Cosmic Navigator: Unveiling Constellations from CSV to Web
 Aarush Luthra
Aarush Luthra
Introduction
This blog guides one through an approach of using AWS services that automates data flow from a CSV file to DynamoDB table, and then rendering it on a webpage, with user interaction to retrieve information about a specific Name.
This is possible with help of key AWS Services like EC2, Lambda, S3, API Gateway, and DynamoDB, along with essential features like AWS CloudWatch and IAM.
Let’s begin as we navigate through the clouds!!
Diagram
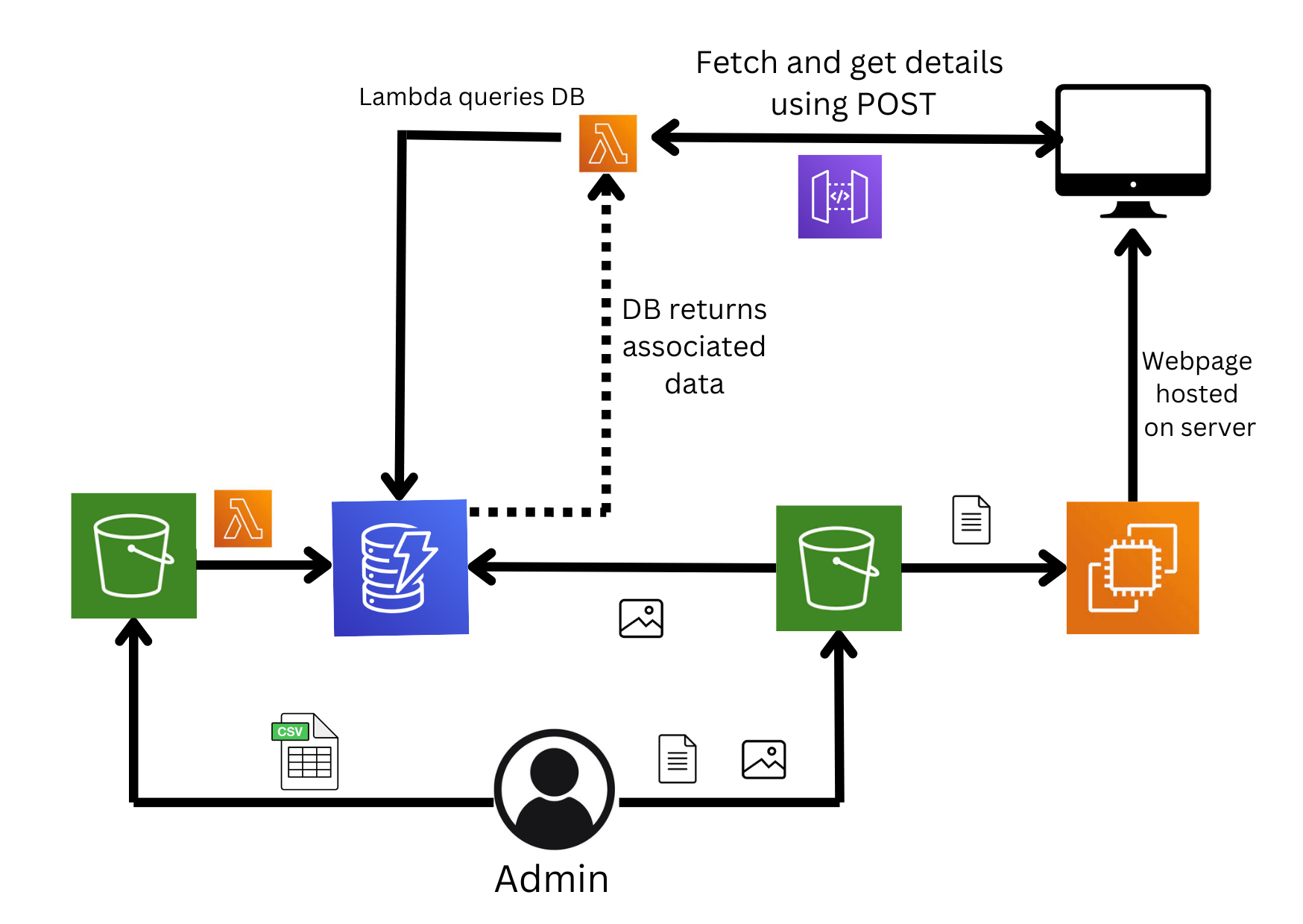
Features used:
Amazon S3: For secure and scalable object storage of your CSV file and website assets
Lambda Function: For executing server-less functions in response to events.
Amazon EC2: For hosting your frontend code
Amazon API Gateway: For building REST API, that is used for accepting user input and interacting with Lambda functions.
AWS CloudWatch: Monitoring, logging and troubleshooting
AWS IAM: For managing access and security permissions.
Step by Step Guide:
Create a S3 Bucket:
Create a S3 bucket, this acts as the storage for the CSV dataset
Set up DynamoDB
Create a DynamoDB table, where partition key is Name
Configure a Lambda function
a) Create a lambda function and create a trigger for S3 bucket, ensuring the Lambda function gets invoked upon file upload.
b) Implement the function to copy data from the CSV file into a DynamoDB table.
Lambda Function:
import json import boto3 import io import csv dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('tablename') s3Client = boto3.client('s3') def lambda_handler(event, context): print(f"Event: {json.dumps(event)}") bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] print(f"Processing file: {key}") response = s3Client.get_object(Bucket=bucket, Key=key) data = response['Body'].read().decode('utf-8') reader = csv.reader(io.StringIO(data)) next(reader) for row in reader: item = { 'Name': row[0], 'Description':(row[1]), 'Major Stars': (row[2]), 'Asterisms':(row[3]), 'Season of Visibility':(row[4]), 'Interesting Facts':(row[5]) 'S3Key':(row[6]), 'ImageURL':(row[7]) } table.put_item(Item=item) print("Data stored in DynamoDB.") return { 'statusCode': 200, 'body': 'Data processed and stored in DynamoDB.' }Configure an API Gateway
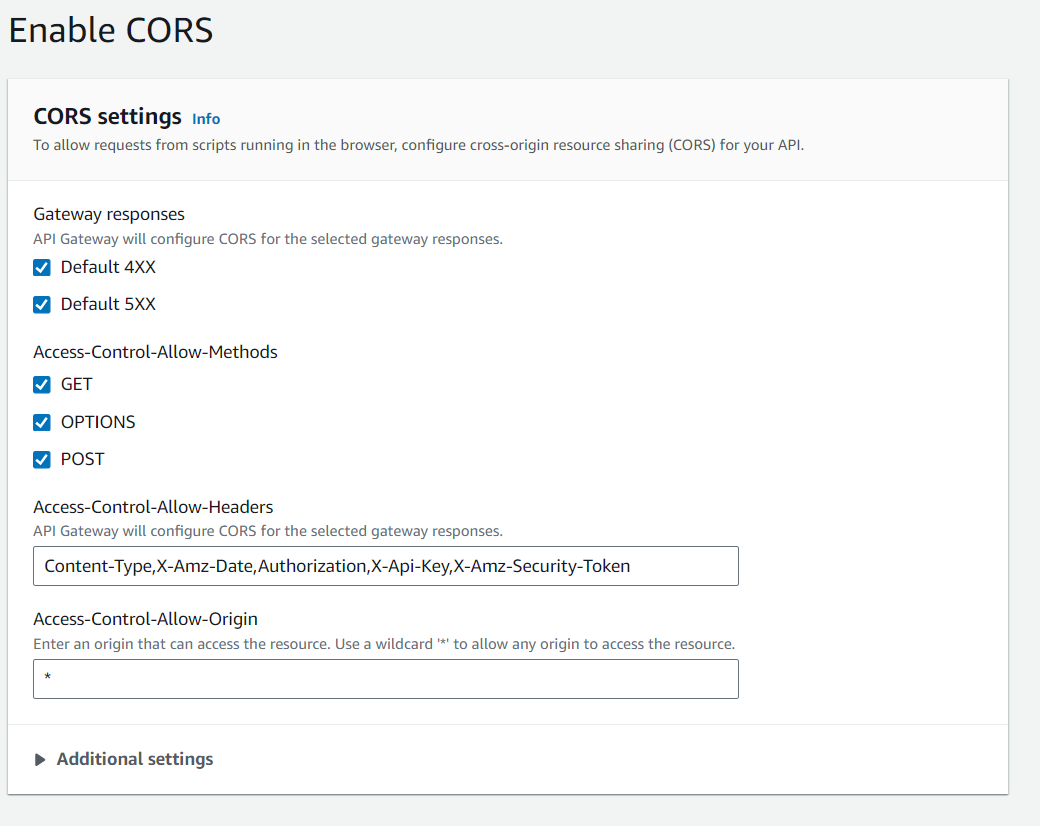
Create a REST API with a resource, method(POST or GET) and enable CORS
Configure a Lambda function
Create a new Lambda Function, this will respond to API requests and fetch data from backend database
import boto3 def lambda_handler(event, context): dynamodb = boto3.resource('dynamodb') table_name = 'tablename' table = dynamodb.Table('tablename') try: name = event['name'] except Exception as e: return { 'statusCode': 400, 'headers': { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'OPTIONS,POST' }, 'body': 'Error parsing request body: {}'.format(str(e)) } try: response = table.query( KeyConditionExpression='#name = :name', ExpressionAttributeNames={'#name': 'Name'}, ExpressionAttributeValues={':name': name} ) items = response.get('Items', []) if items: result = {} for item in items: result['Name'] = item['Name'] result['Description'] = item['Descrption'] result['Major Stars'] = item['Major Stars'] result['Asterisms'] = item['Asterisms'] result['Season of Visibility'] = item['Season of Visibility'] result['Interesting Facts'] = item['Interesting Facts'] result['ImageURL'] = item.get('ImageURL') return { 'statusCode': 200, 'headers': { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'OPTIONS,POST' }, 'body': result } else: return { 'statusCode': 404, 'headers': { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'OPTIONS,POST' }, 'body': {'Error!': 'No details found for the provided name.'} }Create a S3 bucket
a) Create another S3 bucket, this will be used to store the frontend codes
b) Modify the bucket policy
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::bucket-name/*" } ] }Launch an EC2 instance
a) Launch an EC2 instance with the required keypairs, security groups and IAM roles
b) Click on connect, in order to configure a server and copy the frontend files
sudo yum update -y sudo yum install nginx -y sudo systemctl start nginx sudo systemctl enable nginx aws s3 cp s3://bucket-name/file-name /usr/share/nginx/html/ sudo systemctl restart nginxc) Now, click on the IP Address and your site is up and running !!

Conclusion
As we reach the culmination, it is evident that this architecture unlocks a powerful toolkit for dynamic data management and engaging web experiences.
With automated workflows that seamlessly integrate data ingestion, processing, and presentation, businesses can adapt and innovate at the speed of thought, where they can automate transfer of a CSV dataset to a table and then render it on a webpage.
Please, feel free to drop suggestions in comments below
Thank you for reading!
Aarush Luthra
Subscribe to my newsletter
Read articles from Aarush Luthra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aarush Luthra
Aarush Luthra
Driven by curiosity and a passion for innovation, I am a tech enthusiast with a growing expertise in cloud computing, dev-ops and web development. Currently, I’m building projects that range from deploying machine learning models on AWS SageMaker to designing interactive web applications.