Demystifying AI: An Insightful Introduction to Machine Learning, Transformers, LLMs, and GPTs
 KIMATHI VICTOR
KIMATHI VICTOR
The winds of change are blowing, and the 21st century presents a unique opportunity: to become a shaper, not just a witness, of the Fourth Industrial Revolution. This revolution, driven by AI and big data, holds immense potential. Imagine being at the forefront, designing algorithms, and crafting the very systems that will define this new era.
Join me on this blog as we delve into the fascinating world of artificial intelligence. We'll explore the intricate details and foundational concepts that lie at its heart, from philosophical underpinnings to cutting-edge experiments.
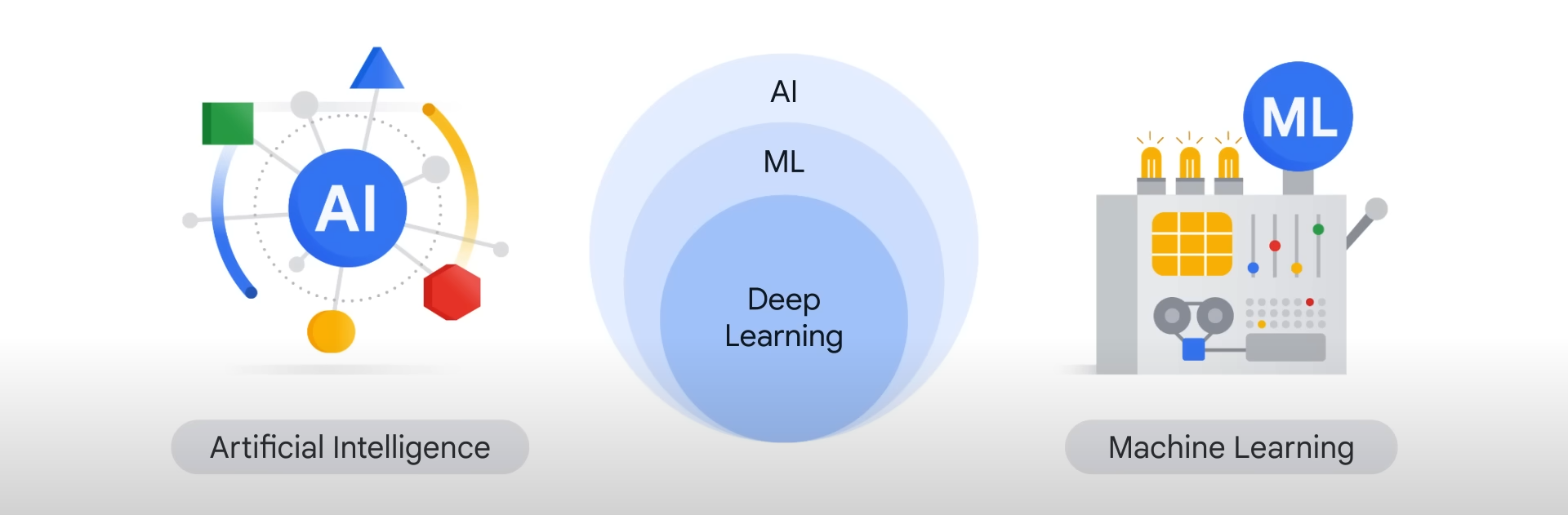
An Introduction to AI
Artificial Intelligence entails simulating human intelligence across domains such as Computer Vision, Natural Language Processing, and Speech Recognition. AI prioritizes cognitive abilities including Learning —employing statistical algorithms capable of learning from data and generalizing to unseen instances— Reasoning—selecting appropriate algorithms to achieve desired objectives—Self-Correction—continuously refining algorithms to optimize performance—and Creativity—leveraging neural networks to generate novel text, ideas, and music.
Artificial Intelligence (AI) encompasses six main fields, each focusing on specific aspects of human-like intelligence:
Machine Learning: This field involves algorithms that enable computers to learn from data, recognize patterns, and make decisions without explicit programming. It's widely used in tasks such as predictive analytics, recommendation systems, and image recognition.
Natural Language Processing (NLP): NLP focuses on enabling computers to understand, interpret, and generate human language. It's used in applications like virtual assistants, sentiment analysis, and language translation.
Computer Vision: Computer vision enables computers to interpret and understand visual information from images or videos. Applications include object detection, image classification, and facial recognition.
Robotics: Robotics combines AI with mechanical engineering to create intelligent machines capable of performing tasks autonomously. This field encompasses areas such as autonomous navigation, manipulation, and human-robot interaction.
Expert Systems: Expert systems mimic the decision-making abilities of human experts in specific domains. They use rules and knowledge bases to provide advice or make decisions in areas like medicine, finance, and engineering.
Speech Recognition and Synthesis: This field focuses on enabling computers to recognize and generate human speech. It's used in applications like virtual assistants, dictation systems, and voice-controlled devices
For a deeper delve into AI, here is a recommendation of philosophical concepts, theoretical distinctions, and notable experiments that you should possibly research on:
The Chinese Room experiment presented by John Searle in 1980,
Weak AI vs Strong AI,
Concept of Artificial General Intelligence,
The Turing Test,
Stochastic Parrot,
Meta Consciousness - Claude-3 Opus Needle in the Haystack Experiment.
An Introduction to Machine Learning
Machine Learning is a scientific discipline concerned with the design and development of self-learning algorithms that derive knowledge from data in order to generate underlying rules,improve the performance of predictive models and make data driven decisions.
Forms of Machine Learning include:
Supervised Learning: Learns from labeled data to predict outcomes based on input-output pairs.
Unsupervised Learning: Discovers patterns in unlabeled data without predefined categories.
Reinforcement Learning: Learns through trial and error with feedback from its actions and experiences.
Other Techniques: Include Semi-supervised Learning, Self-supervised Learning, Multi-task Learning, Transfer Learning, Meta Learning, Online Learning, Active Learning, and Ensemble Learning.
An Introduction to Transformers
A transformer is a deep learning architecture introduced by Google and rooted in the multi-head attention mechanism, as proposed in the seminal 2017 paper "Attention Is All You Need". In the realm of transformers, text undergoes conversion into numerical representations termed tokens, with each token then transformed into a vector via lookup from a word embeddingtable.
Transformers consist of several components. Firstly, tokenizers which converts text into tokens. Following this, a single embeddinglayer which converts both tokens and positions of the tokens into vectorrepresentations. Then Transformerlayers, which carry out repeated transformations on the vector representations extracting more and more linguistic information. These layers primarily comprise alternating attention and feedforward layers. Additionally, an optional un-embedding layer may be employed to revert the final vector representations back into a probability distribution over the tokens.
An Introduction to LLMs
from transformers import pipeline
import sys
classifier = pipeline('sentiment-analysis')
text = sys.argv[1]
result = classifier(text)[0]
print(f"The text \"{text}\" was classified as {result['label']} with a score of {round(result['score'], 4) * 100}%")
py <filename>.py "I prefer Bython over Python"
A Large Language Model (LLM) is a type of Artificial Intelligence algorithm that uses deep learning techniques to analyze and process massive amounts of text data. This allows LLMs to learn the relationships between words, phrases, and sentences. LLMs can be used in: Sentiment Analysis, Conversational AI and Chatbots, Content Summary, Text Generation and Translation.
Large Language Models encompass various types, including:
Zero-shot Model: These models, like GPT-3, are large and generalized, trained on diverse datasets to provide accurate results across various tasks without the need for additional training.
Fine-tuned or Domain-specific Models: Building upon zero-shot models, these are further trained on specific domains to enhance performance. OpenAI Codex, for instance, is tailored for programming tasks based on GPT-3.
Language Representation Model: Models like BERT utilize deep learning and transformer architectures, particularly suitable for Natural Language Processing (NLP) tasks, providing bidirectional representations of text.
Multimodal Model: Initially focused on text, multimodal models like GPT-4 can process both text and images, broadening their applicability to diverse datasets and tasks.
Introduction to GPTs
Generative Pre-Trained Transformers are a type of Large Language Models that are trained to generate outputs (inference) from inputs (prompts)n based on their training data (pre-training).
Generative Pre-trained Transformers, operate through a multi-step process:
Model Training: GPTs undergo pre-training on large and diverse dataset. This process involves machine learning techniques to compute patterns and probabilities within the data, enhancing the model's ability to generate accurate outputs.
Tokens Encoding and Decoding: Calculations in GPTs are performed on encoded tokens rather than raw character strings. Each word undergoes tokenization into smaller pieces (n-grams), that are used to compute the patterns and probabilities between the contents present in the training data. The encoding process is the process of converting the character strings into these tokens, and the decoding process is the process of converting these tokens back into the character strings
Transformers: These neural networks, utilized during both training and inference phases, establish relationships between tokens in the training data. They are used to calculate the relations between the tokens and generate the outputs based on these on learned patterns.
Inference: This is the process of generating outputs from inputs in a transformer. In this phase, the model generates outputs from inputs based on computed patterns and probabilities stored within the model. It rapidly computes the most probable output for a given prompt.
Prompting: A Prompt is an input that the model will process to generate the output, and it can be as simple as a single word or as complex as a full book. GPTs require prompting to execute tasks. Prompts vary widely in format, tailored to specific tasks or configurations. They serve as inputs guiding the model to generate meaningful outputs.
Context: GPTs operate within limited context sizes, typically ranging from a few hundred to a few thousand tokens. This constraint influences the model's ability to process and respond to prompts effectively.
Fine-tuning: To improve output accuracy and relevance, GPTs undergo fine-tuning processes. These involve training the model on specific datasets, incorporating human feedback, or utilizing targeted training approaches to align outputs with desired criteria.
RAG (Retrieval-Augmented Generation): RAG enhances GPTs by combining generative abilities with an external information retrieval system. It identifies relevant information from a large database, incorporating it into the model's query to improve precision and accuracy in responses. This technique offers efficiency and simplicity compared to passing extensive information in prompts or fine-tuning with new data
GPT Model Configuration Parameters
Agent description: This plays a crucial role in guiding the AI's behavior and response style. Different descriptions can set the tone, personality, and approach of the model. For instance, using a description such as "You are a creative storyteller" would prompt the AI to adopt a more imaginative and narrative style, whereas "You are a technical expert" might lead to more detailed and specific technical information in responses.
Temperature: This controls the randomness of the responses. A lower temperature (e.g., 0.0-0.3) results in more predictable, conservative responses, ideal for factual or specific queries. A higher temperature (e.g., 0.7-1.0) generates more creative and varied responses, useful for brainstorming or creative writing.
Max Tokens (Length): This sets the maximum length of the response. For concise, straightforward answers, a lower range (e.g., 50-100 tokens) is suitable. For more detailed explanations or narratives, a higher range (e.g., 150-500 tokens) can be used.
Frequency Penalty: This reduces the likelihood of the model repeating the same word or phrase. A lower setting (e.g., 0.0-0.5) allows some repetition, which can be useful for emphasis in writing or speech. A higher setting (e.g., 0.5-1.0) minimizes repetition, helpful for generating diverse and expansive content.
Presence Penalty: This discourages the model from mentioning the same topic or concept repeatedly. A lower setting (e.g., 0.0-0.5) is suitable for focused content on a specific topic, while a higher setting (e.g., 0.5-1.0) encourages the model to explore a wider range of topics, useful for brainstorming or exploring different aspects of a subject.
Top P (Nucleus Sampling): This determines the breadth of word choices considered by the model. A lower setting (e.g., 0.6-0.8) leads to more predictable text, good for formal or factual writing. A higher setting (e.g., 0.9-1.0) allows for more creativity and divergence, ideal for creative writing or generating unique ideas.
This journey wouldn't be possible without the Encode Club, a leading web3 education community. Their recent AI Coding Bootcamp 2024 equipped me with the knowledge to share with you. A special thanks goes out to my instructor, Matheus, for an incredible week of learning
Subscribe to my newsletter
Read articles from KIMATHI VICTOR directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by