Streamlit Chatbot with LlamaIndex (I)
 Isabelle De Backer
Isabelle De Backer
Today, we are going to create a chatbot that answers queries about members of the Build Club, a community of passionate AI builders! Members provide general information about their current projects and start-up when they join, and also regular build updates that details the progress of their projects. There are already 550 of them and growing,
What you will learn in this post:
Store your data as vectors in Supabase [1]
Implementing Retrieval Augmented Generation with Llamaindex [2]
Setting up Supabase as a vector store
Implementing retrieval
Re-ranking the result
Generating an answer
Creating project on Supabase
First, create a free account on Supabase. Once you have logged in, you can create a new project by clicking on the "New Project" button. Give your project a name and choose a region for your database. Click on the "Create Project" button to create your project. For example, here's my BuildClub project on ap-southeast-2
Next you have to locate the database connection string. Go into you project settings at the bottom of the left sidebar:
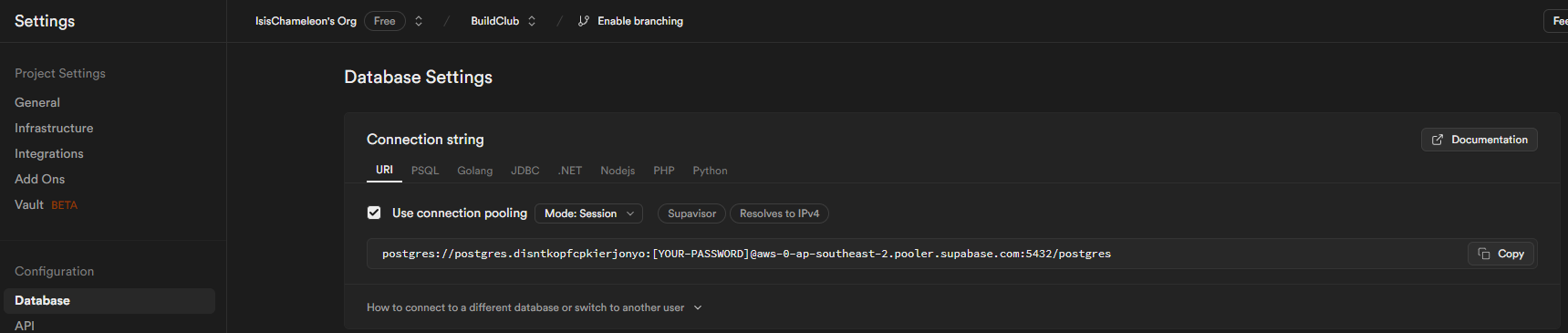
Select Database, and copy the string URI. You will have to save it in a .env file at the root of your project repository, replace the password holder with your real password, and finally ensure that the .env file is added to your .gitignore to avoid pushing your password to your repo.
For more information on how to setup the .env file and your development environment refer to this blog :https://isabelle.hashnode.dev/setup-a-development-environment-to-experiment-with-langchain.
Extracting the Members and Build Update data
(CustomAirtableReader class)
That data is on Airtable. pyairtable is a python library to interact with Airtable, provided you have the base id, table id and also a token that gives you at least read access to that table.
You can find the Airtable Base ID and Table ID in the Airtable website URL when viewing your data:

Base ID: The path in the URL that begins with
appTable ID: The path in the URL that begins with
tbl
To create a personal access token (PAT), refer to https://support.airtable.com/docs/creating-personal-access-tokens
CustomAirtableReader
In the code, I have created a class CustomAirtableReader whose job is to provide data from Airtable in various formats required for the application. We are going to extract semantic data (long text) from 2 tables: the Members table and the BuildUpdates table.
I setup the Airtable token, base and table ids in the constructor of this class.
class CustomAirtableReader(BaseReader):
"""Airtable reader. Reads data from a table in a base.
Args:
api_key (str): Airtable API key.
"""
def __init__(self) -> None:
"""Initialize Airtable reader."""
self.api = Api(AIRTABLE_CONFIG['BuildBountyMembersGenAI']['TOKEN'])
self.base_id = AIRTABLE_CONFIG['BuildBountyMembersGenAI']['BASE']
self.member_table_id = AIRTABLE_CONFIG['BuildBountyMembersGenAI']['TABLE']
self.build_update_table_id = AIRTABLE_CONFIG['BuildBountyBuildUpdates']['TABLE']
The whole content of the table is loaded into _member_data and build_update_data.This is feasible because the tables are not too big.
def _load_member_data(self) -> List[dict]:
table = self.api.table(self.base_id, self.member_table_id)
self._member_data = table.all()
return self._member_data
What to do with this data?
Let's take the member table: there is information such as LinkedIn URL or list of skills that can be used like standard data in a table when searching for it. You can imagine doing a SQL query like "select member_name from members where linkedin_url = '<some_url>'", you don't need anything more sophisticated. But there are other columns that contain chunks of text, like the member project description or a build update: we can use keyword search with some degree of success, but we can also vectorise a.k.a. embed those chunks of texts to perform a semantic retrieval. In other words, given a query and its embedding vector, what are the vectors in our knowledge base that are close-by and therefore semantically related? (See introduction to RAG in my earlier post).
For the members, I'm going to make a mini-text for each member using the element of the members table. Then I will embed those texts.
'MEMBER DETAILS:\n'
'\n'
'Member name: John Smith \n'
'LinkedIn Url: Https://linkedin.com/john-smith\n'
"Skills: ['Go to market']\n"
'Build Project: Newsary (app.newsary.co) democratise PR for all stories worth '
'sharing while removing the painpoints of reading through 100s of irrelevant '
'pitches or overly promotionalpress releases for the media. I am not '
"technical but I'm looking for one the best AI technical co-founder to take "
"our MVP to its full potential and I'm learning coding (with a 22 months it's "
'a commitment) and I can help the other founders with their brand and media '
'strategy! \n'
'Past work: EzyCom is the one platform for SMEs and startups to rule all '
'their external communications. \n'
I'm using Llama_Index so I'm going to transform that into Document and Node objects, that are core abstractions within LlamaIndex.
A Document is a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database. A Node represents a “chunk” of a source Document, whether that is a text chunk, an image, or other. Similar to Documents, they contain metadata and relationship information with other nodes.
In our instance a Document is equal to a record in one of the Airtable table, Members or BuildUpdates, and since this data is not big, a Document will not be chunked up further, so each Document will become a Node. The node "text" property will contain the data to embed, the rest of the information will be added as a metadata dictionary that can be used to perform keyword search as well.
reader = CustomAirtableReader()
documents = reader._extract_member_documents()
Here for example we are showing one of the documents. A key point is that I keep the unique identifier from the record in Airtable (airtable_id) to be able to retrieve the original record from Airtable if I need to. This document does not yet have an embedding vector associated with it as you can see with embedding=None.
Document(
id_='777d57a8-e59d-4909-8444-3f3b03e6007c',
embedding=None,
metadata={
'airtable_id': 'rec1lbotPQyFcaTrP',
'skills': ['Go to market'],
'member_name': 'Marie Dowling ',
'linkedin_url': 'Https://linkedin.com/marie-dowling',
'referrer_name': 'N/A',
'keen_for_ai_meetup': True,
'accepted': False,
'record_type': 'build_club_members',
'location': ''},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={},
text="MEMBER DETAILS:\n\nMember name: John Smith \nLinkedIn Url: Https://linkedin.com/john-smith\nSkills: ['Go to market']\nBuild Project: Newsary (app.newsary.co) democratise PR for all stories worth sharing while removing the painpoints of reading through 100s of irrelevant pitches or overly promotionalpress releases for the media. I am not technical but I'm looking for one the best AI technical co-founder to take our MVP to its full potential and I'm learning coding (with a 22 months it's a commitment) and I can help the other founders with their brand and media strategy! \nPast work: EzyCom is the one platform for SMEs and startups to rule all their external communications. \n", start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n')
Also, I made the decision to mix the build updates with the member information in the same index, so I collect them in the same Documents collection.
def extract_documents_full(self) -> List[Document]:
documents = self._extract_member_documents()
documents.extend(self._extract_build_updates_documents())
return documents
In this particular application, there is no chunking: each member information mini-text and each build update is going to be a vector without further split. The nodes are therefore just a copy of the document.
def extract_nodes(self) -> List[BaseNode]:
documents = self.extract_documents_full()
nodes = [ TextNode(text=d.text, metadata=d.metadata) for d in documents]
for node in nodes:
record_id = node.metadata.get('airtable_id', '') #metadata['id'] should contain the id of the corresponding record in the airtable table
if record_id != '':
node.id_ = record_id
node.metadata['extracted_timestamp']=time.time()
return nodes
Embedding and Indexing
Now to the final part of the semantic retrieval preparation step: embed each of my chunks, and then store in Supabase. This is where the little effort I put in using Llama_Index nodes will pay off.
For that job of dealing with retrieval and query, I have set up a class called Indexer. There's 2 parts to this class: setting up the vector store with all our little embeddings, and doing the retrieval when querying that vector store (during the retrieval step of a RAG engine).
Let's focus on the part 1 which is to finalize our vector store.
The following code:
gets the nodes (i.e. structure the data ready for embedding and indexing)
defines the vector store as supabase (give the connection string, and give a name to your collection)
instantiates the Vector Store Index based on whatever is found in Supabase in that collection (there might be existing vectors and you just want to add some)
insert the nodes in the vector store using "insert_nodes"
def _buildVectorStoreIndex_supabase(self):
logging.log(logging.INFO, f'===BUILD VECTOR STORE INDEX insert nodes into supabase === members_and_build_updates')
nodes = self.reader.extract_nodes()
self.vector_store = SupabaseVectorStore(
postgres_connection_string=SUPABASE_CONNECTION_STRING,
collection_name='members_and_build_updates'
)
self.vectorstoreindex = VectorStoreIndex.from_vector_store(self.vector_store, use_async=True)
self.vectorstoreindex.insert_nodes(nodes)
return self.vectorstoreindex
You might ask what is the text embedding model here? By default it is OpenAI text embedding, but you can change it by passing it as a parameter to Vector Store Index or defining it in your Settings.(https://docs.llamaindex.ai/en/stable/module_guides/models/embeddings.html#concept)
For example, by updating the code above with these lines, I'm using the latest text embedding model text-embedding-3-small with dimension 1536 (https://openai.com/blog/new-embedding-models-and-api-updates)
Please note that you cannot mix and match text embeddings - so you have to redo all your embeddings if you change, and you have to use the same embedding for your query as well. Text embedding leaderboard is available here (https://huggingface.co/spaces/mteb/leaderboard)
embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimension=1536)
self.vectorstoreindex = VectorStoreIndex.from_vector_store(self.vector_store, use_async=True, embed_model=embed_model)
Ok, let's read all from our Airtable tables and then create the vector store with the embeddings of our carefully crafted nodes ;):
from modules.reader import CustomAirtableReader
from modules.indexer import Indexer
reader = CustomAirtableReader()
indexer = Indexer(reader)
vectorstore_index = indexer._buildVectorStoreIndex_supabase()
After this has run (it took less than 2 min to create a new vector store), let's have a look in Supabase, go to the Table Editor and then select the "vecs" schema:
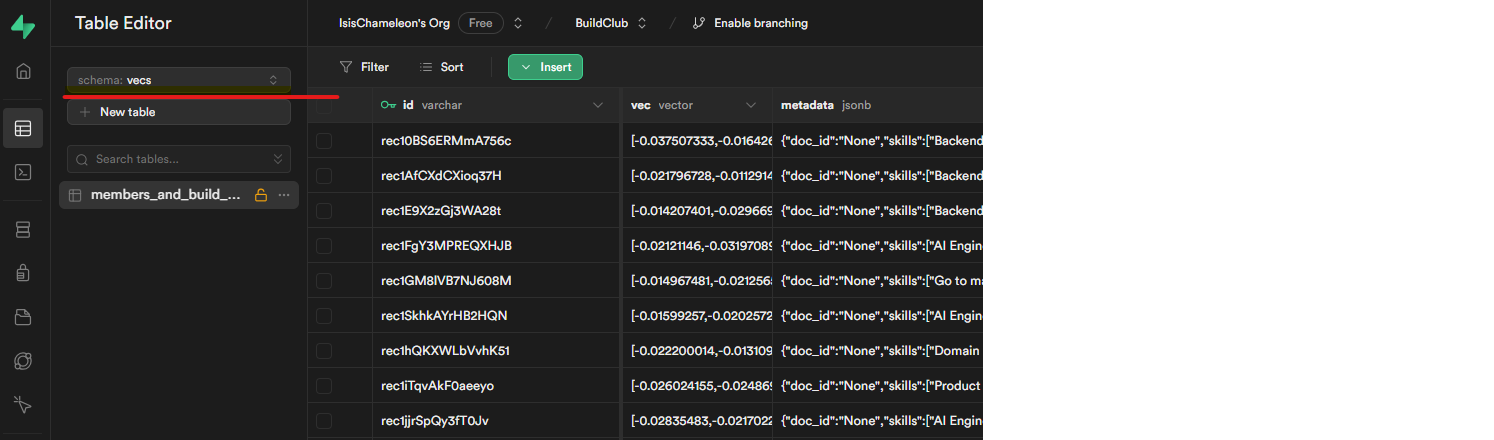
The collection members_and_build_updates has 3 columns: an id (which is also our node id, the airtable id of the original record), a vector (vec) and all the node metadata. The vector corresponds to the embedding of the metadata "_node_content". As you can see, Llama_Index has included all the metadata in the embedding (e.g. skills, linkedin_url, ...) but that is configurable in the Node properties.
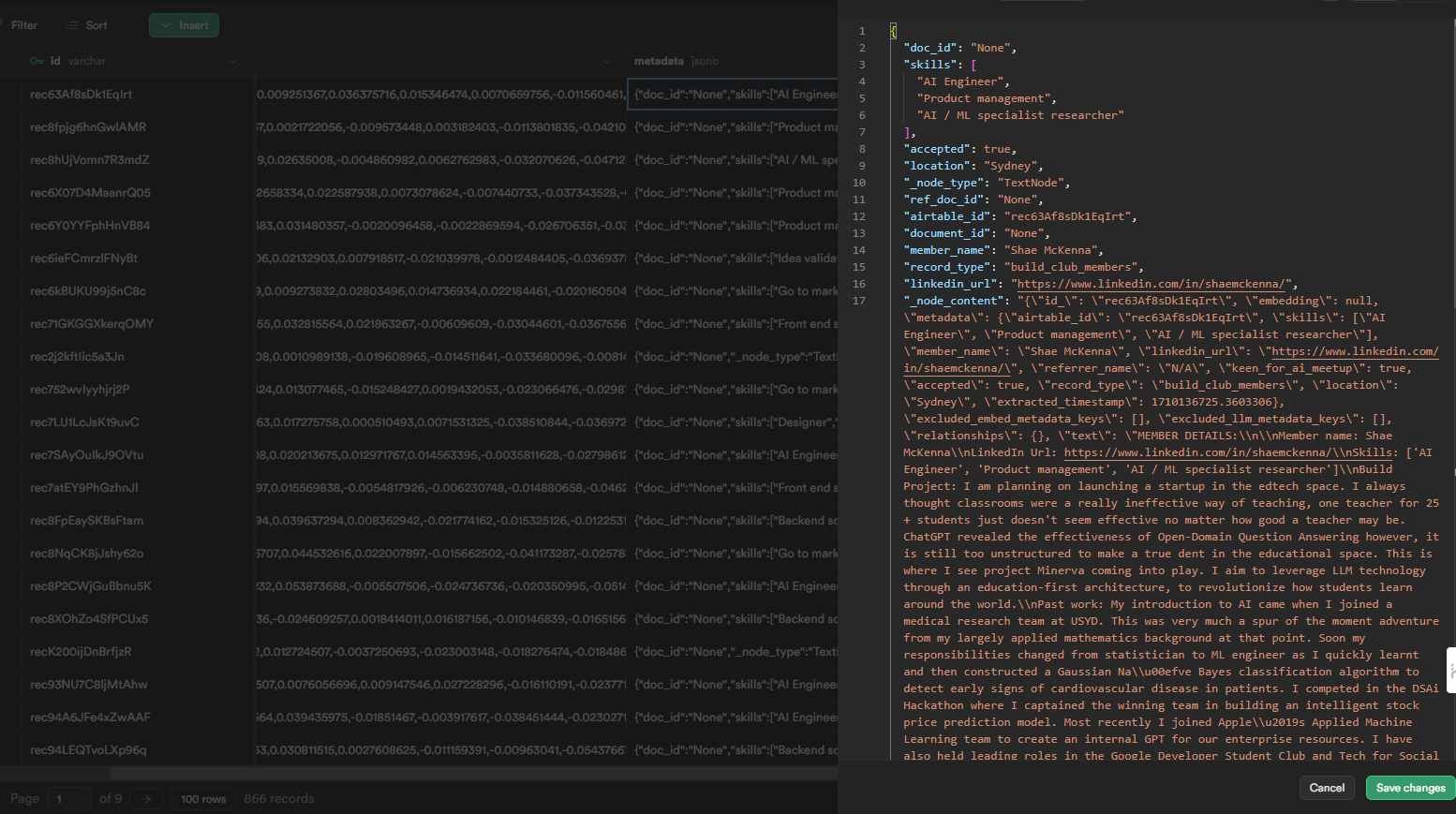
Querying data
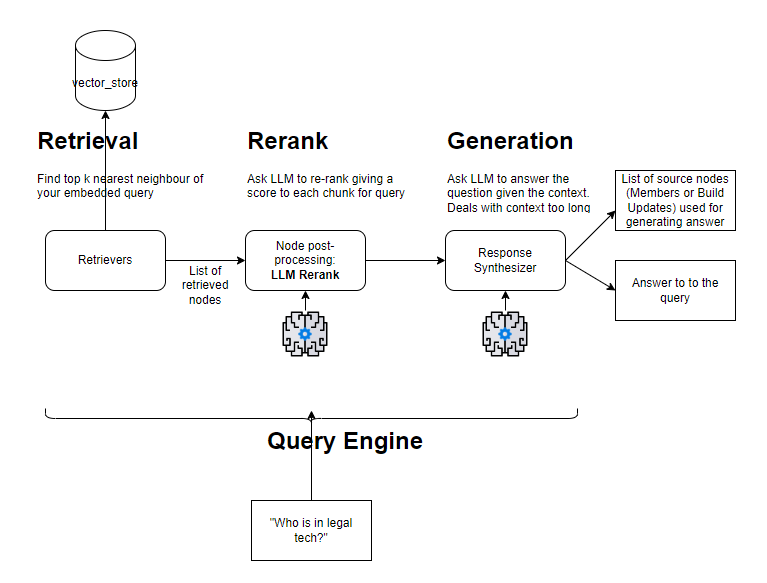
We create a query engine using LlamaIndex: it allows you to ask question over your data. A query engine takes in a natural language query, and returns a rich response. LlamaIndex is a flexible framework that allows you to configure your query engine pipeline, i.e. the steps you are taking from retrieval to answer generation. For this project, the query engine will follown the different steps illustrated below. First, a semantic search, then a re-ranking of the retrieved results (which may include elimination of irrelevant chunks), then generation including dealing with oversize information for the context by repetitive call to LLM. Once setup, a user query is submitted to the query engine, and after all steps have completed it returns an answer and the list of sources used for generating the answer.
def _getVectorStoreIndex_supabase(self):
self.vector_store = SupabaseVectorStore(
postgres_connection_string=SUPABASE_CONNECTION_STRING,
collection_name='members_and_build_updates'
)
logging.log(logging.INFO, f'===Get VectorStoreIndex from SUPABASE=== members_and_build_updates using openai text-embedding-3-small dim 1536')
self.vectorstoreindex = VectorStoreIndex.from_vector_store(self.vector_store, use_async=True, embed_model=embed_model)
return self.vectorstoreindex
@property
def semantic_query_engine(self):
if self.vectorstoreindex is None:
_ = self._getVectorStoreIndex_supabase()
llm = OpenAI(model="gpt-4", temperature=0)
node_postprocessor_2 = LLMRerank(llm=llm)
self._semantic_query_engine = self.vectorstoreindex.as_query_engine(
llm=llm,
# retriever kwargs
similarity_top_k=8,
# post processing
node_postprocessors=[node_postprocessor_2])
return self._semantic_query_engine
I have setup the query engine as a property of the Indexer class, that lazy loads the query engine. That property is "semantic_query_engine".
First, when required, it instantiates the vector store index with the Supabase vector store.
It sets up the LLM Rerank node post-processor (using GPT-4). LLM Reranking will simply take all the chunks retrieved and ask the LLM how relevant they are to the user query, and ask to give it a score from 1 to 10. Also if a chunk is irrelevant, the LLM is asked to chuck it away.
Finally, it creates the query engine based on the vector store index with a few parameters
1) The LLM used for generation (GPT-4 as well)
2) Some arguments for the retriever: top_k indicates to return the k nearest neighbours
3) Node postprocessors (processing of retrieved nodes prior to the generation step)
And that's it for the query engine!
Now we have already something that can return information about the build club members and their updates.
from modules.reader import CustomAirtableReader
from modules.indexer import Indexer
reader = CustomAirtableReader()
indexer = Indexer(reader)
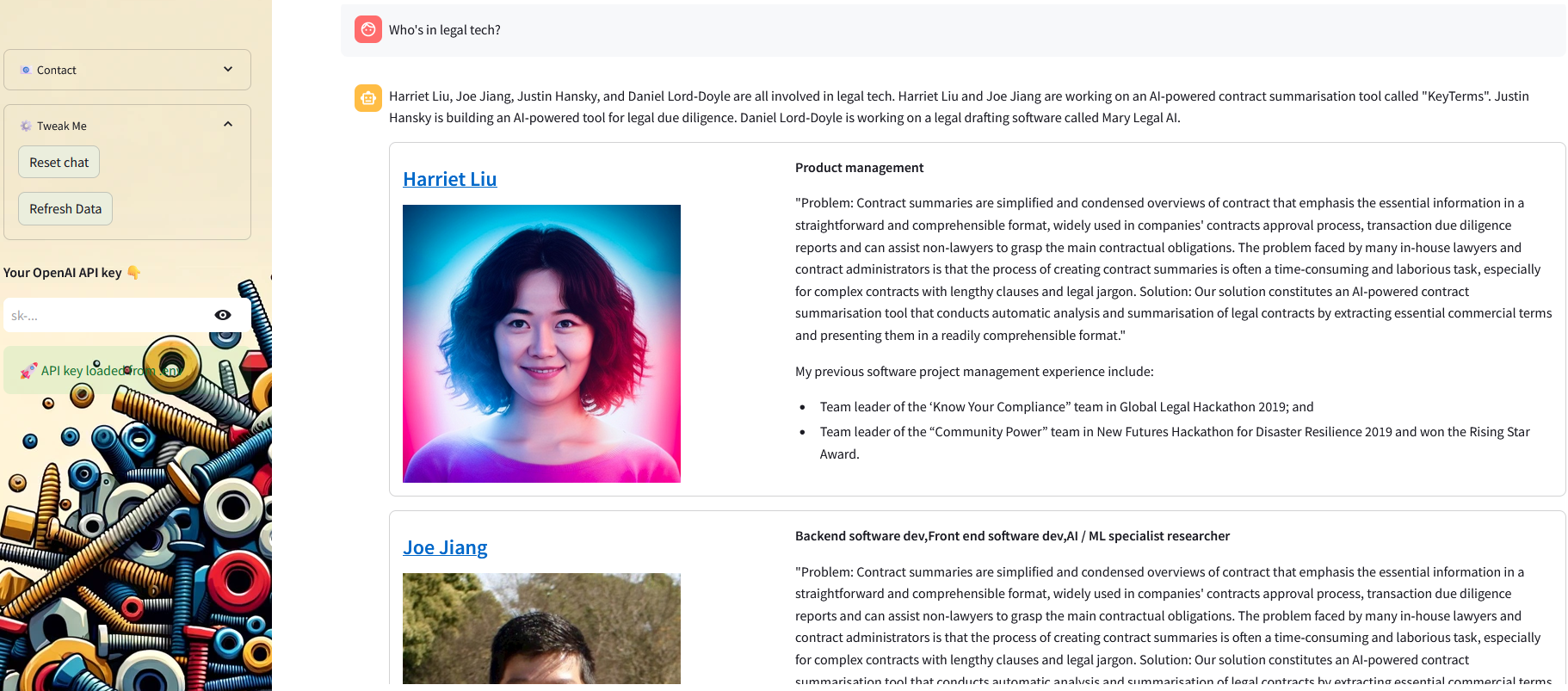
response = indexer.semantic_query_engine.query("Who's in legal tech?")
The response will get you 2 things:
The answer generated by the LLM
The list of nodes and their score (obtained in our case by LLM Rerank)
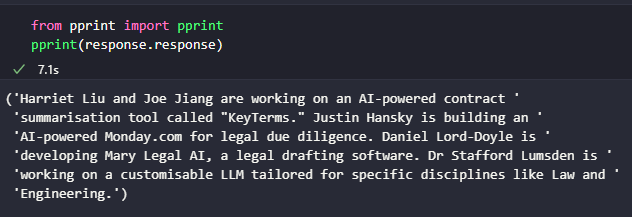
The list of nodes with score will be used to display the members and their information in the streamlit app that we will build in the next post.
References
[1] LlamaIndex https://docs.llamaindex.ai/en/latest/
[2] Supabase https://supabase.com/
[3] Airtable https://www.airtable.com/, https://support.airtable.com/docs/creating-personal-access-tokens
Subscribe to my newsletter
Read articles from Isabelle De Backer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by