The Odia Dataset
 Saswat Samal
Saswat Samal

Odia, a language predominantly spoken in the Indian state of Odisha, boasts a unique script that adds to its cultural richness. Recognizing the need for an efficient Odia number recognition system, this project harnesses the power of machine learning to automate and digitize tasks involving Odia text. The primary objective is to accurately interpret both handwritten and typed Odia characters, contributing to increased efficiency and productivity across diverse sectors, including education, science, and management.
The dataset's core motivation is to create a precise Optical Character Recognition (OCR) system tailored for the Odia language. While languages like English and Hindi often take the spotlight, focusing on Odia can bring about significant social changes. By enhancing accessibility, preserving cultural heritage, empowering education, fostering language technology, and driving economic growth in Odisha, the project aspires to make a lasting impact.
Existing Datasets
Progress and Challenges
While existing Odia OCR systems have made strides in recognizing printed text, challenges persist in handling handwritten text, low-quality images, and non-standard fonts. These challenges, not unique to Odia, find parallels in OCR systems for various languages. Insights from OCR technology in languages like Hindi and Bengali serve as a foundation but underscore the need for a specialized Odia OCR system.
Dataset Exploration
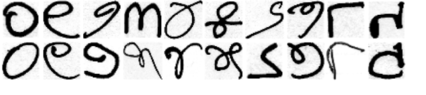
In the quest for a suitable dataset, the ISI Kolkata dataset (digits) revealed limitations, focusing solely on numerical data and exhibiting inconsistencies in image samples. Challenges included variations in class-wise sample counts and incorrect image formats. To surmount these issues, alternative datasets or additional data collection efforts are deemed necessary.
The Odia Character Dataset
The dataset creation involved multiple iterations, including traditional pen-and-paper collection. However, challenges like shadows and text bleed-through affected the dataset's quality. Subsequent adjustments, such as improved lighting and careful positioning, partially addressed these issues. Ultimately, a shift to a digital pen and a paint application yielded clear, diverse samples, overcoming previous challenges.
So using the help of digital medium and handwritten texts, we have created two datasets:
The Odia Characters Dataset
The Odia Digits Dataset
The Odia Characters Dataset
Visit kaggle.com/datasets/saswatsamal/odia-characters-dataset
The Odia Character Dataset is a curated collection of images that captures the diversity of handwritten characters from the Odia script, an important script used for writing the Odia language. With 47 distinct classes, each corresponding to a specific character in the Odia script, the dataset provides a comprehensive representation of the script's character set. This diversity ensures that the dataset is well-suited for various applications, particularly in the fields of character recognition, handwriting analysis, and machine learning model training.

Within each class, the dataset contains 5 images, resulting in a total of 235 images. This careful curation allows for robust model training and evaluation, as it offers multiple instances of each character for a more comprehensive understanding of the script's variability in handwriting styles. The images have been standardized to a resolution of 28x28 pixels, facilitating consistency in the dataset and making it compatible with a wide range of machine learning models and algorithms.
| Description | Count |
| Number of Classes | 47 |
| Number of Images in Each Class | 5 |
| Total Number of Images | 235 |
Overall, the Odia Character Dataset serves as a valuable resource, contributing to the advancement of character recognition technologies and fostering a deeper understanding of the intricacies of the Odia script within the realm of machine learning and artificial intelligence.
The Odia Digits Dataset
Visit: kaggle.com/datasets/saswatsamal/odia-digits-dataset
The Odia Digit Dataset is a purposefully curated collection of digital images tailored to the representation of numerical digits in the Odia script. With a focus on digits ranging from 0 to 9, this dataset is designed to facilitate tasks related to digit recognition, numerical analysis, and machine learning model training specific to the Odia script's numerical representation.
The Odia Digit Dataset comprises 10 distinct classes, each corresponding to one of the digits in the Odia script, with 5 images within each class, totaling 50 images. This intentional distribution ensures ample instances for each digit, fostering robust model training and accurate digit classification. To ensure uniformity and compatibility with diverse machine learning models, all images in the dataset are standardized to a resolution of 28x28 pixels.
| Description | Count |
| Number of Classes | 10 |
| Number of Images in Each Class | 5 |
| Total Number of Images | 50 |
Researchers, developers, and practitioners interested in the numerical aspects of the Odia script can leverage this dataset for tasks such as digit recognition, where the objective is to train models to accurately identify and classify handwritten Odia digits.
Conclusion
The Odia Dataset, comprising the Odia Characters Dataset and the Odia Digits Dataset, stands as a significant contribution to the advancement of character recognition technologies and machine learning applications in the context of the Odia script. With meticulous curation, these datasets offer a diverse and comprehensive representation of handwritten characters and digits, addressing challenges in existing Odia OCR systems.
Moreover, these datasets provide opportunities for enhanced precision in the interpretation of Odia characters by tackling issues related to handwritten writing and unconventional fonts, which could have implications for fields including science, education, and management. With technology still playing a vital role in maintaining linguistic diversity and making languages more accessible, the Odia dataset represents a major advancement in giving the Odia language more power in the fields of artificial intelligence and machine learning. Its accessibility to a broad audience is ensured by its availability on platforms such as Kaggle, which promotes innovation and collaboration in the field.
Credits
This dataset was created during the Senior Design Project, 8th Semester Major Project (2023), ITER (Siksha 'O' Anusandhan University) by Saswat Samal, Sanket Sanjeeb Pattanaik, Pratyasha Mohanty & Rupali Swain under the guidance of Dr. Sanjay Kumar Sonbhadra

Subscribe to my newsletter
Read articles from Saswat Samal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saswat Samal
Saswat Samal
I am Saswat Samal, currently contributing to Ernst & Young GDS India's Strategy and Transactions Service Line.