A Step-by-Step Guide to Running anythingLLM Using Ollama on Your Local Machine as a Private LLM
 Asif Ahmed
Asif AhmedIntroduction:
In the world of natural language processing (NLP), large language models (LLMs) have been gaining significant attention due to their ability to generate human-like text. However, using cloud-based LLMs can come with its own set of challenges such as privacy concerns and latency issues. This is where Ollama comes in – an open-source tool that allows you to run private LLMs on your local machine. In this blog post, we will walk you through the steps to run AnythingLLM as a private LLM using Ollama on your local machine.
Context:
Ollama is a powerful and flexible tool designed to help users train and run their own LLMs locally. It supports various architectures such as BERT, DistilBERT, RoBERTa, and many more. By running LLMs locally, you have full control over your data, and you don’t need to worry about privacy concerns or latency issues associated with cloud-based solutions.
Benefits of Running Private LLM with Ollama:
Data Privacy: You can keep your data local, ensuring that it remains confidential and secure.
Faster Inference: Running models locally is faster than sending requests to cloud services, which can lead to significant time savings.
Customization: With Ollama, you have the flexibility to customize your LLM according to your specific use case.
Prerequisites:
Get up and running with large language models, locally. To use Ollama, follow these steps:
a. Download and install the Ollama link: https://ollama.com/download/Ollama-darwin.zip
b. Unizip and move the Ollama app to application folder
c. Quickstart
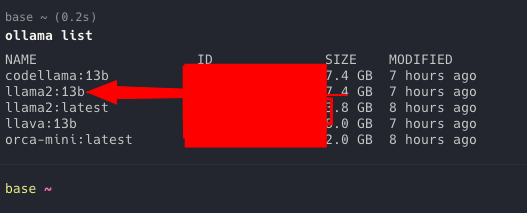
ollama run llama2:13bollama run codellama:13bollama run llava:13bollama serve - To check which port its runnig as-wellollama list - to check the list
Subscribe to my newsletter
Read articles from Asif Ahmed directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by