Rock Vs Mine Prediction Using Machine Learning
 SHREYAS GANDHI
SHREYAS GANDHIIn this project, we're leveraging logistic regression for a specific task: predicting whether an object is a rock or a mine. This endeavor falls under supervised learning, meaning we have labeled data to train our model.
Throughout this process, maintaining a clear understanding of the problem domain and continuously validating the model against real-world data are crucial for success.
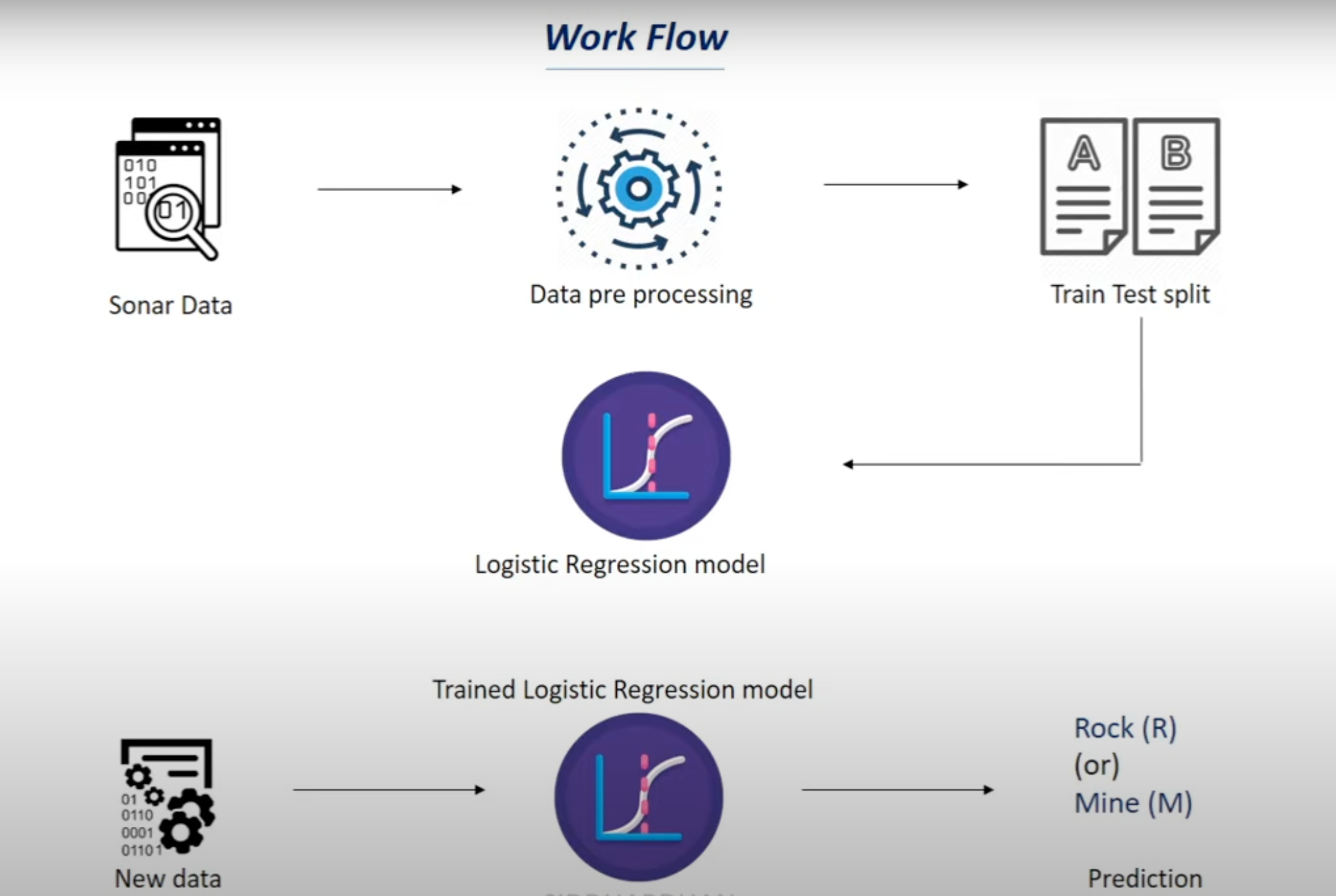
The workflow starts with checking for missing values in the dataset and then preprocessing it. After that, we dive into exploratory data analysis (EDA) to understand our data better and extract useful features for prediction.
Next, we split our data into training and testing sets. In the training phase, we apply logistic regression, which essentially draws a line through the data. On one side of this line are points representing rocks, and on the other side are points representing min
logistic regression is like drawing a line through a bunch of points on a graph to separate them into two groups. Imagine you have a bunch of dots on a piece of paper, some representing rocks and others representing mines. Logistic regression helps us draw a line on the paper in such a way that one side of the line mostly has rocks, and the other side mostly has mines.
Overall, the workflow involves data preprocessing, exploratory analysis, feature extraction, model training, and evaluation to develop a predictive model capable of identifying rocks and mines based on given data.
This is the sample code which predicts whether the object is Rock or Mine.
# Prediction system
input_data = (0.0453 ,0.0523 ,0.0843 ,0.0689 ,0.1183 ,0.2583 ,0.2156 ,0.3481, 0.3337, 0.2872, 0.4918, 0.6552 ,0.6919, 0.7797, 0.7464, 0.9444, 1.0000, 0.8874, 0.8024, 0.7818, 0.5212, 0.4052, 0.3957, 0.3914, 0.3250, 0.3200, 0.3271, 0.2767, 0.4423, 0.2028, 0.3788, 0.2947, 0.1984, 0.2341 ,0.1306, 0.4182, 0.3835, 0.1057, 0.1840, 0.1970 ,0.1674, 0.0583, 0.1401, 0.1628, 0.0621, 0.0203, 0.0530 ,0.0742, 0.0409, 0.0061, 0.0125, 0.0084, 0.0089, 0.0048, 0.0094, 0.0191, 0.0140 ,0.0049, 0.0052 ,0.0044)
# changing the input_data to numpy array
input_data_as_numpy_array = np.asarray(input_data)
input_data_reshape = input_data_as_numpy_array.reshape(1,-1)
prediction = model.predict(input_data_reshape)
print(prediction)
if(prediction[0] == 'R'):
print('The object is rock')
else:
print('The object is mine')py
Google Colab Link - https://colab.research.google.com/drive/1qhg0VnpJEoDiGGqFWHecglVJrqpu0O1o#scrollTo=aws7u-6NS45g
Subscribe to my newsletter
Read articles from SHREYAS GANDHI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by