mapper at a time from the input text file.The
main()method is the entry point for the driver. In this method, instantiate a new Configuration object for the job.
Complete Source code:
package com.ilenlab.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount{
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values) {
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the output path automatically from hdfs so that we don't have to delete it explicitly
outputPath.getFileSystem(conf).delete(outputPath);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Run the MapReduce code:
The command for running a MapReduce code:
hadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output
Use case: KMeans Clustering using Hadoop’s MapReduce.
KMeans Algorithm is one of the simplest Unsupervised Machine Learning Algorithm. Typically, unsupervised algorithms make inferences from datasets using only input vectors without referring to known or labelled outcomes.
Executing the KMeans Algorithm using Python with a smaller Dataset or a .csv file is easy. But, when it comes to executing the Datasets at the level of Big Data, then the normal procedure cannot stay handy anymore.
That is exactly when you deal Big Data with Big Data tools. The Hadoop’s MapReduce. The following code snippets are the Components of MapReduce performing the Mapper, Reducer and Shuffle and Sort Jobs
Mapper Class
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center), new DoubleWritable(point));
}
Reducer Class
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}
Shuffle and Sort Code
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}
Now, we will go through the complete executable code
import java.io.IOException;
import java.util.*;
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.Reducer;
@SuppressWarnings("deprecation")
public class KMeans {
public static String OUT = "outfile";
public static String IN = "inputlarger";
public static String CENTROID_FILE_NAME = "/centroid.txt";
public static String OUTPUT_FILE_NAME = "/part-00000";
public static String DATA_FILE_NAME = "/data.txt";
public static String JOB_NAME = "KMeans";
public static String SPLITTER = "t| ";
public static List<Double> mCenters = new ArrayList<Double>();
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, DoubleWritable, DoubleWritable> {
@Override
public void configure(JobConf job) {
try {
Path[] cacheFiles = DistributedCache.getLocalCacheFiles(job);
if (cacheFiles != null && cacheFiles.length > 0) {
String line;
mCenters.clear();
BufferedReader cacheReader = new BufferedReader(
new FileReader(cacheFiles[0].toString()));
try {
while ((line = cacheReader.readLine()) != null) {
String[] temp = line.split(SPLITTER);
mCenters.add(Double.parseDouble(temp[0]));
}
} finally {
cacheReader.close();
}
}
} catch (IOException e) {
System.err.println("Exception reading DistribtuedCache: " + e);
}
}
@Override
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center),
new DoubleWritable(point));
}
}
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}
public static void main(String[] args) throws Exception {
run(args);
}
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}
}
Now, you guys have a basic understanding of MapReduce framework. You would have realized how the MapReduce framework facilitates us to write code to process huge data present in the HDFS. There have been significant changes in the MapReduce framework in Hadoop 2.x as compared to Hadoop 1.x. These changes will be discussed in the next blog of this MapReduce tutorial series. I will share a downloadable comprehensive guide which explains each part of the MapReduce program in that very blog.
source:
[1] https://thirdeyedata.io/hadoop-mapreduce/
[2] https://jheck.gitbook.io/hadoop/hdfs-and-mapreduce
[3] https://medium.com/@mohsin68.murtuza/425b23b67db2
[4] https://thirdeyedata.io/hadoop-mapreduce/
Subscribe to my newsletter
Read articles from I Len directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by