Demystifying Consistent Hashing: A Comprehensive Guide
 Aditya Lad
Aditya Lad
What is Hashing ?
It is a technique to convert data into hash code using a hash function.
This hash code is used to uniquely identify the data or map it to a specific memory location.
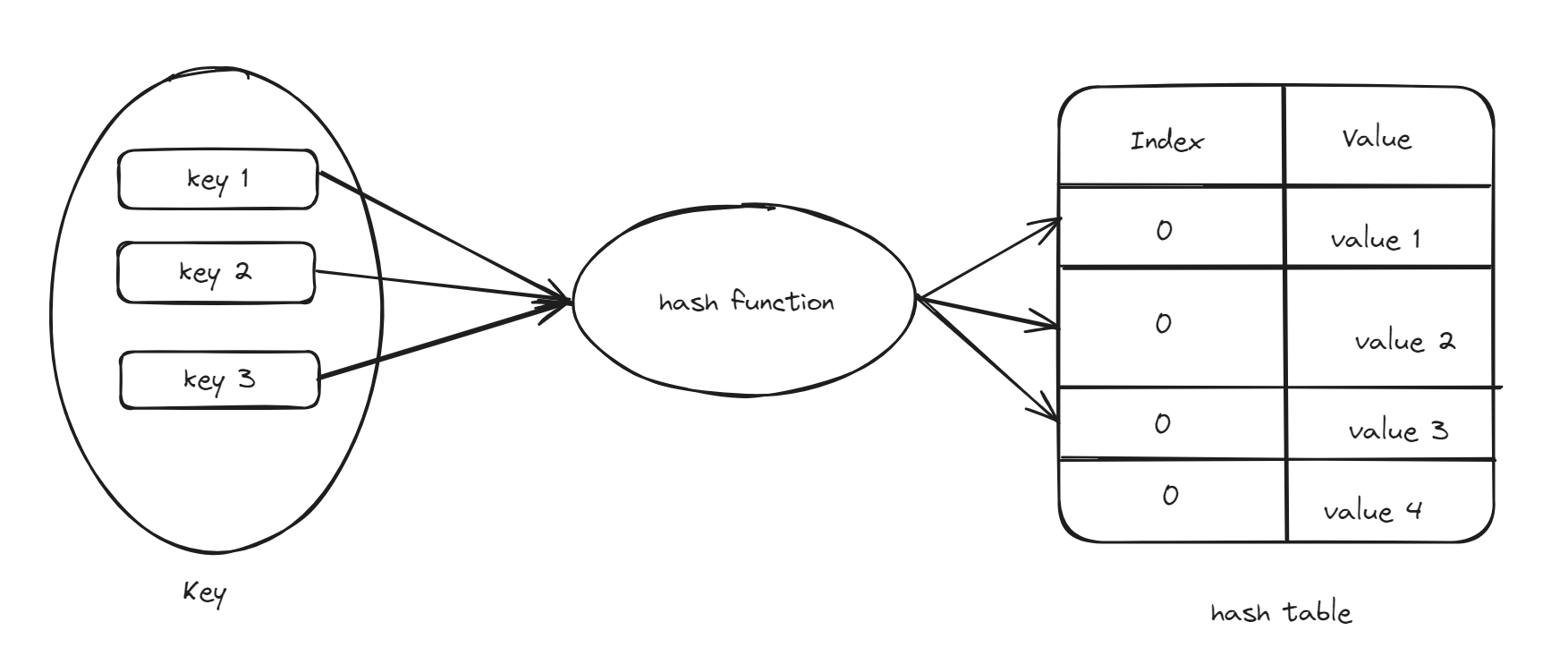
Why use Hashing ?
Efficient storage of data by converting complex data into fixed size hash codes.
Fast retrieval of data by mapping hashed values to specific memory locations.
Uniform distribution of data.
Data integrity:- If 2 hash codes are same, it indicates that data is identical.
Hashing in distributed System
In distributed systems, we need a method to evenly distribute the requests among available servers.
In naive hashing approach, mapping of keys to server nodes is directly dependent on number of nodes. When a node is added or removed from the system, the entire set of keys needs to be recalculated and redistributed among the remaining nodes.
Because of the use of simple rehashing, any change in the cluster size requires reshuffling all data.
This inefficiency makes simple rehashing impractical for large-scale distributed systems.
Consistent Hashing
This technique used in distributed systems to determine which server node should handle a particular request.
It involves representing both the server nodes and the requests on a virtual ring structure called a hash ring.
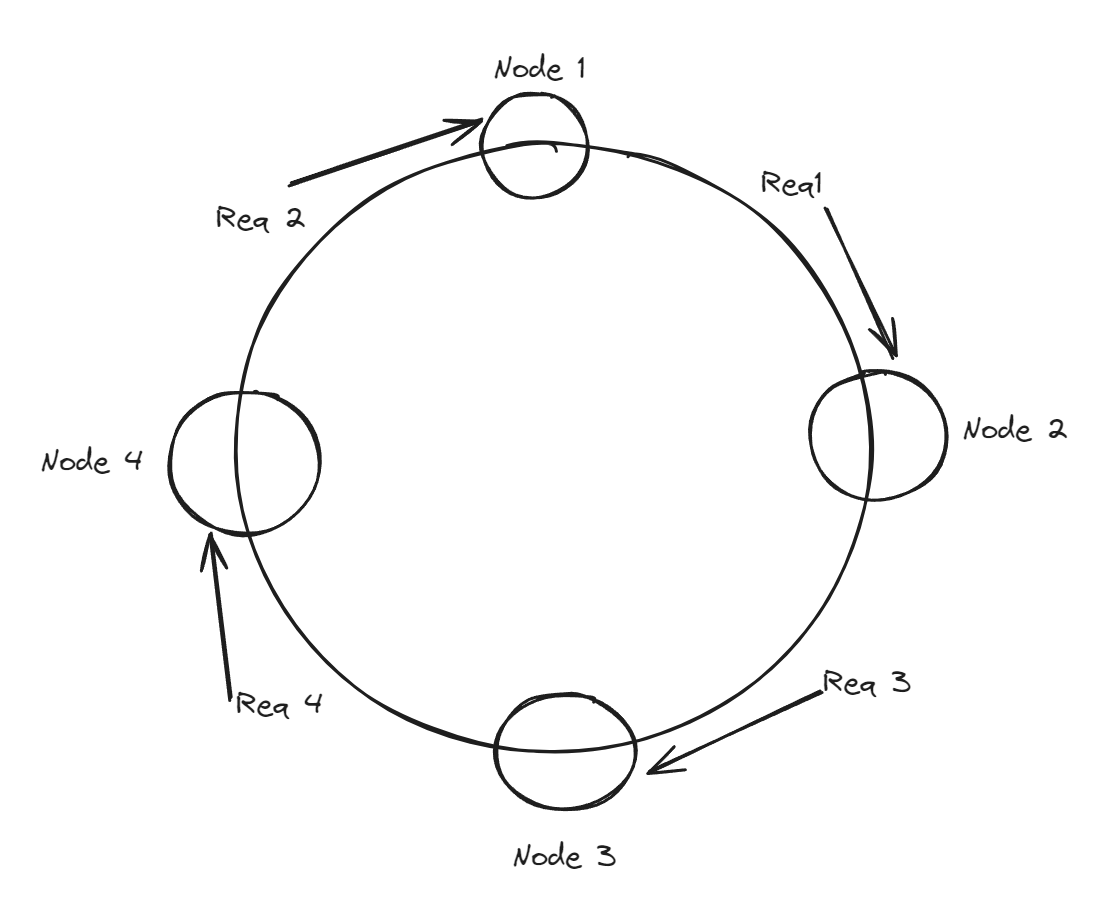
The ring is imagined to have an infinite number of points, and server nodes are placed at random locations on this ring using a hash function. Similarly, requests are also placed on the ring using the same hash function.
The decision about which server node serves a request is made based on the clockwise traversal of the ring. The request is assigned to the first server node encountered in this traversal whose address is greater than the address of the request.
Each server node effectively "owns" a range of the hash ring, and any requests falling within this range will be served by that node.
This approach minimizes the need for data reshuffling when the cluster size changes, making it more scalable and efficient compared to naive hashing techniques.
If one of the server nodes fails, the range of the next node widens and any request coming in all of this range goes to the new server node.
Implementing Consistent Hashing
#include <iostream>
#include <map>
#include <string>
#include <vector>
struct Node {
std::string name;
std::vector<int> hashes;
};
// Add a node to the hash ring
void addNode(std::map<int, Node*>& hashRing, Node* newNode) {
for (int hash : newNode->hashes) {
hashRing[hash] = newNode;
}
}
// Get the node responsible for a given key
Node* getNodeForKey(const std::map<int, Node*>& hashRing, int key) {
auto it = hashRing.lower_bound(key);
if (it == hashRing.end()) {
it = hashRing.begin();
}
return it->second;
}
// Remove a node from the hash ring
void removeNode(std::map<int, Node*>& hashRing, Node* nodeToRemove) {
for (auto it = hashRing.begin(); it != hashRing.end(); ) {
if (it->second == nodeToRemove) {
it = hashRing.erase(it);
} else {
++it;
}
}
}
int main() {
// Create initial nodes
Node nodeA{"Node A", {10, 20}};
Node nodeB{"Node B", {30, 40}};
// Create hash ring
std::map<int, Node*> hashRing;
// Add initial nodes to the hash ring
addNode(hashRing, &nodeA);
addNode(hashRing, &nodeB);
// Get node responsible for a given key
Node* responsibleNode = getNodeForKey(hashRing, 15);
std::cout << "Key 15 is mapped to: " << responsibleNode->name << std::endl;
responsibleNode = getNodeForKey(hashRing, 35);
std::cout << "Key 35 is mapped to: " << responsibleNode->name << std::endl;
// Add a new node
Node nodeC{"Node C", {50, 60}};
addNode(hashRing, &nodeC);
// Get node responsible for a new key
responsibleNode = getNodeForKey(hashRing, 55);
std::cout << "Key 55 is mapped to: " << responsibleNode->name << std::endl;
// Remove a node
removeNode(hashRing, &nodeB);
// Get node responsible for a key after node removal
responsibleNode = getNodeForKey(hashRing, 35);
std::cout << "Key 35 is now mapped to: " << responsibleNode->name << std::endl;
return 0;
}
Key 15 is mapped to: Node A
Key 35 is mapped to: Node B
Key 55 is mapped to: Node C
Key 35 is now mapped to: Node C
Subscribe to my newsletter
Read articles from Aditya Lad directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by