Understanding Machine Learning: A Beginner's Guide
 Ridwan Ibidunni
Ridwan Ibidunni
Assuming you are a member of the admissions committee at a university, a student's acceptance hinges on two scores: their test results and their grades. These two scores are also known as the determining factors, or more formally, input features, which we will use to forecast the outcome of our decision – either the student's acceptance or rejection. A prediction greater than or equal to zero results in acceptance, while a prediction less than zero leads to rejection. The ability of a computer to autonomously make such judgments without explicit programming is termed Machine Learning.
Perceptron
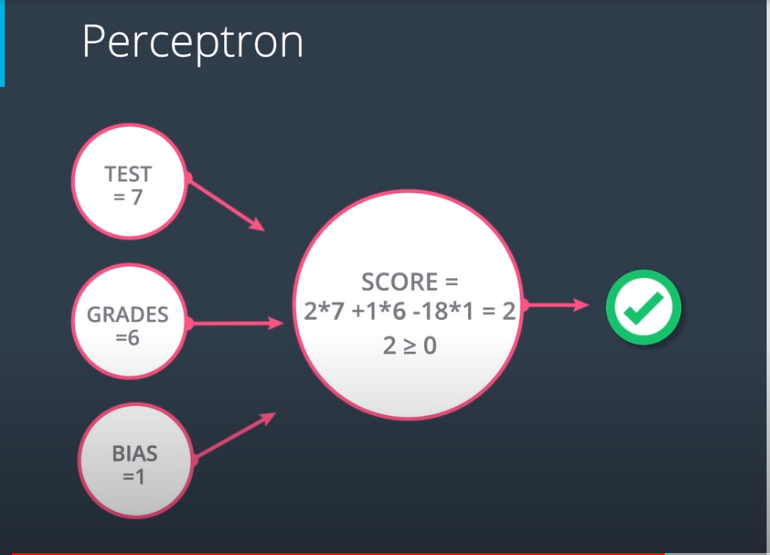
The process described above is formally represented by a concept called the Perceptron. This type of artificial neural network is inspired by the neural networks present in animal brains. It's designed to imitate the human ability to learn and recognize patterns when making decisions. For instance, imagine you have inputs representing a test score of 7 and a grade score of 6, along with a bias. These inputs can be fed into the perceptron.
What the perceptron does is it plots the point (7, 6) on a graph to determine if it falls within the positive or negative area of the graph before making a decision to accept (a score greater than or equal to 0) or reject (a score less than 0) the student. This process can be visualized in the graph below.
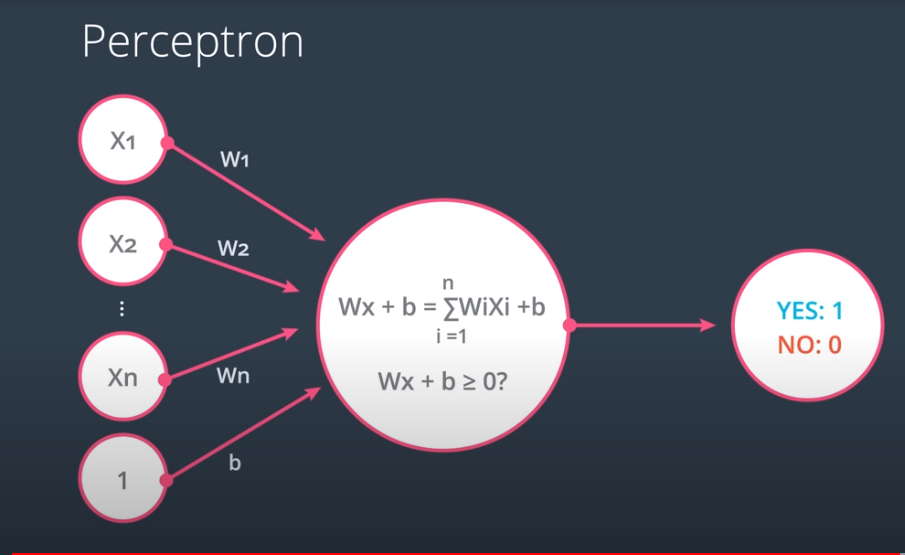
In broader terms, the perceptron can receive inputs \(x_1, x_2, \\... x_n \) and a bias for the node within the neural network, where the equation is given by \(Wx + b = \sum_{i = 1}^n W_i X_i + b\).
\(Where:\)
\(W: \text{weight or slope}\)
\(X: \text{input feature}\)
\(b: \text{bias}\)
Supervised Learning
Supervised learning is a branch of machine learning wherein the algorithm learns from labeled training data, with each training example consisting of an input feature (denoted as x) and a corresponding target variable or output feature (denoted as y). The algorithm's primary task is to learn the mapping or relationship between the input data and the corresponding output data.
Supervised learning can be applied through two main problem types: Classification and Regression. Classification addresses scenarios where the objective is to identify the relationships between input and output that are categorical or discrete. This means that the number of potential outputs is well-defined. For instance, consider training a model to distinguish between 'spam' and 'not-spam' messages. This represents a binary classification problem, with only two potential output categories. If there are multiple classes to predict, it is known as a multi-class classification. Notable algorithms for classification include logistic regression, decision trees, and support vector machines.
Regression, on the other hand, is a different flavor of supervised learning. It addresses scenarios where the objective is to ascertain relationships between input and an infinite array of potential outputs. Unlike classification, regression predicts continuous values for the output variable. This continuous value determines the placement of the input along a numerical scale. Prominent algorithms for regression include linear regression, decision tree regression, and support vector regression.
Unsupervised Learning
Unsupervised Learning represents another branch of machine learning, focused on understanding relationships between input features (denoted as x) and an output or target variable (denoted as y). Unlike supervised learning, which relies on labeled datasets, unsupervised learning examines relationships without these explicit labels or answers. Instead, the algorithm is left to discern the relationships by itself. The primary aim of unsupervised learning is to recognize patterns, structures, or associations within the data without specific guidance or supervision.
Examples of unsupervised learning methods include:
Clustering: In this technique, the algorithm groups data points into clusters based on similarities. Data points within a cluster are expected to be more alike than those in different clusters. Notable clustering algorithms include K-means clustering and hierarchical clustering.
Dimensionality Reduction: This unsupervised learning method reduces the number of features (or dimensions) in a dataset while attempting to retain as much essential information as possible. This simplifies the data and facilitates the visualization of high-dimensional data in a lower-dimensional space. Dimensionality reduction techniques include Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE).
Reinforcement Learning
Reinforcement Learning is a machine learning approach where an algorithm (agent) learns how to make decisions through interactions with its environment. In contrast to supervised learning, which uses labeled data, or unsupervised learning, which doesn't use labels, RL operates differently: it learns through trial and error. The main idea behind RL is to figure out a set of actions (or a policy) that an agent should take in different situations to maximize its overall reward. The agent explores the environment, takes actions, gets feedback, and updates its strategy based on the feedback received.
Applications of Machine learning
Machine learning, much like the evolution of electricity, has had a significant impact on various sectors of human endeavor. In today's world, we see its influence in many areas:
Healthcare: The advancement of machine learning has revolutionized the discovery of drugs, prediction of ailments, and the delivery of personalized treatments.
Finance: Anomaly detection, a type of unsupervised machine learning, is used for fraud detection in the financial sector.
Transportation: Machine learning methodologies, such as image and object detection, underpin the development of autonomous vehicles, adept at navigating complex roadways.
Chatbots: Machine learning has enabled the creation of highly advanced and human-like conversational agents, such as ChatGPT and BERT, using algorithms like Natural Language Processing (NLP).
Marketing: Recommendation systems, a type of machine learning, have boosted the sales of companies by providing personalized suggestions.
Subscribe to my newsletter
Read articles from Ridwan Ibidunni directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ridwan Ibidunni
Ridwan Ibidunni
I'm a mathematician that loves its applications in all spheres of life, especially in the field of machine learning. I write Java, Python and Android applications