Scrape Wikipedia in Python - Ultimate Tutorial
 Crawlbase
Crawlbase
This blog is originally posted to the crawlbase blog.
In this guide, we’ll be scraping Wikipedia, the Internet’s largest encyclopedia. Whether you’re an academic researcher, content creator, data scientist, or simply curious about how to build a Wikipedia scraper, this tutorial is for you.
We’ll provide you with step-by-step instructions on how to extract data from Wikipedia using Python, a popular programming language known for its simplicity and versatility. Additionally, we’ll introduce you to Crawlbase’s Crawling API, a powerful tool that streamlines the scraping process and makes it even more efficient.
By the end of this tutorial, you’ll have the skills and knowledge to extract wikipedia and gather information from its articles with ease for all sorts of projects. Let’s begin.
Table of Contents
I. What are the Best Ways to Scrape Data from Wikipedia?
V. How to Extract HTML from Wikipedia
Step 1: Importing the Crawlbase Library
Step 2: Defining the crChoosing an Endpointawl Function
Step 3: Initializing the CrawlingAPI Object
Step 4: Making a GET Request
Step 5: Checking the Response Status Code
Step 6: Extracting and Printing the HTML Content
Step 7: Handling Errors
Step 8: Main Function
Step 9: Specifying Wikipedia Page URL and API Token
Step 10: Calling the crawl Function
Step 1: Importing Libraries
Step 2: Initializing the Crawling API
Step 3: Scraping the Wikipedia Page Title
Step 4: Scraping Nickname property
Step 5: Scraping Citizenship property
Step 6: Scraping Image
Step 7: Scraping Profile Title
Step 8: Complete the Code
VII. How to Scrape a Table from Wikipedia
Step 1: Importing Libraries
Step 2: Scraping Table from Wikipedia pages
Step 3: Initializing the Crawling API
Step 4: Execute the Code to Save in CSV file
IX. Frequently Asked Questions
I. What are the Best Ways to Extract Wikipedia?
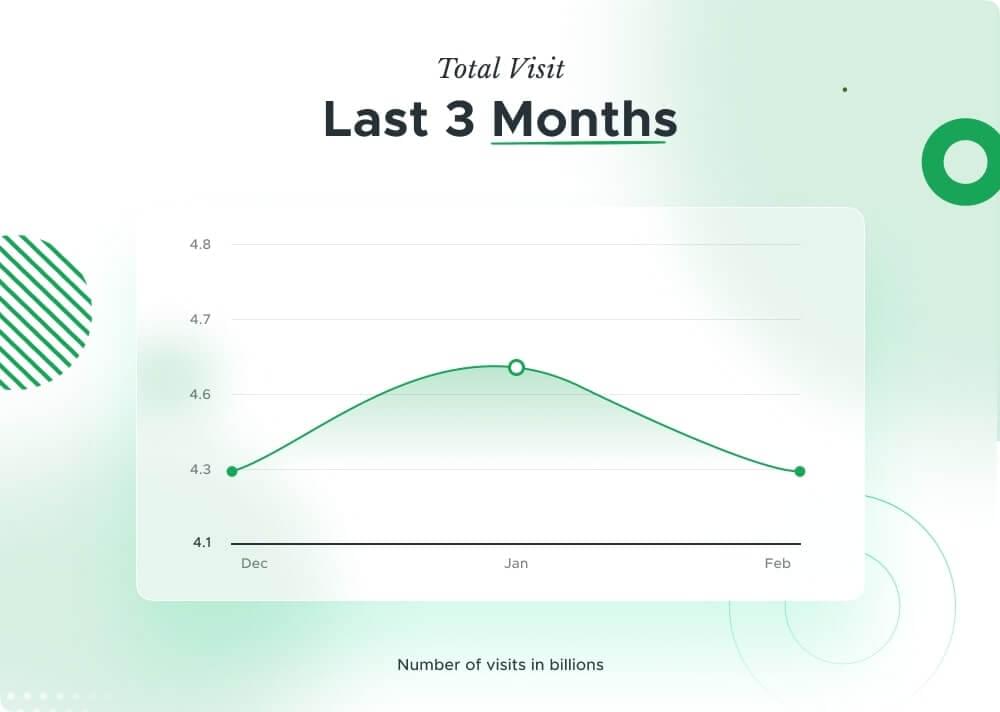
Wikipedia, founded in 2001, is a free online encyclopedia maintained by volunteers globally. With close to 4.3 billion unique global visitors in December 2023, it serves as a vital resource for information on diverse topics. Operated by the Wikimedia Foundation, Wikipedia allows open collaboration and democratized knowledge-sharing, making it an important platform for users worldwide.
Wikipedia scraping can be achieved through various methods, each with its own advantages. Here are some effective approaches:
APIs: Wikipedia provides a MediaWiki API, allowing programmatically access to a vast amount of Wikipedia content. While this API allows for retrieving specific datasets, it may have its limitations. In this tutorial, we will explore another type of API, the Crawling API, which promises greater efficiency and flexibility in data extraction.
Web Scraping: Using libraries like BeautifulSoup (for Python), Scrapy, or Cheerio (for Node.js) you can scrape Wikipedia pages directly. Be cautious to comply with Wikipedia’s robots.txt file and avoid overloading their servers with excessive requests. Later in this blog, we will combine BeautifulSoup with the Crawling API to achieve the most effective way to scrape Wikipedia pages.
Database Dumps: Wikipedia periodically releases complete database dumps containing the entirety of its content. Although these dumps can be large and require specialized software for parsing, they offer comprehensive access to Wikipedia data.
Third-Party Datasets: There are third-party datasets available that have already extracted and formatted data from Wikipedia. These datasets can be beneficial for specific use cases, but it’s essential to verify their accuracy and reliability.
When utilizing scraped data, it’s important to attribute the source appropriately. Additionally, consider the impact of your scraping activities on Wikipedia’s servers and ensure compliance with their usage policies.
II. Project Scope
Our aim in this tutorial is to develop a Python-based wikipedia scraper to extract data from Wikipedia pages. Our project scope includes utilizing the BeautifulSoup library for HTML parsing and integrating the Crawlbase Crawling API for efficient data extraction. We’ll cover scraping various elements such as page titles, nicknames, citizenship details, images, profile titles, and tabular data from Wikipedia pages.
The key components of this project include:
- HTML crawling: We’ll utilize Python with Crawlbase Crawling API to extract the complete HTML content from Wikipedia pages, ensuring efficient data retrieval while respecting Wikipedia’s usage policies.
We will be targeting this URL for this project.
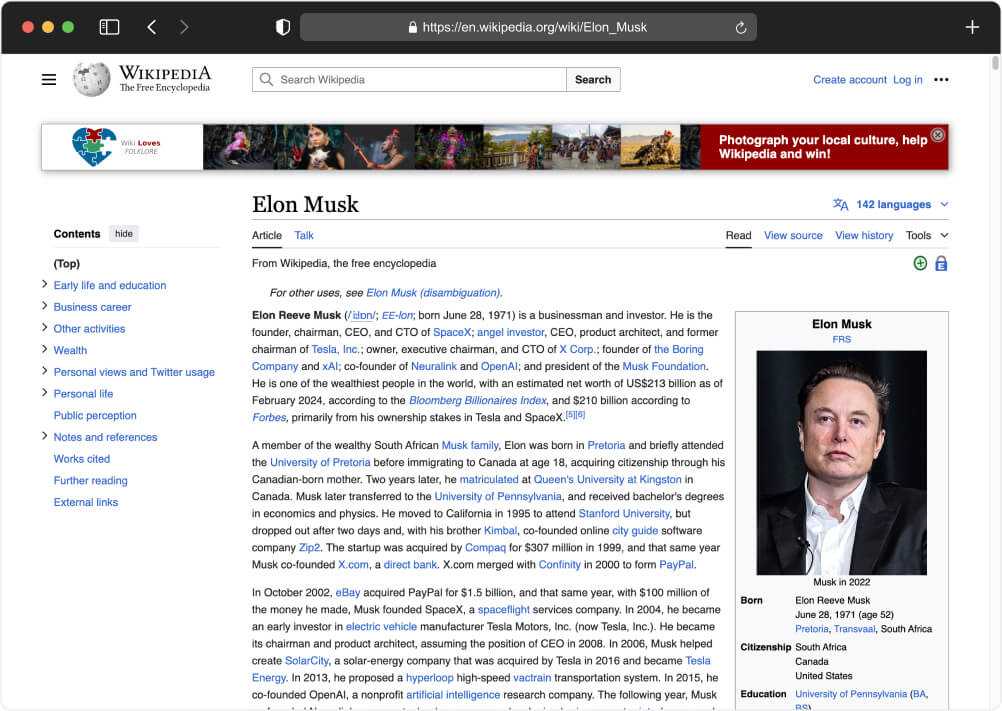
Wikipedia Scraping: Our focus will be on extracting specific data elements from Wikipedia pages with the help of BeautifulSoup (Python), including titles, nicknames, citizenship details, images, and profile titles.
Web Scraping Wikipedia Tables: We’ll discuss techniques for scraping tabular data from Wikipedia pages, identifying tables using BeautifulSoup selectors, and saving the extracted data to a CSV file.
This URL will be our example for this project.

- Error Handling: We’ll address error handling during the scraping process, providing guidelines and troubleshooting tips for common issues encountered during data extraction.
Now that this is clear, let’s continue with the prerequisites of the project.
III. Prerequisites
Before diving head first into our web scraping project to scrape Wikipedia using Python, there are a few prerequisites you should take into account:
Basic Knowledge of Python: Familiarity with Python programming language is essential for understanding the code examples and concepts presented in this tutorial. If you’re new to Python, consider going through introductory Python tutorials or courses to grasp the fundamentals.
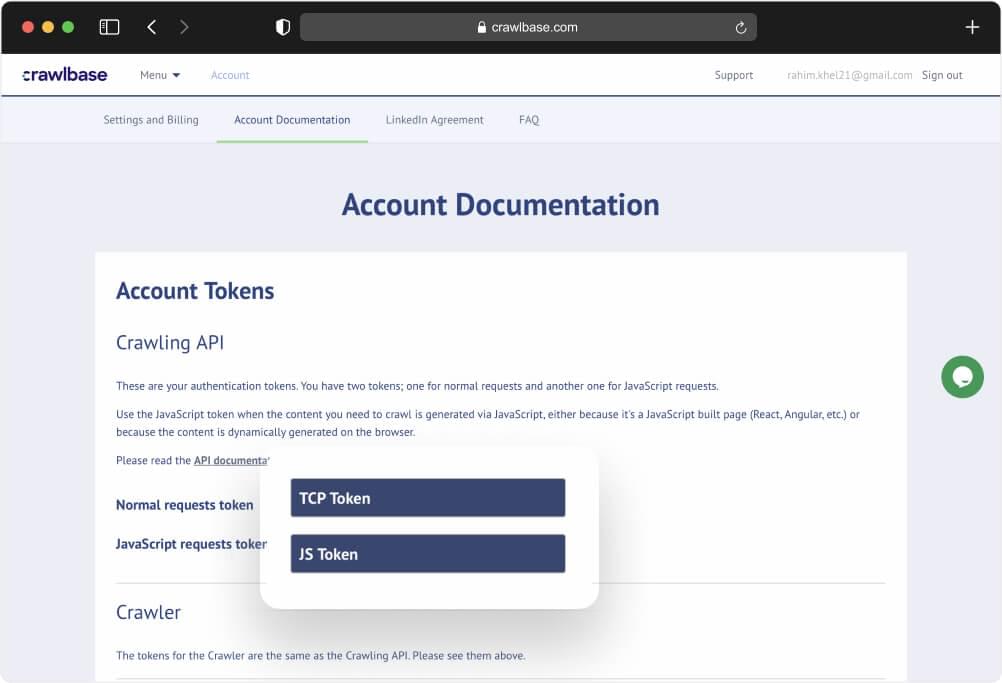
Active Crawlbase API Account with API Credentials: To access Wikipedia pages programmatically and efficiently, you’ll need an active account on Crawlbase and obtain API credentials.
Start by signing up for the Crawlbase Crawling API to get your free 1,000 requests and obtaining your API credentials from account documentation. For this particular project, we will utilize the normal request token.
- Python Installed on Your Development Machine: Make sure that Python is installed on your local development machine. You can download and install Python from the official Python website based on your operating system. Additionally, ensure that you have pip (Python package manager) installed, which is usually included with Python installations by default.
Once you have fulfilled these prerequisites, you’ll be ready to start on the journey of web scraping Wikipedia pages using Python. In the next sections, we’ll guide you through the process step by step, from setting up the environment to extracting and handling data effectively. Let’s proceed with the project!
IV. Installing Dependencies
If you haven’t already installed Python on your system, you can download and install the latest version from the official Python website.
Packages Installation:
- Open your Command Prompt or Terminal:
For Windows users: Press
Win + R, typecmd, and press Enter.For macOS/Linux users: Open the Terminal application.
- Create a Directory for Your Python Scraper:
- Navigate to the directory where you want to store your Python scraper project.
- Install Necessary Libraries:
- Use the following commands to install the required Python libraries:
pip install crawlbase |
About the Libraries:
Pandas: Pandas is a popular open-source Python library used for data manipulation and analysis. It provides powerful data structures and functions designed to make working with structured or tabular data seamless and efficient. The primary data structure in Pandas is the DataFrame, which is a two-dimensional labeled data structure similar to a spreadsheet or SQL table.
Crawlbase: The Crawlbase Python library simplifies the integration of the Crawling API, which we’ll utilize to fetch HTML content from websites, including Wikipedia pages. By utilizing the Crawlbase Python library, we can streamline the process of retrieving data, enabling efficient web scraping operations for our project.
BeautifulSoup: BeautifulSoup is a popular Python library for web scraping and parsing HTML and XML documents. It provides a convenient way to extract data from web pages by navigating the HTML structure and searching for specific tags, attributes, or text content.
Setting Up Your Development Environment:
To begin coding your web scraper, open your preferred text editor or integrated development environment (IDE). You can use any IDE of your choice, such as PyCharm, VS Code, or Jupyter Notebook.
Create a New Python File: Open your IDE and create a new Python file. Let’s name it wikipedia_scraper.py for this example. This file will serve as our scraper script.
Now that you have Python installed and the necessary libraries set up, you’re ready to start coding your web scraper to extract data from Wikipedia pages. Let’s proceed with building the scraper script!
V. How to Extract HTML from Wikipedia
To extract the complete HTML source code from a Wikipedia webpage, we’ll utilize the Crawlbase package to make a request and retrieve the HTML content. Below are the steps to write the code:
Step 1: Importing the Crawlbase Library
from crawlbase import CrawlingAPI |
- This line imports the
CrawlingAPIclass from thecrawlbaselibrary, which allows us to make requests to the Crawlbase API for web crawling and scraping tasks.
Step 2: Defining the crawl Function
def crawl(page_url, api_token): |
- This function, named
crawl, takes two parameters:page_url(the URL of the Wikipedia page to scrape) andapi_token(the API token required for accessing the Crawlbase API).
Step 3: Initializing the CrawlingAPI Object
api = CrawlingAPI({'token': api_token}) |
- Here, we create an instance of the
CrawlingAPIclass, passing the API token as a parameter to authenticate our request to the Crawlbase API.
Step 4: Making a GET Request
response = api.get(page_url) |
- This line sends a GET request to the specified
page_urlusing thegetmethod of the api object. It retrieves the HTML content of the Wikipedia page.
Step 5: Checking the Response Status Code
if response['status_code'] == 200: |
- We check if the response status code is 200, indicating that the request was successful and the HTML content was retrieved without any errors.
Step 6: Extracting and Printing the HTML Content
print(f'{response["body"]}') |
- If the request was successful, we print the HTML content of the Wikipedia page. The HTML content is stored in the
responsedictionary under the key'body'.
Step 7: Handling Errors
else: |
- If the request fails (i.e., if the response status code is not 200), we print an error message along with the response details.
Step 8: Main Function
if name == "main": |
- This block of code ensures that the following code is executed only if the script is run directly (not imported as a module).
Step 9: Specifying Wikipedia Page URL and API Token
page_url = 'https://en.wikipedia.org/wiki/Elon_Musk' |
- Here, we specify the URL of the Wikipedia page we want to scrape (
page_url) and the API token required for accessing the Crawlbase API (api_token). Make sure to replace Crawlbase_Token with your actual Crawling API normal request token.
Step 10: Calling the crawl Function
crawl(page_url, api_token) |
- Finally, we call the
crawlfunction, passing thepage_urlandapi_tokenas arguments to initiate the scraping process.
Here is the complete Python code snippet you can copy and paste to your wikipedia_scraper.py file:
from crawlbase import CrawlingAPI |
Now let’s execute the above code snippet. To run it we need to execute the below command:
python wikipedia_scraper.py |
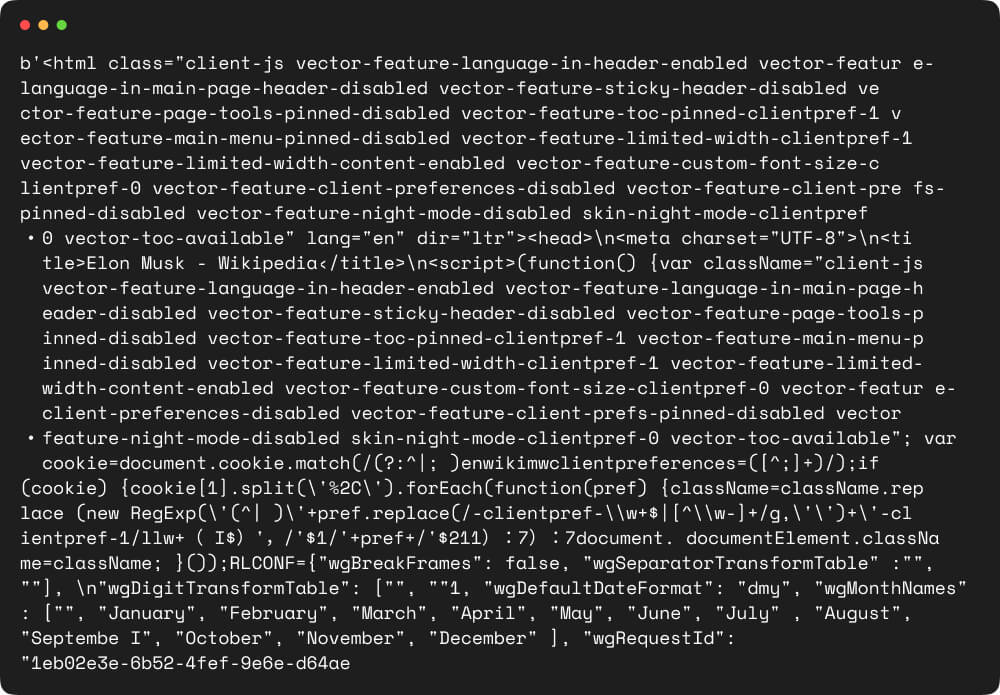
Upon execution, the script will make a request to the specified Wikipedia page URL (‘https://en.wikipedia.org/wiki/Elon_Musk‘) using the Crawlbase API token provided. If the request is successful, it will print the HTML content of the page. Otherwise, it will display an error message.
The output will be the HTML content of the Wikipedia page, which can then be parsed and processed further to extract specific data of interest.
VI. How to Scrape Wikipedia
To scrape content from Wikipedia using BeautifulSoup, we’ll need to import the necessary libraries and define functions to handle the scraping process. Here’s how we can proceed:
Step 1: Importing Libraries
We’ll need to import the CrawlingAPI class from the crawlbase module for making requests to the Crawlbase API. Additionally, we’ll import BeautifulSoup from the bs4 (BeautifulSoup) module for parsing HTML, and pandas for creating and manipulating data frames.
from crawlbase import CrawlingAPI |
Step 2: Initializing the Crawling API
We’ll define a function named crawl to initialize the CrawlingAPI object, fetch the webpage content using the API, and handle the scraping process.
We will also define a function named scrape_data to extract specific information from the HTML content of the webpage using BeautifulSoup.
Finally, we’ll specify the Wikipedia page URL to scrape, the Crawlbase API token, and call the crawl function to initiate the scraping process.
def crawl(page_url, api_token): |
Step 3: How to Scrape Wikipedia Page Title
In the HTML source code, locate the section or container that represents the title. This typically involves inspecting the structure of the webpage using browser developer tools or viewing the page source.
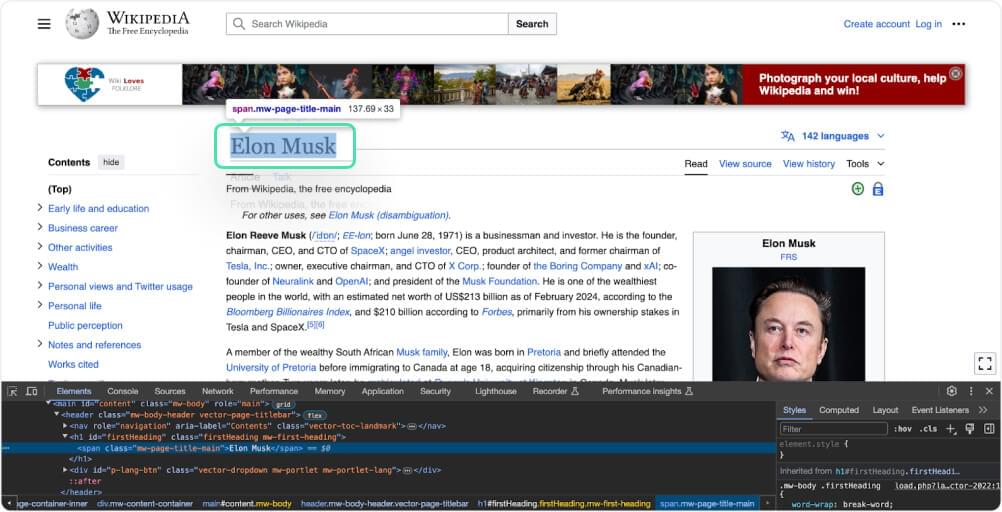
Utilize BeautifulSoup selectors to target the title element within the webpage. This involves specifying the appropriate class that matches the desired element.
title = soup.find('h1', id='firstHeading').get_text(strip=True) |
This line of code finds the first occurrence of the <h1> element with the ID “firstHeading” in the HTML content stored in the variable soup. It then extracts the text inside that element and removes any extra spaces or newlines using the get_text(strip=True) method. Finally, it assigns the cleaned text to the variable title.
Step 4: How to Scrape Wikipedia Nickname property
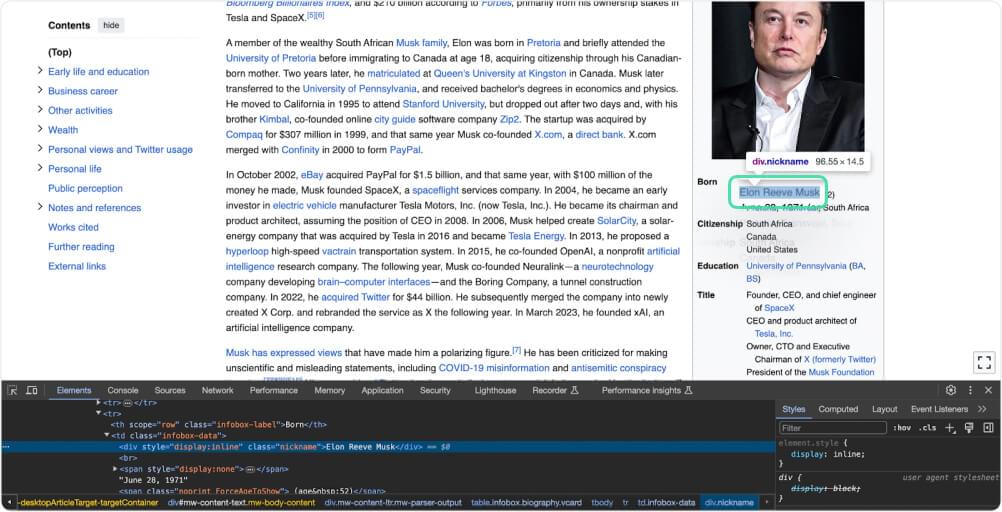
nickname = soup.find('div', class='nickname').get_text(strip=True) |
This code finds an HTML element <div> with the CSS class “nickname” within a parsed HTML document represented by the variable soup. It then extracts the text content of this element, removing any extra whitespace characters before and after the text, and assigns it to the variable nick_name.
Step 5: How to Scrape Wikipedia Citizenship property
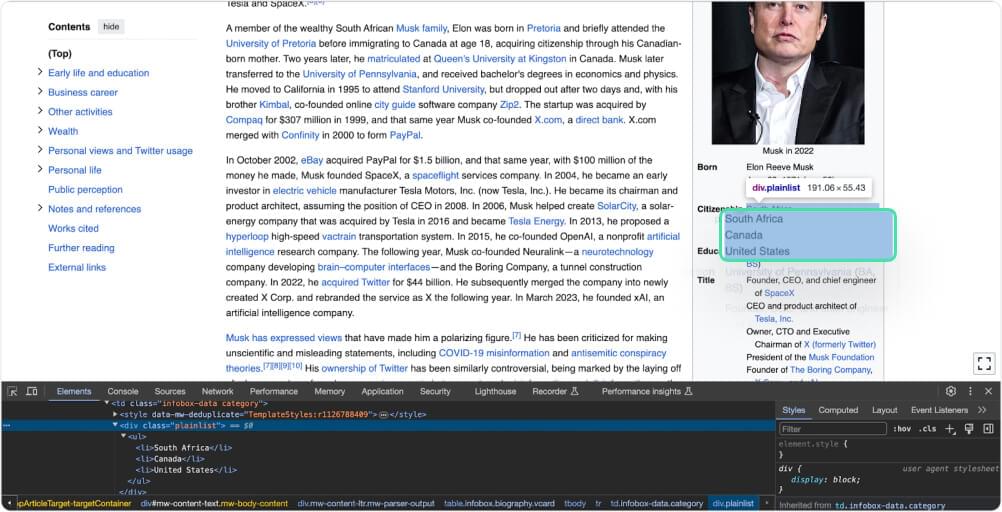
citizenship = soup.select_one('.infobox-data .plainlist').text.strip().replace('\n', ', ') |
The above code searches for an HTML element with class “infobox-data” and “plainlist” within a parsed HTML document represented by the variable soup. It selects the first matching element and extracts its text content. Then, it removes any leading or trailing whitespace characters and replaces newline characters with commas. The resulting text represents citizenship information and is assigned to the variable citizenship.
Step 6: How to Scrape Wikipedia Image
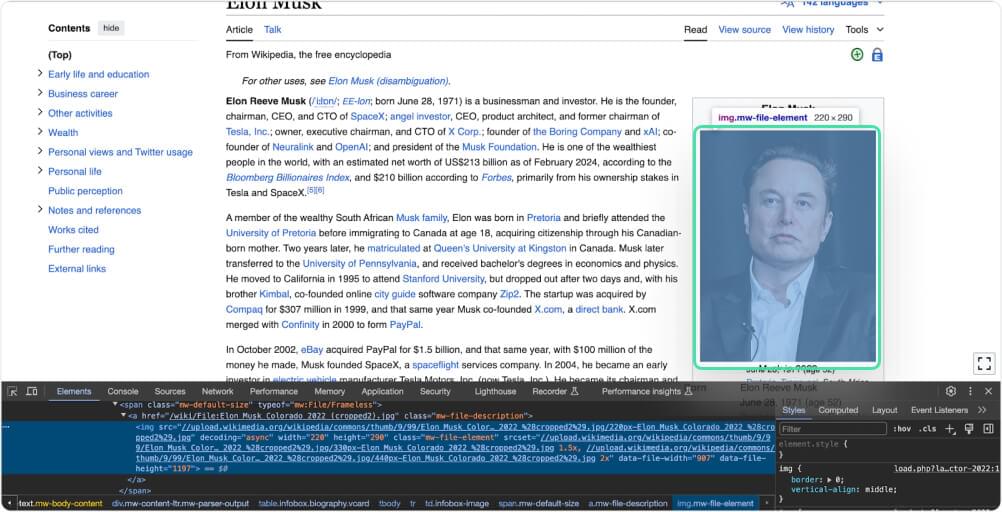
image_src = soup.select_one('.mw-file-description .mw-file-element')['src'] |
This code snippet searches for an HTML element that has both the classes “mw-file-description” and “mw-file-element” within a parsed HTML document represented by the variable soup. It selects the first matching element and retrieves the value of the “src” attribute, which typically contains the URL of an image. The URL is then assigned to the variable image_src.
Step 7: How to Scrape Wikipedia Profile Title
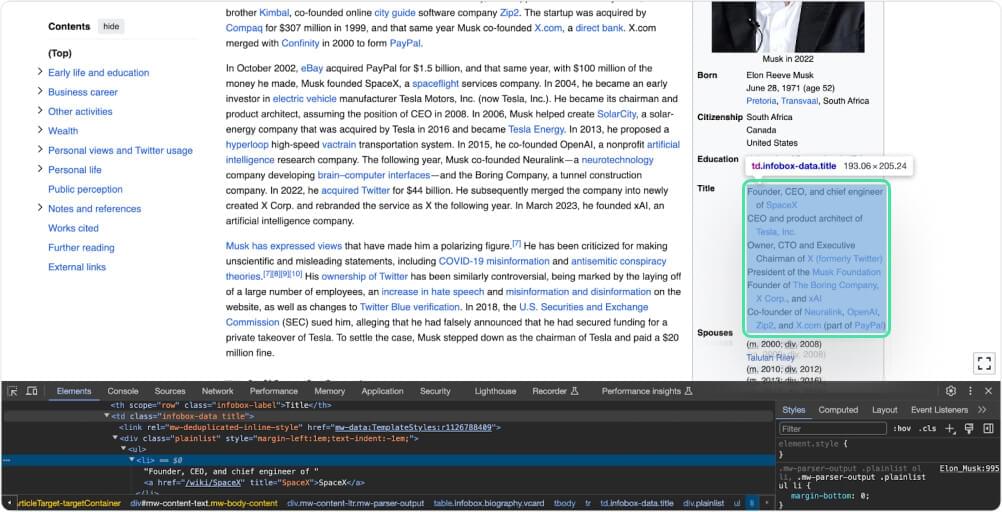
profile_title = soup.select_one('.infobox-data.title').text.strip().replace('\n', ', ') |
This code searches for an HTML element with the class “infobox-data” and “title” within a parsed HTML document represented by the variable soup. It selects the first matching element and retrieves the text content. Then, it removes any leading or trailing whitespace using strip() and replaces newline characters ('\n') with commas (','). Finally, it assigns the modified text to the variable profile_title.
Step 8: Complete the Code
Put everything together and your code should look like this. Feel free to copy and save it to your local machine:
from crawlbase import CrawlingAPI |
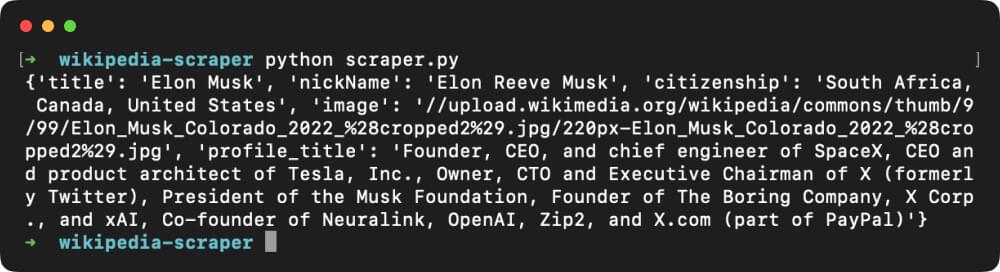
Executing the code by using the command python wikipedia_scraper.py should provide a similar output as shown below:
VII. How to Scrape a Table from Wikipedia
To scrape a table from Wikipedia, we’ll utilize BeautifulSoup along with the Crawlbase library again for fetching the HTML content. Here’s how we can proceed:
Step 1: Importing Libraries
We’ll import the necessary libraries for scraping the table from Wikipedia. This includes BeautifulSoup for parsing HTML, pandas for data manipulation, and the CrawlingAPI class from the Crawlbase library for making requests to fetch the HTML content.
from bs4 import BeautifulSoup |
Step 2: Scraping Table from Wikipedia pages
To scrape a table from Wikipedia, we need to inspect the HTML structure of the webpage containing the table. This can be done by right-clicking on the table, selecting “Inspect” from the context menu. This action will reveal the HTML content of the page, allowing us to identify the tags inside which our data is stored. Typically, tabular data in HTML is enclosed within <table> tags.
Let’s target this URL that contains the table we want to scrape. Once we have identified the URL, we can proceed to extract the table data from the HTML content.
Step 3: Initializing the Crawling API
Next, we’ll initialize the CrawlingAPI to fetch the table data from the Wikipedia page. We’ll pass this data to the scrape_data function to create a BeautifulSoup object. Then, we’ll use the select_one() method to extract the relevant information, which in this case is the <table> tag. Since a Wikipedia page may contain multiple tables, we need to specify the table by passing either the “class” or the “id” attribute of the <table> tag.
You can copy and paste the complete code below:
from bs4 import BeautifulSoup |
Step 4: Execute the Code to Save in CSV file
Run the code one again using the command below:
python wikipedia_scraper.py |
The code structure will allow us to scrape the table from the specified Wikipedia page, process it using BeautifulSoup, and save the extracted data to a CSV file for further analysis. See the example output below:

VIII. Conclusion
In summary, this tutorial provided a comprehensive guide on scraping data from Wikipedia using Python, BeautifulSoup, and the Crawlbase library. It covered various aspects, including scraping HTML content, extracting specific data such as page titles, nicknames, citizenship information, and images, as well as scraping tables from Wikipedia pages.
Furthermore, the tutorial included instructions on scraping tables from Wikipedia pages, highlighting the process of inspecting the HTML structure to identify table elements and utilizing BeautifulSoup to extract tabular data.
The code provided in this tutorial is freely available for use. We encourage you to modify and adapt the code for your projects. Additionally, the techniques demonstrated here can be applied to scrape data from other websites, offering a versatile approach to web scraping tasks.
We hope that this tutorial serves as a valuable resource for anyone looking to learn Wikipedia scraping or other online sources for analysis, research, or other purposes.
We recommend browsing the following pages if you would like to see more projects like this:
How to Scrape Samsung Products
How to Scrape Google Scholar Results
Real-Estate Data Scraping from Zillow
If you have questions regarding Crawlbase or this article, please contact our support team.
IX. Frequently Asked Questions
Q. Is scraping Wikipedia legal?
Scraping Wikipedia is generally legal, but there are certain factors to consider. While Wikipedia’s content is often licensed under Creative Commons licenses, which allow for certain uses with proper attribution, it’s essential to review and adhere to their terms of use, including any restrictions on automated access.
Consulting with legal experts or seeking clarification from Wikipedia directly is advisable to ensure compliance with applicable laws and regulations. This helps to mitigate the risk of potential legal issues related to web scraping activities.
Q. Is it possible to scrape Wikipedia using a different programming language?
Yes, it is possible to scrape Wikipedia using various programming languages besides Python. Wikipedia provides an API, such as the MediaWiki API, which allows access to its content programmatically. This means you can use different programming languages that support HTTP requests and JSON/XML parsing to interact with the API and retrieve Wikipedia data.
However, the specific details may vary depending on the programming language and the available libraries or frameworks for making HTTP requests and processing JSON/XML data.
Additionally, web scraping techniques, such as parsing HTML with libraries like BeautifulSoup, can also be applied in different programming languages to extract Wikipedia data directly.
Subscribe to my newsletter
Read articles from Crawlbase directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by