Exploring Chaos Engineering: The Path to System Resilience in DevOps
 Ambuz Ranjan
Ambuz RanjanTable of contents
- Introduction to Chaos Engineering
- The Need for Chaos Engineering
- Principles of Chaos Engineering
- Getting Started with Chaos Engineering
- Chaos Engineering Tools and Platforms
- Planning and Designing Chaos Experiments
- Implementing Chaos Experiments
- Conducting the Experiment
- Analyzing Results
- Advanced Chaos Engineering Techniques
- Real-Life Examples of Chaos Engineering
- Best Practices and Common Pitfalls in Chaos Engineering
- The Future of Chaos Engineering
- Conclusion

Introduction to Chaos Engineering
In today's digital age, where services and applications underpin nearly every aspect of our lives, the resilience of systems against failures isn't just desirable—it's absolutely critical. This imperative leads us to a revolutionary discipline known as Chaos Engineering.

What is Chaos Engineering?
Chaos Engineering can be likened to a vaccine for software systems. Just as a vaccine introduces a controlled dose of a virus to stimulate the body's immune response, Chaos Engineering introduces controlled disruptions to a system to fortify its resilience against unforeseen failures. It's a disciplined approach to identifying failures before they escalate into outages, ensuring systems are battle-tested and robust.
Historical Context
The concept took root at Netflix, a company that rapidly evolved its infrastructure to support streaming services on a global scale. They introduced Chaos Monkey, a tool designed to randomly terminate instances in production to ensure that engineers implemented their services to be resilient to instance failures.
Importance in DevOps
DevOps practices emphasize rapid development cycles, continuous integration/continuous deployment (CI/CD), and operational stability. Chaos Engineering slots perfectly into this paradigm by ensuring that as new features are deployed, the system's resilience is not compromised.
Enhancing Reliability
Reliability is the cornerstone of user trust and business continuity. In a DevOps context, where rapid deployment cycles and continuous integration are the norms, maintaining and improving system reliability amidst frequent changes is a significant challenge. Chaos Engineering addresses this challenge head-on.
Identifying and Mitigating Risks Proactively
Chaos Engineering allows teams to identify potential points of failure in a system before they impact users. By intentionally injecting failures into the system (such as killing processes, introducing network latencies, or simulating database outages), teams can observe how their systems react, identify weaknesses, and implement improvements. This proactive approach to identifying and mitigating risks is far more effective than reacting to issues post-incident, as it allows for more thoughtful and less rushed solutions.
Ensuring High Availability
High availability is critical for businesses to meet their service level agreements (SLAs) and maintain customer satisfaction. Chaos Engineering tests the resilience of systems, ensuring that they can handle unexpected disruptions without significant downtime. Techniques such as redundancy, failover mechanisms, and graceful degradation are validated under real-world conditions, guaranteeing that systems remain available even under duress.
Continuous Learning and Improvement
The iterative nature of Chaos Engineering aligns perfectly with the DevOps philosophy of continuous learning and improvement. Each experiment provides insights not just into specific vulnerabilities but also into how the system behaves under stress. These insights inform ongoing development and operations work, ensuring that reliability is baked into the system at every level.
Fostering Innovation
Innovation thrives in environments where failure is seen as an opportunity to learn rather than a setback. Chaos Engineering creates such an environment by normalizing failures and providing a safe framework to learn from them.
Creating a Culture of Resilience
By integrating Chaos Engineering practices into the DevOps lifecycle, organizations foster a culture that values resilience. This cultural shift empowers developers to experiment boldly with new features and technologies, knowing that the system's resilience is continually assessed and improved. Such a culture not only accelerates innovation but also attracts talent looking to work at the cutting edge of technology.
Encouraging Cross-Functional Collaboration
Chaos Engineering experiments require collaboration across development, operations, and sometimes even business teams. This cross-functional collaboration breaks down silos, leading to innovative solutions that might not have emerged within more isolated teams. It also ensures that everyone has a stake in the system's reliability, further embedding resilience into the organizational DNA.
Operational Efficiency
Operational efficiency is about doing more with less—less time, fewer resources, and minimal disruption. Chaos Engineering directly contributes to this by reducing downtime, streamlining incident response, and optimizing resource usage.
Reducing Downtime and Incident Response Time
By identifying and addressing failures before they occur, Chaos Engineering significantly reduces the likelihood and impact of downtime. Moreover, teams become more adept at incident response through practice with controlled experiments, leading to quicker resolution times when real incidents occur. This efficiency minimizes the economic impact of outages and frees up resources for value-adding activities.
Optimizing Resource Usage
Chaos Engineering can also uncover opportunities to optimize resource usage, leading to cost savings and improved performance. For example, experiments may reveal that a service can maintain its performance levels with fewer resources than previously allocated, or they may identify underutilized resources that can be reallocated or decommissioned.
Learning from Failure to Avoid Repetition
Each chaos experiment is a learning opportunity. By systematically documenting and analyzing the outcomes of these experiments, teams build a knowledge base that helps avoid repeating past mistakes. This continuous learning loop not only improves system resilience but also contributes to a more efficient and effective DevOps practice.
The Need for Chaos Engineering

As the digital ecosystem evolves, the complexity of software systems has escalated dramatically. This complexity, while enabling advanced functionalities and interconnected services, introduces a myriad of potential failure points. Here, we delve into the necessity of Chaos Engineering in navigating the labyrinth of modern systems, ensuring their resilience, and why it's particularly crucial in today’s technology-dependent world.
Unveiling the Complexity of Modern Systems
Modern software systems are not monoliths; they are distributed networks of microservices, APIs, cloud-based services, and third-party integrations. This intricate mesh, while flexible and scalable, is also fraught with challenges:
Interdependencies: Services depend on other services to function. A failure in one can cascade, causing widespread disruption.
Diverse Infrastructure: Systems span across on-premise servers, cloud platforms, and edge devices, each adding layers of complexity.
Dynamic Environments: Continuous deployment and integration mean systems are constantly updated, changing the failure landscape.
Given this complexity, traditional testing methods fall short. They often cannot replicate the unpredictable nature of production environments or foresee how systems will react under stress. This unpredictability is where Chaos Engineering steps in, offering a proactive approach to uncovering potential failures.
System Resilience and Reliability: The Cornerstones of Digital Trust
In a world where downtime can lead to significant financial loss and damage to reputation, resilience and reliability are paramount. Here’s why:
Customer Expectations: Today’s users expect services to be available around the clock. Even minor disruptions can lead to dissatisfaction and churn.
Economic Impact: Downtime is costly. According to Gartner, the average cost of IT downtime is approximately $5,600 per minute, which varies by industry.
Competitive Advantage: Systems that are resilient to failures can maintain a continuous service delivery, keeping a step ahead of competitors.
The Role of Chaos Engineering in Enhancing Resilience
Chaos Engineering is not merely about causing disruptions; it’s about understanding a system's behavior under various conditions to improve its robustness. By systematically introducing faults into the system, teams can:
Identify Weaknesses: Discover hidden bugs or issues that could lead to larger problems.
Test Failover and Recovery: Ensure that backup systems and recovery processes work as expected during a failure.
Validate Monitoring and Alerts: Confirm that monitoring tools and alerts promptly and accurately notify the team of issues.
Improve Documentation and Knowledge: Update documentation and spread knowledge on system behavior under failure scenarios, preparing teams better for real incidents.
Real-World Importance
The necessity of Chaos Engineering is underscored by high-profile outages experienced by major companies. For example, in 2019, a significant cloud service provider faced an outage due to an overloaded database, affecting numerous businesses and services. Had Chaos Engineering been employed, it’s conceivable that the vulnerability could have been identified and mitigated beforehand, minimizing or even preventing the outage.
Principles of Chaos Engineering
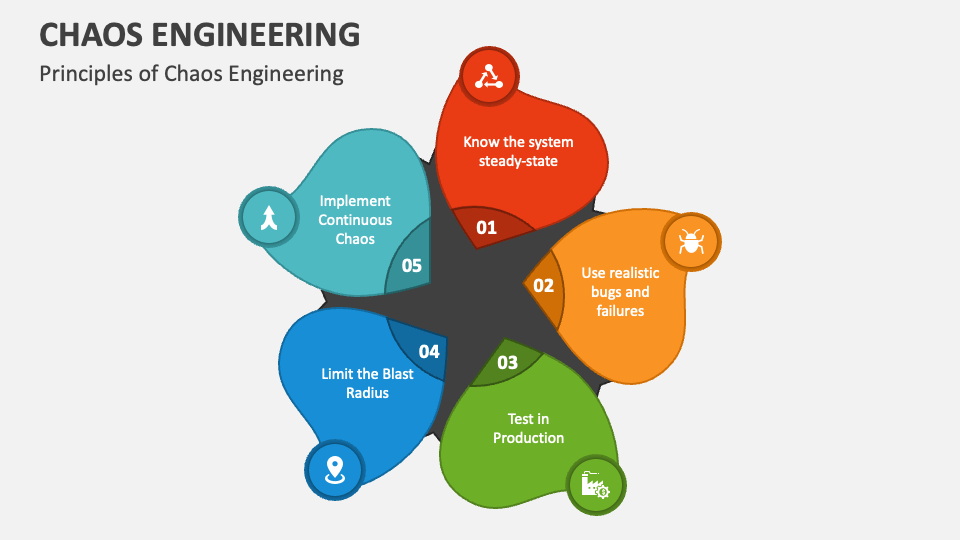
The principles of Chaos Engineering form a methodological framework for improving system resilience through proactive testing and experimentation. This approach is designed to expose weaknesses before they become critical failures, ensuring systems can withstand unexpected disruptions. Here's a breakdown of the core principles you mentioned:
Define a 'Steady State'
The steady state is essentially the "normal" for a system—a benchmark of what its healthy performance looks like under typical conditions. It's the baseline from which any deviation, due to introduced chaos or real-world events, is measured. This principle emphasizes the importance of understanding and quantifying what "good" looks like in a system's operation, making it easier to identify when something is amiss.
Hypothesize That This Steady State Will Continue in Both Control and Experimental Groups
Before starting experiments, there's an assumption made that the steady state will not change significantly in either the control group (where no variables are changed) or the experimental group (where chaos is introduced). This hypothesis serves as a null hypothesis in the experiment, setting a baseline expectation that any significant deviation from the steady state in the experimental group can be attributed to the introduced chaos.
Introduce Variables That Reflect Real-World Events
This principle is about making the chaos experiments as relevant and realistic as possible by simulating events that could actually happen. These might include hardware failures, network latency, or spikes in traffic. The goal is to see how these real-world scenarios affect the system's steady state, providing insights into potential vulnerabilities or areas for improvement.
Run Experiments in Production
While it might seem risky, conducting chaos experiments in a production environment is considered the gold standard. This is because it's the only way to truly understand how a system behaves under real conditions. Running experiments in a test environment can still be valuable, but it may not fully capture how systems interact or how they're affected by real-world traffic patterns and user behaviors.
Automate Experiments to Run at Scale
Automation is key to conducting chaos experiments at scale and ensuring consistency across tests. As systems grow in complexity and size, manually running experiments becomes impractical. Automation tools and platforms can help run these experiments regularly, allowing for continuous verification of system resilience and the identification of potential issues before they escalate.
Minimize the 'Blast Radius'
Starting small with chaos experiments helps ensure that any negative impact is contained and manageable. This cautious approach allows teams to learn about their system's behavior under stress without risking significant outages or degradation in user experience. As confidence in the system's resilience grows, the scope of experiments can be gradually expanded, always with an eye towards minimizing potential harm.
Together, these principles guide the practice of Chaos Engineering, helping organizations to build more resilient systems by embracing and learning from failure.
Getting Started with Chaos Engineering

Getting started with Chaos Engineering in your organization is a strategic move towards enhancing system resilience and reliability. It involves a deliberate, structured approach to introducing, managing, and learning from controlled disruptions. Below is a detailed roadmap to help you establish a comprehensive chaos engineering practice:
Building a Chaos Engineering Team
A successful Chaos Engineering initiative relies on a dedicated team with diverse roles and expertise. This team will drive the process, from planning experiments to implementing improvements based on the findings. The team should include:
Chaos Champion: This person is the driving force behind the Chaos Engineering initiatives within the organization, advocating for its principles and ensuring that it gains the necessary support and resources. They facilitate communication between different stakeholders and help in overcoming any resistance to the adoption of chaos engineering practices.
Chaos Architect: Responsible for designing and strategizing the chaos experiments, the Chaos Architect ensures that the chaos experiments align with both the technical aspects of the system and the business objectives. They work closely with system architects to understand the system's intricacies and potential points of failure.
Chaos Engineers: These are the hands-on practitioners who design, execute, and monitor the experiments. They possess a deep technical understanding of the system, its environment, and how to safely introduce chaos without causing unintended damage.
Site Reliability Engineers (SREs): SREs play a crucial role in maintaining system reliability and uptime. They apply the insights gained from chaos experiments to improve operational practices, enhance monitoring, and refine incident response strategies.
Product Owners and Development Teams: Engaging with the chaos engineering process, these stakeholders understand the impact of system changes on resilience. Their involvement ensures that resilience becomes an integral part of the development lifecycle, from design through deployment.
Identifying Targets for Chaos Experiments
The selection of targets for chaos experiments is a critical step that requires careful consideration:
Criticality to Business Operations: Prioritize components critical to the customer experience and business operations. This focus helps ensure that the chaos engineering efforts yield meaningful improvements in the areas that matter most.
Previous Outages or Failures: Analyzing historical data on system outages or failures can highlight vulnerable components that may benefit from targeted chaos experiments. These are areas where resilience can be significantly improved.
Complexity and Interdependencies: Components with high complexity or numerous interdependencies are often prone to unpredictable behavior under stress. These make excellent candidates for chaos experiments, as they can reveal hidden failure modes.
Creating a Chaos Engineering Process
Developing a structured process is essential for the systematic conduct of chaos experiments:
Planning: Begin with clear objectives and well-defined parameters. Determine the scope of each experiment, including the systems, components, and conditions to be tested.
Hypothesis Formation: Develop a hypothesis that predicts the outcome of the experiment based on the current understanding of the system. This step is crucial for comparing expected versus actual outcomes.
Experimentation: Execute the chaos experiment as planned, ensuring to monitor the system closely for any deviations from normal behavior. This phase should be carried out with the utmost care to prevent unintended consequences.
Observation: Collect and document observations on how the system responded to the introduced chaos. Note any deviations from expected behavior.
Analysis: Analyze the collected data to assess whether the system's response aligned with the hypothesis. Identify any resilience gaps or unexpected vulnerabilities that were exposed.
Learning and Improvement: Translate the insights gained from the analysis into actionable improvements. This could involve architectural changes, code modifications, or enhancements to monitoring and alerting systems.
Repeat: Embrace Chaos Engineering as an ongoing practice, not a one-time event. Regularly scheduled experiments, aligned with system changes and updates, ensure continued resilience and reliability.
Chaos Engineering Tools and Platforms
To effectively implement Chaos Engineering, it's crucial to leverage the right tools and platforms. These tools enable the controlled introduction of chaos into systems, allowing teams to observe effects and glean insights without causing undue disruption to operations. This section dives into the most prominent tools and platforms in Chaos Engineering, detailing their features, use cases, and how they fit into a comprehensive resilience strategy.
Chaos Monkey and the Simian Army
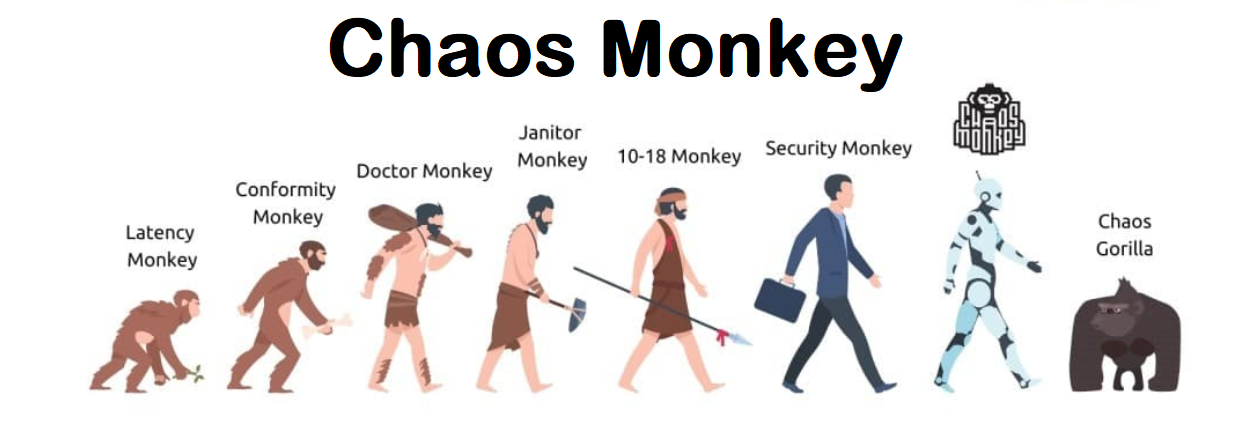
Developed by Netflix, Chaos Monkey and the broader Simian Army suite represent some of the earliest and most influential tools in Chaos Engineering. They are designed to test the resilience of Amazon Web Services (AWS) environments but have principles applicable across various cloud and on-premise environments.
Chaos Monkey: Randomly terminates virtual machine instances and containers to test how remaining systems cope with the loss, encouraging the design of fault-tolerant services.
Latency Monkey: Introduces communication delays to simulate system latency and observe how services respond, highlighting timeouts and retry mechanisms.
Conformity Monkey: Identifies instances not adhering to best practices and shuts them down, promoting adherence to operational standards.
These tools are particularly effective in large, distributed systems where understanding the impact of individual component failures on the overall system is crucial.
Gremlin
Gremlin provides a more controlled, sophisticated approach to Chaos Engineering, offering a wide range of attacks including resource consumption, network manipulation, and state disruption. Its features include:
Safety Measures: Gremlin includes several safety mechanisms, such as halts and rollbacks, making it easier to minimize the blast radius of experiments.
Comprehensive Attack Types: From CPU and memory to disk I/O and network latency, Gremlin allows for precise targeting of system components.
Scenario Design: Users can create complex scenarios that mimic real-world outages, providing deep insights into system weaknesses and recovery strategies.
Gremlin's platform is suitable for organizations at various stages of their Chaos Engineering journey, from beginners to advanced practitioners.
LitmusChaos, Chaos Mesh, and PowerfulSeal
These tools are tailored for Kubernetes environments, reflecting the growing adoption of container orchestration systems in modern infrastructure.
LitmusChaos: Offers a broad range of chaos experiments for Kubernetes, making it easier to test and improve the resilience of containerized applications and microservices architectures.
Chaos Mesh: A cloud-native Chaos Engineering platform that provides comprehensive tools for performing chaos experiments in Kubernetes environments, focusing on making these experiments as realistic as possible.
PowerfulSeal: Inspired by Chaos Monkey, PowerfulSeal is designed to test the resilience of Kubernetes clusters, adding scenarios that specifically target the peculiarities of container orchestration.
These tools underscore the importance of Chaos Engineering in ensuring the reliability of microservices and cloud-native applications, particularly in dynamic, scalable environments.
Selecting the Right Tool
Choosing the appropriate tool depends on several factors:
Environment Specificity: The choice may depend on whether your infrastructure is cloud-based, on-premise, or a hybrid, and whether you're using containerization technologies like Kubernetes.
Complexity and Scale of Your Systems: Larger, more complex environments may benefit from more sophisticated tools that offer granular control and safety features.
Organizational Maturity: Companies new to Chaos Engineering might start with simpler tools, gradually moving to more complex scenarios as their comfort level increases.
Integrating Tools into Your Workflow
Successful integration of Chaos Engineering tools into your workflow involves:
Pilot Testing: Start with non-critical systems or staging environments to get familiar with the tool's capabilities and effects.
Incorporate into CI/CD Pipelines: Automate chaos experiments as part of your deployment process to continuously test and improve resilience.
Monitoring and Alerting: Ensure comprehensive monitoring and alerting mechanisms are in place to track the impact of chaos experiments in real-time.
Real-Life Application
Gremlin at Twilio: Twilio, a cloud communications platform, utilizes Gremlin to conduct Chaos Engineering experiments across its microservices architecture. By systematically introducing failures, Twilio enhances its systems' resilience, ensuring high availability and reliability for its communications services.
Planning and Designing Chaos Experiments

The planning and design phase is crucial in Chaos Engineering, laying the groundwork for effective and insightful experiments. This stage involves a clear understanding of your system's architecture, identifying key metrics for gauging system health, and formulating hypotheses on how your system would react under different scenarios of induced chaos. Here, we explore the comprehensive approach to planning and designing chaos experiments that yield actionable insights and contribute to building more resilient systems.
Understanding Your System
Before embarking on chaos experiments, it's vital to have a deep understanding of your system's architecture and operational dynamics. This understanding should encompass:
Service Dependencies: Map out the dependencies between services and how they communicate. This helps in identifying potential points of failure and their cascading effects.
Critical Workflows: Identify critical paths in your system that are essential for business operations. Understanding these workflows helps prioritize where to start with chaos experiments.
Baseline Metrics: Establish baseline metrics that represent the normal operating range of your system. These metrics could include throughput, latency, error rates, and system resource utilization.
Identifying System Weaknesses
The next step is to identify potential weaknesses in your system. This can involve:
Review of Past Incidents: Analyze past incidents and outages to identify components that have historically been points of failure.
Stress Testing: Conduct stress tests to find the limits of your system's capacity.
Consultation with Teams: Engage with development, operations, and business teams to gather insights on areas they perceive as vulnerable.
Formulating Hypotheses
With an understanding of your system's architecture and potential weaknesses, you can begin to formulate hypotheses. A hypothesis in Chaos Engineering is a statement predicting the outcome of an experiment based on the induced chaos. For example, "If service X fails, then service Y will take over without impacting user experience."
Designing Chaos Experiments
Designing a chaos experiment involves specifying the variables you will manipulate, defining the scope, and determining the metrics for evaluating the experiment's outcome.
Experiment Variables: Identify what component or aspect of the system you will disrupt (e.g., network latency, server downtime).
Scope and Blast Radius: Determine the scope of your experiment to minimize impact. Start small and gradually increase the complexity as you gain confidence.
- Success Criteria: Define clear criteria for what success looks like in the context of the experiment. This could include maintaining user experience, failing over gracefully, or triggering alerting mechanisms correctly.
Incorporating Safety Measures
Safety is paramount in Chaos Engineering. Incorporating safety measures ensures that you can halt experiments if unexpected negative impacts occur. Measures include:
Manual Overrides: Ensure there is a way to quickly and easily stop the experiment.
Automated Rollbacks: Implement automated mechanisms to revert the system back to its original state if certain thresholds are crossed.
Monitoring and Alerting: Enhance monitoring to detect and alert on any unintended consequences, allowing for quick intervention.
Real-Life Example: Chaos Experiment at a Financial Institution
A leading financial institution wanted to test the resilience of its payment processing system. The hypothesis was that if the primary payment processing service failed, the secondary system would take over with no impact on transaction processing times.
Experiment Design: The team introduced a controlled failure in the primary payment processing service during off-peak hours.
Safety Measures: The experiment was designed with a manual override and automated health checks to rollback changes if transaction processing times exceeded a predefined threshold.
Observations: The secondary system took over as expected, but the transaction processing time increased slightly, indicating room for optimization.
Outcome: The experiment revealed a bottleneck in the data synchronization process between the primary and secondary systems, leading to targeted improvements.
Implementing Chaos Experiments

The essence of Chaos Engineering lies in its implementation: turning theory into action to fortify system resilience. This process, stretching from meticulous planning to insightful post-experiment analysis, is pivotal for revealing vulnerabilities, enhancing failover mechanisms, and bolstering overall system durability. We delve deep into executing chaos experiments—covering practical steps, safety protocols, code snippets, and illustrating real-world applications.
Step-by-Step Guide to Implementing Chaos Experiments
Preparation
Monitoring and Alerting Setup: Ensure systems are primed for detailed data capture during experiments. This includes fine-tuning monitoring tools and alerting mechanisms to track vital metrics and system behaviors.
Stakeholder Communication: Clearly communicate the experiment's scope, goals, and potential impacts to all involved parties, ensuring alignment and readiness.
Safety Checks Activation: Verify that all safety mechanisms, such as manual overrides and automated rollbacks, are functional to swiftly mitigate unexpected adverse effects.
Execution
Initiate with Minimal Impact Experiments: Begin with experiments designed to have the least system impact, escalating in intensity based on initial insights and system responses.
Adhere to Design Specifications: Implement the chaos experiment as planned, introducing variables like component faults, network latency, or resource constraints as intended.
Monitoring and Observation
Real-Time System Monitoring: Vigilantly monitor system metrics and logs, observing the system’s reaction to the induced chaos.
Documentation of Anomalies: Record any system behavior that deviates from expected outcomes, noting the system’s recovery actions and any manual interventions required.
Experiment Conclusion
Timely Experiment Termination: End the experiment as per the predefined schedule or if critical thresholds necessitating immediate cessation are met.
System Restoration: Employ safety measures to revert the system back to its pre-experiment state, ensuring normal operations are resumed with minimal delay.
Post-Experiment Analysis
Data Analysis: Evaluate the data collected during the experiment to assess system performance against the hypothesized outcomes.
Identify Improvement Areas: Pinpoint system weaknesses or failures exposed by the experiment. Use these insights to formulate enhancements to system design and operational procedures.
Knowledge Sharing: Document and disseminate the experiment findings among the relevant teams and stakeholders to foster a culture of continuous learning and resilience building.
Safety Measures
Prioritizing safety mitigates risk, ensuring chaos experiments do not inadvertently degrade system performance or user experience. Essential safety measures include limiting the experiment's scope (blast radius), employing kill switches for immediate termination, and setting up automated recovery processes.
Code Example: Network Latency Injection
Let's consider an experiment designed to introduce network latency between two services to observe its impact on response times. This example uses Gremlin, a popular chaos engineering tool, to simulate the conditions:
import gremlinapi as gremlin
def introduce_latency(target_service, latency_ms, duration_s):
# Authenticate with Gremlin API
gremlin.authenticate_with_api_key('your-gremlin-api-key')
# Define the target for the chaos experiment
target = {
"type": "service",
"name": target_service
}
# Define the attack parameters
attack_args = {
"type": "latency",
"amount": latency_ms,
"length": duration_s
}
# Launch the attack
gremlin.create_attack(target, attack_args)
print(f"Introduced {latency_ms}ms latency to {target_service} for {duration_s} seconds.")
# Example usage
introduce_latency("payment-service", 500, 60)
This script, intended as a simplified illustration, uses a hypothetical Gremlin API client to introduce 500 milliseconds of latency to the "payment-service" for 60 seconds, simulating network congestion. In practice, ensure your experiments are well-scoped and monitored to prevent unintended consequences.
Conducting the Experiment

Execution
Run the chaos experiment according to the plan. For example, if using Kubernetes, you might employ Chaos Mesh to target specific pods or nodes:
apiVersion: chaos-mesh.org/v1alpha1 kind: NetworkChaos metadata: name: test-network-latency namespace: default spec: action: delay mode: one selector: labelSelectors: "app": "your-target-app" delay: latency: "500ms" duration: "60s"This YAML file defines a NetworkChaos experiment in Chaos Mesh, introducing 500 milliseconds of latency to pods labeled with "app: your-target-app" for 60 seconds.
Monitoring and Observation
Closely monitor the system's response using predefined metrics. Tools like Prometheus, Grafana, or cloud-native monitoring solutions can provide real-time insights into how the system copes with the introduced chaos.
Analyzing Results

After the experiment, gather and analyze the data:
Impact Assessment
Evaluate the system's behavior against the expected outcome. Did the system degrade gracefully? Were there any unexpected side effects?
Root Cause Analysis
For any identified issues, conduct a thorough root cause analysis to understand why the system behaved as it did.
Documentation
Document the experiment's setup, execution, observations, and analysis. This documentation is crucial for sharing learnings and informing future experiments.
Tools and Techniques for Analysis
Log Aggregation Tools: Use tools like Elasticsearch or Splunk to aggregate and query logs for anomalies during the experiment period.
Metric Visualization Tools: Tools like Grafana or Kibana can visualize metrics collected during the experiment, helping identify patterns or anomalies.
Statistical Analysis Software: Software like R or Python's SciPy can perform more in-depth statistical analysis to understand the significance of the observed changes.
Iteration and Continuous Improvement
Feedback Loops: Share the results and insights with all stakeholders, fostering a culture of continuous learning and improvement.
Iterative Testing: Use the findings to refine hypotheses, update experiment designs, and plan new tests, gradually increasing the complexity and scope as your confidence in the system's resilience grows.
Advanced Chaos Engineering Techniques

As organizations mature in their Chaos Engineering practices, they often seek to push the boundaries further by incorporating advanced techniques. These methods not only deepen their understanding of system resilience but also integrate chaos experiments more seamlessly into their development and operations workflows. This section explores sophisticated Chaos Engineering techniques, including Game Days, incorporating chaos into CI/CD pipelines, and Security Chaos Engineering, offering insights into their implementation and benefits.
Game Days: Simulated Real-World Scenarios
Concept
Game Days are organized events where teams simulate real-world incidents in a controlled environment to assess the system's resilience and the team's response capabilities.
Implementation Steps
Planning: Choose scenarios based on real incidents or potential high-impact failures. Prepare comprehensive plans detailing the scenarios, objectives, and roles.
Execution: Simulate the chosen scenarios as realistically as possible, observing the system's response and the team's actions.
Debrief: Conduct a thorough review session to discuss what went well, what didn't, and why. This should lead to actionable insights for improvement.
Code Example: Simulating a Service Outage
For a Game Day scenario simulating a critical service outage, you might use a chaos toolkit to disable the service.
# Pseudo-command to disable a service using Chaos Toolkit chaos run disable-service-experiment.jsonAnd
disable-service-experiment.jsonmight look like this:{ "version": "1.0.0", "title": "Simulate Critical Service Outage", "description": "Disables the critical payment processing service to observe system and team response.", "method": [ { "type": "action", "name": "disable-service", "provider": { "type": "process", "path": "/usr/bin/disable-service", "arguments": "payment-processor" } } ] }
Integrating Chaos into CI/CD Pipelines

Concept
Automating chaos experiments within CI/CD pipelines ensures that resilience testing is a continuous part of development and deployment processes.
Implementation Steps
Select Experiments: Choose or design chaos experiments that are meaningful for your application and infrastructure, focusing on areas affected by recent changes.
Automation: Use pipeline tools like Jenkins, GitLab CI, or GitHub Actions to integrate chaos experiments into the deployment process.
Analysis: Automatically analyze the impact of experiments on system performance and stability. Fail builds where necessary to prevent deployment of changes that reduce system resilience.
Code Example: Pipeline Configuration
Here's how you might configure a Jenkins pipeline to include a chaos experiment:
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'make build'
}
}
stage('Deploy to Staging') {
steps {
sh 'make deploy-staging'
}
}
stage('Chaos Experiment') {
steps {
sh 'chaos run network-latency-experiment.json'
}
}
stage('Performance Test') {
steps {
sh 'make test-performance'
}
}
}
post {
always {
sh 'make cleanup'
}
}
}
This Jenkinsfile includes a stage for running a chaos experiment after deployment to staging but before performance testing, ensuring only resilient changes progress through the pipeline.
Security Chaos Engineering

Concept
Security Chaos Engineering involves introducing security-related failures to validate security postures and incident response capabilities.
Implementation Steps
Identify Security Experiments: Focus on experiments that simulate attacks or failures relevant to your system's security, like DDoS simulations or secret management failures.
Execution and Monitoring: Execute security chaos experiments, closely monitoring for potential breaches, data leaks, or failures in security mechanisms.
Analysis and Improvement: Analyze the outcomes to identify weaknesses in security postures and improve incident response strategies.
Code Example: Simulating an Authentication Service Failure
To simulate an authentication service failure, you might use a script to bypass the authentication service temporarily.
# This is a hypothetical example for illustrative purposes
import requests
def simulate_auth_failure(service_url):
# Send a request to disable the authentication check
response = requests.post(f"{service_url}/simulate-failure", data={"mode": "auth-bypass"})
if response.status_code == 200:
print("Authentication failure simulation activated.")
else:
print("Failed to activate authentication failure simulation.")
simulate_auth_failure("http://your-auth-service.local")
Real-Life Examples of Chaos Engineering
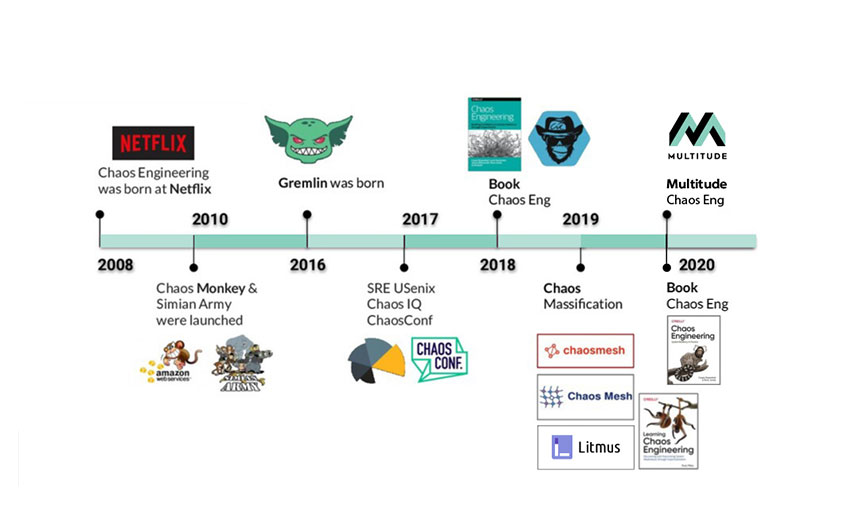
Chaos Engineering has been embraced by a range of companies, from tech giants to financial institutions, each with its unique infrastructure and set of challenges. This section explores real-life examples of Chaos Engineering, highlighting the methods employed, the lessons learned, and the best practices that emerged from these experiences. These examples serve as powerful testimonials to the value of Chaos Engineering in enhancing system resilience.
Netflix: Pioneering Chaos Engineering
Background
Netflix is a trailblazer in Chaos Engineering, developing the Chaos Monkey tool to randomly terminate instances in their production environment. This approach was integral to ensuring their service could gracefully handle failures, crucial for their global streaming service.
Implementation
Tooling: Utilized the Simian Army suite, including Chaos Monkey, to introduce various failures.
Culture: Fostered a company-wide acceptance of Chaos Engineering, integrating it into daily operations.
Lessons Learned
Resilience by Design: Netflix learned the importance of designing systems that are resilient by default, leading to the development of robust microservices architectures.
Automated Recovery: They emphasized automated recovery mechanisms, reducing the need for manual intervention.
Amazon: Ensuring AWS Reliability
Background
Amazon Web Services (AWS) supports a vast array of critical online services. To maintain its reliability, AWS employs Chaos Engineering to simulate outages and test the resilience of its infrastructure.
Implementation
Fault Injection Simulator: AWS developed the Fault Injection Simulator, a service that allows customers to inject faults and simulate outages within their environment.
Wide Scope: Experiments ranged from network disruptions to entire data center outages.
Lessons Learned
Scalability of Chaos: Amazon demonstrated how Chaos Engineering could be scaled to support one of the world's largest cloud infrastructures.
Customer Empowerment: By offering tools like the Fault Injection Simulator, AWS empowers its customers to proactively test their systems, enhancing the overall ecosystem's resilience.
Capital One: Financial Services Resilience
Background
As a major financial institution, Capital One faces the dual challenge of innovating in the competitive banking sector while maintaining the highest levels of reliability and security.
Implementation
Comprehensive Testing: Beyond application resilience, Capital One used Chaos Engineering to test incident response capabilities and security posture.
Integration with Cloud: Leveraged its cloud infrastructure to automate and scale chaos experiments.
Lessons Learned
Business Continuity: Highlighted the importance of Chaos Engineering in ensuring business operations can continue unimpeded, even under adverse conditions.
Security as a Priority: Capital One's approach underscored the significance of incorporating security considerations into chaos experiments.
Code Example: Generic Chaos Experiment Template
Below is a simplified Python code example that could represent a basic framework for implementing chaos experiments, inspired by practices from these companies:
import random
import requests
def terminate_random_instance(service_url, service_token):
headers = {"Authorization": f"Bearer {service_token}"}
response = requests.get(f"{service_url}/instances", headers=headers)
if response.status_code == 200:
instances = response.json()
victim = random.choice(instances)
del_response = requests.delete(f"{service_url}/instances/{victim['id']}", headers=headers)
if del_response.status_code == 200:
print(f"Successfully terminated instance: {victim['id']}")
else:
print("Failed to terminate instance.")
else:
print("Failed to retrieve instances.")
# Example usage
terminate_random_instance("http://your-service-api.com", "your-service-token")
This example, while highly abstracted, captures the essence of initiating a chaos experiment—randomly terminating an instance of a service—to test system resilience.
Best Practices and Common Pitfalls in Chaos Engineering
Embracing Chaos Engineering is a journey filled with learning opportunities and challenges. To navigate this path effectively, understanding the best practices that have been distilled from numerous experiments and recognizing common pitfalls to avoid is crucial. This section outlines key strategies for success and potential obstacles, supplemented with code examples to illustrate how to implement these practices and avoid common errors.
Best Practices in Chaos Engineering
Start Small and Gradually Increase Complexity
Begin with experiments that have a limited scope and impact, allowing your team to build confidence and understanding of the process. Gradually introduce more complex scenarios as your system's resilience improves and your team becomes more comfortable with the methodology.
Automate Chaos Experiments and Responses
Automation is key to scaling Chaos Engineering across large systems and teams. Automate not only the execution of chaos experiments but also the responses to failures, ensuring that your system can recover quickly without manual intervention.
Code Example: Automated Experiment with Rollback
Here's a Python snippet that automates a chaos experiment with a built-in rollback mechanism:
import subprocess import time def execute_experiment_with_rollback(experiment_command, rollback_command, timeout_seconds): try: # Start the experiment subprocess.run(experiment_command, check=True) print("Experiment started successfully.") # Wait for the specified duration time.sleep(timeout_seconds) except subprocess.CalledProcessError as e: print(f"Experiment failed: {e}") finally: # Always attempt to rollback try: subprocess.run(rollback_command, check=True) print("Rollback executed successfully.") except subprocess.CalledProcessError as e: print(f"Rollback failed: {e}") # Example usage execute_experiment_with_rollback(["inject-failure", "--service", "payment-service"], ["remove-failure", "--service", "payment-service"], 60)Integrate Chaos Engineering into Your CI/CD Pipeline
Incorporating chaos experiments into your CI/CD pipeline ensures that resilience testing is a continuous part of your development process. This practice helps catch potential failures early, before they impact users.
Emphasize Clear Communication and Documentation
Maintain clear communication with all stakeholders throughout the chaos experiment process, from planning through analysis. Documenting your experiments, findings, and improvements made is crucial for sharing knowledge and fostering a culture of resilience.
Common Pitfalls in Chaos Engineering

Running Unplanned Experiments
Jumping into chaos experiments without a clear plan and objectives can lead to confusion, unnecessary downtime, and could potentially cause more harm than good. Always start with a well-defined hypothesis and a detailed experiment plan.
Neglecting the Blast Radius
Failing to properly scope the blast radius of an experiment can result in unintended widespread impact. Use tools and techniques to limit the scope of your experiments to prevent accidental disruption to your users.
Code Example: Scoped Chaos Experiment
In this simplified example, a chaos experiment is scoped to a specific Kubernetes namespace to limit its blast radius:
# Using Chaos Mesh to scope an experiment to a specific namespace kubectl annotate ns staging chaos-mesh.org/inject=enabled # Run experiment only in the annotated namespace chaos run network-chaos.yamlOverlooking the Importance of Observability
Without proper monitoring and observability in place, you might miss critical insights from your experiments. Ensure that you have comprehensive logging, monitoring, and alerting systems set up to capture the full impact of your experiments.
Ignoring Post-Experiment Analysis
The value of Chaos Engineering lies not just in conducting experiments but in the learning that follows. Skipping the post-experiment analysis phase means missing out on opportunities to improve your system's resilience.
The Future of Chaos Engineering

The landscape of Chaos Engineering is continuously evolving, driven by advancements in technology, shifts in infrastructure paradigms, and a growing recognition of its value in ensuring system resilience. As we look to the future, several trends and developments stand poised to shape the direction of Chaos Engineering, making it an even more integral part of software development and operations. This section explores these future directions, highlighting emerging tools, methodologies, and the potential impact of AI and machine learning on Chaos Engineering practices.
Integration with Artificial Intelligence and Machine Learning
Predictive Chaos Engineering
AI and machine learning models can analyze historical data to predict potential system failures before they occur, enabling preemptive chaos experiments that are more targeted and effective.
Code Example: Predictive Failure Analysis
from sklearn.ensemble import RandomForestClassifier import pandas as pd # Example dataset of system metrics and failure events data = pd.read_csv("system_metrics_and_failures.csv") X = data.drop("failure_event", axis=1) y = data["failure_event"] # Train a model to predict potential failures model = RandomForestClassifier() model.fit(X, y) # Predictive analysis to identify potential failure points predicted_failures = model.predict_proba(X)[:, 1] > 0.7 if predicted_failures.any(): print("Potential failure points identified, recommend targeted chaos experiments.")Automated Experiment Generation
Machine learning algorithms can also generate and prioritize chaos experiments based on the system's complexity, critical paths, and past experiment outcomes, streamlining the experiment design process.
from sklearn.ensemble import RandomForestClassifier import pandas as pd # Example dataset of system metrics and failure events data = pd.read_csv("system_metrics_and_failures.csv") X = data.drop("failure_event", axis=1) y = data["failure_event"] # Train a model to predict potential failures model = RandomForestClassifier() model.fit(X, y) # Predictive analysis to identify potential failure points predicted_failures = model.predict_proba(X)[:, 1] > 0.7 if predicted_failures.any(): print("Potential failure points identified, recommend targeted chaos experiments.")
Advanced Observability and Real-Time Analytics
As systems grow in complexity, the importance of advanced observability and real-time analytics in Chaos Engineering becomes paramount. Tools leveraging AI for anomaly detection and root cause analysis will become standard, providing deeper insights into system behavior under stress.
Code Example: Anomaly Detection in System Metrics
from sklearn.ensemble import IsolationForest
import pandas as pd
# Load system metrics data
metrics_data = pd.read_csv("system_metrics.csv")
# Train an isolation forest model for anomaly detection
model = IsolationForest()
model.fit(metrics_data)
# Detect anomalies in real-time metrics data
anomalies = model.predict(metrics_data)
anomalous_data_points = metrics_data[anomalies == -1]
print("Anomalous metrics detected, suggesting areas for chaos experiments.")
Chaos Engineering as a Service (CEaaS)
The future will see the rise of Chaos Engineering as a Service (CEaaS), offering organizations the ability to conduct sophisticated chaos experiments without the need for in-house expertise. These services will provide tailored recommendations, automated experiment execution, and comprehensive analysis capabilities.
Expanding Beyond Infrastructure to Business Processes
Chaos Engineering will extend its reach beyond technical infrastructure to include business processes and workflows. Simulating disruptions in business operations will help organizations improve their operational resilience and response strategies.
Conclusion

In navigating the complexities of today's digital landscape, the adoption of Chaos Engineering stands as a pivotal strategy for ensuring system resilience and reliability. This journey through Chaos Engineering has illuminated its foundational principles, vital role within DevOps, impactful real-world applications, and its promising future enriched by AI and ML innovations.
The experiences of pioneers like Netflix, Amazon, and Capital One highlight the transformative power of Chaos Engineering in achieving high availability and operational excellence. These examples, alongside the exploration of advanced techniques and the future integration of AI, paint a picture of a discipline poised for greater adoption and evolution.
Chaos Engineering transcends mere technical practices to embody a cultural shift towards embracing failure as a catalyst for growth and innovation. It champions a proactive approach to discovering and mitigating potential system failures, ensuring that businesses remain resilient in the face of challenges.
As we wrap up, the essence of Chaos Engineering resonates as a call to action for organizations to proactively embrace and learn from chaos. In doing so, they not only safeguard their systems but also foster a culture of continuous improvement and resilience. The path forward is clear: by integrating Chaos Engineering into our practices, we prepare our systems—and our teams—for a future defined by certainty in uncertainty.

Thank you for reading this Blog. Hope you learned something new today! If you found this blog helpful, please like, share, and follow me for more blog posts like this in the future.
If you have some suggestions I am happy to learn with you.
I would love to connect with you on LinkedIn
Meet you in the next blog....till then Stay Safe ➕ Stay Healthy
#HappyLearning #devops #ChaosEngineering #ResilienceEngineering #SystemResilience #SiteReliability #TechInnovation #SRE (Site Reliability Engineering) #CloudComputing #CloudNative #Microservices #ContinuousImprovement #ContinuousDelivery #SoftwareDevelopment #TechTrends #OperationalExcellence #HighAvailability #FailFastLearnFaster #FailFast #LearnFromFailure #InfrastructureAsCode #Automation #AgileDevelopment #DigitalTransformation #SoftwareTesting #FaultTolerance #Monitoring #IncidentResponse #ReliabilityEngineering #SoftwareArchitecture #CI/CD #PerformanceTesting #Scalability #DataIntegrity #DevSecOps #AIInTech #AIops #MachineLearning #MachineLearningInTech #PredictiveAnalytics #PredictiveEngineering #Cybersecurity #CyberResilience #Containerization #Kubernetes #Observability #SoftwareQuality #CodeResilience #TechLeadership #FutureTech #FutureOfTech
Subscribe to my newsletter
Read articles from Ambuz Ranjan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by