Crafting a Basic Data Pipeline with Airflow.
 Victor Nduti
Victor Nduti
From setup to mastery: A Guide to Crafting Your Inaugural DAG
In a previous blog post, we explored the fundamental concepts of Apache Airflow—a versatile workflow management platform that empowers users to orchestrate complex data pipelines with ease. If you haven't had the chance to delve into the world of Airflow yet, I highly recommend checking out my earlier guide on setting up Airflow locally using Docker Compose.
Now that we've laid the foundation, let's take the next step in our Airflow journey. In this blog, we'll dive into the practical aspect of creating your first Directed Acyclic Graph (DAG). Think of DAGs as the blueprints for your workflows, guiding the execution of tasks and managing dependencies between them.
As we proceed, we'll build upon the groundwork established in the previous tutorial. Assuming you've successfully set up Airflow on your local machine, with the necessary directories such as dags, plugins, and config, it's time to breathe life into our workflows.
Our journey begins with understanding the key components of a DAG, initializing it, and defining tasks that make up the steps of our workflow. Let's explore each of these elements in detail, paving the way for you to harness the full power of Airflow in orchestrating your data pipelines.
A peep into DAG components
Before diving into the code, let's take a look at some of a DAG components.
DAG (Directed Acyclic Graph): Picture it as the roadmap for your workflow. It outlines a series of tasks and their relationships, ensuring a clear, organized flow of operations.
Tasks: These are the individual units of work within a DAG. Each task represents a specific operation or computation, forming the backbone of your workflow.
Operators: Operators define the logic of a task. Airflow offers a variety of built-in operators (such as PythonOperator and BashOperator) to execute different types of tasks.
Dependencies: The relationships between tasks. You can set tasks to depend on the completion of others, allowing for precise control over the execution sequence.
Setting the stage
We will proceed to implement a process that involves scraping data from a website and subsequently saving it to a CSV file.
Importing Necessary Libraries
from airflow import DAG: This imports the Directed Acyclic Graph (DAG) class from the Apache Airflow library. DAG is the core component in Airflow that represents a workflow.from airflow.operators.python_operator import PythonOperator: This imports thePythonOperatorclass, which allows you to define a task in a DAG that executes a Python callable.from bs4 import BeautifulSoup: This imports theBeautifulSoupclass from thebs4(Beautiful Soup) library. Beautiful Soup is a Python library for pulling data out of HTML and XML files.import requests: This imports therequestsmodule, which is a popular Python library for making HTTP requests. It is commonly used for fetching web pages and interacting with APIs.import pandas as pd: This imports thepandaslibrary and assigns it the aliaspd. Pandas is a powerful data manipulation and analysis library for Python.import os: This imports theosmodule, which provides a way of using operating system-dependent functionality like reading or writing to the file system.from datetime import datetime, timedelta: This imports thedatetimeandtimedeltaclasses from thedatetimemodule. These classes are used to work with dates and times. In Airflow, they are often used to define the start date, schedule interval, and other time-related parameters in a
from airflow.operators.python_operator import PythonOperator
from bs4 import BeautifulSoup
import requests
import pandas as pd
import os
from datetime import datetime, timedelta
Setting our default arguments
'owner': 'nduti': Specifies the owner of the DAG. The owner is typically the person or team responsible for the DAG.'depends_on_past': False: Indicates whether the tasks in the DAG should depend on the success or failure of the previous run's instances. In this case, it's set toFalse, meaning the tasks won't depend on the past instances.'start_date': datetime(2023, 11, 11): Defines the start date of the DAG. The DAG will not run any instances before this date. In this example, the start date is set to November 11, 2023.'retries': 1: Specifies the number of times a task should be retried in case of a failure. If a task fails, it will be retried once.'retry_delay': timedelta(minutes=1): Determines the delay between retries for a failed task. In this case, it's set to 1 minute.
default_args = {
'owner': 'nduti',
'depends_on_past': False,
'start_date': datetime(2023, 11, 11),
'retries': 1,
'retry_delay': timedelta(minutes=1),
}
Initializing the dag instance
'scrape_and_save_to_csv': The first argument is thedag_id, which is a unique identifier for the Directed Acyclic Graph (DAG). It's a user-defined string that should be unique among all DAGs.default_args=default_args: This sets the default configuration parameters for the DAG. It refers to the dictionarydefault_argsthat you defined earlier, providing default values for various parameters like owner, start date, retries, etc.description='Scraping_with_airflow': This provides a human-readable description of the DAG. It's optional but helps in documenting the purpose or workflow of the DAG.schedule_interval=timedelta(days=1): Specifies the interval at which the DAG should run. In this case, the DAG is scheduled to run every day (timedelta(days=1)). This means that a new DAG run will be triggered once a day.
dag = DAG(
'scrape_n_save_to_csv',
default_args=default_args,
description='Scraping_with_airflow',
schedule_interval=timedelta(days=1),
)
Creating Python functions to be invoked during task definition. One will be responsible for web scraping, and the other will handle saving the data to a CSV file.
def scrape_quotes():
url = 'http://quotes.toscrape.com'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [quote.text.strip() for quote in soup.select('span.text')]
return quotes
else:
print(f"Failed to fetch quotes. Status code: {response.status_code}")
return []
def save_to_csv(quotes, **kwargs):
if not quotes:
print("No quotes to save.")
return
# Get the directory of the current DAG file
current_dag_directory = os.path.dirname(os.path.abspath(__file__))
# Specify the directory where you want to save the CSV file
output_directory = os.path.join(current_dag_directory, 'output')
# Create the output directory if it doesn't exist
os.makedirs(output_directory, exist_ok=True)
# Create a Pandas DataFrame
df = pd.DataFrame({'Quote': quotes})
# Save to CSV file in the specified output directory
csv_path = os.path.join(output_directory, 'quotes.csv')
df.to_csv(csv_path, index=False)
print(f"Quotes saved to {csv_path}.")
Task definition using a Python Operator
task_scrape_quotes Configuration:
task_id='scrape_quotes': Assigns a unique identifier to the task.python_callable=scrape_quotes: Specifies the Python callable (function) that will be executed when the task runs. In this case, it's thescrape_quotesfunction.dag=dag: Associates the task with the DAG (dag) to which it belongs.
task_scrape_quotes = PythonOperator(
task_id='scrape_quotes',
python_callable=scrape_quotes,
dag=dag,
)
task_save_to_csv Configuration:
task_id='save_to_csv': Assigns a unique identifier to the task.python_callable=save_to_csv: Specifies the Python callable (function) that will be executed when the task runs. In this case, it's thesave_to_csvfunction.op_args=[task_scrape_quotes.output]: Specifies the positional arguments to be passed to thesave_to_csvfunction. It attempts to pass the output of thetask_scrape_quotestask as an argument. However, note thatPythonOperatordoesn't inherently support passing outputs between tasks.provide_context=True: Enables the passing of additional context (like task instance details) to the callable. It's set toTrueto enable context passing.dag=dag: Associates the task with the DAG (dag) to which it belongs.
task_save_to_csv = PythonOperator(
task_id='save_to_csv',
python_callable=save_to_csv,
op_args=[task_scrape_quotes.output], # Pass the output of the first task as an argument
provide_context=True, # This allows passing parameters between tasks
dag=dag,
)
Creating tasks dependency
Defines that task_save_to_csv depends on the successful completion of task_scrape_quotes
task_scrape_quotes >> task_save_to_csv
Ensure that you save your DAG file in your integrated development environment (IDE).
Navigate to the Airflow user interface by entering localhost:8080 (or the specific port you used in your Docker Compose file) in your web browser.

Upon accessing the Airflow web interface, follow these steps:
- Search for your DAG with the name you assigned to it.
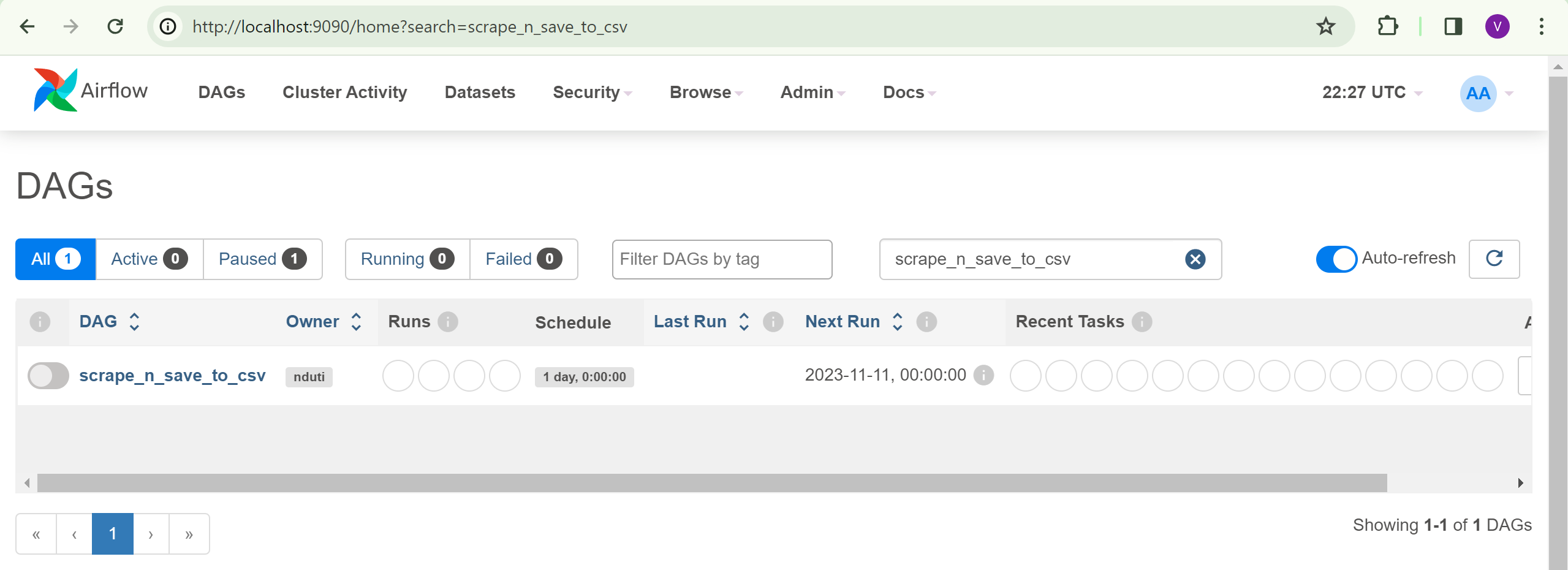
- Manually trigger the DAG to run for testing purposes.
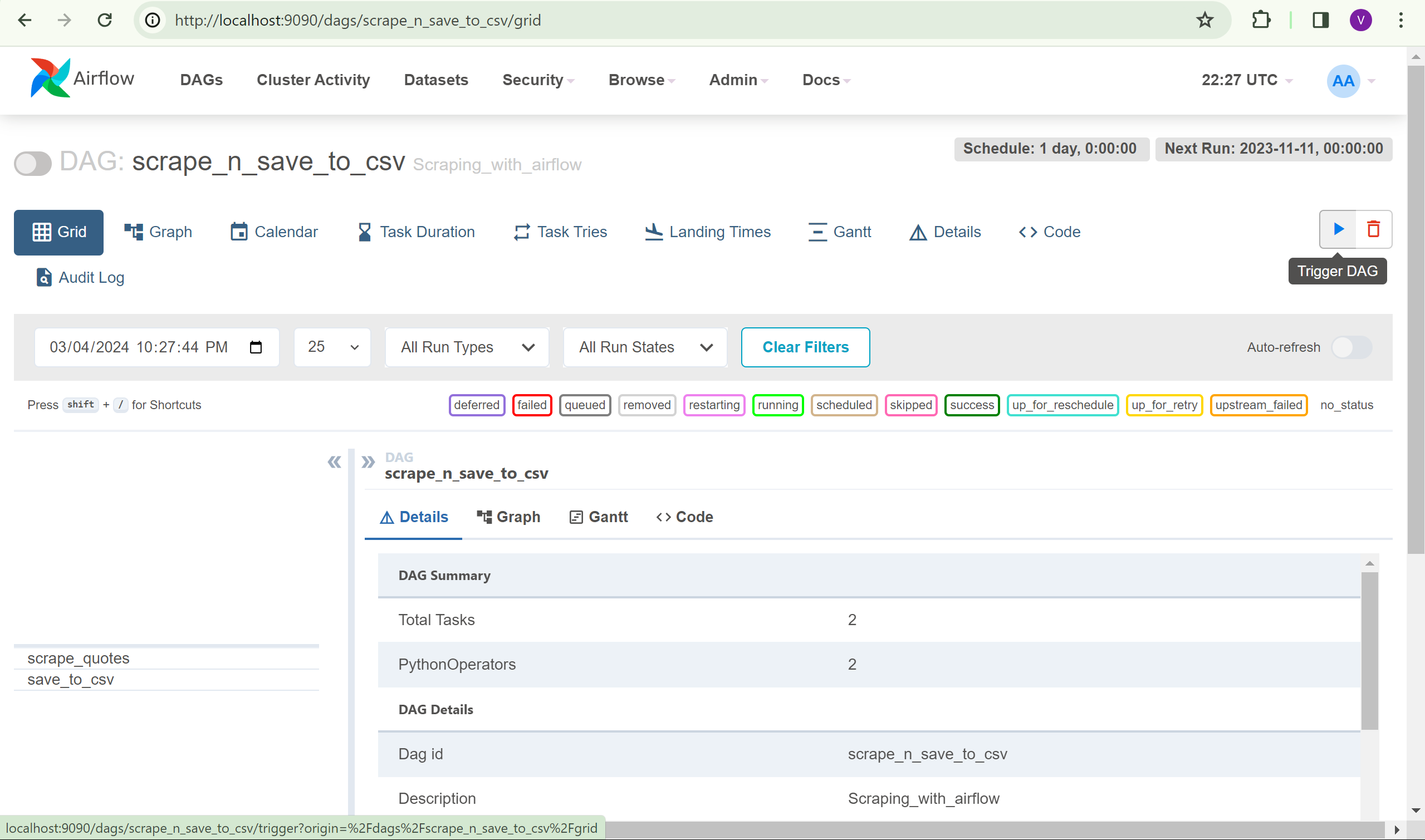
- Observe the DAG's progress as it runs; the colors of the bars indicate its current state.
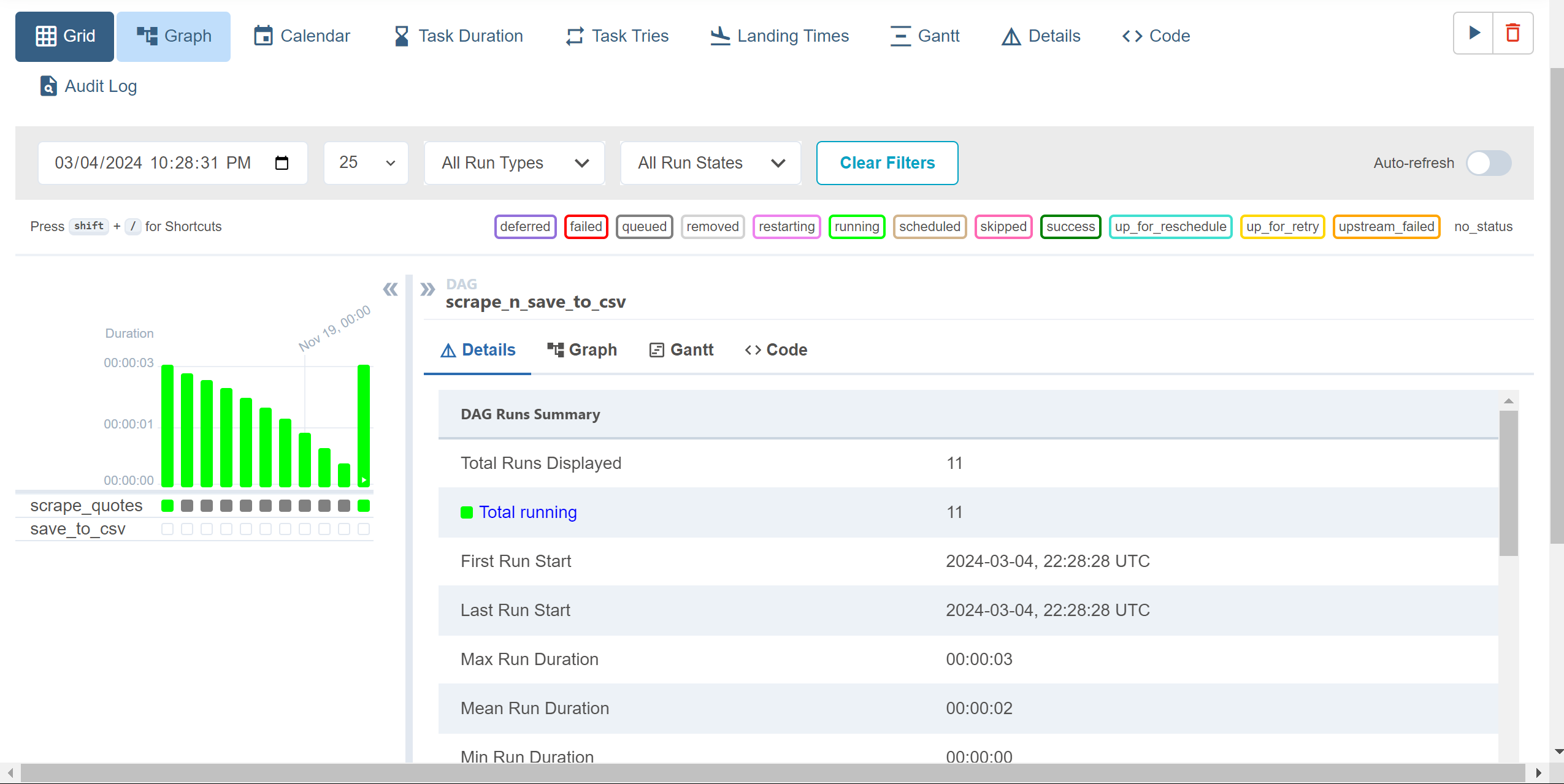
- Utilize the Graph view for insights into each task's status and to visualize task dependencies
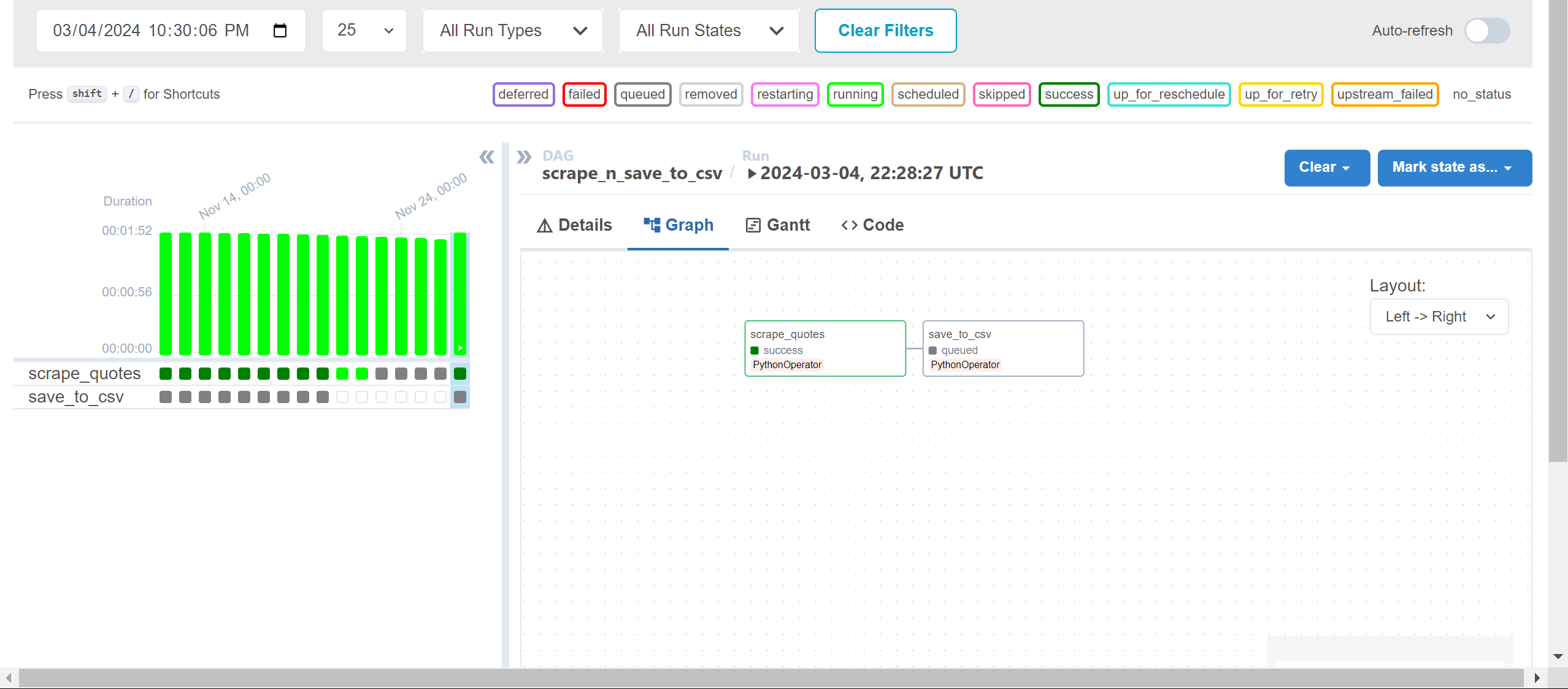
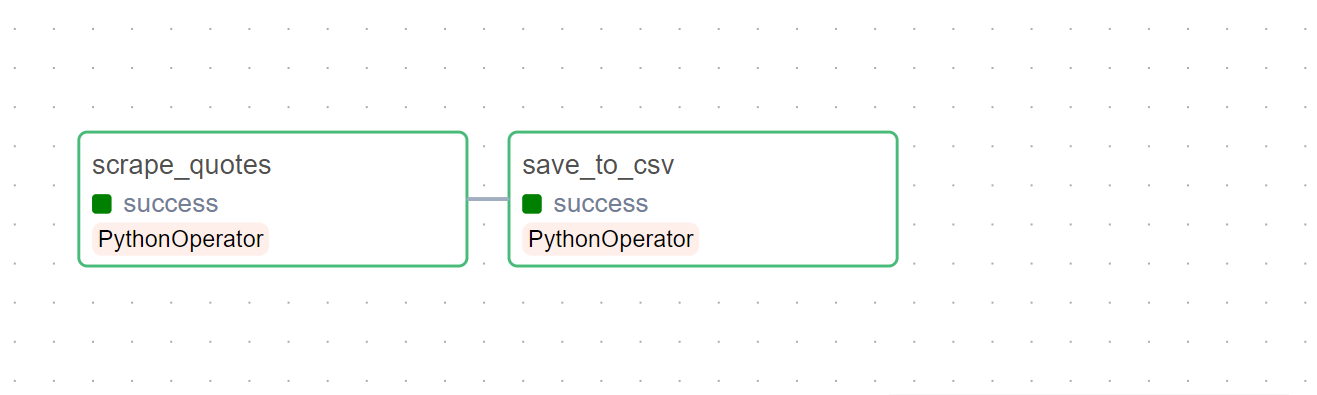
In the Graph view, the successful completion of both tasks will be visually represented as below:
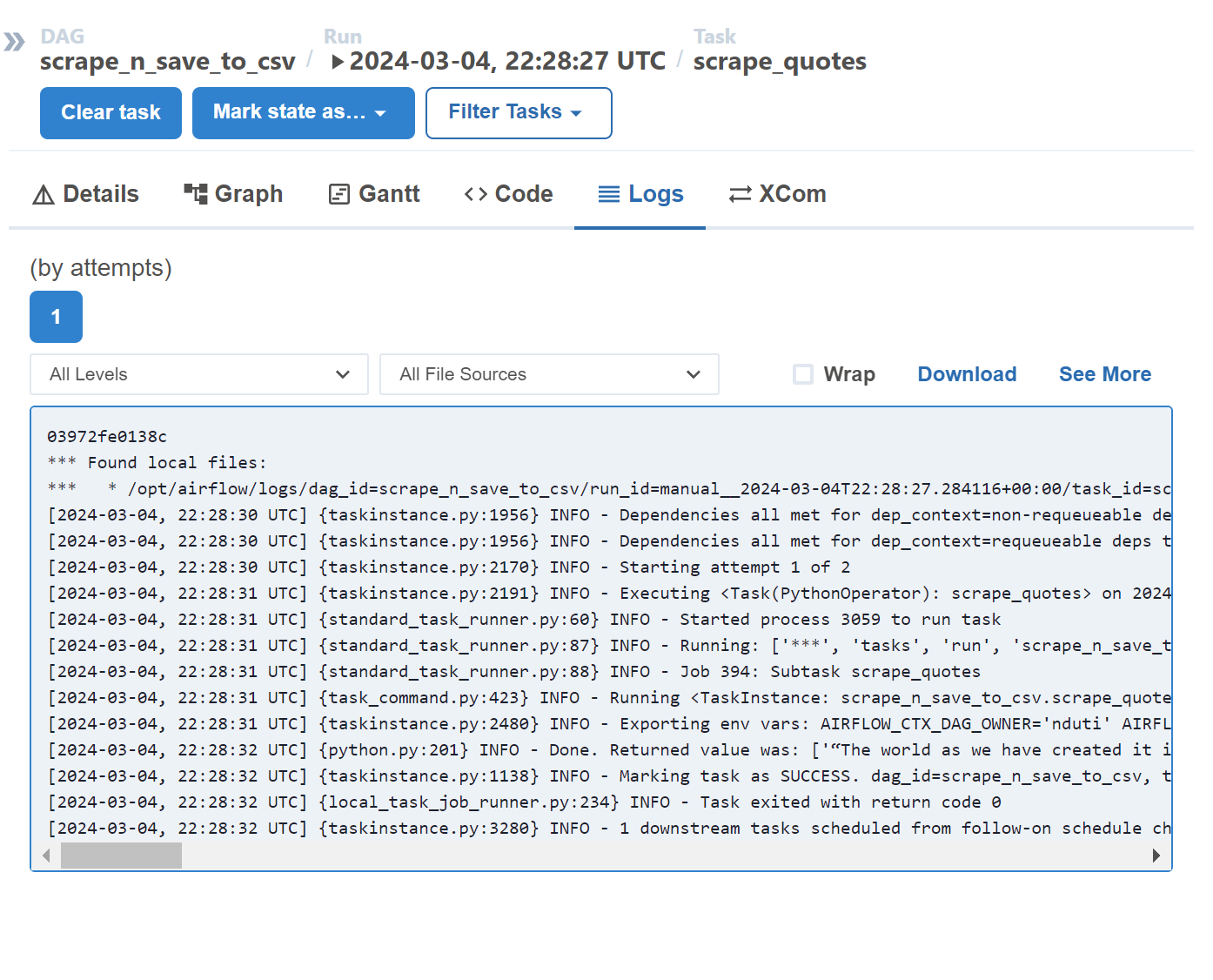
Feel free to inspect the logs of individual tasks within the Airflow UI.
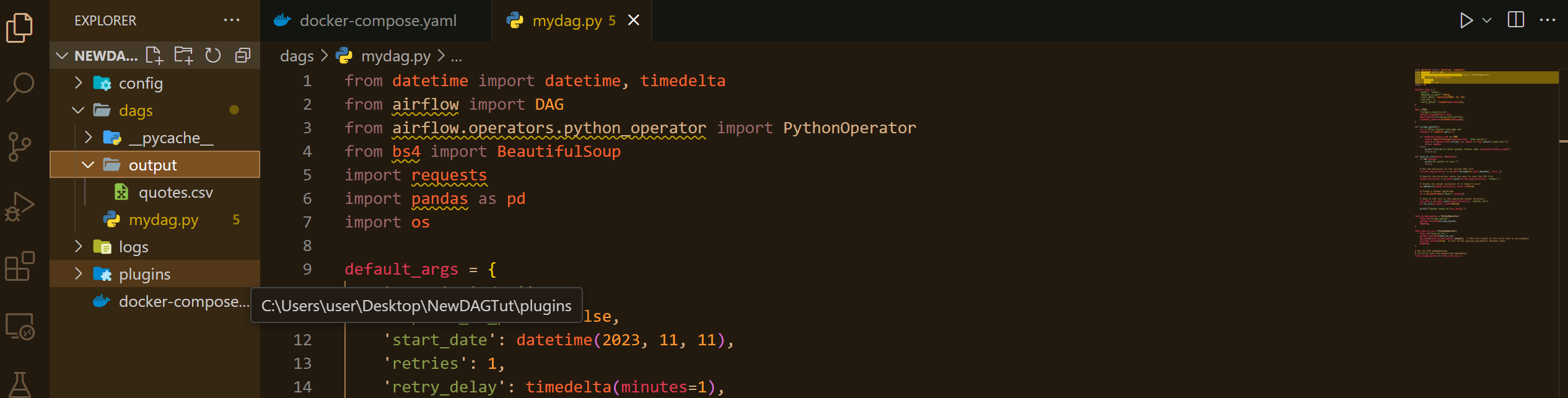
A quick check in your IDE should confirm the creation of a new 'output' folder, containing a CSV file named 'quotes.csv' that holds the scraped data.
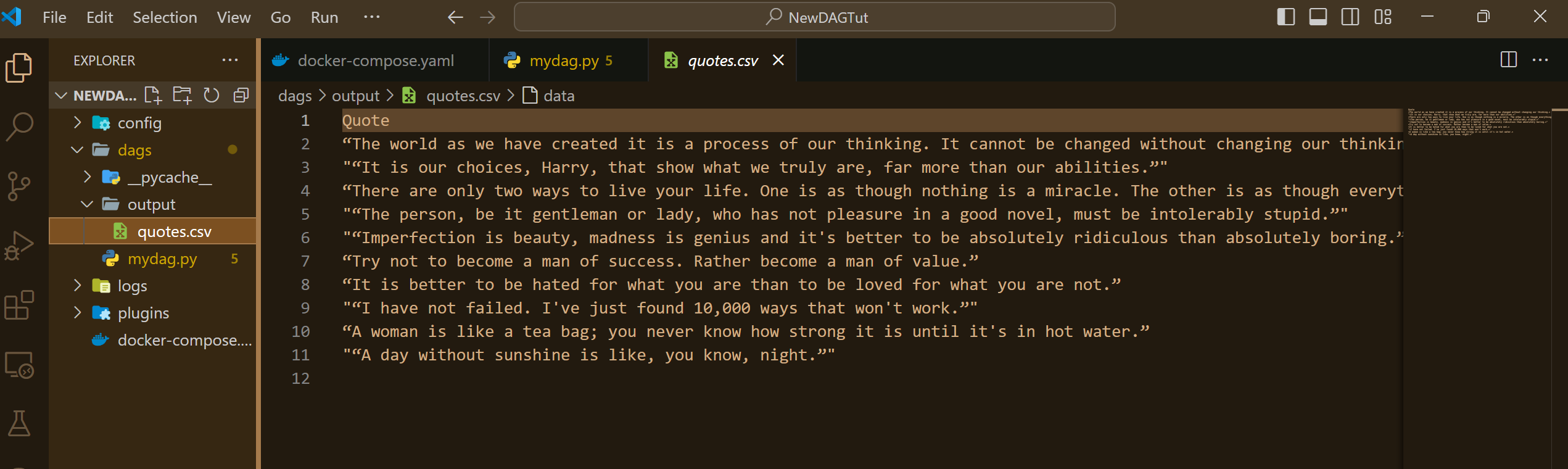
Voila! We've successfully orchestrated a simple pipeline. However, it doesn't end here. Keep exploring the vast capabilities of Airflow, experiment with different operators to enhance your ability.
Happy orchestrating!!!
Additional Links
- Airflow Documentation ; https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/dags.html
Subscribe to my newsletter
Read articles from Victor Nduti directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Victor Nduti
Victor Nduti
Data enthusiast. Curious about all things data.