Day 8. Python Libraries For DevOps
 Ashvini Mahajan
Ashvini Mahajan
List of Python modules for DevOps
osModuleThis module provides a way of using operating system functionality.
Basics of OS Module
#Import os module import os #Get Os name os.name #Get environment variables os.environ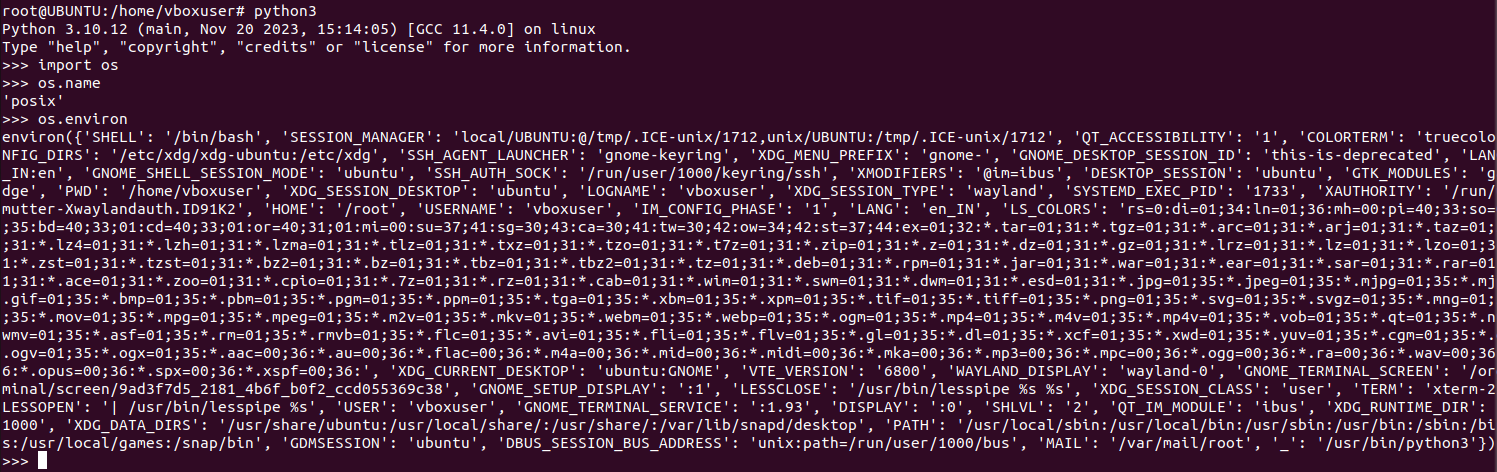
Current Working Directory
import os #Get current working directory cwd = os.getcwd() print("Current working directory",cwd) #changing current working directory def currentPath(): print("Current directory is",os.getcwd()) currentPath() os.chdir('../') currentPath()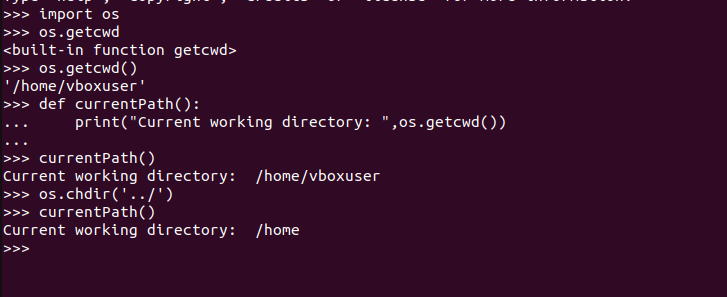
Creating directory
import os #Directory path directoryname="Hashnode" parentdirectory="/home/vboxuser/Documents" path =os.path.join(parentdirectory,directoryname) #Create directory os.mkdir(path) #Creating directoy with permissions mode=0o666 directoryname="HashnodeP" path=os.path.join(parentdirectory,directoryname) os.mkdir(path,mode) #Create director using mkdirs #mkdirs creates any missing directory in path directory="Ashwini" parentdirectory="/home/vboxuser/HashnodeMissing" path =os.path.join(parentdirectory,directory) os.mkdirs(path)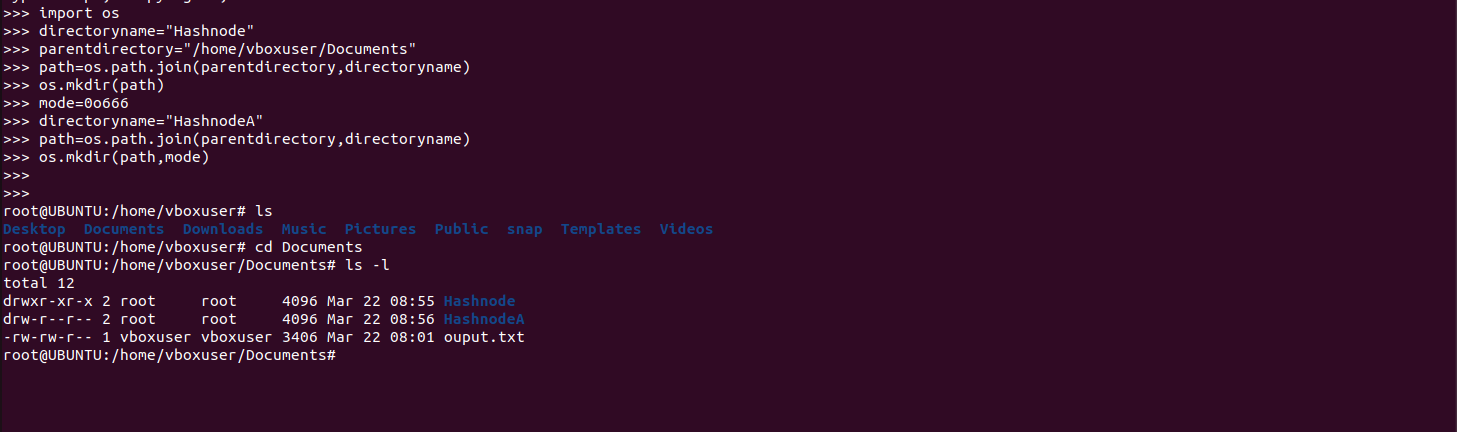

Listing out Files and Directories
import os #List out files/directories path = "/" dirlist = os.listdir(path) print("Files and directories in '", path, "' :") print(dirlist)
Deleting directories or Files
import os #Deleting files filename='file1.txt' directory="/home/vboxuser/Documents" path=os.path.join(directory,filename) os.remove(path) #Deleting directory directory="Hashnode" parent="/home/vboxuser/Documents" path=os.path.join(parent,directory) os.rmdir(path)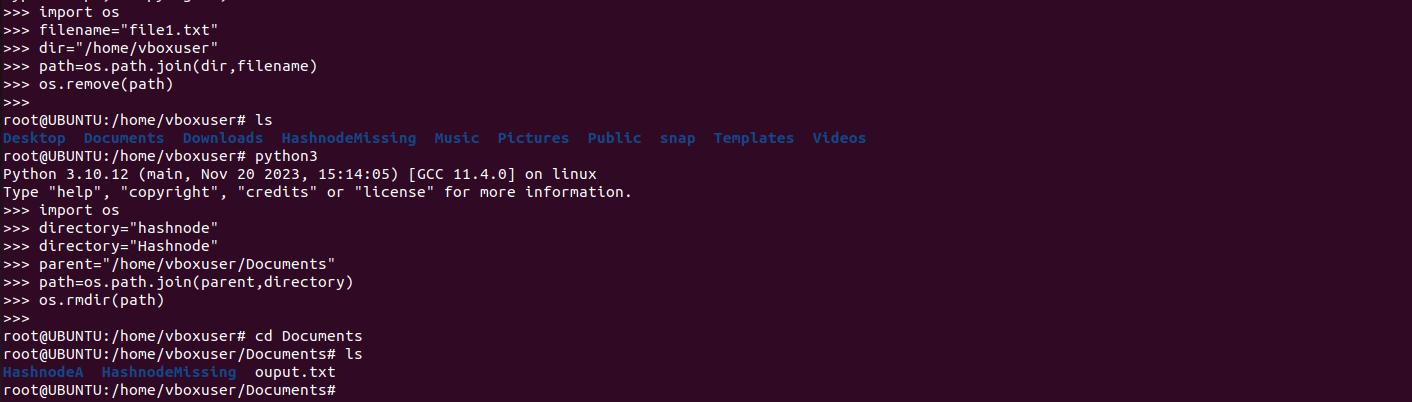
platformmodulePlatform module is used to access underlying platform data such as operating system, interpreter version information, and hardware. It has also been used to write cross-platform script.
import platform import sys #Various architecture information platform.architecture(executable=sys.executable, bits='', linkage='') #Returns machine type platform.machine() #returns computer network name platform.node() #Returns a single string identifying the underlying platform with as much useful information as possible. platform.platform(aliased=False,terse=False) #returns processor name platform.processor() #returns system release platform.release() #returns system os name platform.system() #Fairly portable uname interface. Returns containing six attributes: system, node, release, version, machine, and processor. platform.uname() #Returns a string identifying the compiler used for compiling Python. platform.python_compiler() #Returns the Python version as string. platform.python_version() #Returns a tuple (release, vendor, vminfo, osinfo) with vminfo being a tuple (vm_name, vm_release, vm_vendor) and osinfo being a tuple ( platform.java_ver(release='', vendor='', vminfo=('', '', ''), osinfo=('', '', '')) #return a tuple (release, version, csd, ptype) referring to OS release, version number, CSD level (service pack) and OS type (multi/single processor). platform.win32_ver(release='', version='', csd='', ptype='')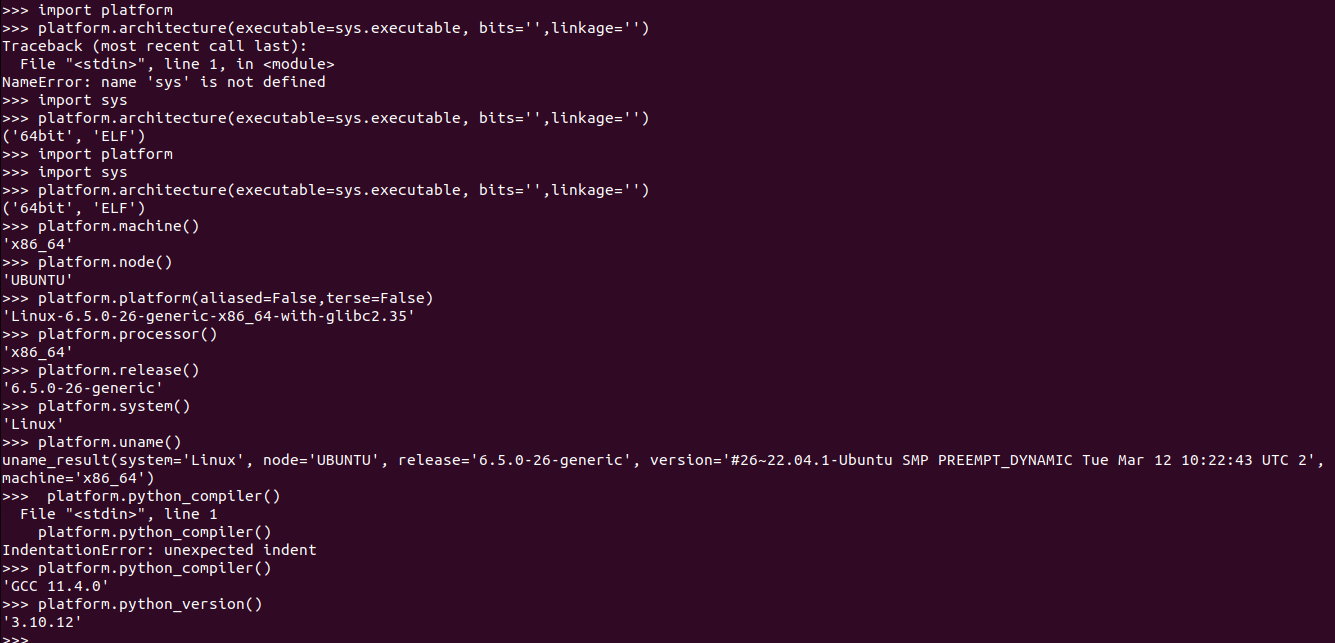
subprocessModuleThe Python
subprocessmodule is for launching child processes. The parent-childrelationship of processes is where the sub in the
subprocessname comes from. When you usesubprocess, Python is the parent that creates a new child process.import subprocess #Run the command with args subprocess.run(["ls","-l"]) #It is employed to execute a command in a separate process and wait for its completion result =subprocess.call(["python3","--version"]) if result ==0: print("Command executed") else: print("command failed")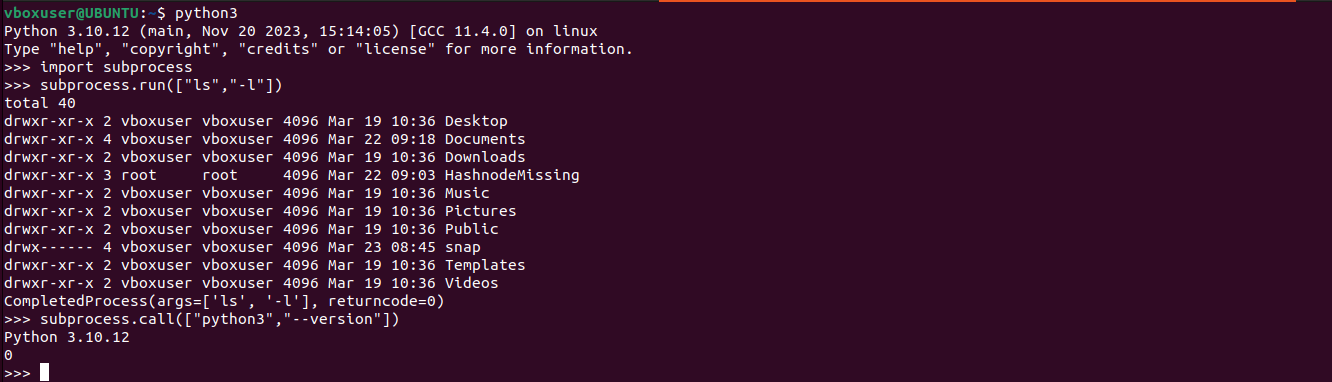
check_outputRun command with arguments and return its output.
If the return code was non-zero it raises a
CalledProcessError. TheCalledProcessErrorobject will have the return code in thereturncodeattribute and any output in theoutputattribute.import subprocess try: ans = subprocess.check_output(["python3", "--version"], text=True) print(ans) except subprocess.CalledProcessError as e: print(f"Command failed with return code {e.returncode}")
pipeTo start a new process, or in other words, a new subprocess in Python, you need to use the
Popenfunction call. It is possible to pass two parameters in the function call.stdin,stdoutandstderrspecify the executed program’s standard input, standard output and standard error file handles, respectively.import subprocess process = subprocess.Popen(['cat', 'example.py'], stdout=PIPE, stderr=PIPE) stdout, stderr = process.communicate() print(stdout)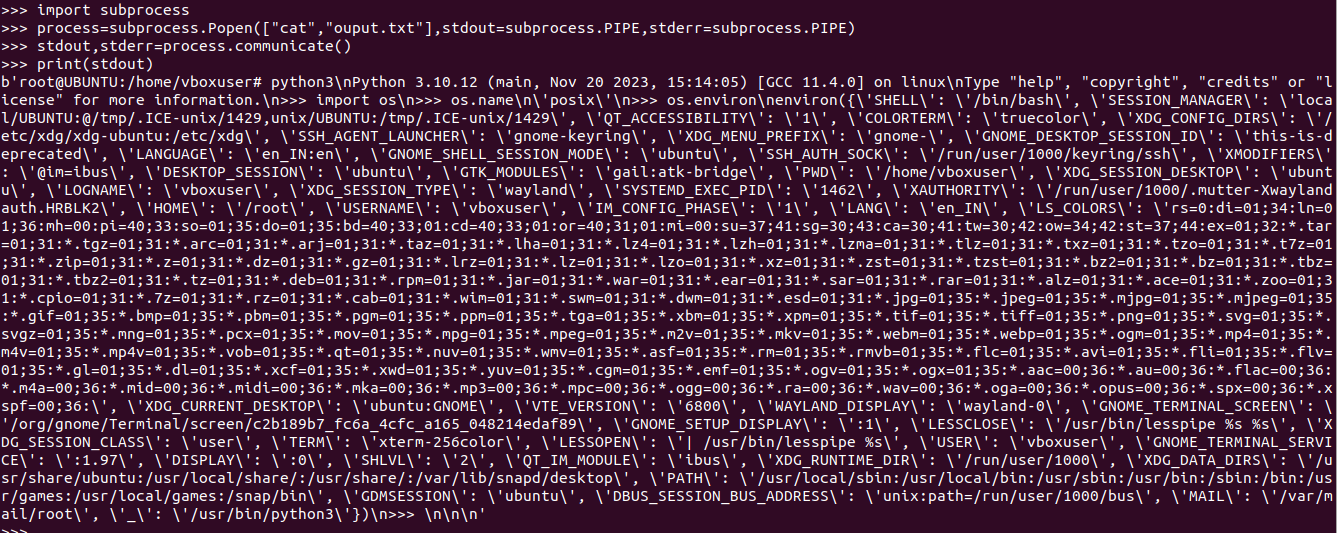
sysModuleThis module provides access to some variables used or maintained by the interpreter and to functions that interact strongly with the interpreter.
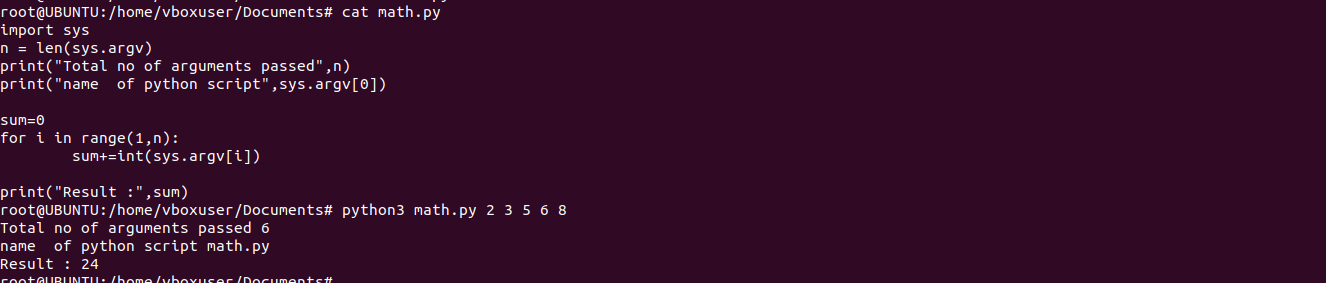
import sys #Version of python interpreter sys.version #Get input directly from the command line using stdin. #save this to file Hash.py and run it using python3 Hash.py command print("Enter message here:") for line in sys.stdin: line= line.rstrip(): print(f"Input :{line}") #Display output directly to the screen console using stdout sys.stdout.write("Hashnode") #Its error messages go to stderr print('This is an error message', file=sys.stderr) #Write stderr to file sys.stderr = open('err.txt', 'w') print('This is an error message', file=sys.stderr) #List of command line arguments passed to script. #Save this code as math.py and run it using python3 math.py n = len(sys.argv) print("Total arguments passed:", n) print("\nName of Python script:", sys.argv[0]) print("\nArguments passed:", end = " ") for i in range(1, n): print(sys.argv[i], end = " ") Sum = 0 for i in range(1, n): Sum += int(sys.argv[i]) print("\n\nResult:", Sum) #exit from program using sys.exit salary=10000 if salary <=10000: sys.exit("Salary is less than 10000")


psutilModulepsutil (process and system utilities) is a cross-platform library for retrieving information on running processes and system utilization (CPU, memory, disks, network, sensors) in Python. It is useful mainly for system monitoring, profiling and limiting process resources and management of running processes.
CPU.
import psutil #CPU #psutil.cpu_times()- This function gives system CPU times as a named tuple. #Parameters: #user – time spent by normal processes executing in user mode #system – time spent by processes executing in kernel mode #idle – time when system was idle #nice – time spent by priority processes executing in user mode #iowait – time spent waiting for I/O to complete. This is not accounted in idle time counter. #irq – time spent for servicing hardware interrupts #softirq – time spent for servicing software interrupts #steal – time spent by other operating systems running in a virtualized environment #guest – time spent running a virtual CPU for guest operating systems under the control of #the Linux kernel psutil.cpu_times() #psutil.cpu_percent(1) -current system CPU utilization in percentage print(psutil.cpu_percent(1)) #It counts logical or physical core in system using logical=true/false flag print("Number of cores in system", psutil.cpu_count(logical=True)) #psutil.cpu_stats() -This function gives CPU statistics as a named tuple. The statistics includes : #ctx_switches – number of context switches since boot. #interrupts – number of interrupts since boot. #soft_interrupts – number of software interrupts since boot. #syscalls – number of system calls since boot. Always set to 0 in Ubuntu. print("CPU Statistics", psutil.cpu_stats()) #psutil.cpu_freq() – This gives CPU frequency as a tuple that includes current, min and #max frequencies expressed in Mhz. print(psutil.cpu_freq()) #psutil.getloadavg() – This function gives the average system load print(psutil.getloadavg())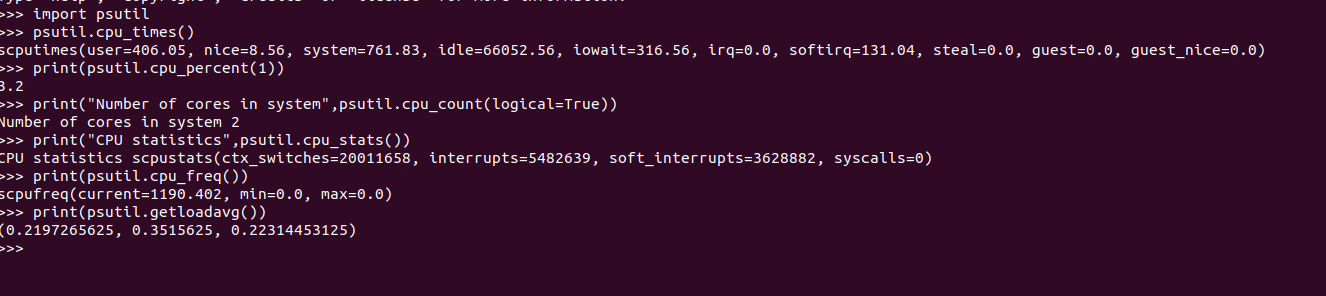
Memory
import psutil #Memory #psutil.virtual_memory() - This gives information about physical memory psutil.virtual_memory() #psutil.swap_memory() - Details of swap memory psutil.swap_memory()
Disks
import psutil #Disks #psutil.disk_partitions() - details of all mounted disk partitions like device, #mount point and filesystem type. psutil.disk_partitions() #psutil.disk_usage('/') -details of disk usage psutil.disk_usage('/')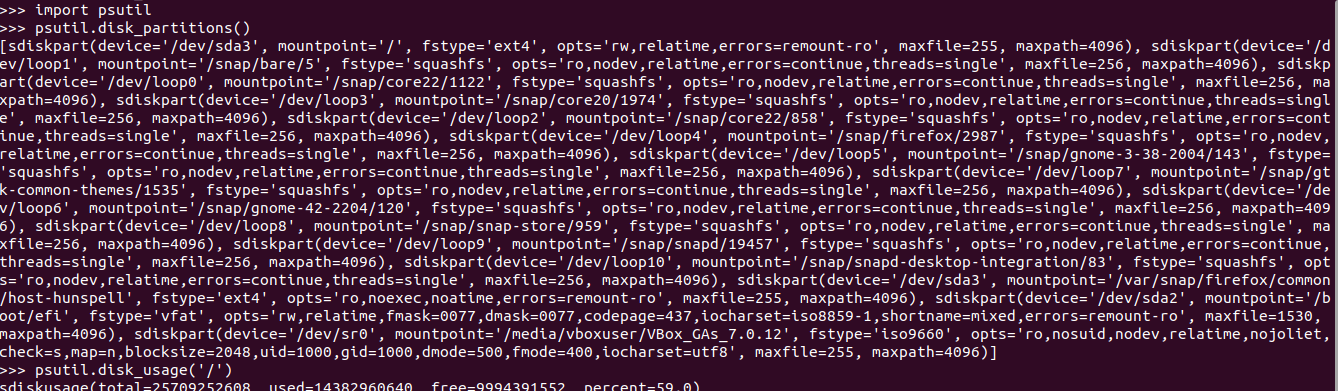
Network
import psutil #psutil.net_io_counters() - details of network psutil.net_io_counters() #psutil.net_connections(kind='tcp') - list of socket connections psutil.net_connections(kind='tcp') #psutil.net_if_addrs() - get address of each network interface card psutil.net_if_addrs()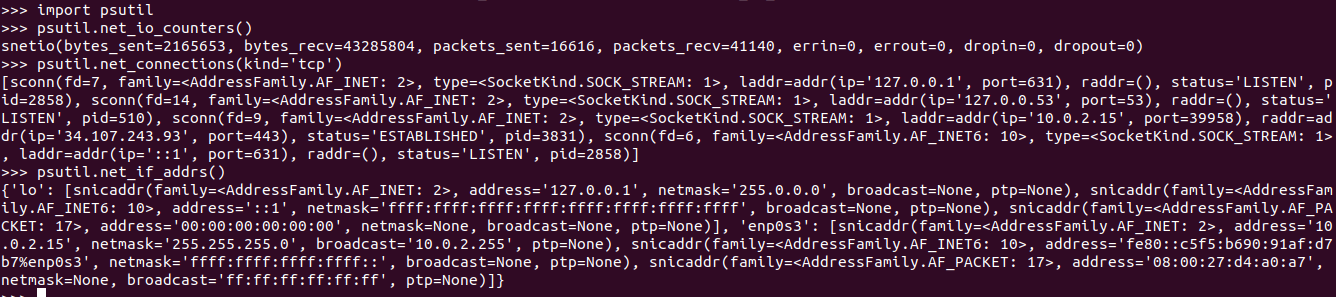
Other system info
import psutil #psutil.boot_time() -get system boot time psutil.boot_time() #psutil.users() - list of users connected on system psutil.users()
reModuleThis module provides regular expression matching operations.A regular expression (or RE) specifies a set of strings that matches it; the functions in this module let you check if a particular string matches a given regular expression
Characters used int pattern:
.- this matches any character except a newline.^- Matches start of string$- Matches end of string*- Any number of repetitions+- One or more repetitions?- Zero or one repetitions\- Escape special characters[]- Used to indicate set of characters|- Means OR ,A|Beither A or B{}- Indicate the number of occurrences of a preceding regex to match.()- Group of regex\A- Matches only at the start of string\b-Matches the empty string, but only at the beginning or end of a word.\B- Matches the empty string, but only not at the beginning or end of a word.\d- Matches any decimal digit\D- Matches which is not a decimal digit\s- Matches whitespace character\S- Matches not a whitespace character\w- Matches word characters\W- Matches not word characters\Z- Matches only at the end of stringFunctions
import re #re.findall() - find all occurences of pattern string = "My sisters age is 45 and my age is 30" pattern="\d+" match = re.findall(pattern,string) print(match)
import re #expression pattern into a regular expression object, #which can be used for matching using its match() p =re.compile('[a-e]') match = p.findall("This is Hashnode blog Day 8") print(match)
import re #re.compile(pattern, flags=0) - Compile a regular #re.split() - split string by occurences of characters print(re.split('\W+', 'set width=20 and height=10')) print(re.split('\d+', 'set width=20 and height=10'))
import re #re.search() - Scan through string looking for the first location where #the regular expression pattern #produces a match, and return #a corresponding Match string ="Day 8. Python Libraries for DevOps" pattern= "(\w+$) (\d+)" match= re.search(pattern,string) if match != None: print("Match Index :",match.start(),match.end()) print("Day :",match.group(0)) else print("Pattern not found")
import re #re.sub() - Return the string obtained by replacing the leftmost #non-overlapping occurrences of pattern in string by the replacement re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE) #re.subn() - It is same as re.sub() except it returns count of #the total of replacement and the new string rather than just the string. #re.escape() - Escape special characters in pattern. print(re.escape('https://www.python.org'))
scapyModuleScapy is a powerful Python-based interactive packet manipulation program and library.
It is able to forge or decode packets of a wide number of protocols, send them on the wire, capture them, store or read them using pcap files, match requests and replies, and much more. It is designed to allow fast packet prototyping by using default values that work.
from scapy.all import * #stacking layers #The / operator has been used as a composition operator between two layers. #When doing so, the lower layer can have #one or more of its defaults fields overloaded according to the upper layer. #src - source IP #dst - destination IP #Show IP fields ls(IP, verbose=True) packet = Ether()/IP(dst="www.hashnode.com")/TCP() packet.summary()from scapy.all import * #sniff - Sniffing the network is as straightforward as sending and #receiving packets. The sniff() function returns a list of Scapy packets sniff(count=2, prn=lambda p: p.summary())
from scapy.all import * #Send/Receive packet #The sr1() function sends a packet and returns the corresponding answer. #srp1() does the same for layer two packets, i.e. Ethernet. p = sr1(IP(dst="8.8.8.8")/UDP()/DNS(qd=DNSQR())) p[DNS].an
requestsandurlib3ModuleThe requests module is used to send Http request.
import requests #get() method sends a GET request to a web server and #it returns a response object.It is used to get resource data response = requests.get("https://hashnode.com/") print(f"{response.status_code}: {response.reason}")
import requests #head() method sends a HEAD request to a web server and #it returns a response object.It is used to get header information response = requests.head("https://hashnode.com") print(response.status_code) print(response.headers["Content-Type"]) print(response.text)
import requests #post() method sends a POST request to a web server #and it returns a response object.It is used to create or update resource data = { "blog": "Day 9.Python Projects" } response = requests.post("https://hashnode.com", data=data) print(f"{response.status_code}: {response.reason}")
import requests #put() method sends a PUT request to a web server #and it returns a response object.It is used to update resource json = { "blog": "Day 9.Python Projects" } response = requests.put("https://httpbin.org/put", json=json) print(response.json()["json"])
import requests #delete() method sends a DELETE request to a web server #and it returns a response object.It is used to delete resource response = requests.put("https://www.google.com") print(f"{response.status_code}: {response.reason}")
jsonModuleIt is a lightweight data interchange format inspired by JavaScript object literal syntax. It is mainly used for storing and transferring data between the browser and the server.
import json #json.loads - It converts json data to python object students='{"John":35,"Jane":45,"Kate":42}' student_dict=json.loads(students) print(student_dict)
import json #json.dumps - It convert python object to json data students_dict={"John":35,"Jane":45,"Kate":42} students_json=json.dumps(students_dict) print(students_json)
boto3ModuleBoto3 is the Amazon Web Services (AWS) Software Development Kit (SDK) for Python, which allows Python developers to write software that makes use of services like Amazon S3 and Amazon EC2.
clientClient is a low level class object. For each client call, you need to explicitly specify the targeting resources, the designated service target name must be pass long. You will lose the abstraction ability.
import boto3 #create s3 bucket s3 = boto3.resource('s3') bucket_name="DemoBucket" s3.create_bucket(Bucket=bucket_name) #upload file to s3 bucket filename="file1.txt" with open(file_name, 'rb') as file: s3.upload_fileobj(file, bucket_name, file_name) # Download a file from the bucket download_file_name = 'downloaded-file.txt' with open(download_file_name, 'wb') as file: s3.download_fileobj(bucket_name, file_name, file) #list all buckets response=s3.list_buckets() for bucket in response["Buckets"] print(bucket["Name"])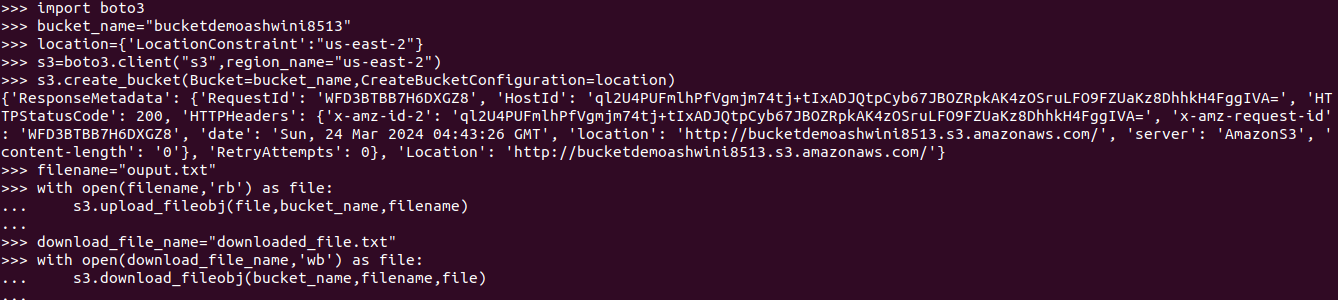

resourceThis is the high-level service class recommended to be used. This allows you to tied particular AWS resources and passes it along, so you just use this abstraction.
import boto3 #create s3 bucket s3 = boto3.resource('s3') bucket_name="DemoBucket" s3.create_bucket(Bucket=bucket_name) #upload file to s3 bucket filename="file1.txt" with open(file_name, 'rb') as file: s3.Bucket(bucket_name).put_object(Key=file_name,Body=file) # Download a file from the bucket download_file_name = 'downloaded-file.txt' with open(download_file_name, 'wb') as file: s3.Bucket(bucket_name).download_file(file_name, file) #list all buckets for bucket in s3.Bucket(bucket_name).objects.all() print(bucket)

sessionSession where to initiate the connectivity to AWS services. E.g. following is default session that uses the default credential profile
~/.aws/credentialsimport boto3 #create session session=boto3.Session(aws_access_key_id="Your_access_key", aws_secret_access_key="Your_Scret_key",resgion_name="us-east-1") #create s3 s3=session.client("s3") #List all buckets response=s3.list_buckets() #print all buckets for bucket in response["Buckets"]: print(bucket["Name"])
yamlModulePyYAML is a YAML parser and emitter for Python.
YAML’s block collections use indentation for scope and begin each entry on its own line. Block sequences indicate each entry with a dash and space ( "
-"). Mappings use a colon and space (":") to mark each mapping key: value pair.
import yaml #Python object names_yaml = """ - 'eric' - 'justin' - 'mary-kate' """ #Convert yaml document to python object names = yaml.safe_load(names_yaml) #dump converts python object into yaml file with open('names.yaml', 'w') as file: yaml.dump(names, file) #print file content print(open('names.yaml').read())

Subscribe to my newsletter
Read articles from Ashvini Mahajan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ashvini Mahajan
Ashvini Mahajan
I am DevOps enthusiast and looking for opportunities in DevOps.