Row vs Column-Oriented (Columnar) Databases
 Shivanagouda Agasimani
Shivanagouda Agasimani
Prerequisites: Databases, Paging in memory management
You'd have come across different types of databases like Relational (MySQL), Document (MongoDB), Graph (Ne04j), Columnar (Cassandra), Key-Value pair (Redis), and some other types. But in this article, we'll particularly go into row-oriented databases and column-oriented databases and how data stored among these types of DBs affects the execution time of queries.
In a nutshell
While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in analytical applications.
Row oriented databases
In row-oriented databases, the tables are stored as rows on disk. You must know about pages on the hard disk. Each page will have a particular size as does each row in the table. Whole rows will be stored on each page as much as they can fit, completely. For example, assume page size = 16KB, and a table where each row size = 8KB. Each page can fit 2 rows completely. The whole row will be stored on a single page, with all the column values separated by a delimiter and multiple rows separated by a different delimiter.
A single IO read to the table fetches multiple rows with all their columns. In the above example, considering each IO fetches 4 pages, it'll fetch 8 rows with all their columns. More IOs are required to find a particular row in a table scan but once the row is found, all columns for that row are also found.
Consider a sample Employee table as follows. DBs like Postgres have a system column row_id (tuple_id) to uniquely identify each row.
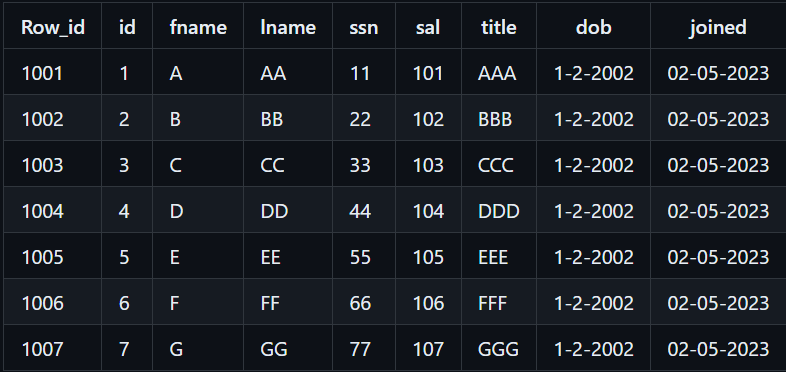
Storage representation of above data in pages (Row-oriented db):
Page 1 -1001, 1, A, AA, 11, 101, AAA, 1-2-2002, 02-05-2023 ||| 1002, 2, B, BB, 22, 102, BBB, 1-2-2002, 02-05-2023
Page 2 -1003, 3, C, CC, 333, 103, CCC, 1-2-2002, 02-05-2023 ||| 1004, 4, D, DD, 44, 104, DDD, 1-2-2002, 02-05-2023
Column-Oriented (Columnar) Databases
In column-oriented databases, the tables are stored as columns first on disk. This means that a single page contains single column values for multiple rows. If we assume page size = 16KB, each column size = 1KB, each page would contain four same column values of different rows, where the values are always with the tuple_id.
A single block IO read to the table fetches multiple-row values for the same column. In the above example, considering each IO fetches 2 pages, it'll fetch 8 same column values. Fewer IOs are required to get more values of a given column. However, working with multiple columns requires more IOs.
Storage representation of Employee table data in pages(Column-oriented db):
Format: column_val:tuple_id
Page 1 - 1:1001, 2:1002, 3:1003, 4:1004
Page 2 - 5:1005, 6:1006, 7:1007....
Page 3 - A:1001, B:1002, C:1003, D:1004
Page 4 - E:1005, F:1006, G:1007...
Page 5 - AA:1001, BB:1002, CC:1003, DD:1004
Page 6 - EE:1005, FF:1006, GG:1007...
Now that you know how the data is stored in each of the DB types, think of the following queries and find out the expected number of page retrievals for each query concerning both the types of DBs (assuming no indices)
1. SELECT fname FROM employee WHERE ssn = 66;
2. SELECT * FROM employee WHERE id = 1;
3. Select SUM(sal) from employee;
Differences
| Row-oriented database | Column-oriented Database |
| Optimal for r/w | Writes are slower |
| Compression isn't efficient | Compress greatly |
| OLTP (Online transaction processing) | OLAP (Online analytical processing) |
| Aggregation isn't efficient | Amazing for aggregation |
| Efficient queries w/multi-columns | Inefficient queries w/multi-columns |
Well, you've reached the end. Thank you.
Subscribe to my newsletter
Read articles from Shivanagouda Agasimani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shivanagouda Agasimani
Shivanagouda Agasimani
A backend software developer passionate about technology