Extract any entity from text with GLiNER
 Andrea D’Agostino
Andrea D’Agostino
Those who have worked in the past with the NER (named entity recognition) paradigm know well the value of having a performing model for the task on which it has been trained.
In fact, NER models are extremely useful for data mining and textual analysis tasks — they are the foundation of every digital intelligence task and in myriad tasks linked to larger and more complex data science pipelines.
Those who do NER also know how complex it is to train such a model due to the enormous amount of labels to be specified during the training phase. Libraries like SpaCy and transformer-based Hugging Face models have greatly helped data scientists develop NER models in an increasingly efficient manner, which still improves the process up to a certain point.
In this article we will look together at the GLiNER paradigm, a new technique for entity extraction that combines the classic NER paradigm with the power of LLMs.
By the end of this article you will know what GLiNER is and how to use it in Python to do classification of any token, on any text.
In summary, by reading this article you will learn
What is GLiNER
Because it is potentially revolutionary
How to implement it in Python
Limitations of GLiNER
GLiNER was published in a scientific paper, present at the link below 👇
https://arxiv.org/abs/2311.08526
Furthermore, the authors of the paper have published a public Github repository
What is GLiNER?
GLiNER is an NER model that can identify any type of entity using a bidirectional transformer encoder (similar to BERT). It provides a practical alternative to traditional NER models, which are limited to predefined entities, and Large Language Models (LLMs) which, despite their flexibility, are expensive and large for resource-limited scenarios.
GLiNER uses a BiLM (Bidirectional Transformer Language Model) and accepts entity prompts and a sentence/text as input.
Going briefly technical, each entity is separated by a learned token [ENT] and BiLM generates vector representations (embeddings) for each token. The embeddings are passed into a feedforward neural network, while the representations of the input words are passed into a neural layer dedicated to learning the character windows that enclose the token in question). These windows are called spans.
Finally, a similarity score is calculated between the entity representations and the span representations using the dot product and sigmoid activation.
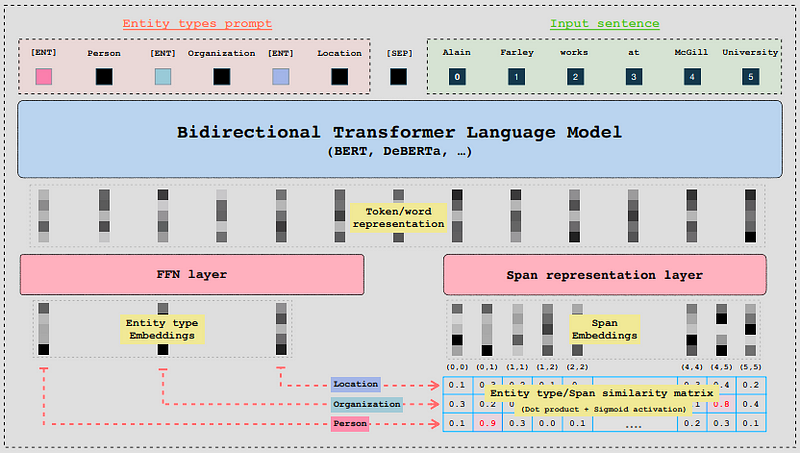
Image taken from GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer.https://arxiv.org/abs/2311.08526
Instead of relying on large-scale autoregressive models (such as GPT-3.5 and 4), small-scale bidirectional language models (the mentioned BiLMs) are used, such as BERT or deBERTa.
💡The central concept of GLiNER is that the task is not generative, but is a matching between token and span embeddings. This approach naturally solves the scalability issues of autoregressive models and allows for bidirectional processing of context, which allows for richer representations.
At the time of publication, GLiNER outperforms both ChatGPT and LLM optimized zero-shot NER datasets.
Why is GLiNER potentially revolutionary?
GLiNER is lighter, scalable, faster and more accurate than an LLM-based approach, including ChatGPT.
The most surprising thing is that it is now possible to do NER at ZERO cost, quickly and efficiently.
We have gone from having to train an NER model from scratch or spending money on an LLM-based solution, to a model that combines both solutions and does so in the most efficient way possible, both from a technical and economic point of view.
GLiNER performances are shown in the image below:
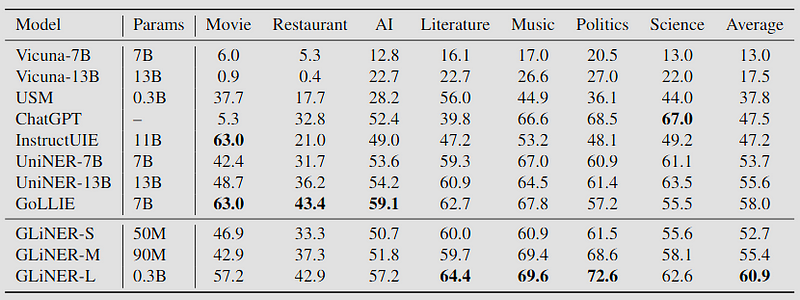
Image taken from GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer.https://arxiv.org/abs/2311.08526
It is only surpassed in some specific domains by other models, but the numerical gap is not large.
Below is a benchmark against ChatGPT only on 20 public NER datasets on a zero-shot token classification task:
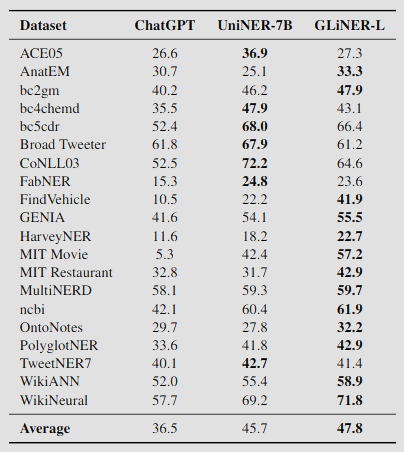
Image taken from GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer.https://arxiv.org/abs/2311.08526
GLiNER is available in various sizes, but the small version is already able to surpass the performance of ChatGPT. The small version has a size of 50 million parameters, which corresponds to approximately 600MB.
The model is therefore impressive from the point of view of results, and has the potential to become the main solution to the most common NER problems.
How to implement GLiNER in Python
The authors of the project have made a convenient package available that can be installed via pip.
pip install gliner
Unlike another NER model, we don’t have to train or fine-tune anything. We just need to specify in a Python list which entities we want to extract from our text.
So there are two things you need:
The entities (read labels) that we want to extract
The text from which we want to extract the entities
Using the example in the project’s Git repository, you can see how simple it is to use GLiNER in Python.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = """
Cristiano Ronaldo dos Santos Aveiro
(Portuguese pronunciation: [kɾiʃˈtjɐnu ʁɔˈnaldu]; born 5 February 1985)
is a Portuguese professional footballer who plays as a forward for
and captains both Saudi Pro League club Al Nassr and the Portugal national
team. Widely regarded as one of the greatest players of all time,
Ronaldo has won five Ballon d'Or awards,[note 3] a record three
UEFA Men's Player of the Year Awards, and four European Golden Shoes,
the most by a European player. He has won 33 trophies in his career,
including seven league titles, five UEFA Champions Leagues,
the UEFA European Championship and the UEFA Nations League.
Ronaldo holds the records for most appearances (183), goals (140)
and assists (42) in the Champions League, goals in the
European Championship (14), international goals (128) and
international appearances (205).
He is one of the few players to have made over 1,200 professional
career appearances, the most by an outfield player,
and has scored over 850 official senior career goals for club and country,
making him the top goalscorer of all time.
"""
labels = ["person", "award", "date", "competitions", "teams"]
entities = model.predict_entities(text, labels, threshold=0.5)
for entity in entities:
print(entity["text"], "=>", entity["label"])
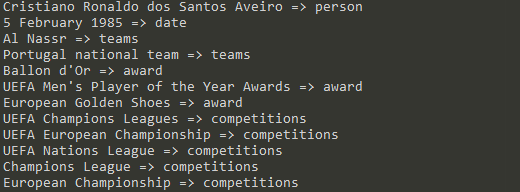
You can change the list as you like, and start the model again to get more entities.
We modify the labels from
labels = ["person", "award", "date", "competitions", "teams"]
to these
labels = ["event", "location"]
This is the output

Limitations of GLiNER
In the paper the authors highlight several aspects on which GLiNER can improve
the model suffers from training done on unbalanced classes: some classes are more frequent than others and would like to improve the identification and management of these classes with a dedicated loss function
multilingual skills need to be improved: training in multiple languages is needed (currently Italian is poorly supported)
it is based on a similarity threshold: in the future the authors would like to make it dynamic so as to capture as many entities as possible without distorting the results
Conclusions
GLiNER is a must explore and use for data mining and data analytics tasks.
My opinion is that it will be a project that will increasingly gain ground in the sector, with possible forks that will give rise to even bigger innovations.
Maybe the RAG paradigm can be improved thanks to fast and efficient identification of entities?
Subscribe to my newsletter
Read articles from Andrea D’Agostino directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Andrea D’Agostino
Andrea D’Agostino
Data scientist. I write about data science, machine learning and analytics. I also write about career and productivity tips to help you thrive in the field.