GCP Data Stream Integration for Seamless Flow
 Srivatsasa Janaswamy
Srivatsasa Janaswamy
On GCP, data analysts look to access the data from Cloud SQL DB instance onto Bigquery console to analyse the data through the queries. But usually, data will fetched by creating the external connections to the DB instances.
However, they can just fetch the data manually by logging into GCP Bigquery console whenever it's required. But what if, data flow should be seamless and on real time from Cloud SQL.
Here is the Solution for it. -> DATA STREAM , a GCP Service
Data Stream is a serverless and easy-to-use change data capture (CDC) and replication service that lets you synchronize data reliably, and with minimal latency. It provides seamless replication of data from operational databases into BigQuery.
In addition, Datastream supports writing the change event stream into Cloud Storage, and offers streamlined integration with Dataflow templates to build custom workflows for loading data into a wide range of destinations, such as Cloud SQL and Spanner.
Benefits of Datastream include:
Seamless setup of ELT (Extract, Load, Transform) pipelines for low-latency data replication to enable near real-time insights in BigQuery.
Being serverless so there are no resources to provision or manage, and the service scales up and down automatically, as needed, with minimal downtime.
Easy-to-use setup and monitoring experiences that achieve super-fast time-to-value.
Integration across the best of Google Cloud data services' portfolio for data integration across Datastream, Dataflow, Cloud Data Fusion, Pub/Sub, BigQuery, and more.
Synchronizing and unifying data streams across heterogeneous databases and applications.
Security, with private connectivity options and the security you expect from Google Cloud.
Being accurate and reliable, with transparent status reporting and robust processing flexibility in the face of data and schema changes.
Supporting multiple use cases, including analytics, database replication, and synchronization for migrations and hybrid-cloud configurations, and for building event-driven architectures.
But in this blog, we will see the seamless data flow from GCP cloud SQL Postgre DB Instance to Bigquery datawarehouse through integration of Data Stream.
Datastream consists of two components:
Connection Profiles
Private Connectivity
Let's move into the action now...!!!
Pre-requisites for this integration:
Cloud SQL Postgre DB instance
Bigquery configuration along with dataset creation
IAM Roles -> Owner, IAP Policy Admin, IAP-secured Tunnel User and Datastream Admin for the Devops Engineer to implement this integration.
PLEASE NOTE, ALL THE CONFIGURATIONS MENTIONED IN THIS BLOG SHOULD BE IN THE SAME REGION
Steps to follow for this integration:
Please check the settings of your VPC
This is the VPC where our Cloud SQL resides in
Please check that Private Google Access is turned on
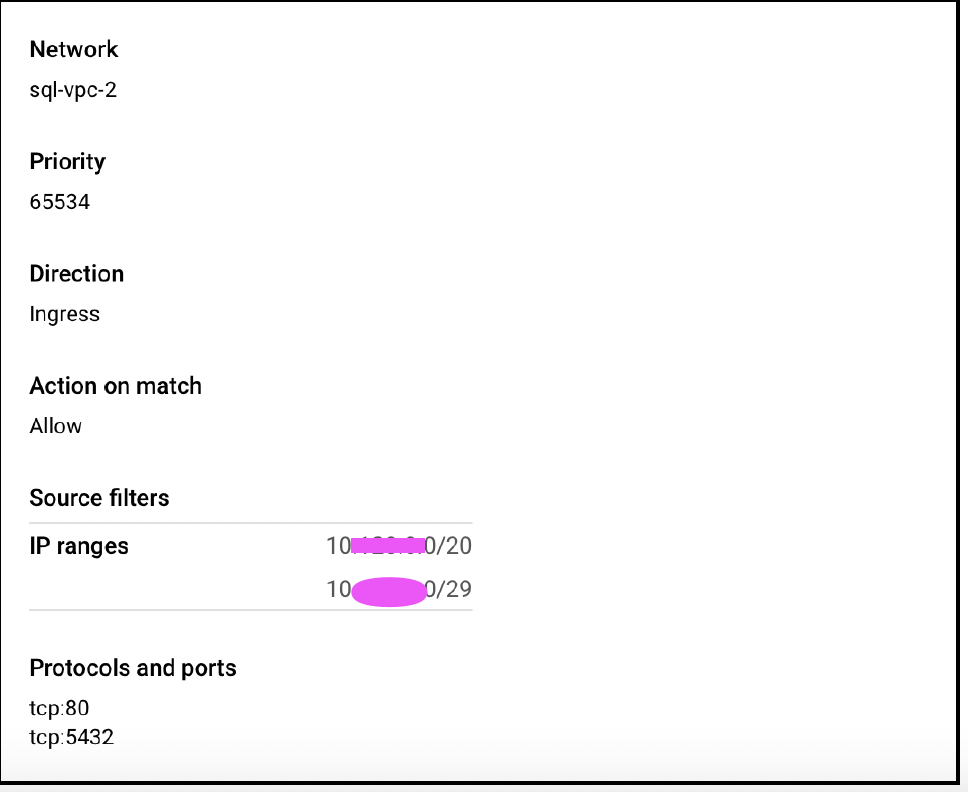
Please create a firewall rule to allow ingress traffic on ports tcp 80 and 5432 from the subnet that the VM resides in and the subnet that Datastream will be allocated.
Example
VM’s subnet → 10.x.x.0/20
IP range for subnet that should be allocated to Datastream → 10.x.x.0/29
Please set a network tag, such that it will be used while creating a VM, so traffic will be allowed to VM on the above mentioned ports
Please create proxy
In the same VPC where Cloud SQL instance present, please create a VM with below settings
e2-standard-2 with debian/linux as instance type
Paste the following code into the startup script under VM's maintenance section
#! /bin/bashexport DB_ADDR=[Cloud SQL private IP]export DB_PORT=5432export ETH_NAME=$(ip -o link show | awk -F': ' '{print $2}' | grep -v lo)export LOCAL_IP_ADDR=$(ip -4 addr show $ETH_NAME | grep -Po 'inet \K[\d.]+')echo 1 > /proc/sys/net/ipv4/ip_forwardiptables -t nat -A PREROUTING -p tcp -m tcp --dport $DB_PORT -j DNAT \--to-destination $DB_ADDR:$DB_PORTiptables -t nat -A POSTROUTING -j SNAT --to-source $LOCAL_IP_ADDRlet’s verify that the forwarding rule has been set up correctly
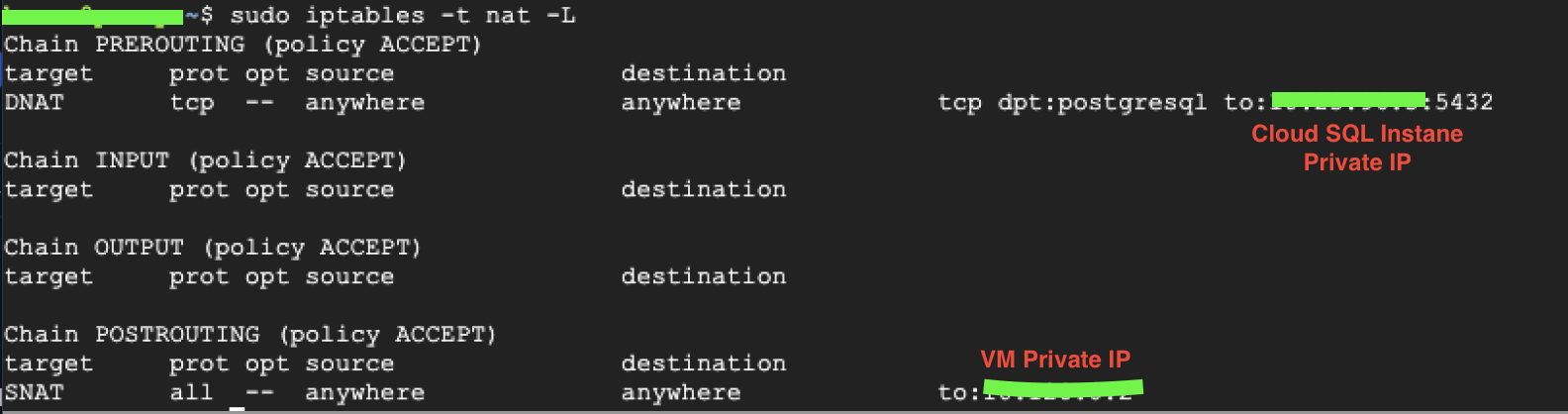
For verification, please run this command to check the forwarding rules
sudo iptables -t nat -Lwhich shows as below. This is a route to the private ip of the Cloud SQL instance under PREROUTING and a route to the VM’s private IP
under POSTROUTING
PRIVATE CONNECTIVITY:
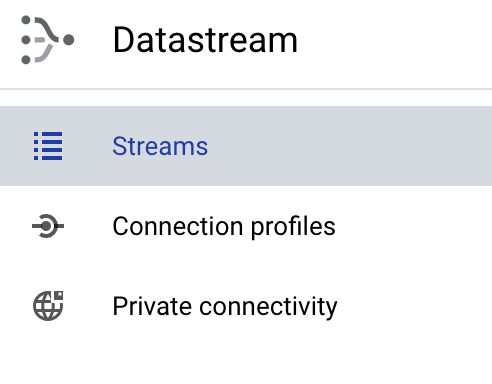
Go to Streams Console on GCP -> Open the left pane -> Select the below highlighted one.
Please give the name to configuration name of private connectivity and choose a region
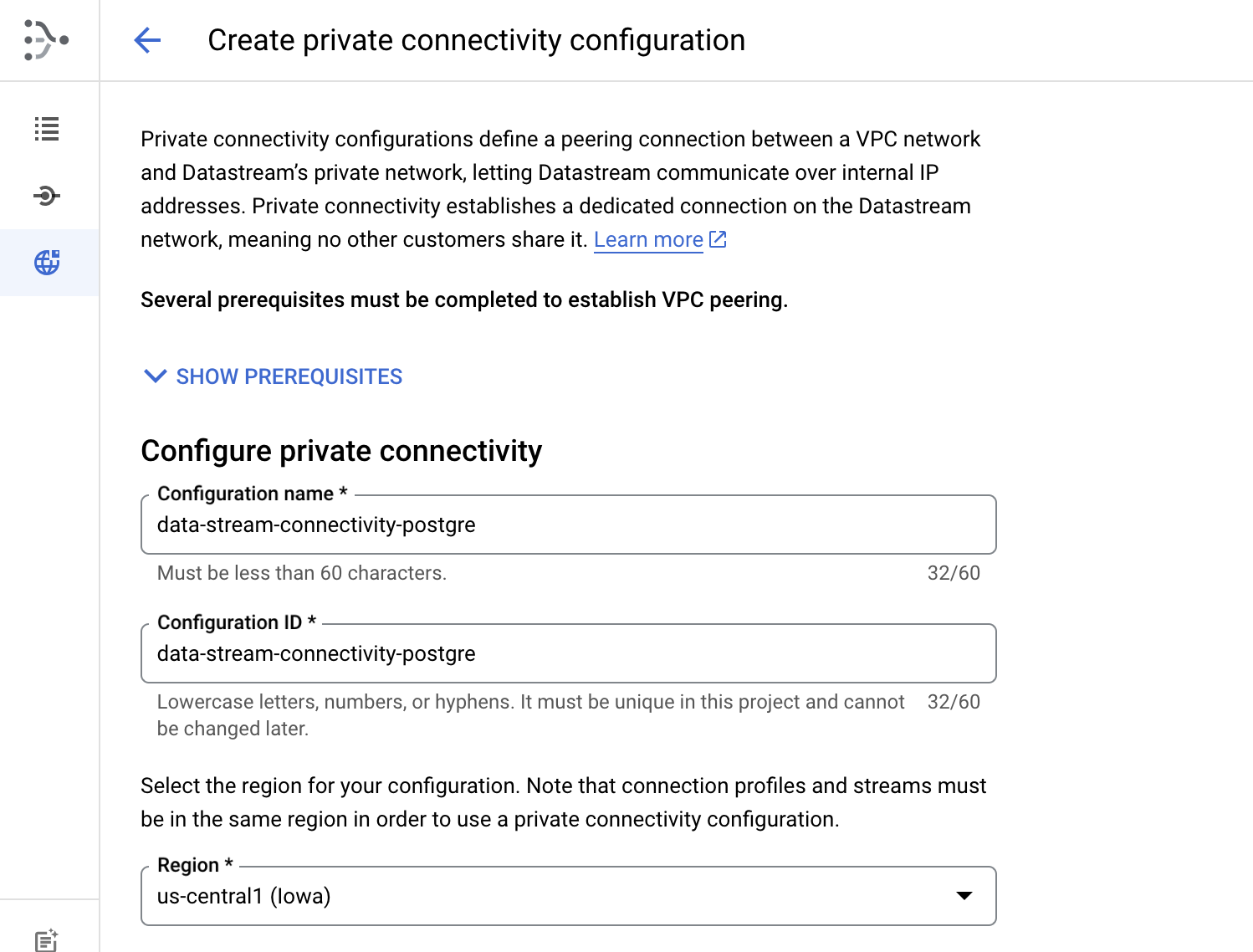
Please choose a VPC network where your Database resides in and assign the IP as mentioned in the 1st step with CIDR IP range /29. Below is the example for the same
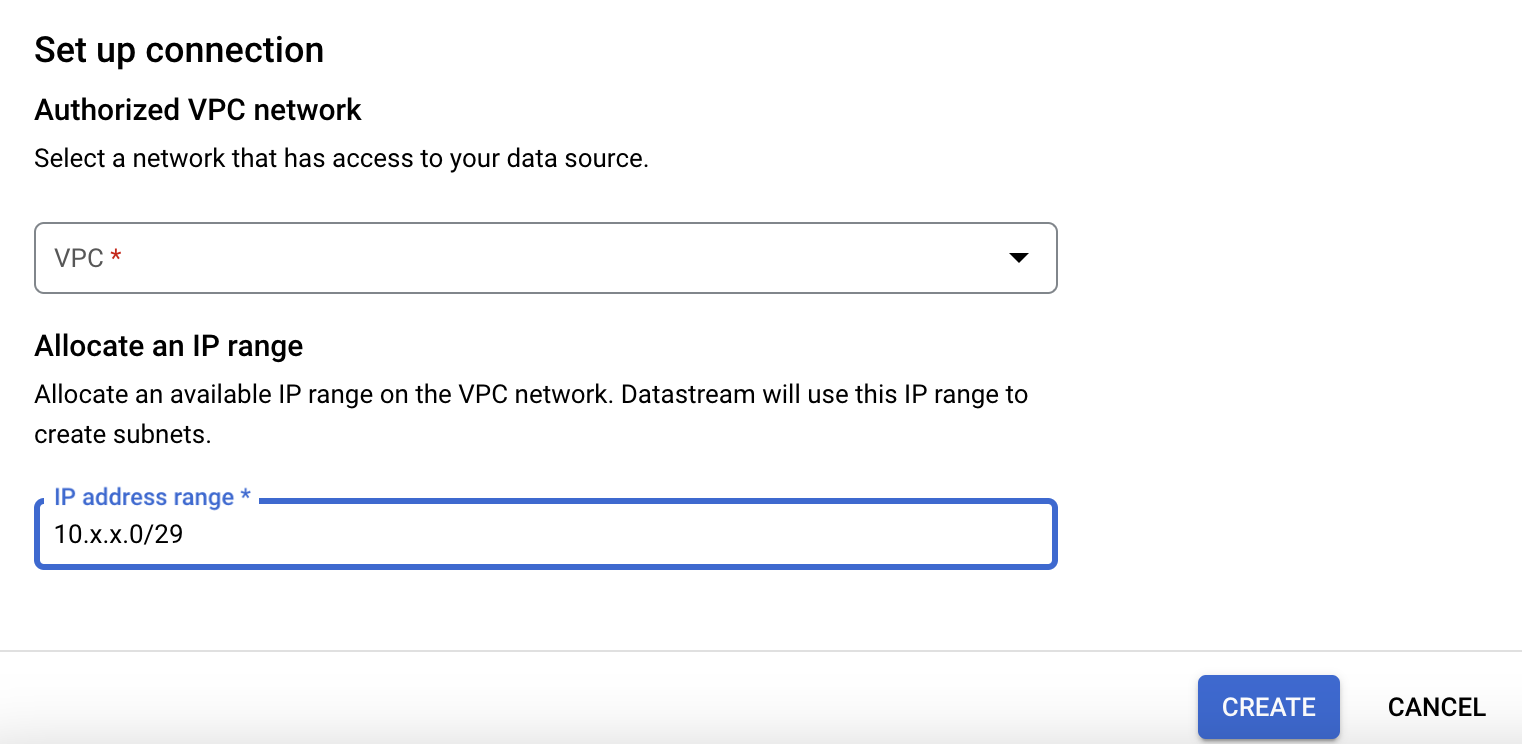
Then please click on 'CREATE' to define a private connectivity.
CONNECTION PROFILES:
Go to Streams Console on GCP -> Open the left pane -> Select the below highlighted one.
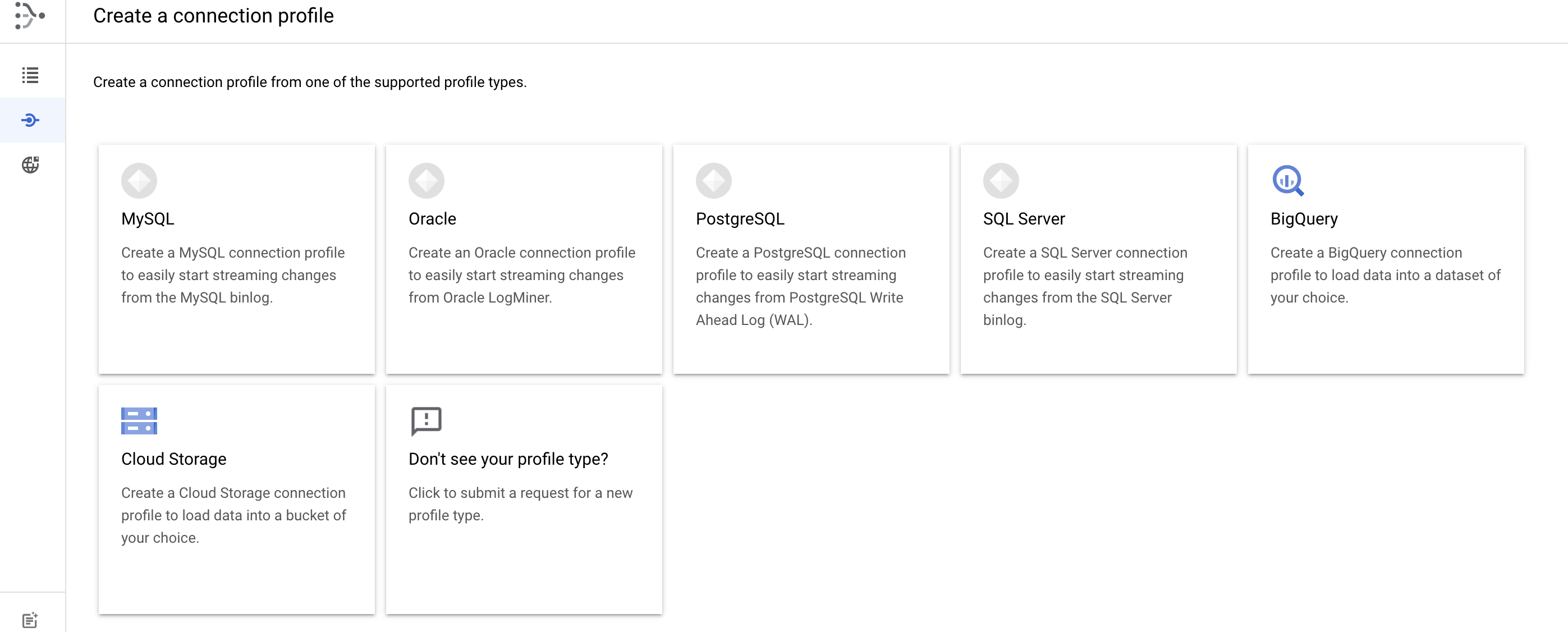
Select the Postgre SQL from the options below, as we are trying to transfer the data from PostgreSQL to Bigquery.
Please provide details in the below mandatory fields
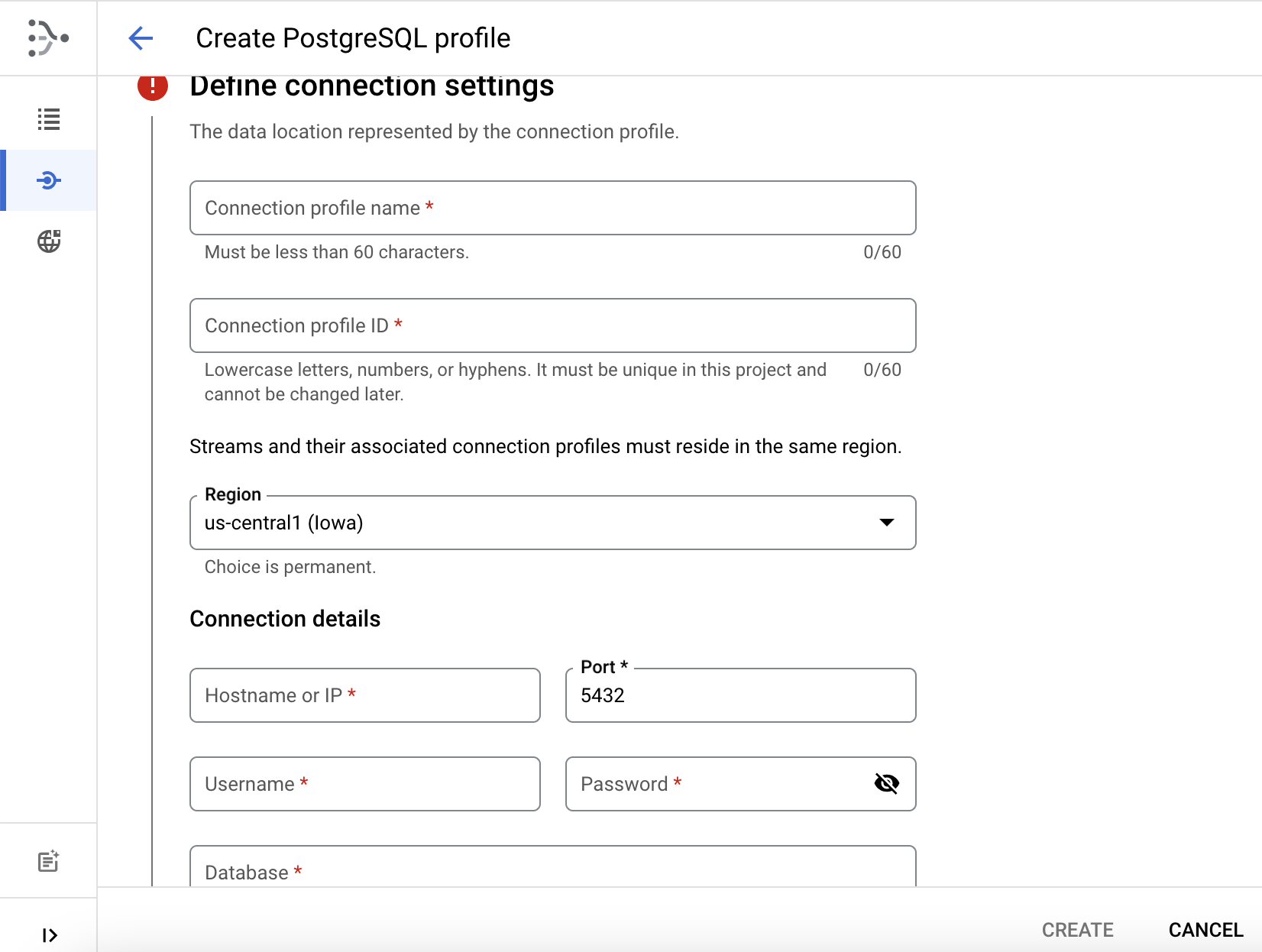
Connection Profile Name: Please enter connection profile name here
Connection profile ID will be auto-generated, while entering connection profile name
Please ensure, region should be as region of other resources like VM and SQL DB
Hostname or IP: This should be IP of VM created as under "Please create proxy"
Port should be 5432 (Because its Postgre SQL DB)
User name and password are credentials for logging into the database and they should have privileges to create "publication" and "replication" which will be shown in one of next few steps.
Database name should be one from which Data is planned to be transfer to BigQuery
Then please click on "Continue"
Then please choose below option. Because Private connectivity is safest option to integrate Postgre and Bigquery
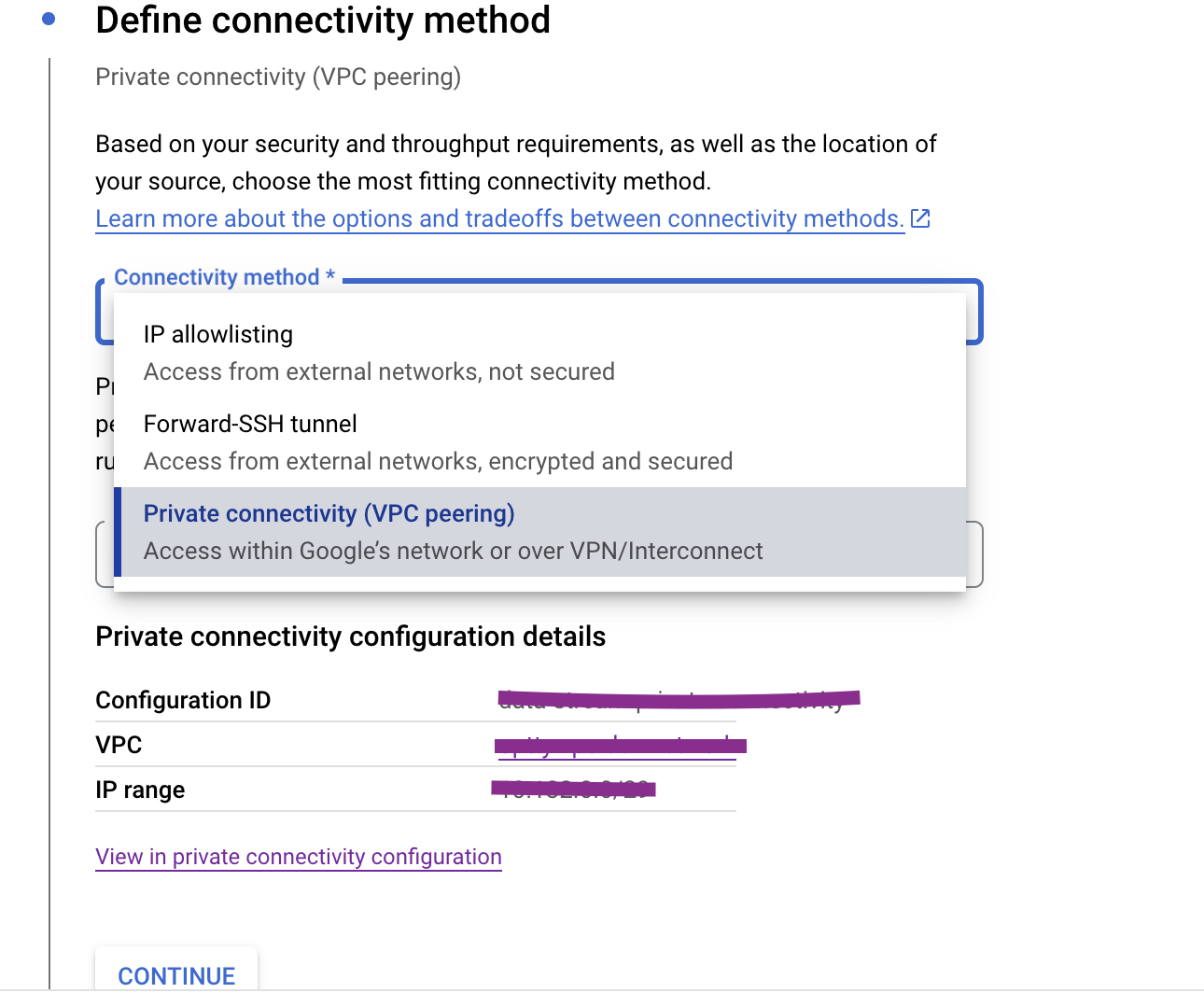
Please click on "Continue".
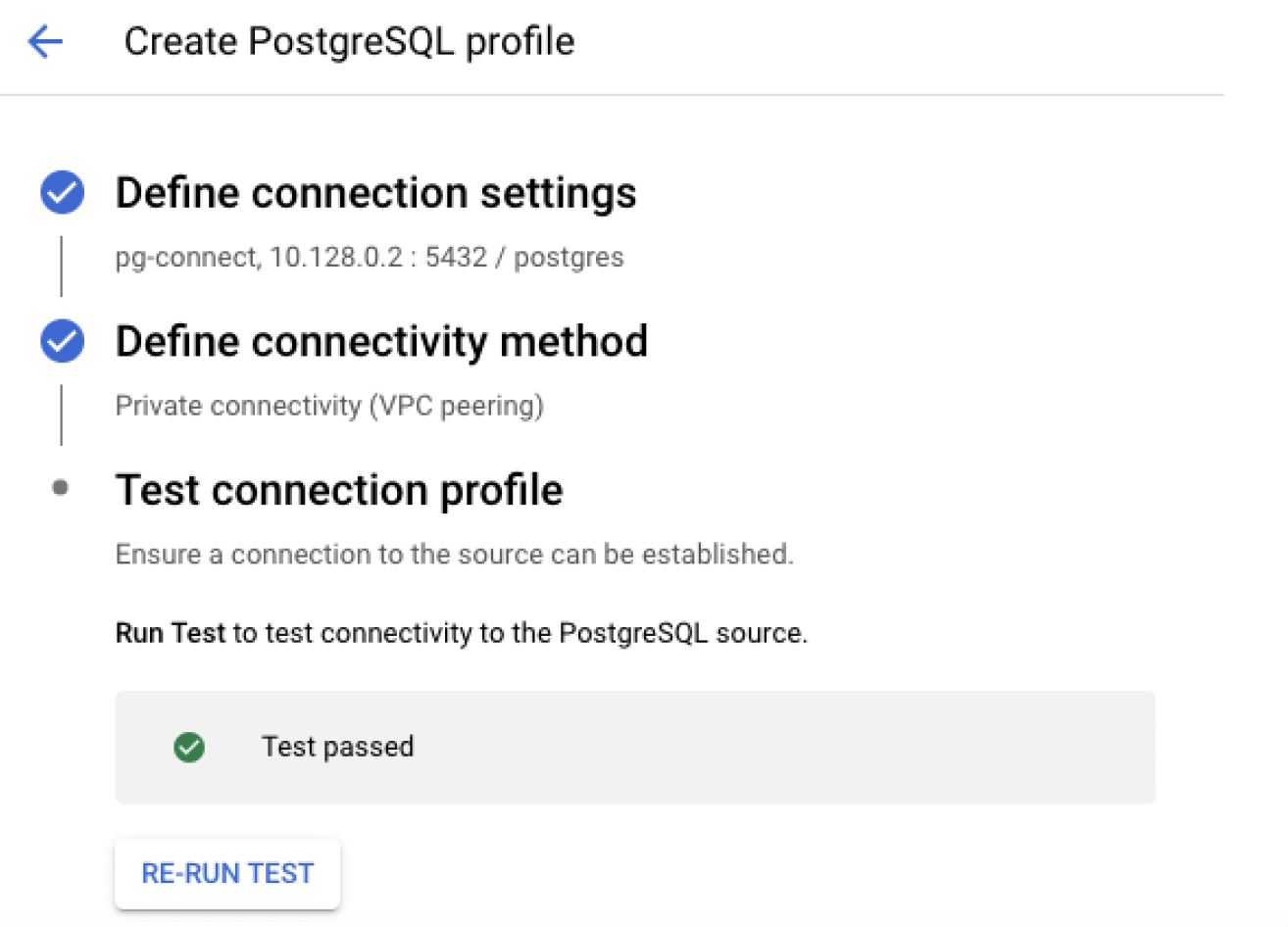
Please click on Run Test to check connectivity to Postgre SQL from Datastream

Please ensure test should be passed as below
CREATE STREAM:
Please choose below highlighted option from the below screenshot
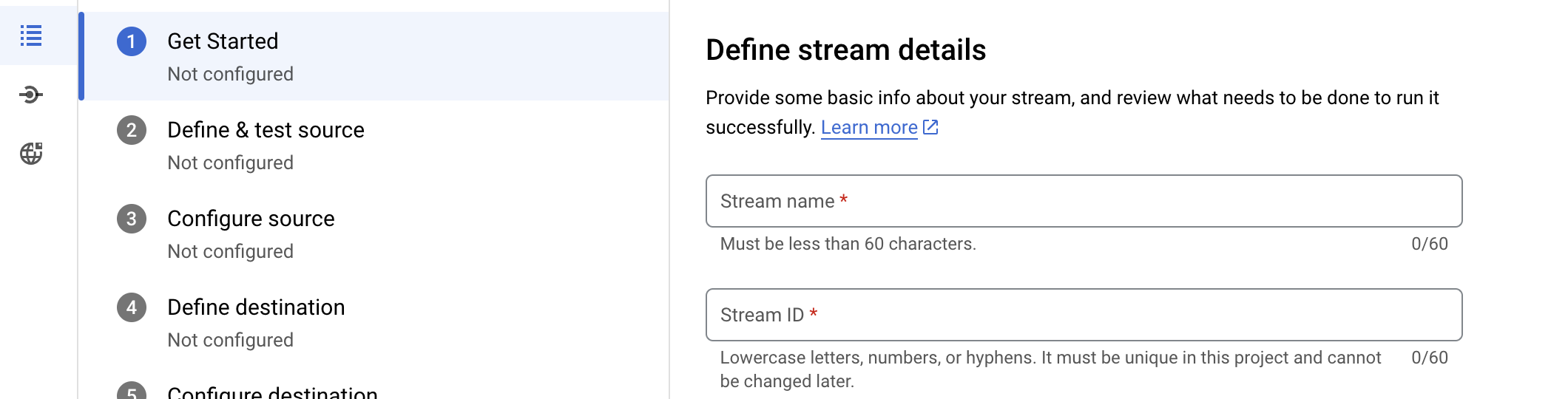
Please enter the following details as shown in the screenshot below
Stream Name: Please enter the Datastream name.
Stream ID: Stream ID will be auto-generated which would be same as stream name
Please choose the region same as region of cloud SQL DB and VM. Also please choose the source type as PostgreSQL and destination as Big query as in below screenshot
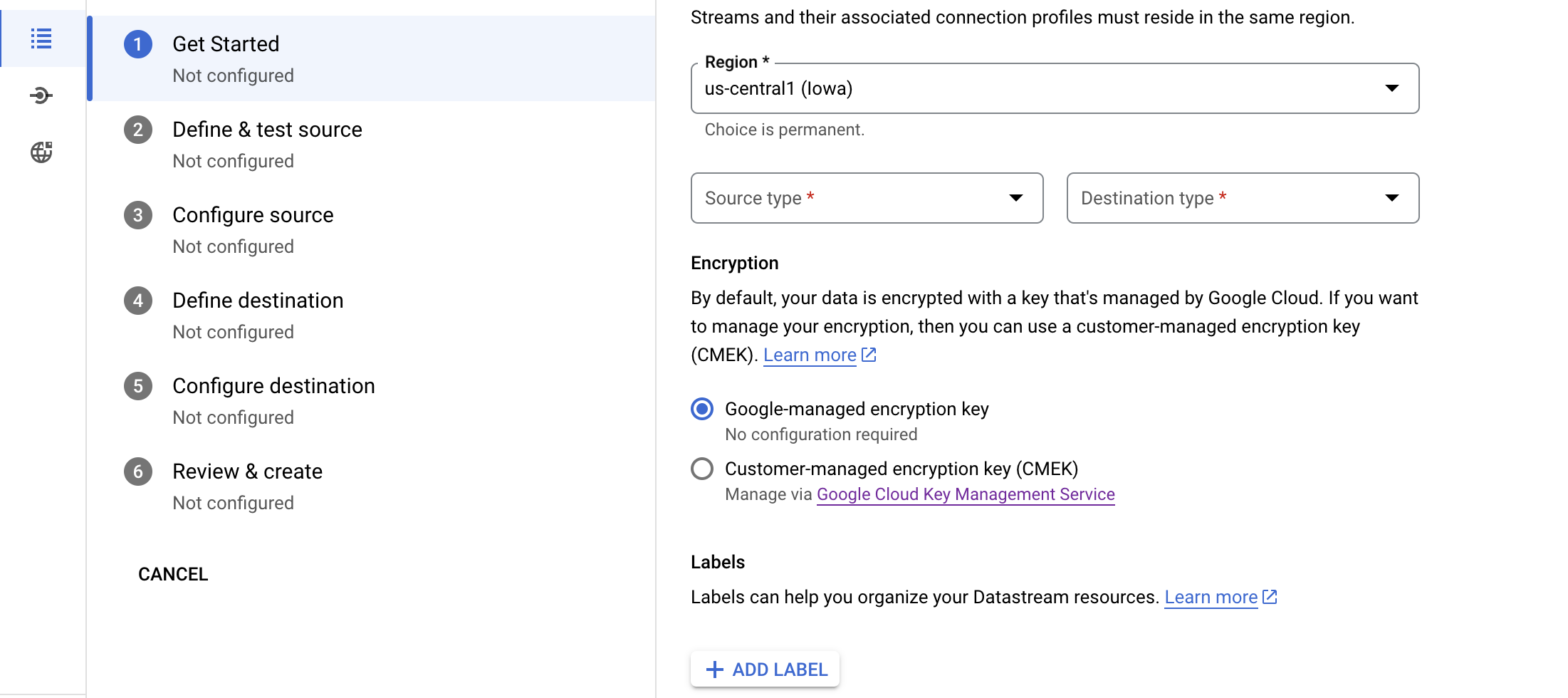
Then please click on Open for SQL Commands and to select the PostgreSQL source type

Please choose option Cloud SQL for PostgreSQL
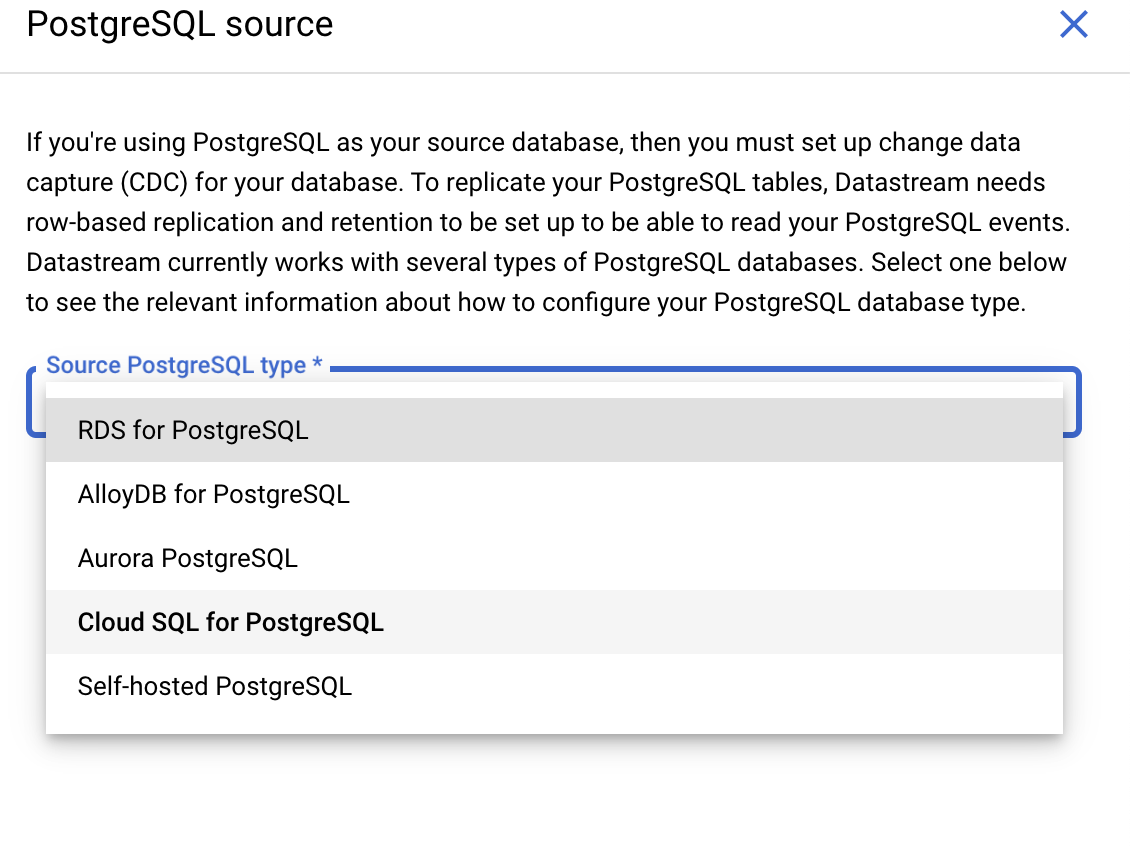
Please enable cloudsql.logical_decoding as mentioned in below screenshot and click on "continue".
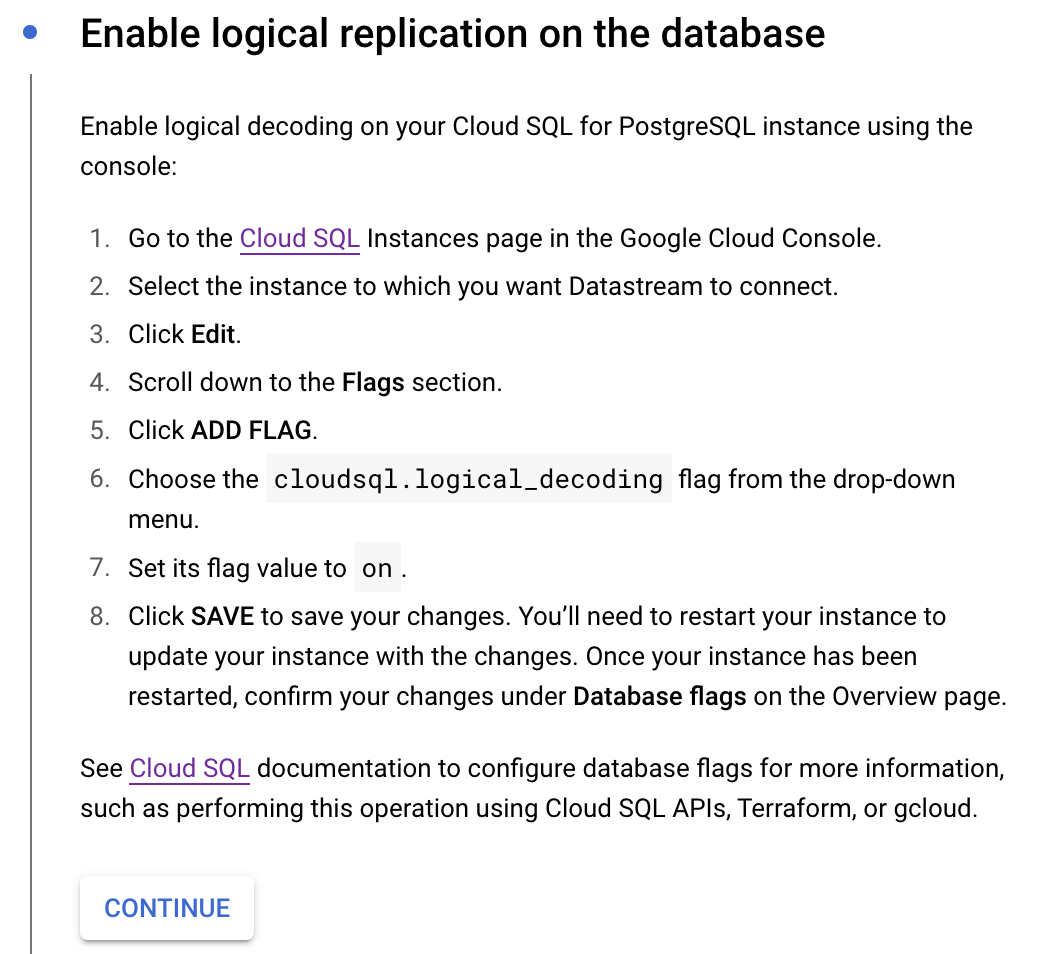
Then please run the commands in below screenshot to create publication and replication. As explained above, Credentials of database should have access to run commands in below two screenshots
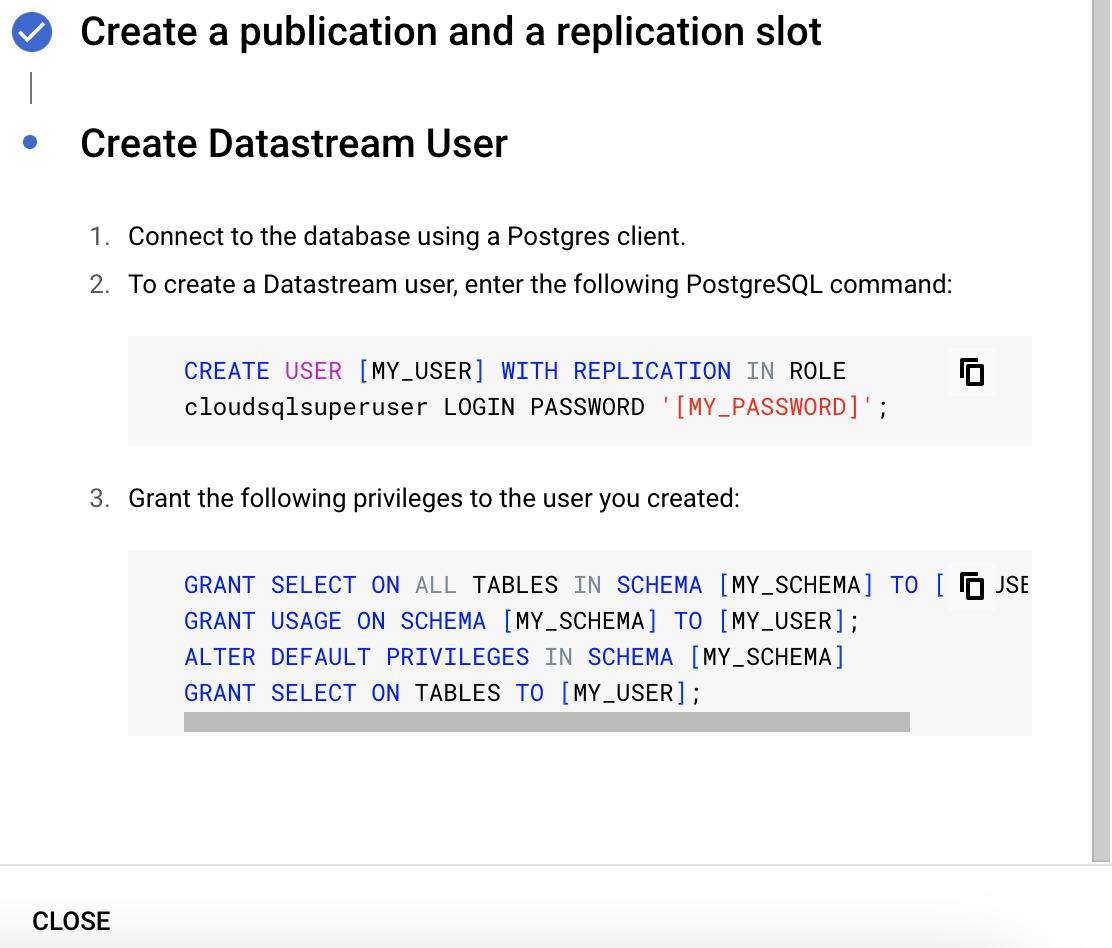
Then please click on "close".
Then you will be routed back to "Get Started". Please click on "Continue" over there.
- Once you click on "continue", you will routed to "Define and test source" as in below screenshot
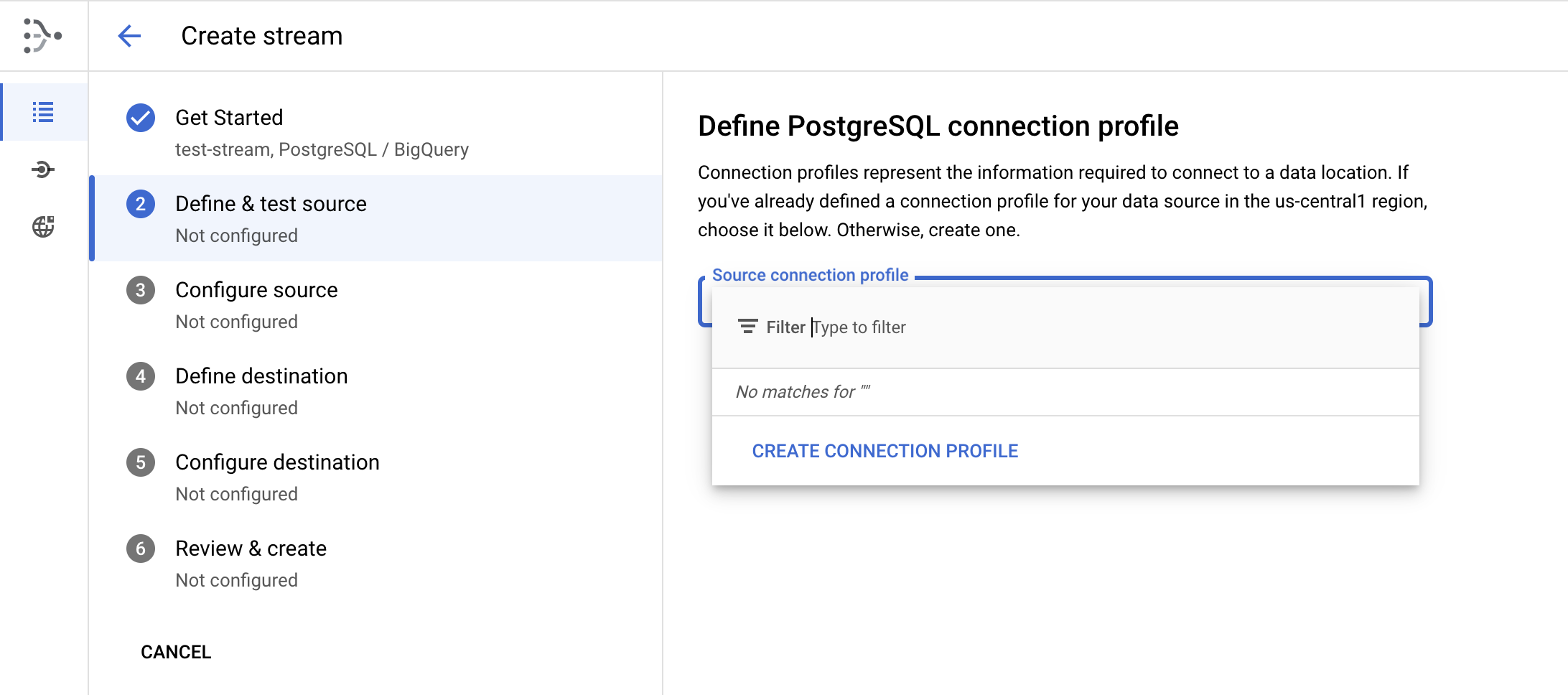
Please choose the connection profile that was created above. It will be shown in the drop-down of below screenshot. Please click on "Continue" or "Save" (option can be anyone)
- Please click on "Configure Source" from the left pane of the "Create Stream"
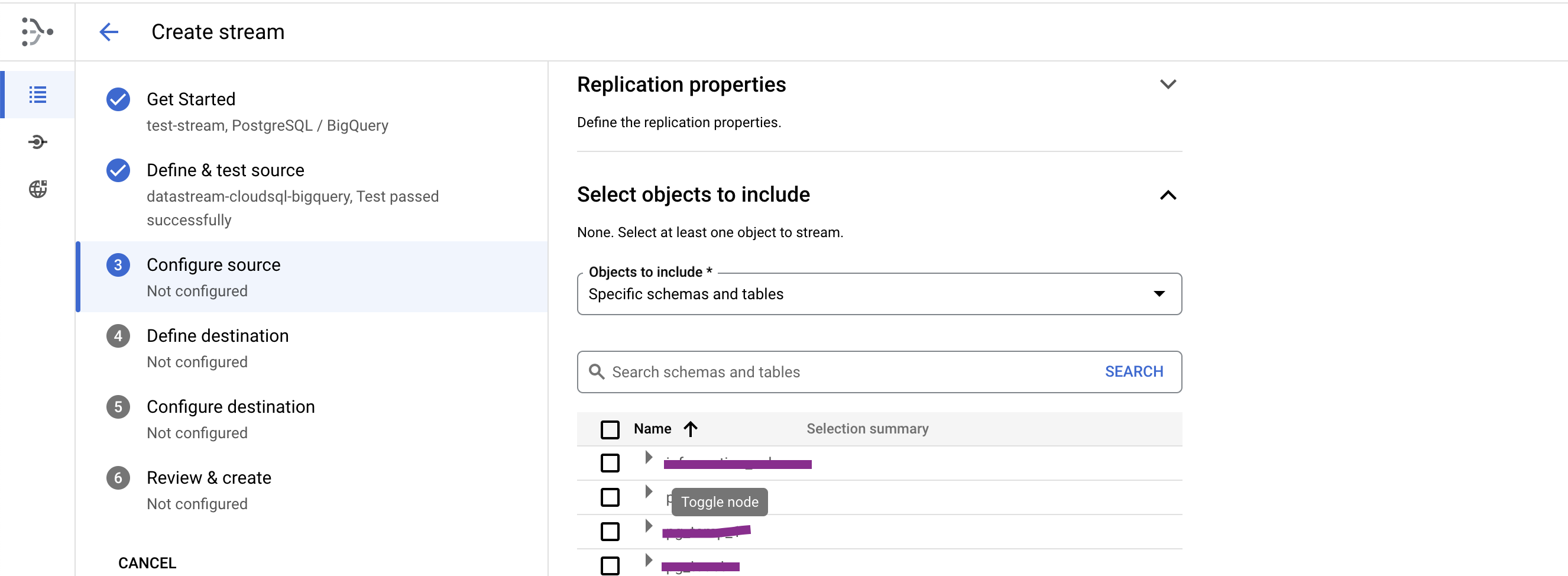
Then please enter the "REPLICATION NAME" and "PUBLICATION NAME" that you have chosen while executing some SQL commands in one of above points and choose the tables you want to see the data on BigQuery as schemas shown in the below screenshots. Once you expand the schema you wanted, you can see the tables under that schema.
Then please leave rest of the options as it is and click on "SAVE".
Please choose "Define Destination" and then create "Bigquery connection profile". By clicking drop-down menu, you can see the option to "CREATE CONNECTION PROFILE"
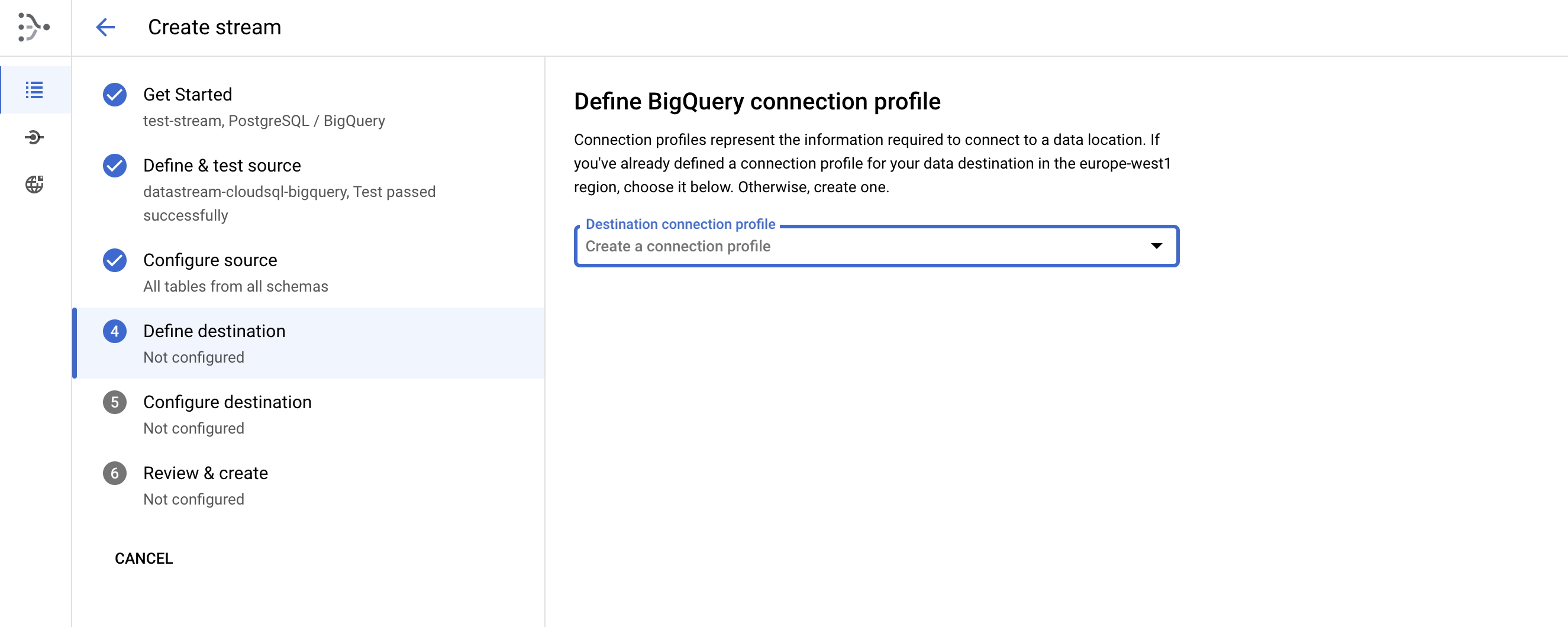
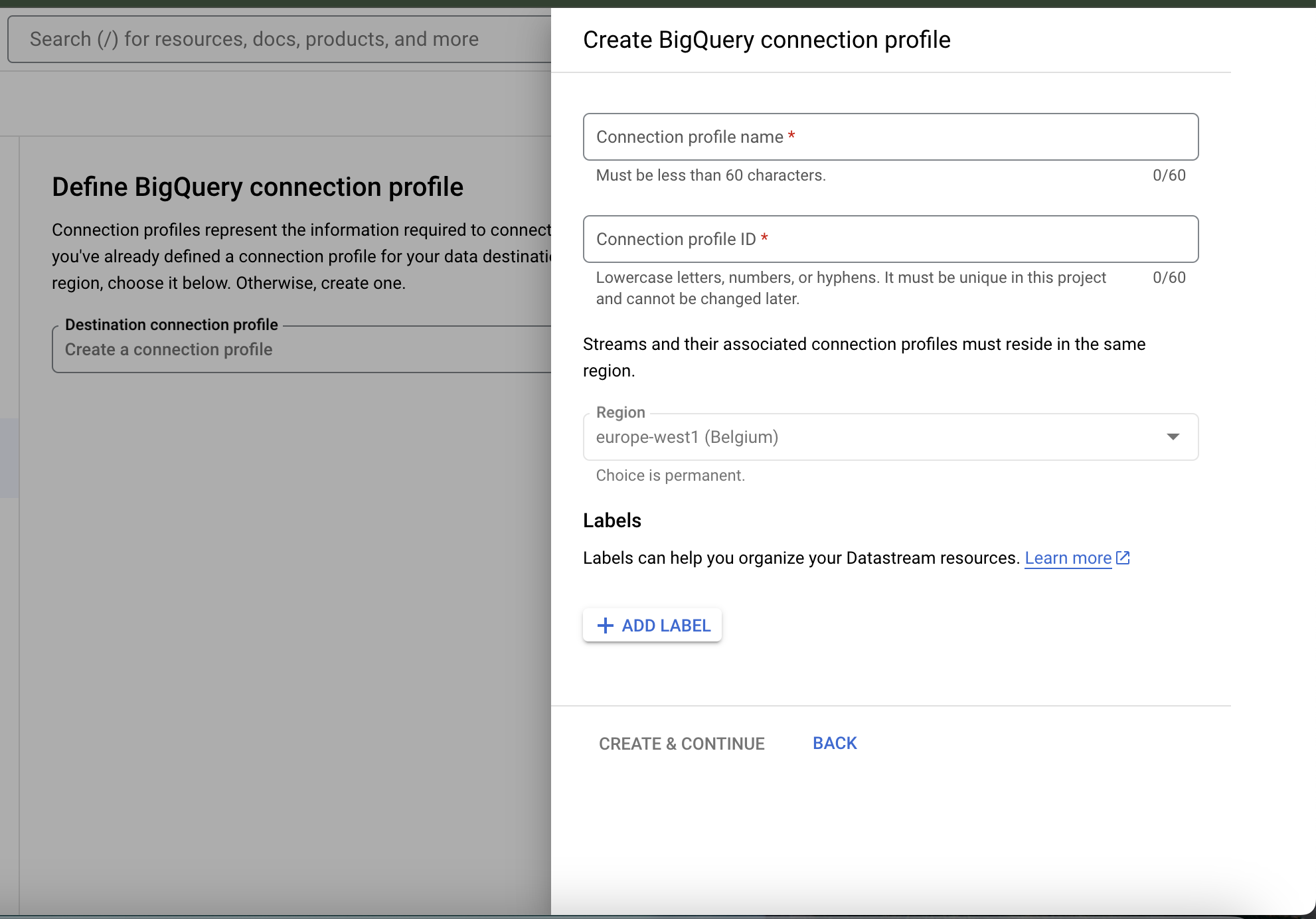
- Please enter the details as
Connection profile name for connection to Big Query.
Profile ID will be auto-generated as per the connection profile name.
Then please click on "Create and Continue"
Once you configure the destination in the next step -> Please click on "Review & Create" where you must "validate the connection" and that must pass.
Once the validation is passed, please go on and create and start the STREAM.
Please note, while configuring destination, dataset should be available on "BIG QUERY" console.
Hope you enjoy this Blog...!!! :)
Subscribe to my newsletter
Read articles from Srivatsasa Janaswamy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by