Mastering Cloud Security: Insights from the AWS DevSecOps Netflix Project
 Sorav Kumar Sharma
Sorav Kumar Sharma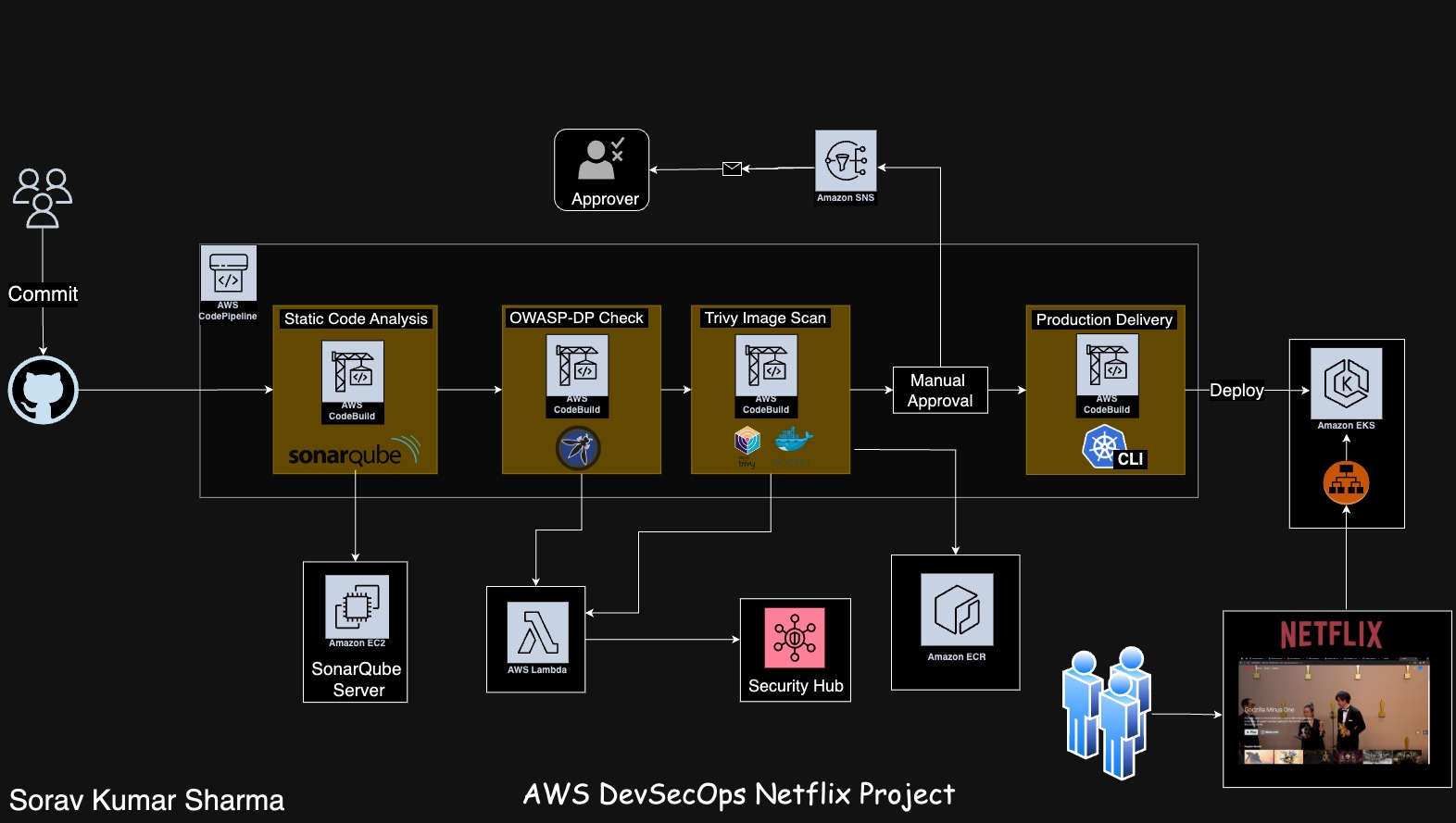
Introduction:
Welcome to our new blog! Get ready for an exciting ride as we walk you through deploying the Netflix clone project on an AWS EKS cluster using AWS DevSecOps techniques. We'll be using handy tools like AWS CodePipeline, AWS CodeBuild, and setting up important policies and roles. We'll also cover how to use Trivy for scanning Docker images, OWASP for checking dependencies, AWS Lambda, AWS Security Hub, and AWS Load Balancer for EKS. It's time to explore cloud-native app deployment with a strong focus on security. Let's dive in!
Prerequisites:
AWS Account
Instance on AWS
CodeBuild
Codepipeline
Lambda
SNS
EKS
ALB
Security Hub
S3
ECR
Let's Start:
- Git Repositories:AWS-DevSecOps-Netflix-Project
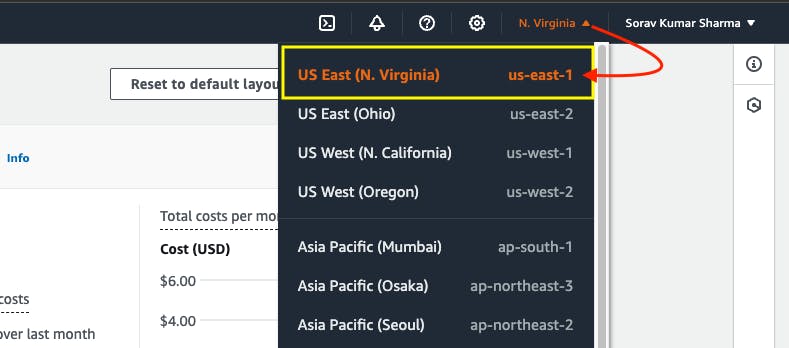
Step1: Select the us-east-1 region from AWS Regions.
Step2: Create an IAM user, If you login with root user.
- Go to AWS Search console, and Search for IAM user, then go to users, Go to create user.
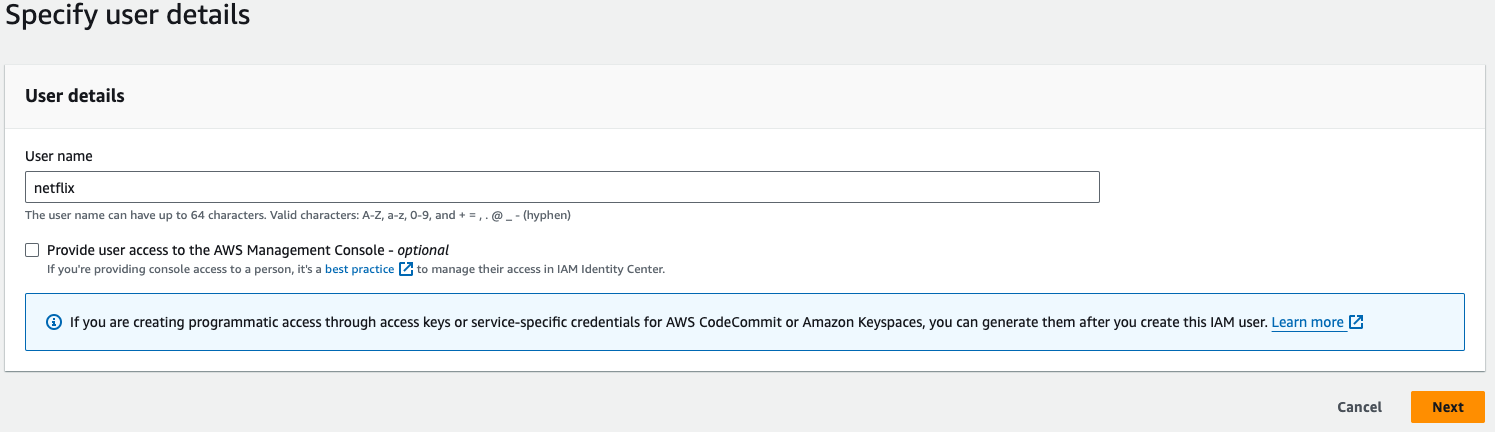
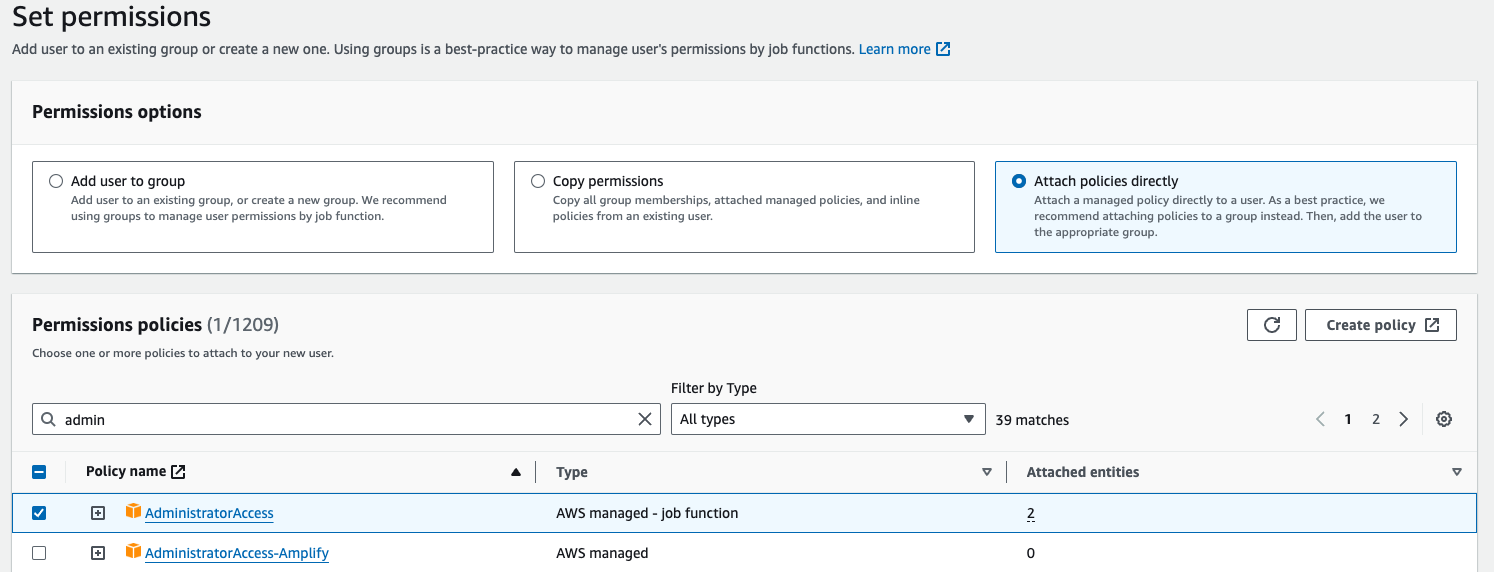
- Give any name, I'm giving "netflix", then Go to "Next".
- Go to "Attach policies directly", and then search for "AdministratorAccess" policy, adn then select that policy, Go to Next, then Go to Create user.
Step 3: Launch an Ubuntu Instance.
- Go to AWS Search console and search for EC2, Go to Dashboard.
- Go to Launch Instance.
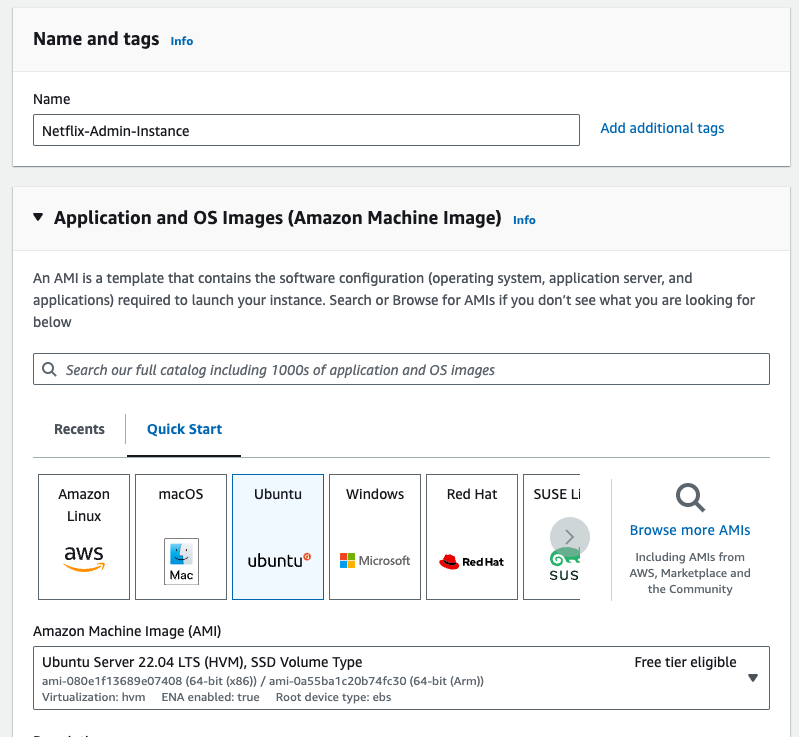
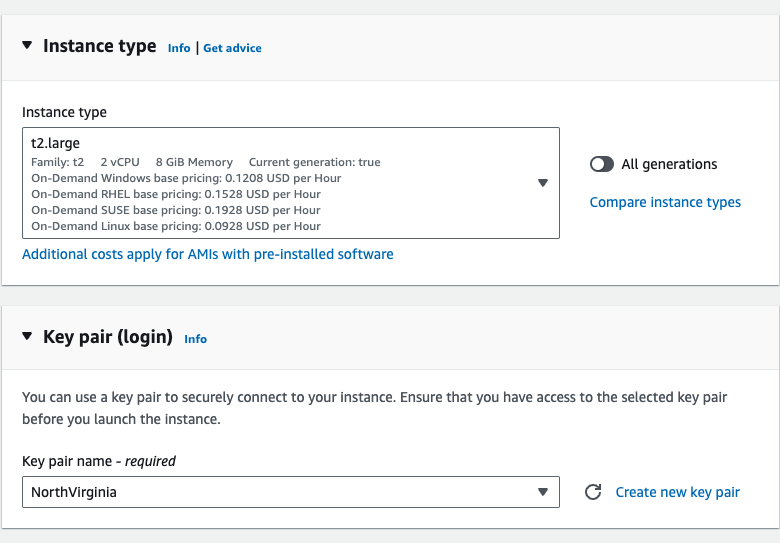
- Give the instance name "Netflix-Admin-Instance", Select the "Ubuntu" AMI, then the Instance type should be "t2.large", Select the keypair if already created. the in the configure storage the root volue size should be 20Gib.
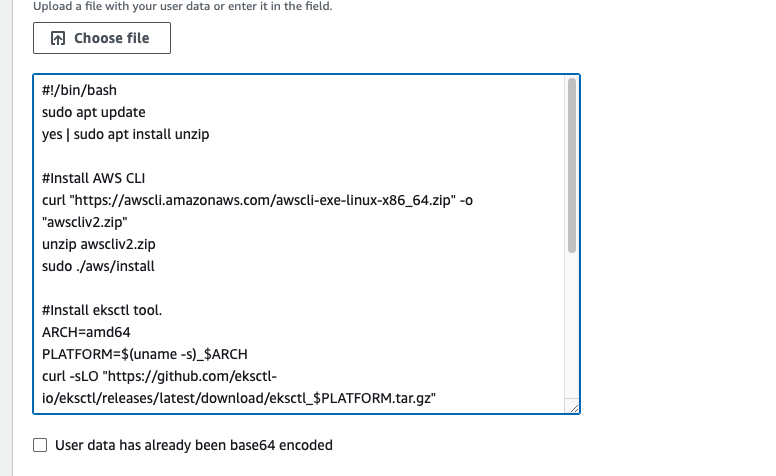
- Go to Advanced details, In the user data section paste the below script to install all the required packages at the boot time, then go to launch an instance.
#!/bin/bash
sudo apt update
yes | sudo apt install unzip
#Install AWS CLI
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
#Install eksctl tool.
ARCH=amd64
PLATFORM=$(uname -s)_$ARCH
curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz"
tar -xzf eksctl_$PLATFORM.tar.gz -C /tmp && rm eksctl_$PLATFORM.tar.gz
sudo mv /tmp/eksctl /usr/local/bin
#Install kubectl tool.
yes | sudo apt-get install apt-transport-https ca-certificates
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
yes | sudo apt-get update
yes | sudo apt-get install kubectl
#Install helm
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
yes | sudo apt-get update
yes | sudo apt-get install helm
- Copy the public ip of "Netflix-Admin-Instance".
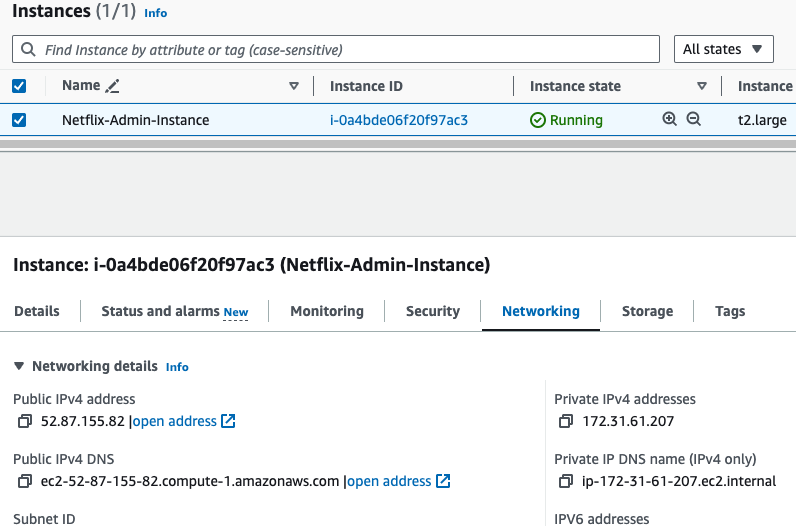
- Once the instance is in the running state, then ssh into the instance.
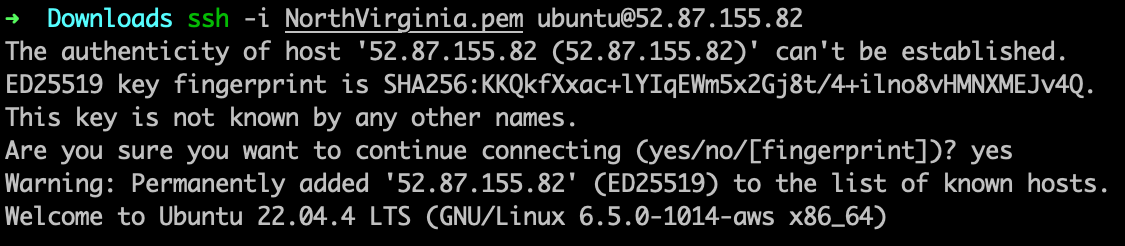
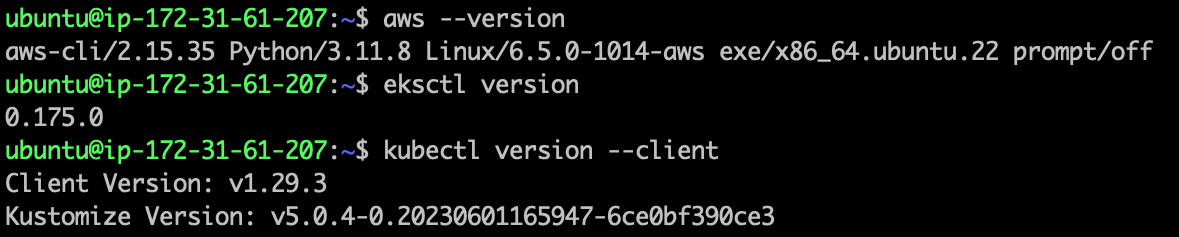
- Run the following command for the cross check, the packages installed or not.
aws --version
eksctl version
kubectl version --client
helm version

Step 4: Setup the "Netflix-Admin-Instance"
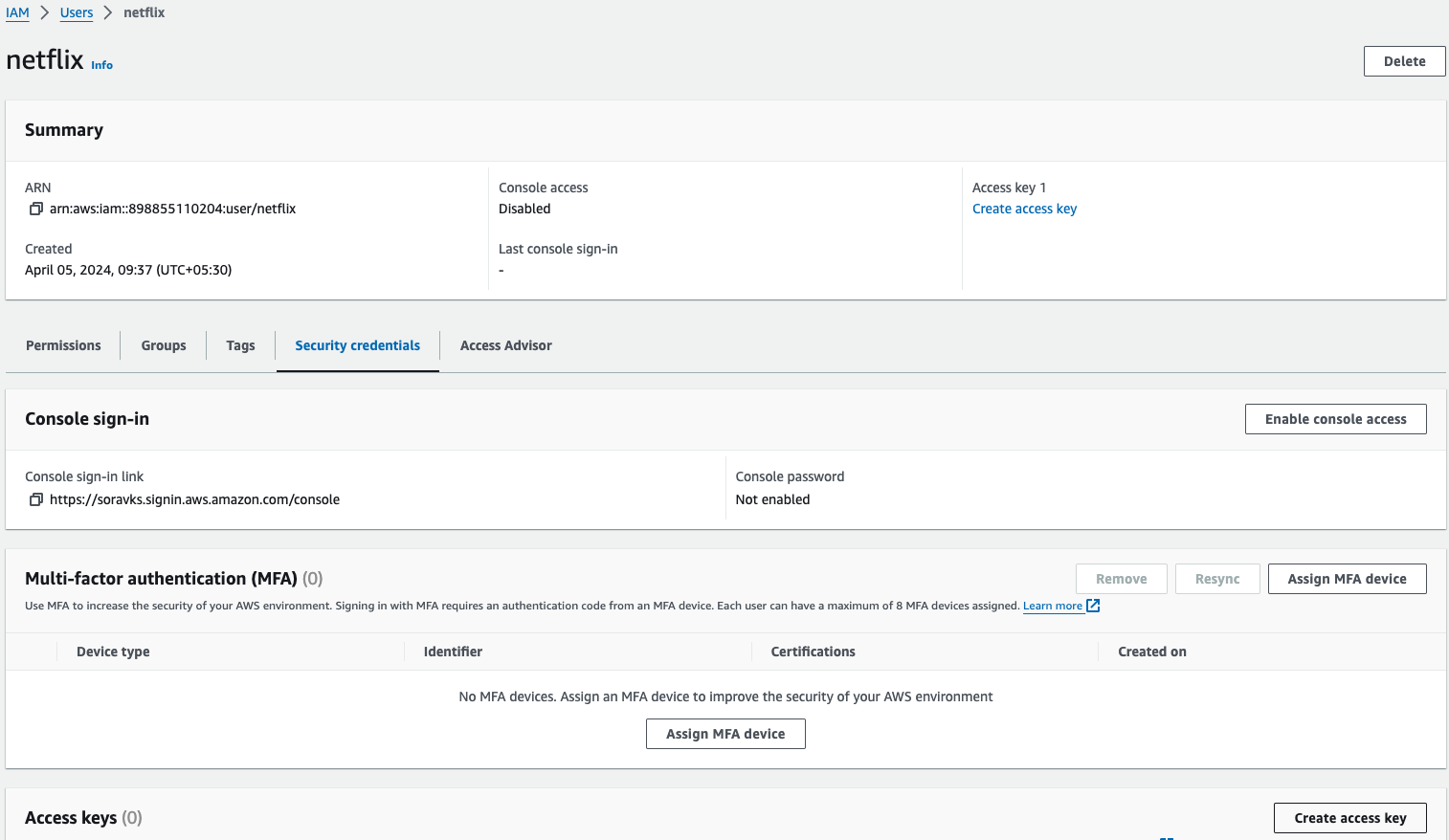
- First, Configure the AWS CLI, Go to again AWS Search console, and Search for IAM user, Go to users, Click on the "netflix" user that is created before, Go to Security Credentials, Go to Create Access Key.
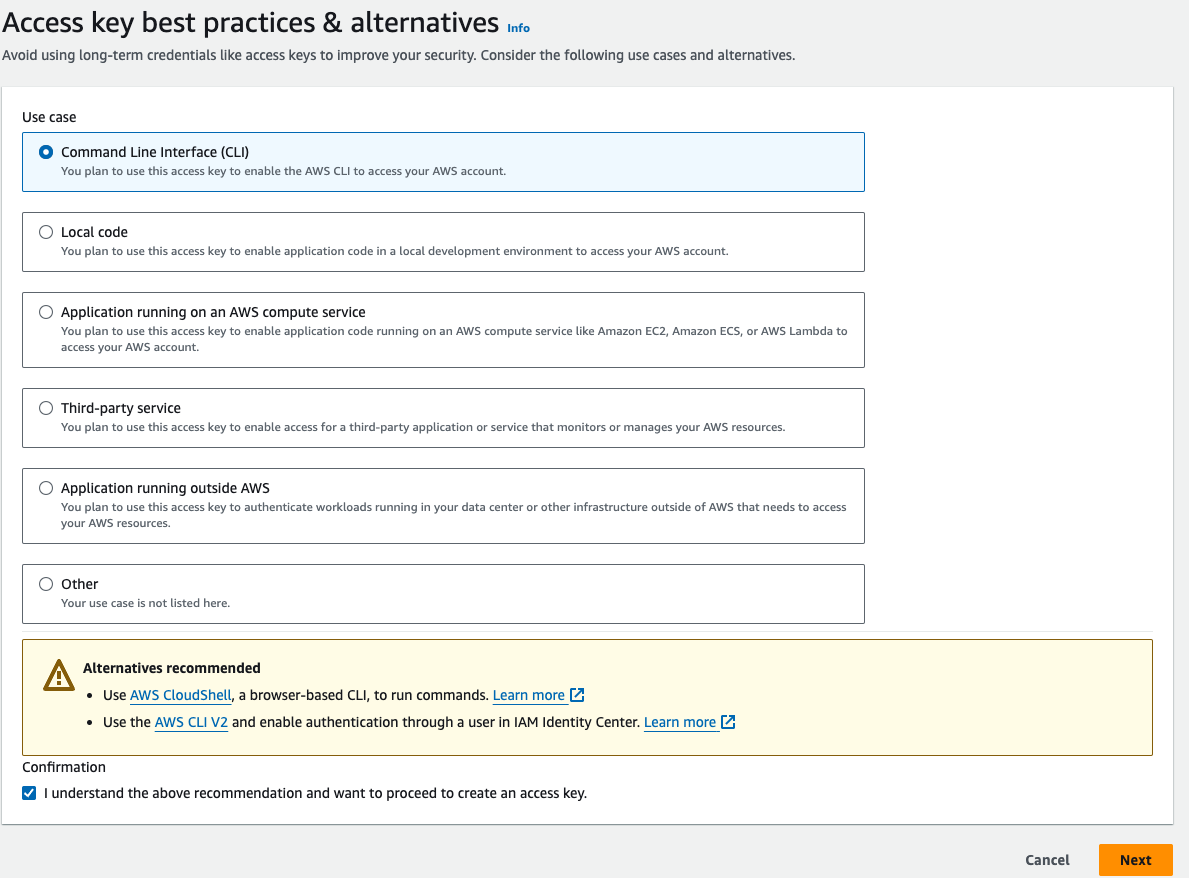
- Select the use case as "CLI", and in the confirmation enable the check box field, then Go to next, Go to Create user.
download the credentials in the .csv format from the below, because if you click on done button without copy or download the credentials then you wont able to retrieve the secret access key.
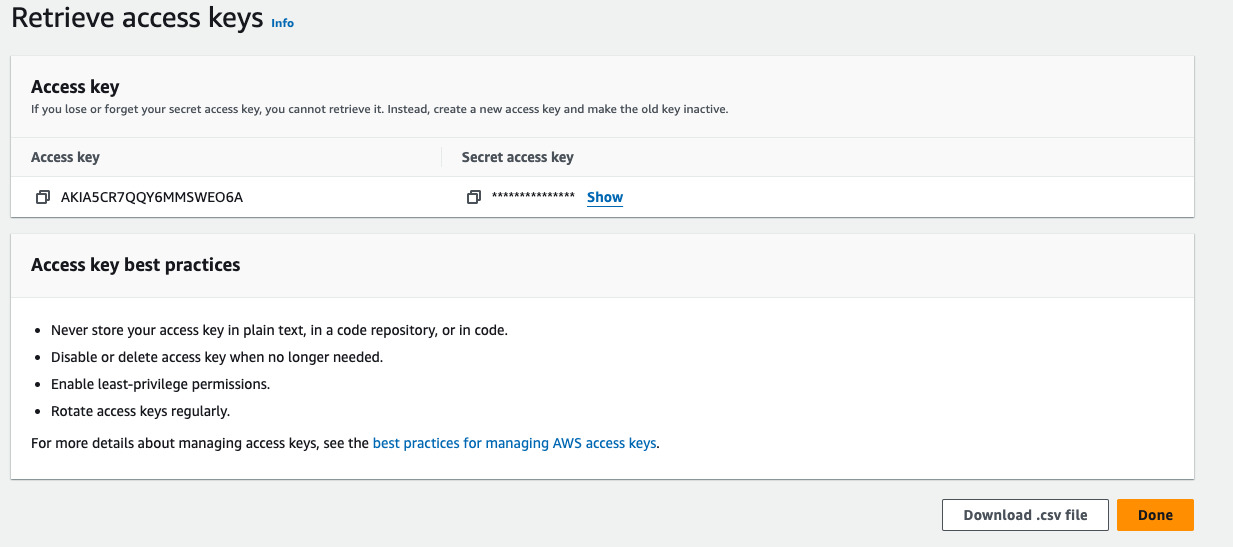
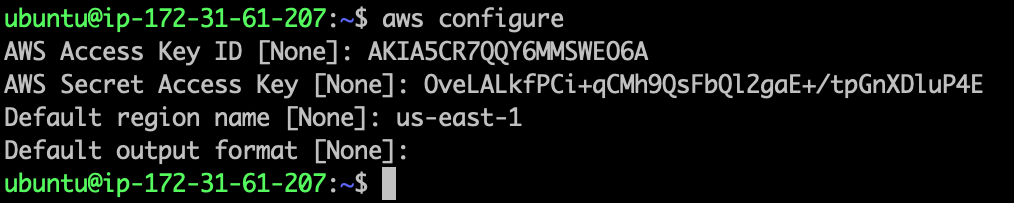
- Copy the Access Key, and Go to "Netflix-Admin-Instance" terminal, run the following command.
aws configure
- paste the access key and secret access key from the aws management console.
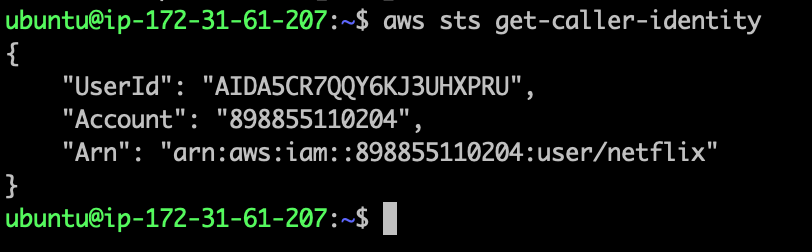
- Run the following command to cross check the aws cli is in the working state or not.
aws sts get-caller-identity
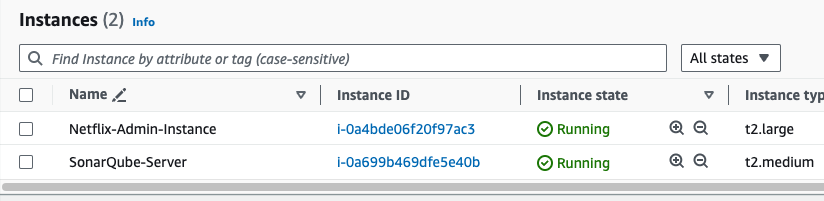
Step 5: Launch Instance for SonarQube Server.
- Go to AWS Search Console, Search for EC2, Go to dashboard, Go to Launch Instances, Give the Instance name "SonarQube-Server", Select the ubuntu AMI, and Instance type should be t2.medium, Select the key pair, In the Networking Section, open the inbound port 9000 for the SonarQube, the source type should be anywhere, Go to Advanced details, In the userdata section paste the below script to install the sonarqube, then go to launch instance.
#!/bin/bash
yes | sudo apt update
yes | sudo apt install docker.io
sudo docker run -d --name sonar -p 9000:9000 sonarqube:lts-community
- Once the Instance is in the running state, the select the SonarQube-Server instance and copy the public ipv4, and paste the public ipv4 address with port, on the browser to access the sonarqube server.
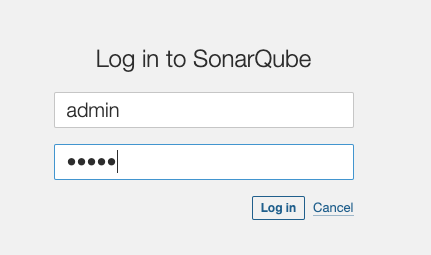
To login the SonarQube server the default credentials are:
username: admin, password: admin
after login you have to change the password.
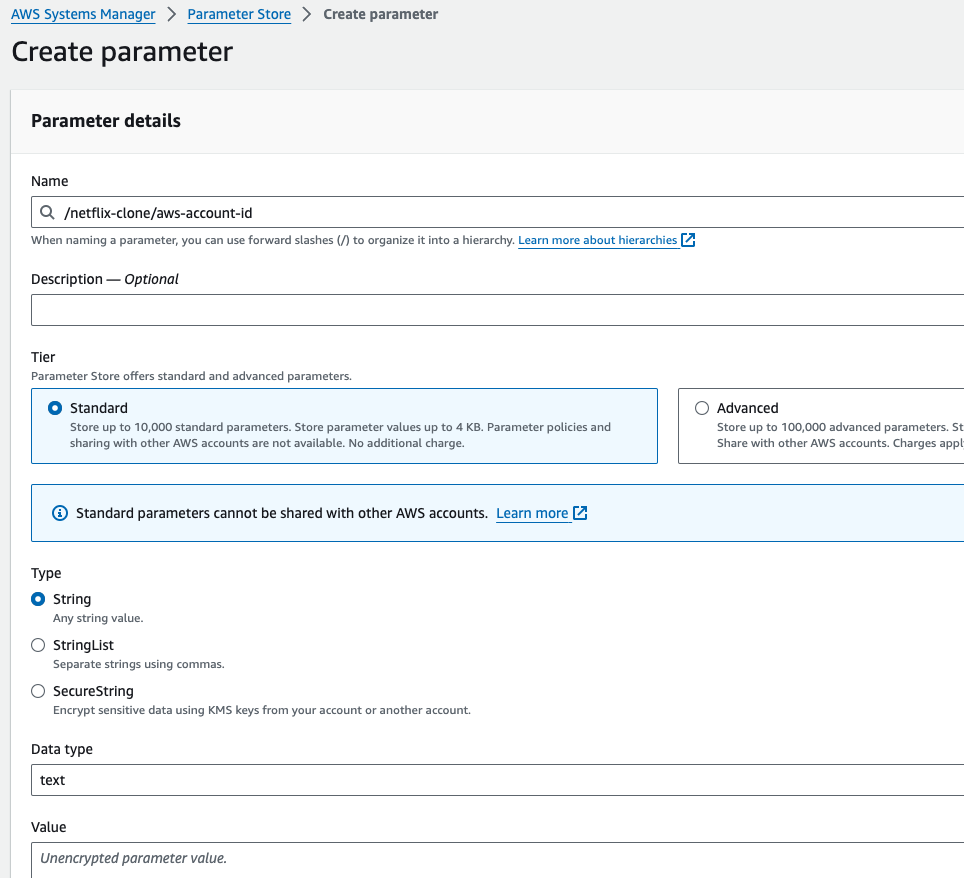
Step 6: Setup the credentials, to store the environment variable in the system manager.
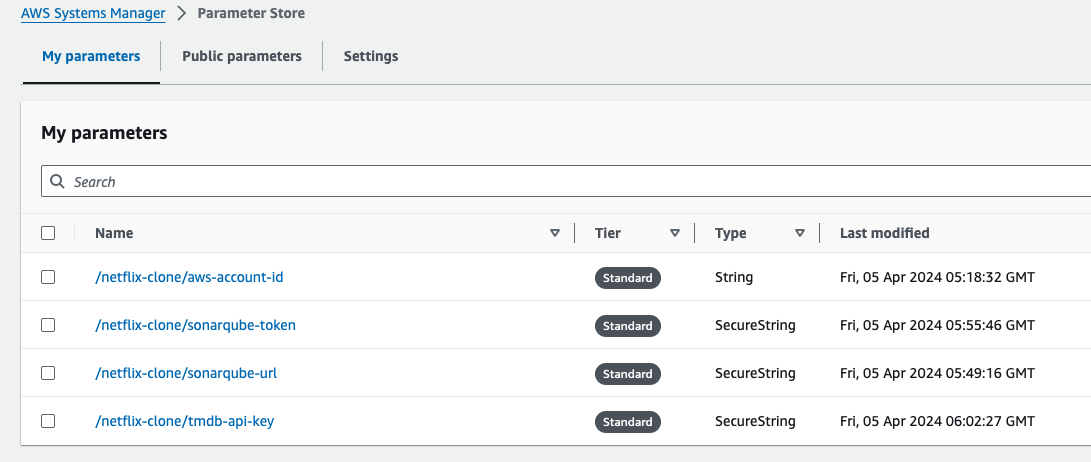
Go to AWS Search console, search for system manger, and then go to paramter store, then go to create paramter.
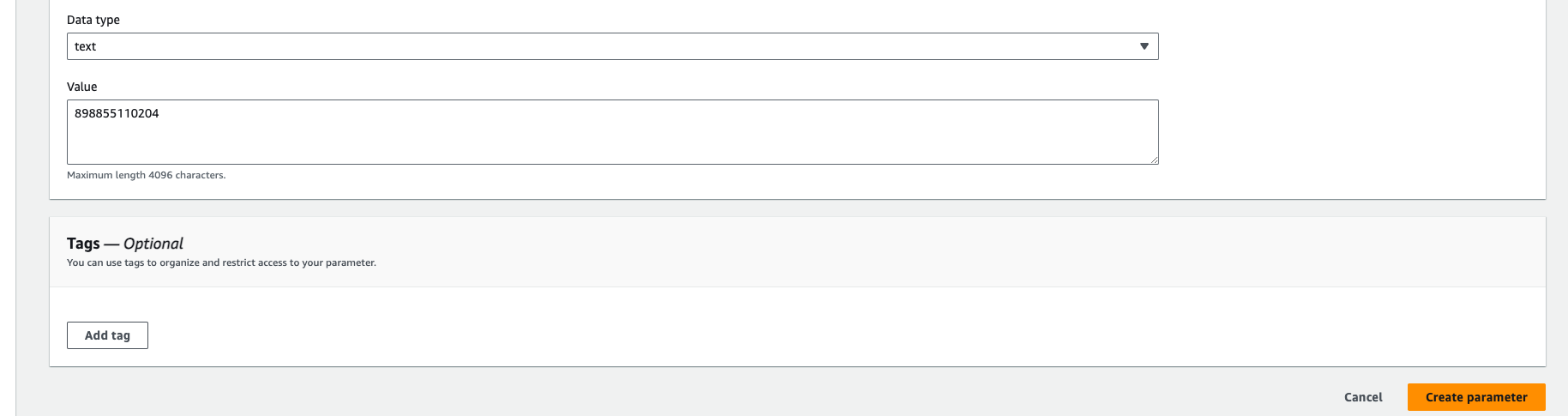
Give the paramter name: /netflix-clone/aws-account-id
the type should be string, and in the value paste the account id.
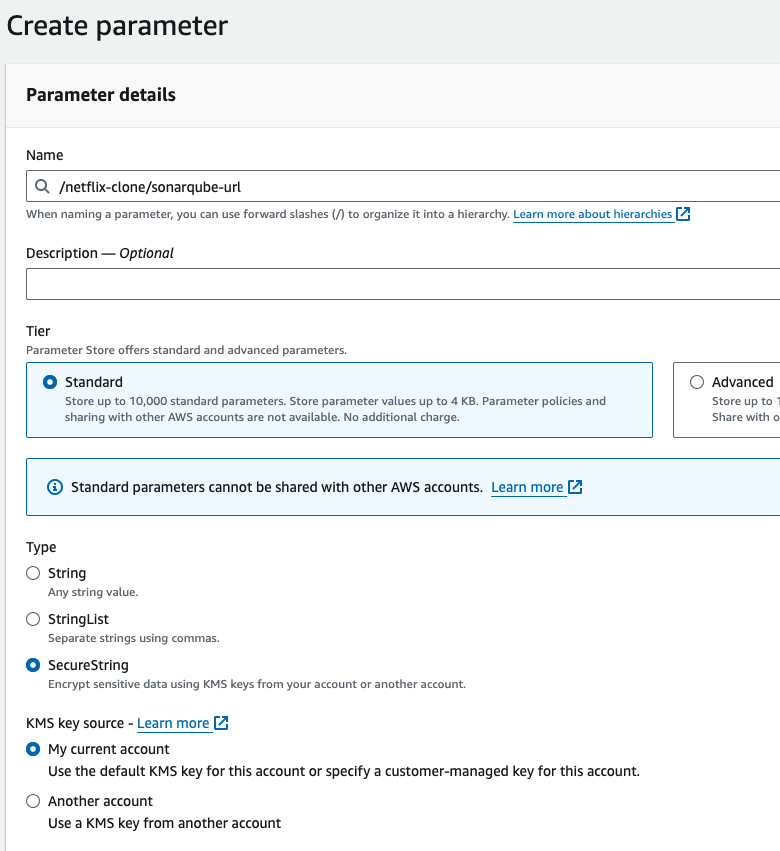
Go to again create paramter store, the paramter name shoud be: /netflix-clone/sonarqube-url
type should be secure string.
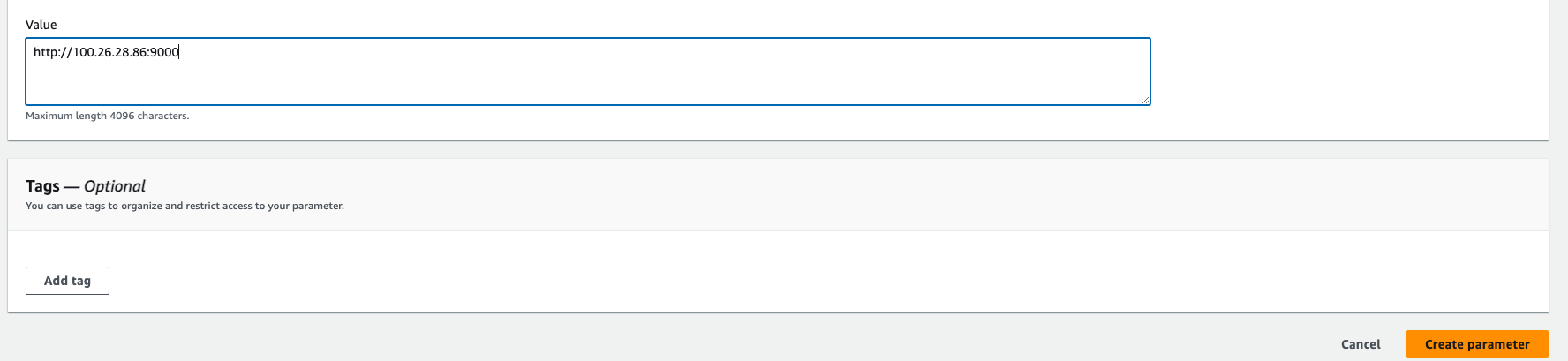
Go to SonarQube-Server url, and then copy the url
- Go to again create paramter, give the paramter name: /netflix-clone/sonarqube-token, type should be secure string.
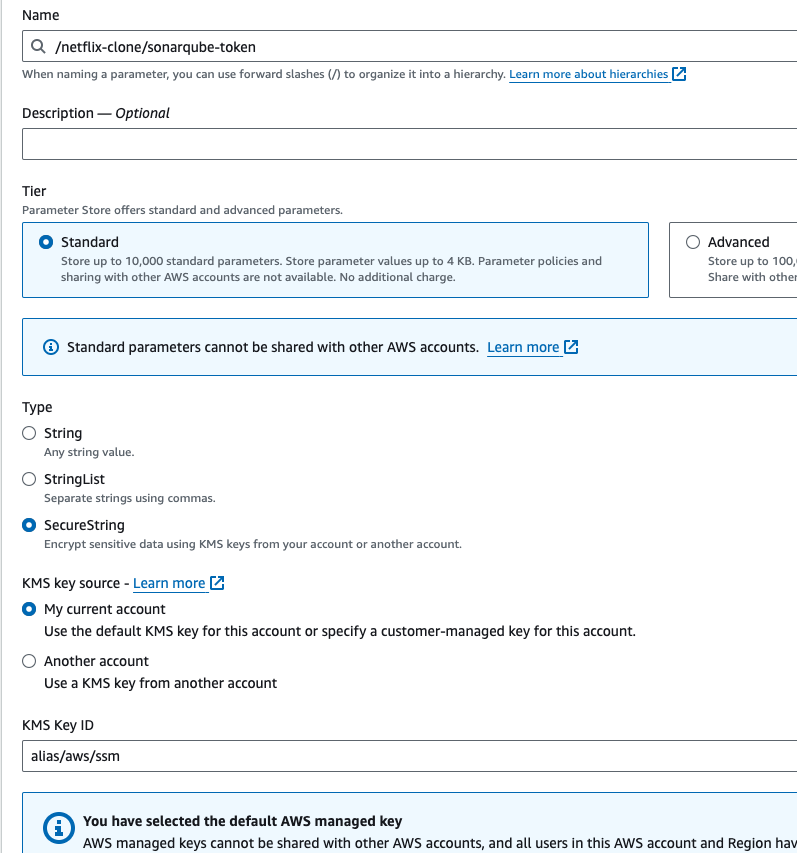
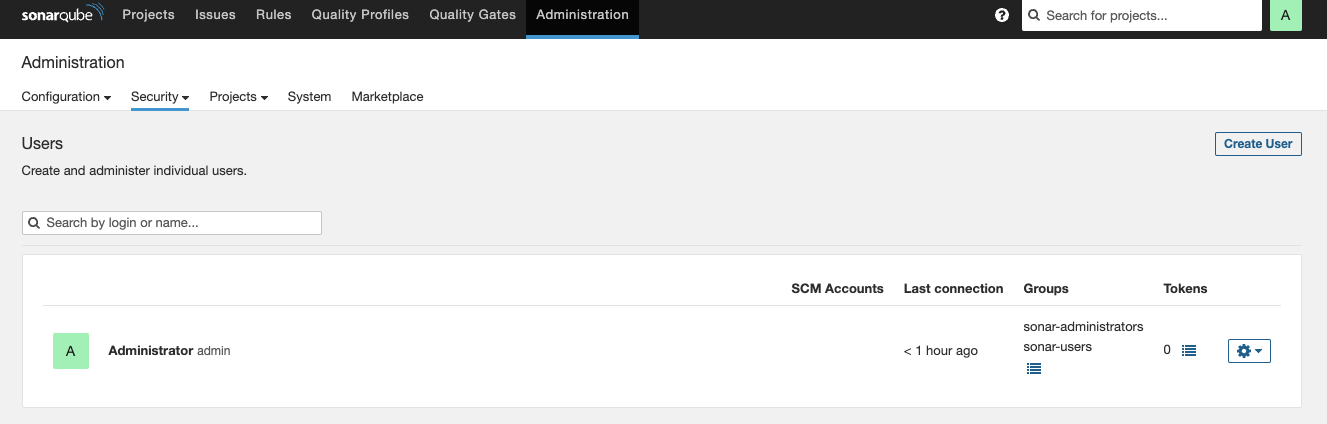
- To create the sonarqube token. First, Go to SonarQube server url, Go to Administration -> Go to Security -> Go to users.
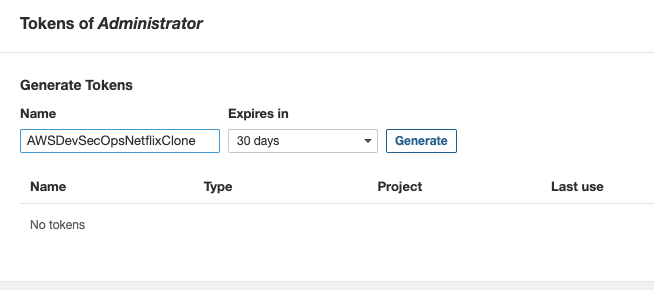
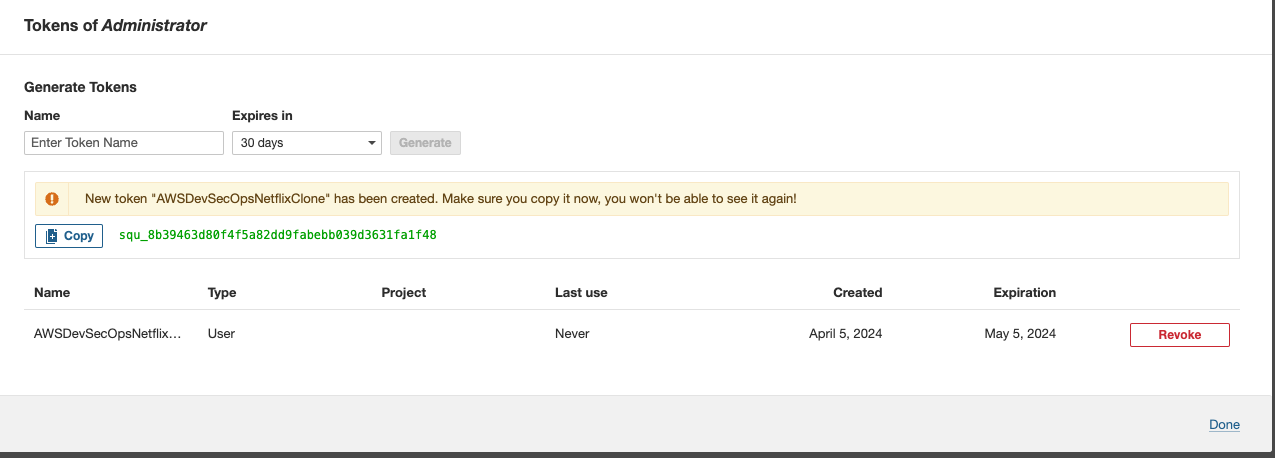
- Go to tokens -> Give the token name "AWSDevSecOpsNetflixClone, Set the expirey, and then click on generate and copy the token. then paste the token as a value inside the paramter store /netflix-clone/sonarqube-token.
- Go to again create paramter, give the paramter name /netflix-clone/tmdb-api-key, type should be secure string. inside the value paste the tmdb api key.
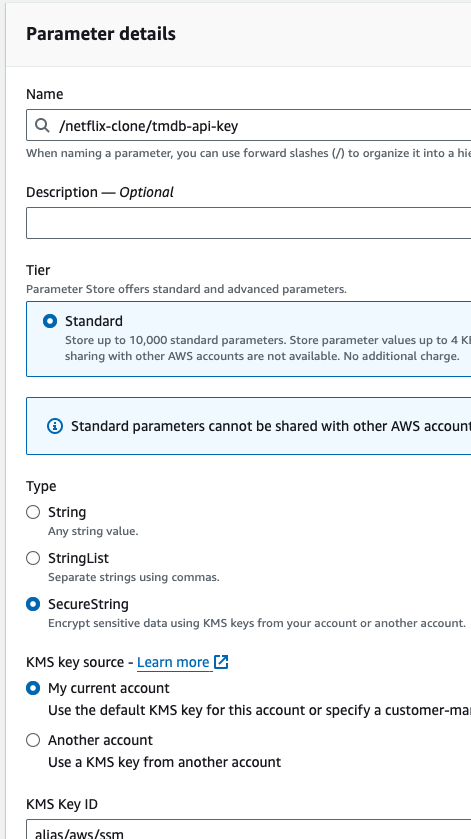
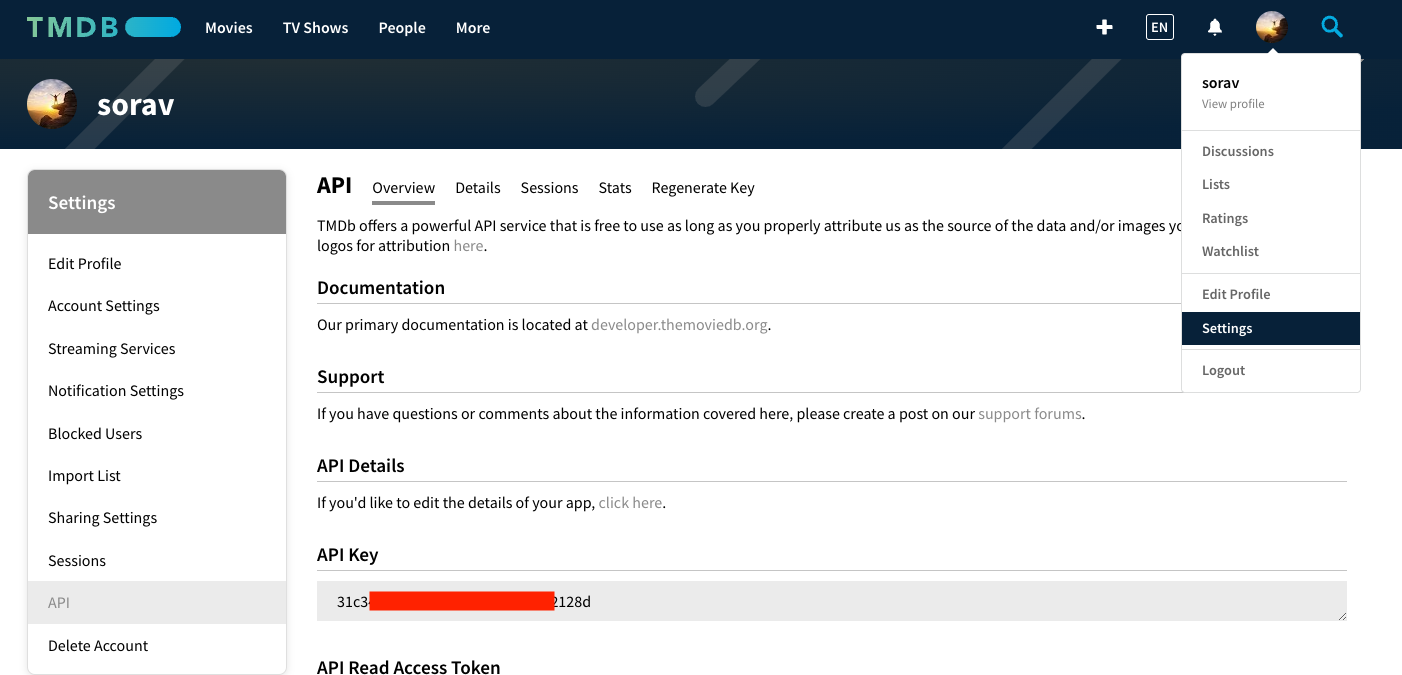
To generate the tmdb api key, Go to themoviedb.org site and create an account.
Go to Profile -> Go to Settings -> Go to API -> Copy the API Key, and paste it inside the paramter store /netflix-clone/tmdb-api-key
Step 7: Setup the policy and role.
Go to Netflix-Admin-Instance terminal, and clone the repo, by running the following command.
git clone https://github.com/soravkumarsharma/AWS-DevSecOps-Netflix-Project.git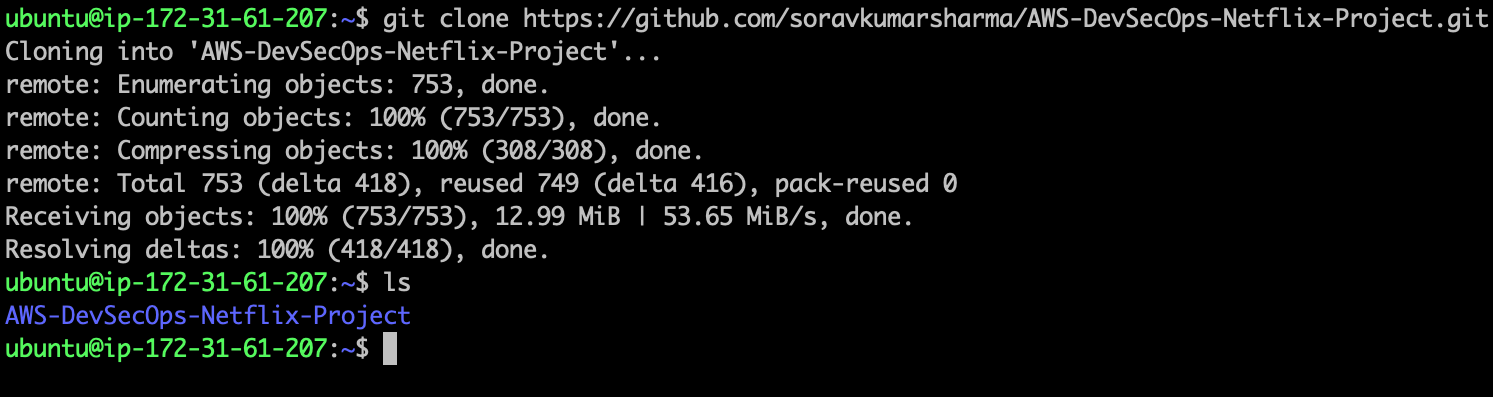
cd AWS-DevSecOps-Netflix-Project/Shell-Scripts/ sh iam_role.sh
- Go to IAM role management console, and corss check the role is created or not.

Step 8: Setup the EKS cluster and ALB.
- Before creating the eks cluster using eksctl tool, we need to create one policy.
cd AWS-DevSecOps-Netflix-Project/EKS-Cluster/
aws iam create-policy --policy-name AWSLoadBalancerControllerIAMPolicy --policy-document file://iam_policy.json
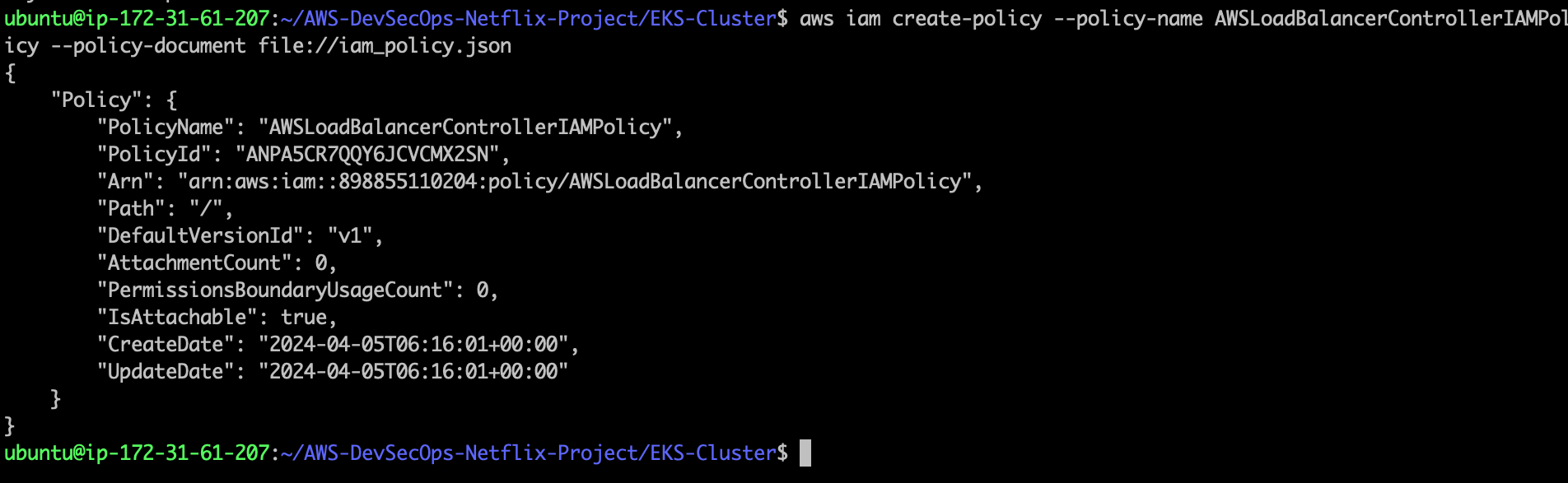
- after created the policy, run the following command to create an eks cluster.
eksctl create cluster -f cluster.yml
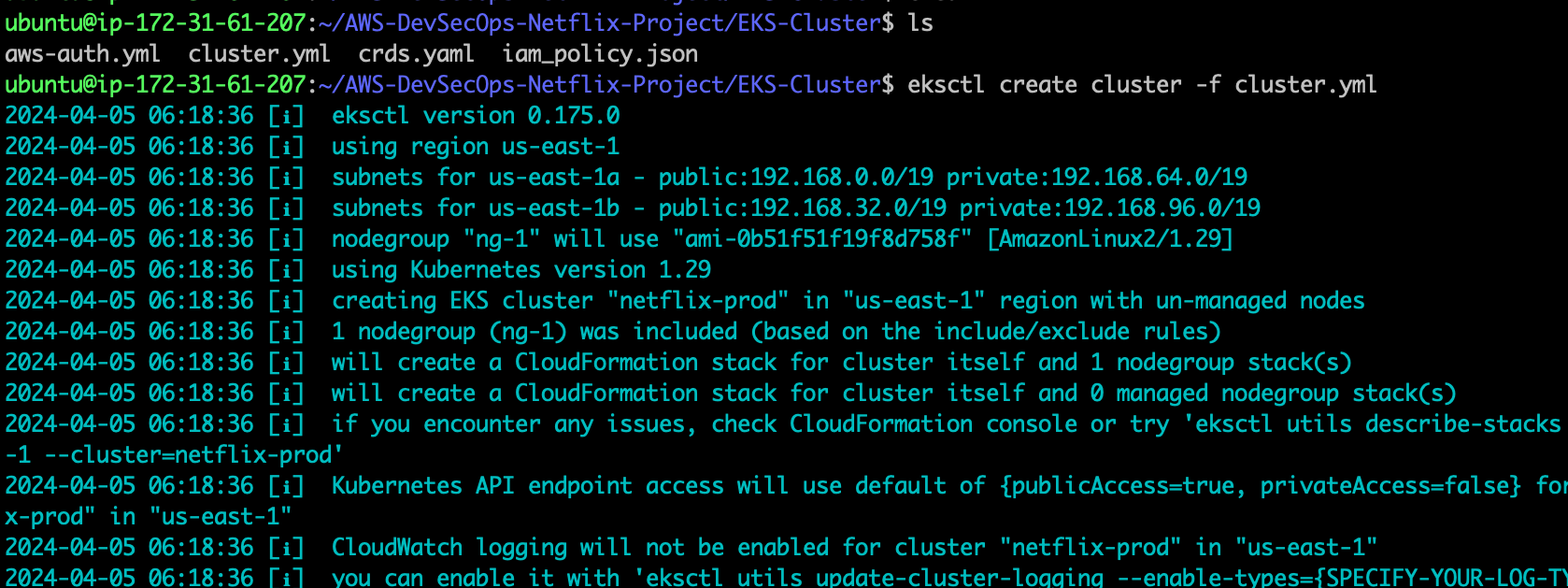
wait 10-20minutes for the EKS-cluster.
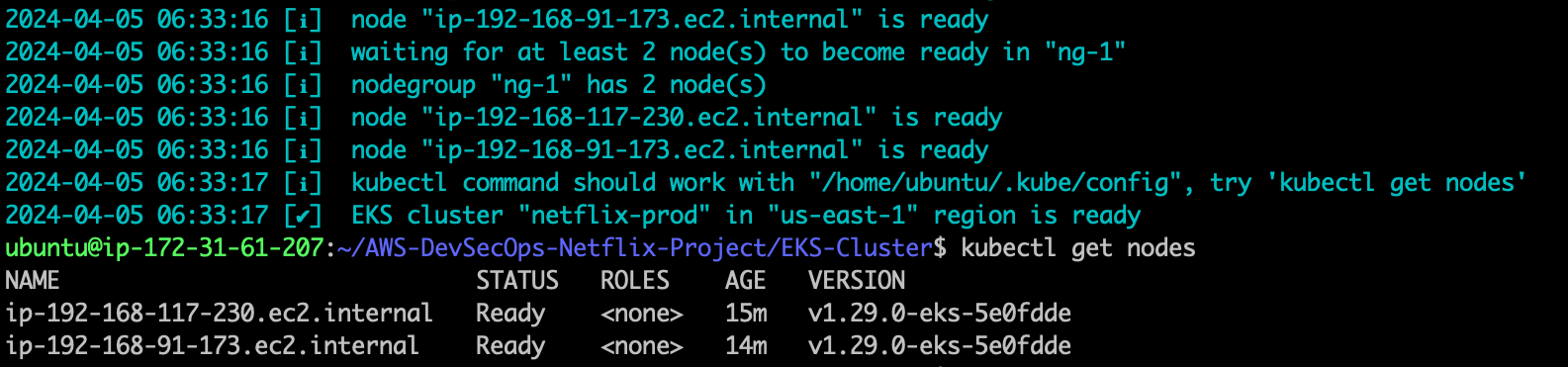
Run the following command to check all the worker nodes.
kubectl get nodes
- Install the aws load balancer controller, to install this first add the eks-charts to the helm repository, run the following command to add the chart to the helm repo.
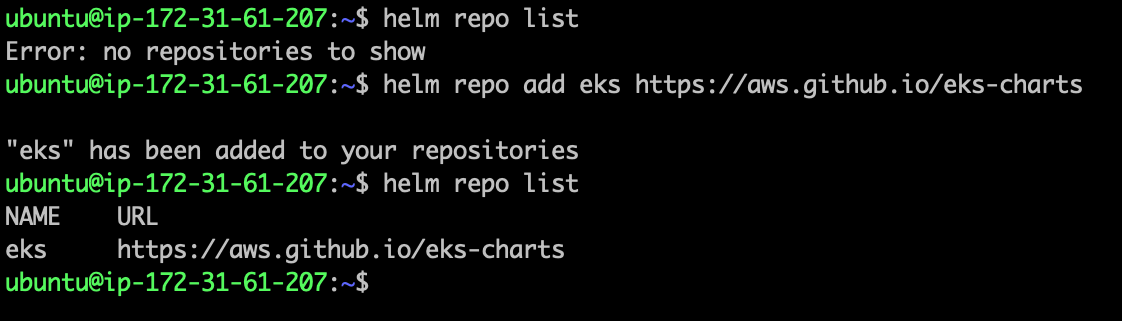
helm repo add eks https://aws.github.io/eks-charts
- Run the following command to check the repo is added or not.
helm repo list
- Update your local repo to make sure that you have the most recent charts.
helm repo update eks

- before installing the aws load balancer controller, first apply the crds.yml file.
cd AWS-DevSecOps-Netflix-Project/EKS-Cluster
kubectl apply -f crds.yaml

- Now, run the following command to Install the aws-load-balancer-controller
helm upgrade -i aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=netflix-prod \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller
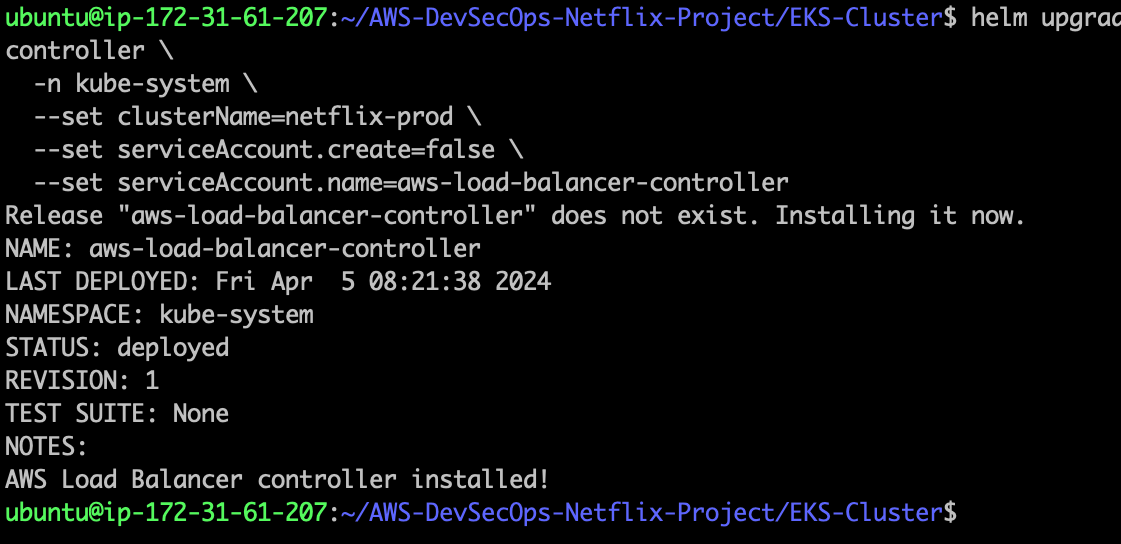
helm list --all-namespaces

- Verify that the controller is installed.
kubectl get deployment -n kube-system aws-load-balancer-controller

- before apply the aws-auth.yml file, first open the file in the vim editor and replace the my aws account id with your aws account id, and then save the file and then apply the aws-auth.yml file
kubectl apply -f aws-auth.yml

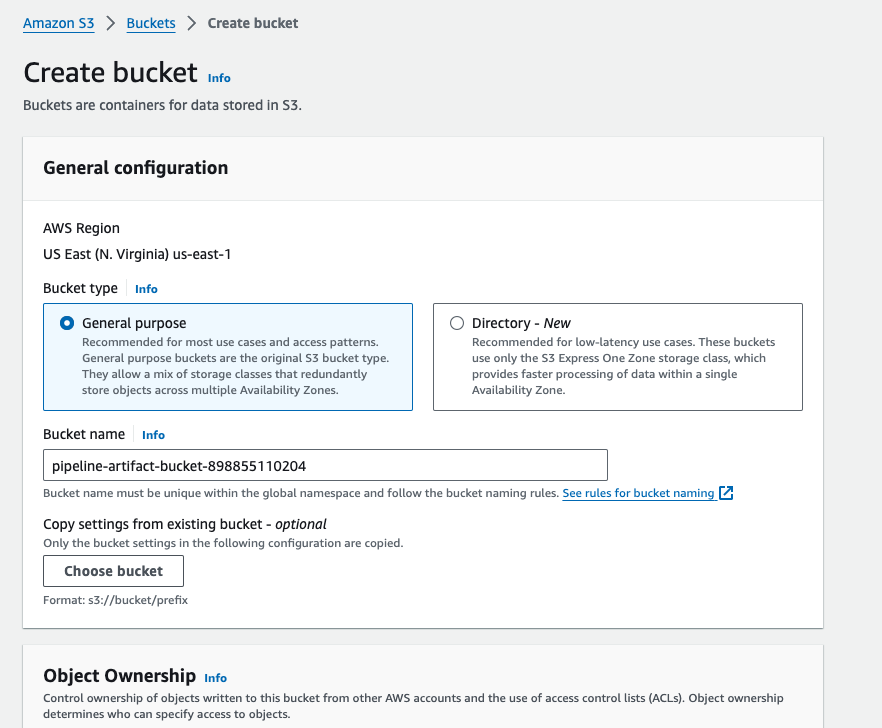
Step 9: Setup the S3 bucket for the lambda function.
Go to AWS search console, and search for s3, go to create a bucket, and the bucket name should be pipeline-artifact-bucket-accountid
After giving the name then click on create a bucket.

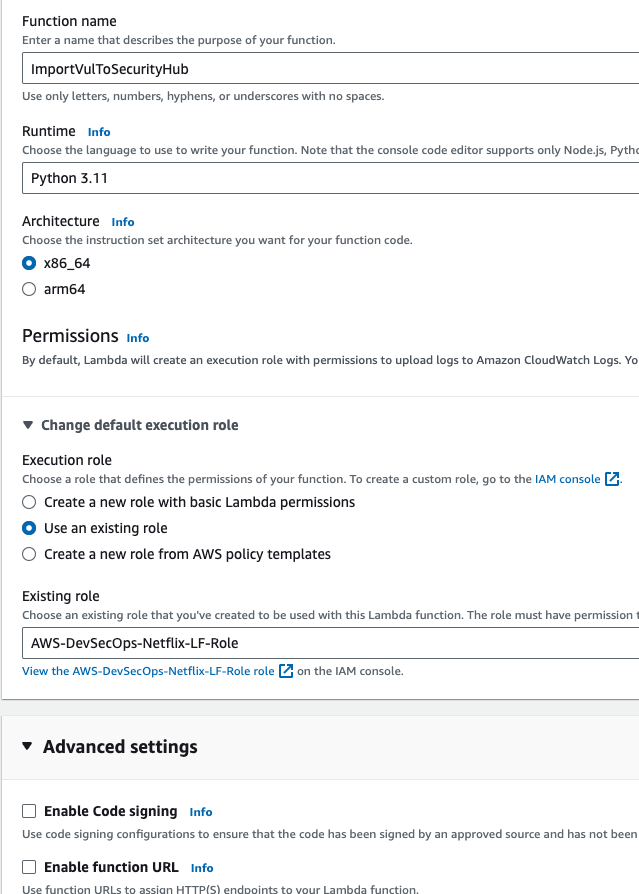
Step 10: Setup the lambda function.
Go to AWS Search console and search for lambda, then go to create function.
Function name should be ImportVulToSecurityHub, because this function name is hardcoded inside the buildspec file, Select the runtime python 3.11, Go to Change defualt execution role, Go to use an existing role. Select the role that is created before, then go to create function.
- In the lambda_function.py, paste the below code, and then save the file
import os
import json
import logging
import boto3
import securityhub
from datetime import datetime, timezone
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
FINDING_TITLE = "CodeAnalysis"
FINDING_DESCRIPTION_TEMPLATE = "Summarized report of code scan with {0}"
FINDING_TYPE_TEMPLATE = "{0} code scan"
BEST_PRACTICES_PHP = "https://aws.amazon.com/developer/language/php/"
BEST_PRACTICES_OWASP = "https://owasp.org/www-project-top-ten/"
report_url = "https://aws.amazon.com"
def process_message(event):
""" Process Lambda Event """
if event['messageType'] == 'CodeScanReport':
account_id = boto3.client('sts').get_caller_identity().get('Account')
region = os.environ['AWS_REGION']
created_at = event['createdAt']
source_repository = event['source_repository']
source_branch = event['source_branch']
source_commitid = event['source_commitid']
build_id = event['build_id']
report_type = event['reportType']
finding_type = FINDING_TYPE_TEMPLATE.format(report_type)
generator_id = f"{report_type.lower()}-{source_repository}-{source_branch}"
### upload to S3 bucket
s3 = boto3.client('s3')
s3bucket = "pipeline-artifact-bucket-" + account_id
key = f"reports/{event['reportType']}/{build_id}-{created_at}.json"
s3.put_object(Bucket=s3bucket, Body=json.dumps(event), Key=key, ServerSideEncryption='aws:kms')
report_url = f"https://s3.console.aws.amazon.com/s3/object/{s3bucket}/{key}?region={region}"
### OWASP SCA scanning report parsing
if event['reportType'] == 'OWASP-Dependency-Check':
severity = 50
FINDING_TITLE = "OWASP Dependecy Check Analysis"
dep_pkgs = len(event['report']['dependencies'])
for i in range(dep_pkgs):
if "packages" in event['report']['dependencies'][i]:
confidence = event['report']['dependencies'][i]['packages'][0]['confidence']
url = event['report']['dependencies'][i]['packages'][0]['url']
finding_id = f"{i}-{report_type.lower()}-{build_id}"
finding_description = f"Package: {event['report']['dependencies'][i]['packages'][0]['id']}, Confidence: {confidence}, URL: {url}"
created_at = datetime.now(timezone.utc).isoformat()
### find the vulnerability severity level
if confidence == "HIGHEST":
normalized_severity = 80
else:
normalized_severity = 50
securityhub.import_finding_to_sh(i, account_id, region, created_at, source_repository, source_branch, source_commitid, build_id, report_url, finding_id, generator_id, normalized_severity, severity, finding_type, FINDING_TITLE, finding_description, BEST_PRACTICES_OWASP)
### Trivy SAST scanning report parsing
elif event['reportType'] == 'TRIVY-IMG-SCAN':
codebuildBuildArn = event['codebuildBuildArn']
containerName = event['containerName']
containerTag = event['containerTag']
results = event.get('report', {}).get('Results', [])
if results:
for result in results:
vulnerabilities = result.get('Vulnerabilities', [])
if vulnerabilities:
vulnerabilities_length = len(vulnerabilities)
for i in range(vulnerabilities_length):
p = ['Vulnerabilities'][i]
cveId = str(p['VulnerabilityID'])
cveTitle = str(p['Title'])
cveDescription = str(p['Description'])
cveDescription = (cveDescription[:1021] + '..') if len(cveDescription) > 1021 else cveDescription
packageName = str(p['PkgName'])
installedVersion = str(p['InstalledVersion'])
fixedVersion = str(p['FixedVersion'])
trivySeverity = str(p['Severity'])
cveReference = str(p['References'][0])
created_at = datetime.now(timezone.utc).isoformat()
if trivySeverity == 'LOW':
trivyProductSev = int(1)
trivyNormalizedSev = trivyProductSev * 10
elif trivySeverity == 'MEDIUM':
trivyProductSev = int(4)
trivyNormalizedSev = trivyProductSev * 10
elif trivySeverity == 'HIGH':
trivyProductSev = int(7)
trivyNormalizedSev = trivyProductSev * 10
elif trivySeverity == 'CRITICAL':
trivyProductSev = int(9)
trivyNormalizedSev = trivyProductSev * 10
else:
print('No vulnerability information found')
securityhub.import_trivy_findings_to_sh(i, containerName, containerTag, region, codebuildBuildArn, account_id, cveId, cveTitle, cveDescription, packageName, installedVersion, fixedVersion, trivySeverity, cveReference, created_at, trivyProductSev, trivyNormalizedSev)
else:
print('No vulnerabilities found in result:', result)
else:
print('No results found in the report')
else:
print("Invalid report type was provided")
else:
logger.error("Report type not supported:")
def lambda_handler(event, context):
""" Lambda entrypoint """
try:
logger.info("Starting function")
return process_message(event)
except Exception as error:
logger.error("Error {}".format(error))
raise
- Go to + icon, Go to New file.
- paste the below code, and then press ctrl+s, or cmd+s
import sys
import logging
sys.path.insert(0, "external")
import boto3
logger = logging.getLogger(__name__)
securityhub = boto3.client('securityhub')
# This function import agregated report findings to securityhub
def import_finding_to_sh(count: int, account_id: str, region: str, created_at: str, source_repository: str,
source_branch: str, source_commitid: str, build_id: str, report_url: str, finding_id: str, generator_id: str,
normalized_severity: str, severity: str, finding_type: str, finding_title: str, finding_description: str, best_practices_cfn: str):
print("called securityhub.py..................")
new_findings = []
new_findings.append({
"SchemaVersion": "2018-10-08",
"Id": finding_id,
"ProductArn": "arn:aws:securityhub:{0}:{1}:product/{1}/default".format(region, account_id),
"GeneratorId": generator_id,
"AwsAccountId": account_id,
"Types": [
"Software and Configuration Checks/AWS Security Best Practices/{0}".format(
finding_type)
],
"CreatedAt": created_at,
"UpdatedAt": created_at,
"Severity": {
"Normalized": normalized_severity,
},
"Title": f"{count}-{finding_title}",
"Description": f"{finding_description}",
'Remediation': {
'Recommendation': {
'Text': 'For directions on PHP AWS Best practices, please click this link',
'Url': best_practices_cfn
}
},
'SourceUrl': report_url,
'Resources': [
{
'Id': build_id,
'Type': "CodeBuild",
'Partition': "aws",
'Region': region
}
],
})
### post the security vulnerability findings to AWS SecurityHub
response = securityhub.batch_import_findings(Findings=new_findings)
if response['FailedCount'] > 0:
logger.error("Error importing finding: " + response)
raise Exception("Failed to import finding: {}".format(response['FailedCount']))
def import_trivy_findings_to_sh(count: int, containerName: str, containerTag: str, awsRegion: str, codebuildBuildArn: str, awsAccount: str, cveId: str, cveTitle: str, cveDescription: str, packageName: str, installedVersion: str, fixedVersion: str, trivySeverity: str, cveReference: str, created_at: str, trivyProductSev: str, trivyNormalizedSev: str):
print("called securityhub.py..................")
new_findings = []
new_findings.append({
'SchemaVersion': '2018-10-08',
'Id': containerName + ':' + containerTag + '/' + cveId,
'ProductArn': 'arn:aws:securityhub:' + awsRegion + ':' + ':product/aquasecurity/aquasecurity',
'GeneratorId': codebuildBuildArn,
'AwsAccountId': awsAccount,
'Types': [ 'Software and Configuration Checks/Vulnerabilities/CVE' ],
'CreatedAt': created_at,
'UpdatedAt': created_at,
'Severity': {
'Product': trivyProductSev,
'Normalized': trivyNormalizedSev
},
'Title': str(count) + '-Trivy found a vulnerability to ' + cveId + ' in container ' + containerName,
'Description': cveDescription,
'Remediation': {
'Recommendation': {
'Text': 'More information on this vulnerability is provided in the hyperlink',
'Url': cveReference
}
},
'ProductFields': { 'Product Name': 'Trivy' },
'Resources': [
{
'Type': 'Container',
'Id': containerName + ':' + containerTag,
'Partition': 'aws',
'Region': awsRegion,
'Details': {
'Container': { 'ImageName': containerName + ':' + containerTag },
'Other': {
'CVE ID': cveId,
'CVE Title': cveTitle,
'Installed Package': packageName + ' ' + installedVersion,
'Patched Package': packageName + ' ' + fixedVersion
}
}
},
],
'RecordState': 'ACTIVE'
})
response = securityhub.batch_import_findings(Findings=new_findings)
if response['FailedCount'] > 0:
logger.error("Error importing finding: " + response)
raise Exception("Failed to import finding: {}".format(response['FailedCount']))
- The file name should be securityhub.py, and then go to save.
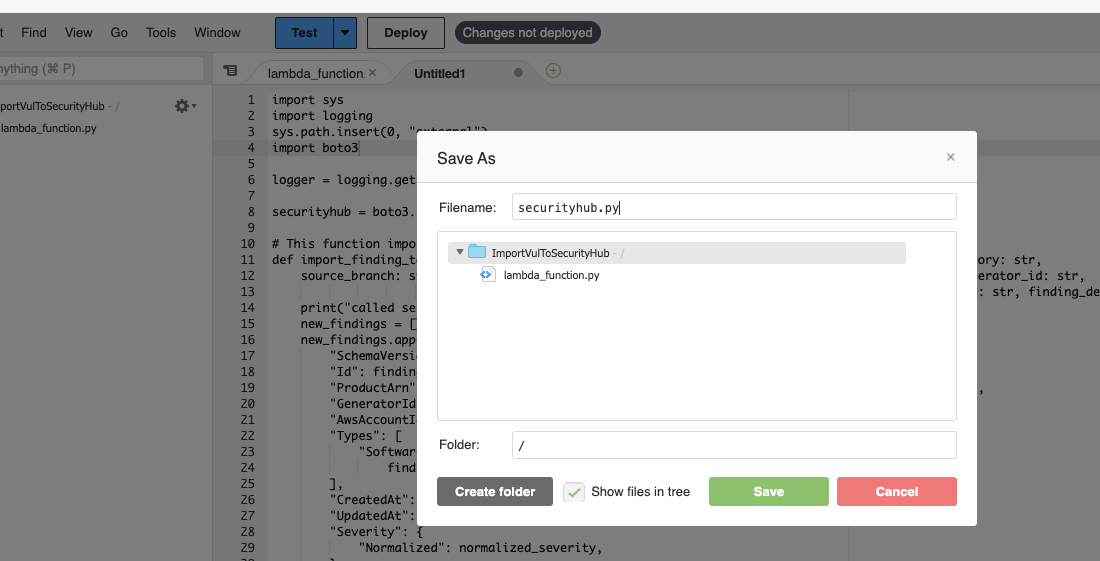
- After saved the file, then click on deploy button to deploy the changes.
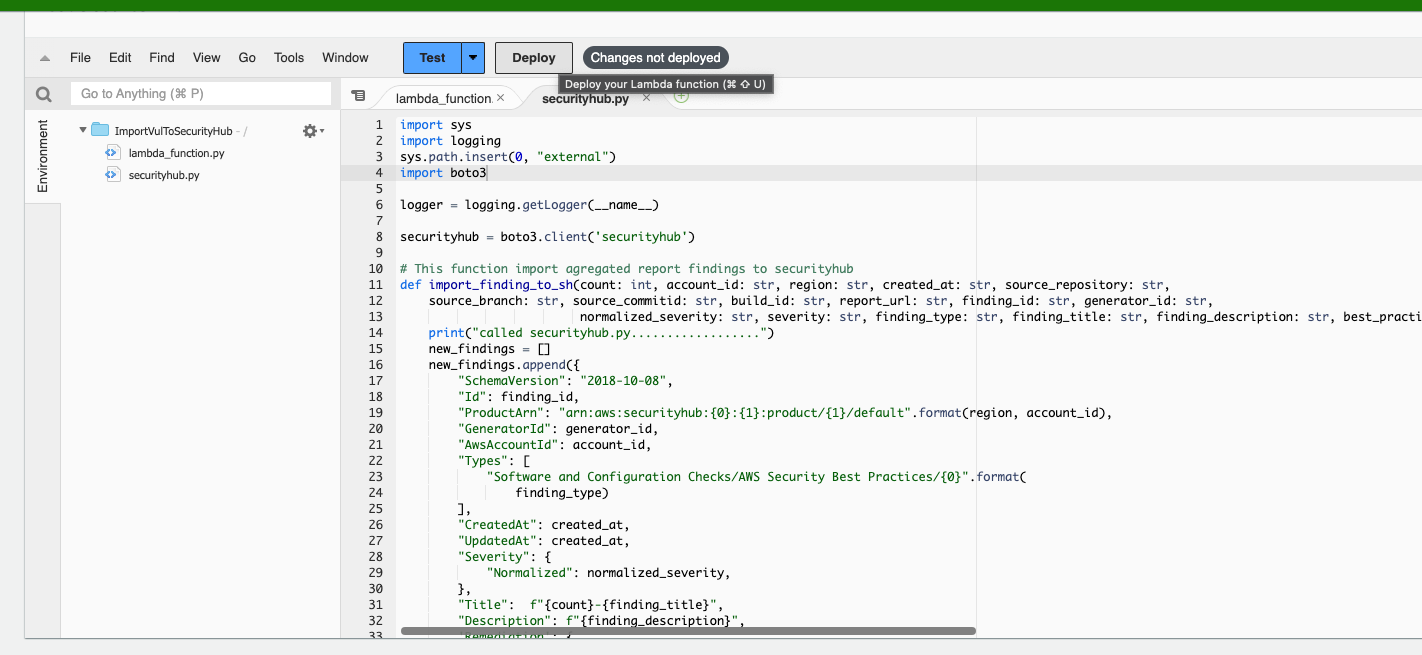
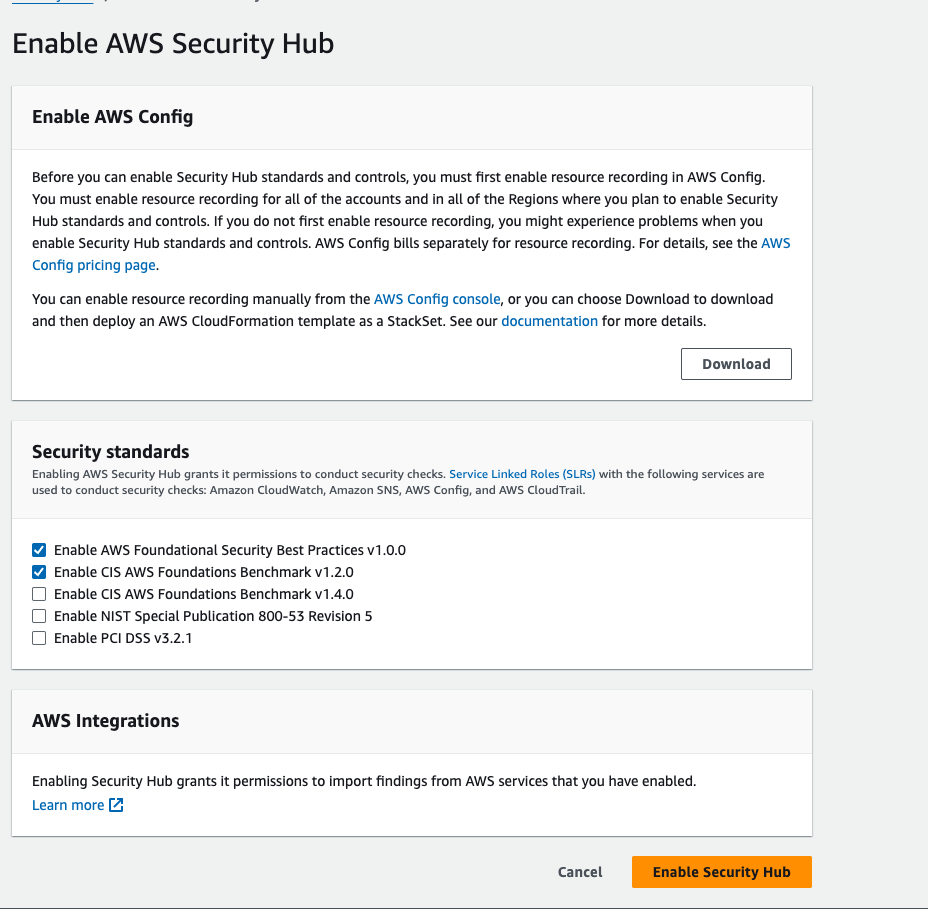
Step 11: Setup the Security Hub.
Go to AWS Search console, search for security hub, Click on "Go to security hub"
Then enable the security hub.
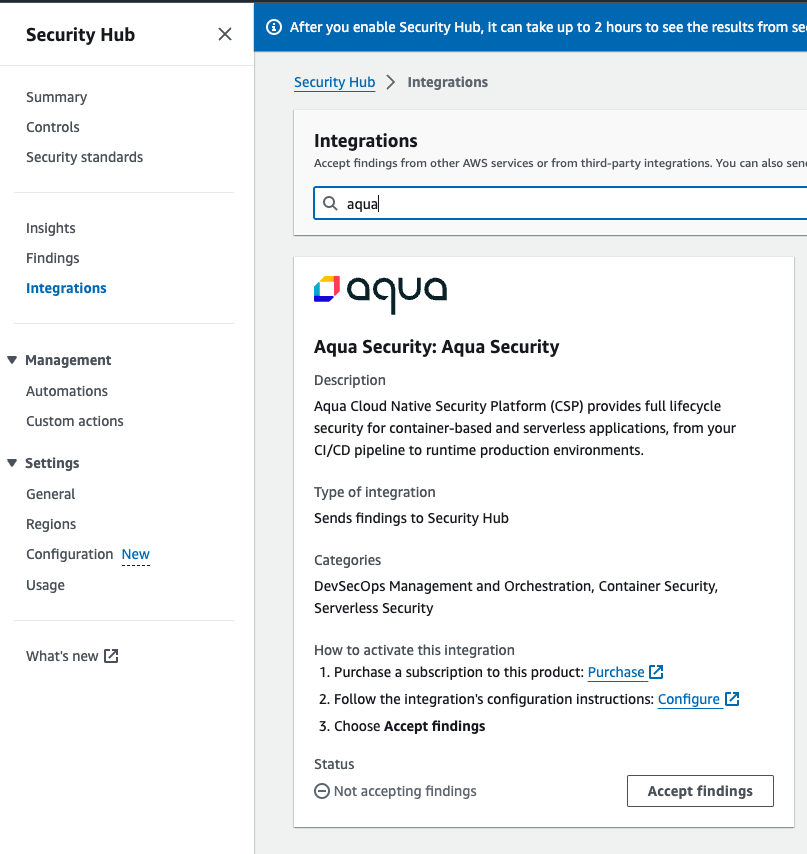
- Go to integration, Search for Aqua, then click on Accept findings.
Step 12: Setup the ECR.
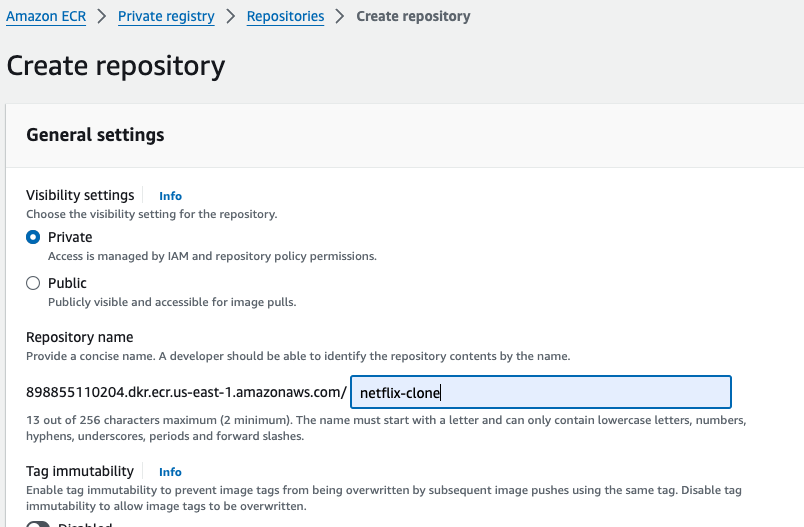
Go to AWS search console, and search for ECR, and then click on get started.
the repository name should be netflix-clone, because this name is hardcoded inside the buildspec file. if you want to change this name then you need to also change the name from the buildspec file. then click on create repository.
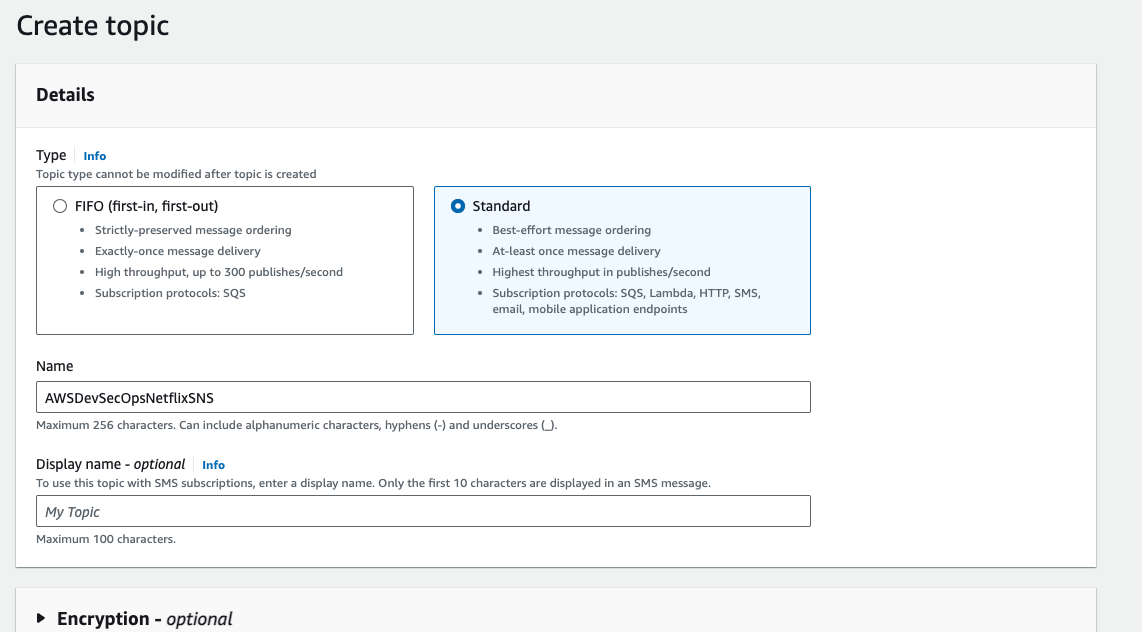
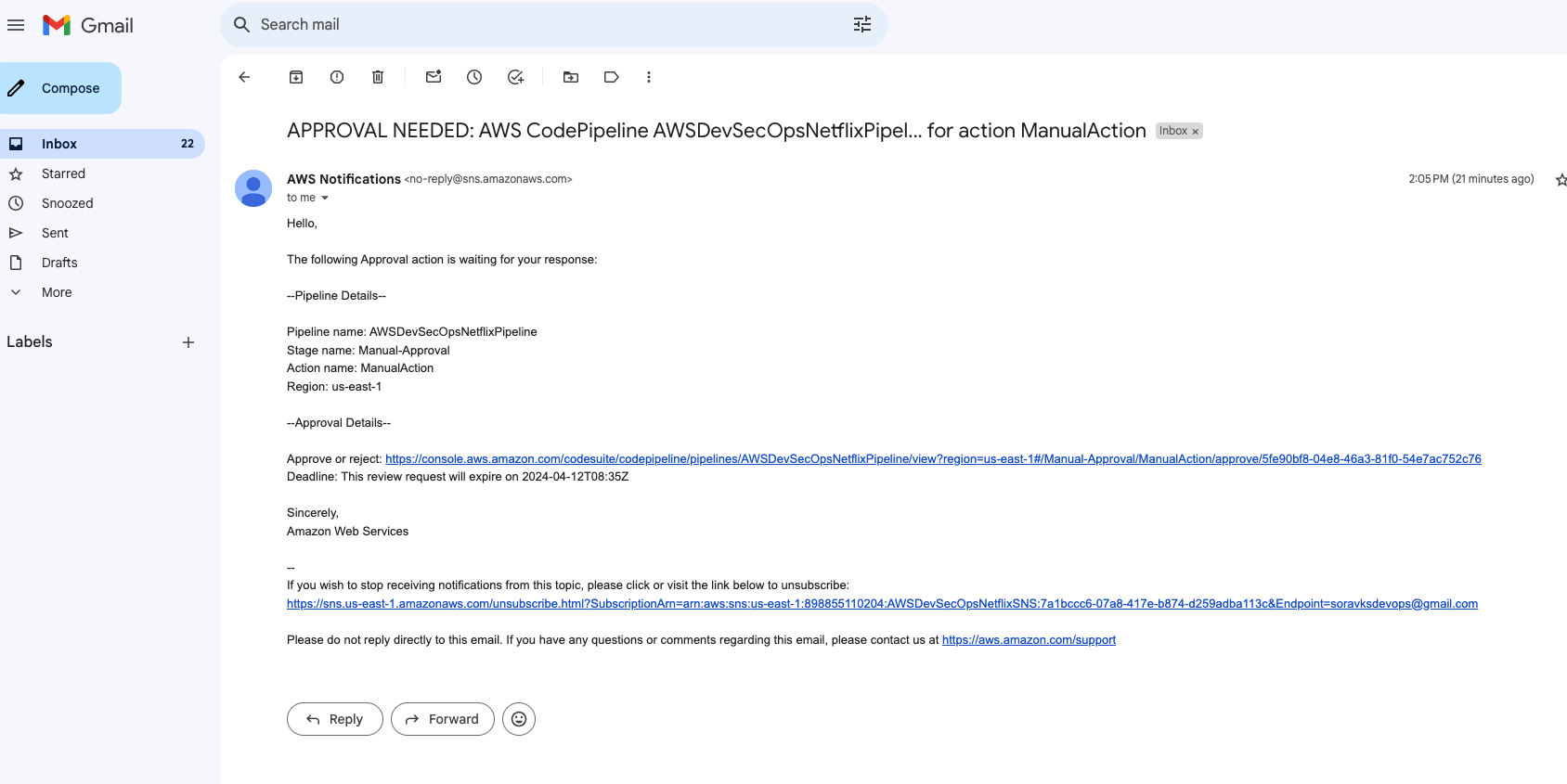
Step 13: Setup SNS notification for manual approval.
- Go to aws search console and search for SNS, and then click on topic, and then go to create a new topic. the type should be standard. Give any name to the topic. then click on create topic.
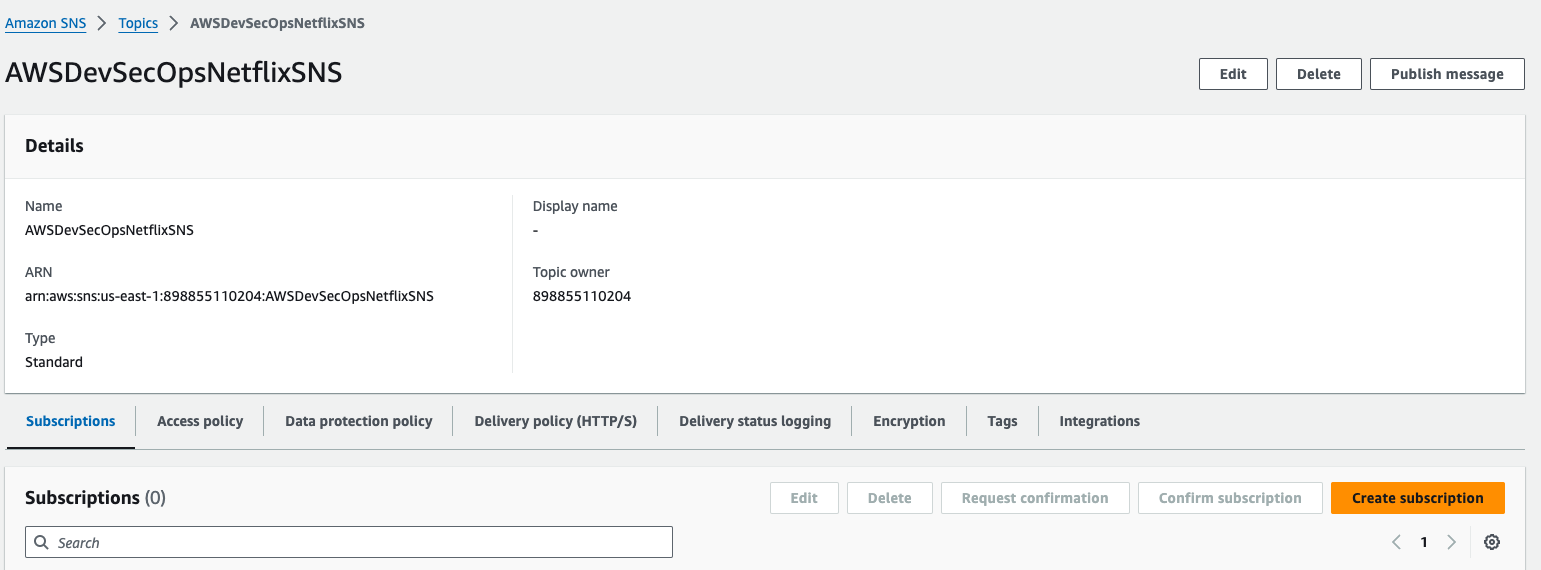
Once the topic is created, then we have to create a subscription.
Click on create subscription.
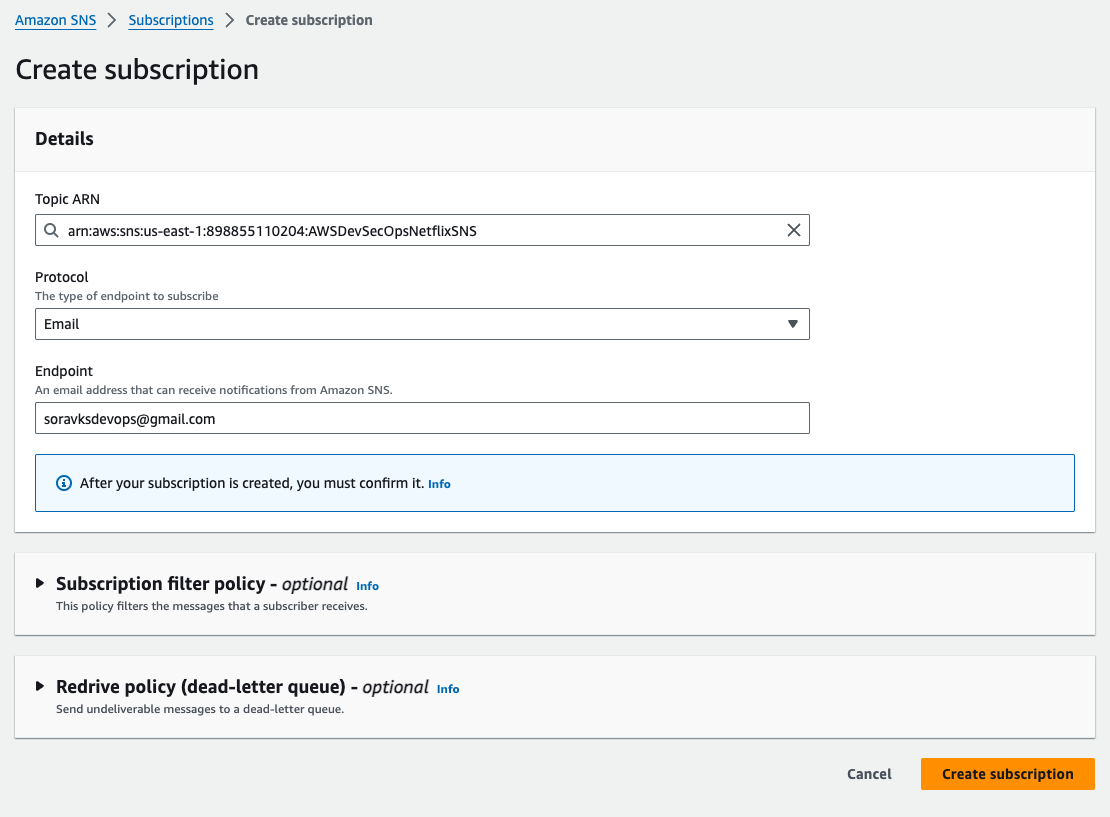
- select the protocol email, and enter your gmail inside the endpoint block. and then clock on create subscription button.
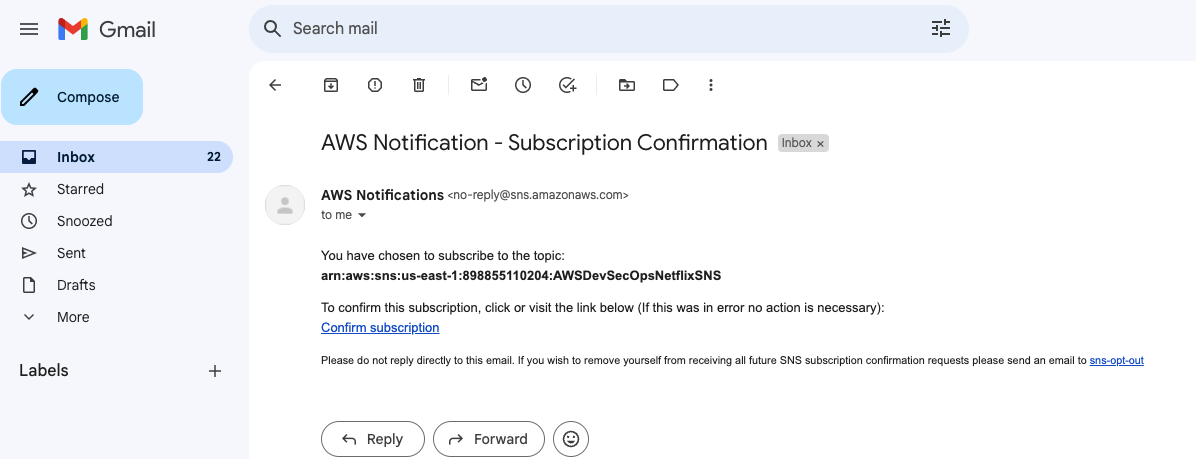
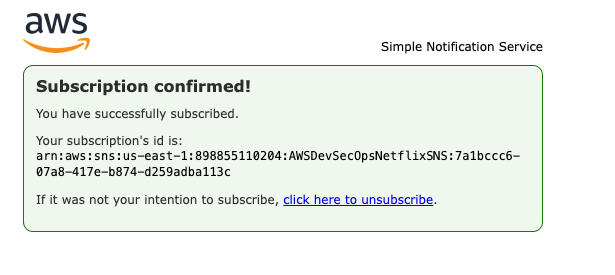
- After clicked on susbscription button, go to your mail inbox, and then click on confirm subscription. when we click on confirm subscription button then only we can receive the mail.
Step 14: Setup the Codepipeline.
Go to AWS search console, search for codepipeline, first of all fork the repo in your personal github account, then only you can perform the further steps.
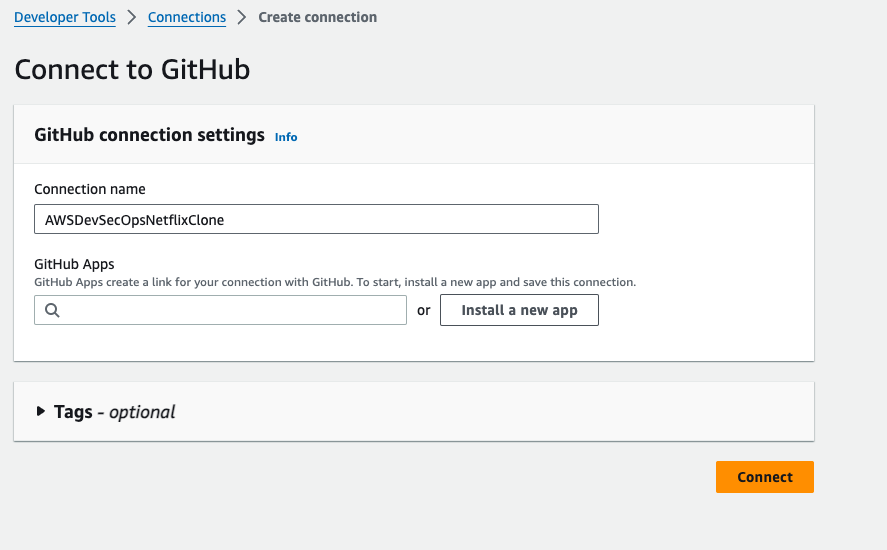
Go to developer tools, go to settings, go to connections, click on create connection.
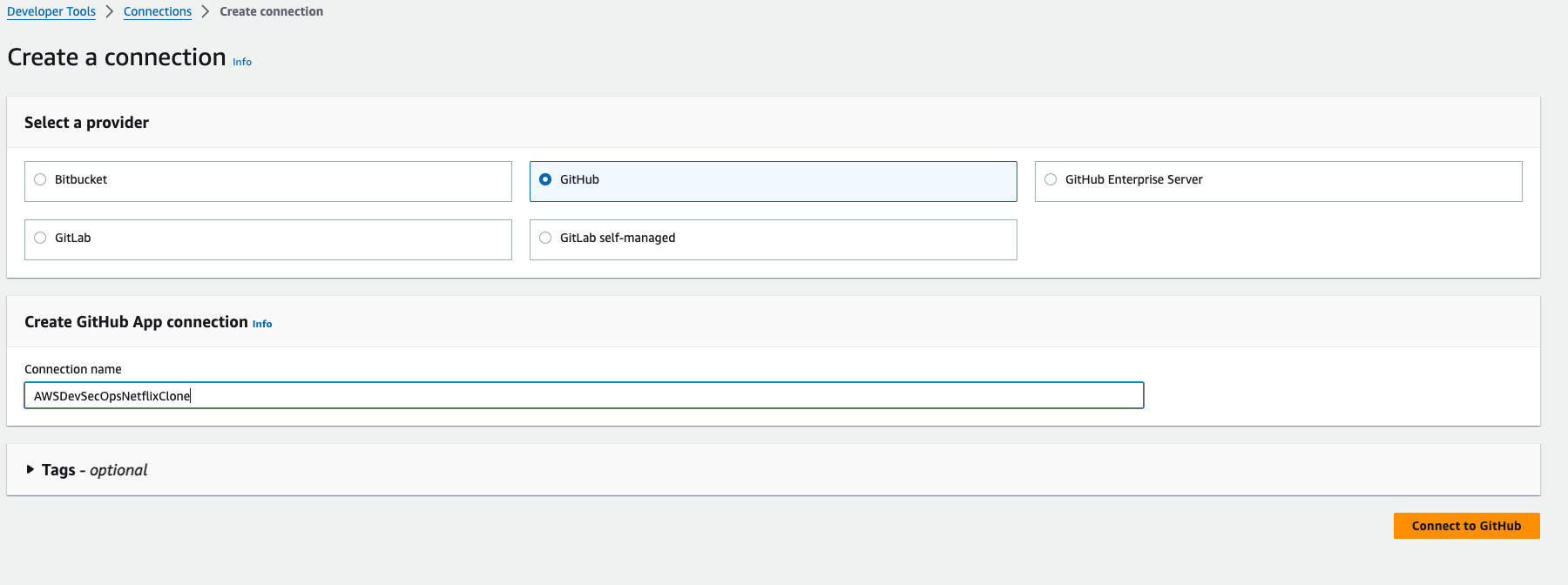
- Select GitHub as a provider, and then give any name for the connection, then click on connect to github.
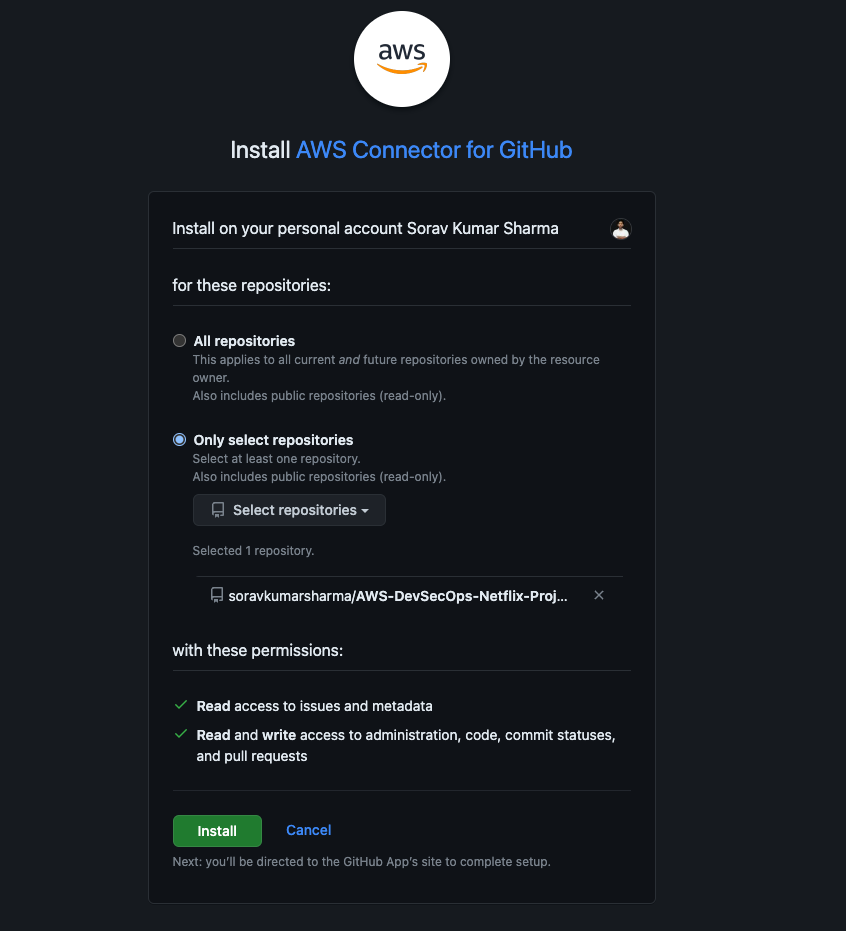
- Click on Install a new app,
login the github, and then you need to configure the aws connector for the github repo.
Click on "Only select repositories", and the select the forked repo, and then click on install.
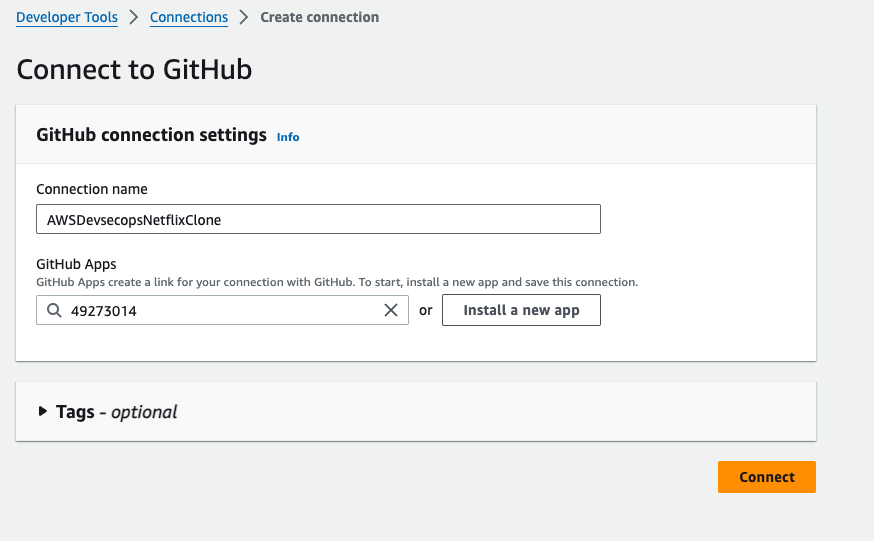
- After click on install, you will be redirected to this below page, and then click on connect.

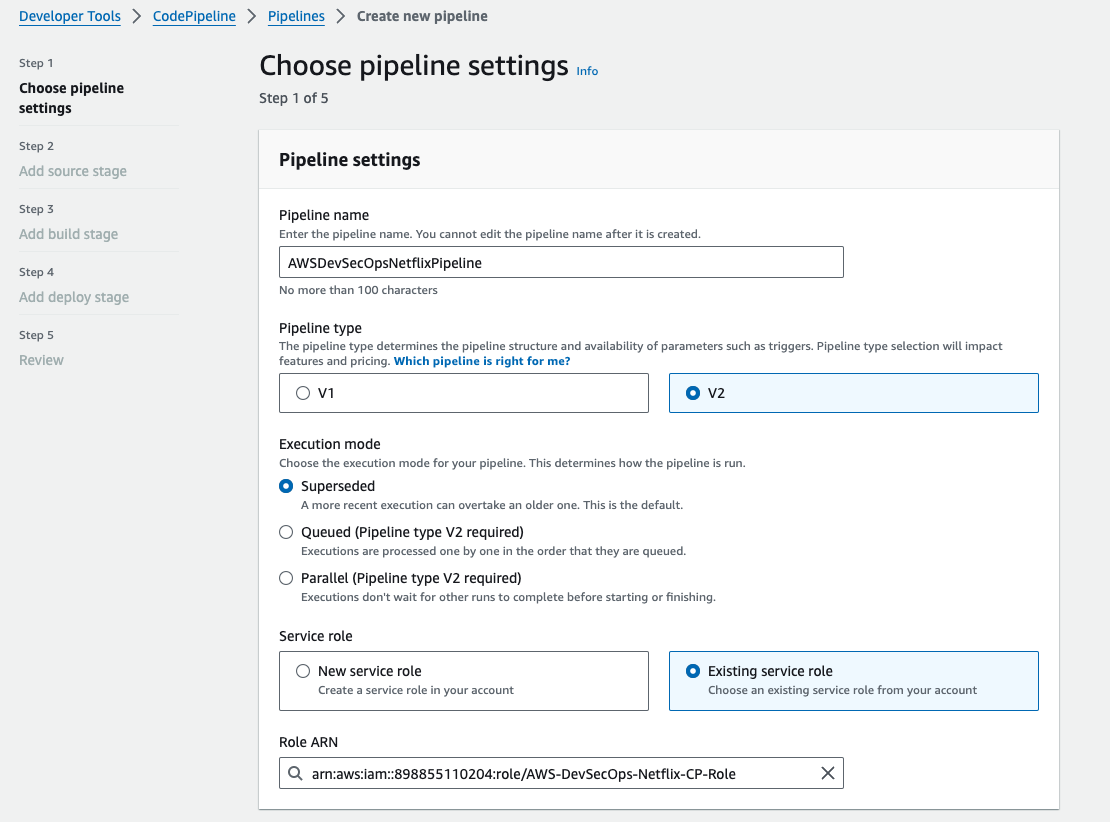
Go to pipelines -> then go to create a pipline.
Give the pipeline name "AWSDevSecOpsNetflixPipeline", the pipeline type should be v2, and select the execution mode "Superseded", and in the service role, select the existing service role. because we already created a serivce with the required policies, then click on next.
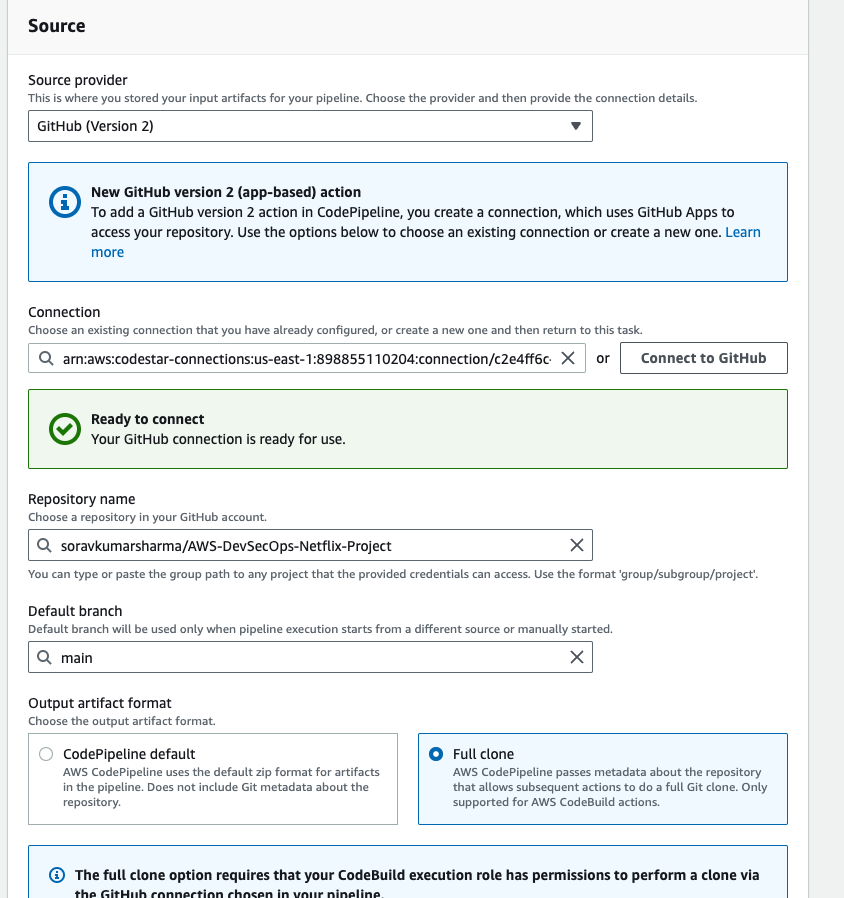
After clicking on next, the source provider should be github version 2, and in the connectin block, select the listed connection that created before, we don't need to click on connect to github because we already did this process.
Select the repository name, select the branch as main, output artifact format should be full clone,
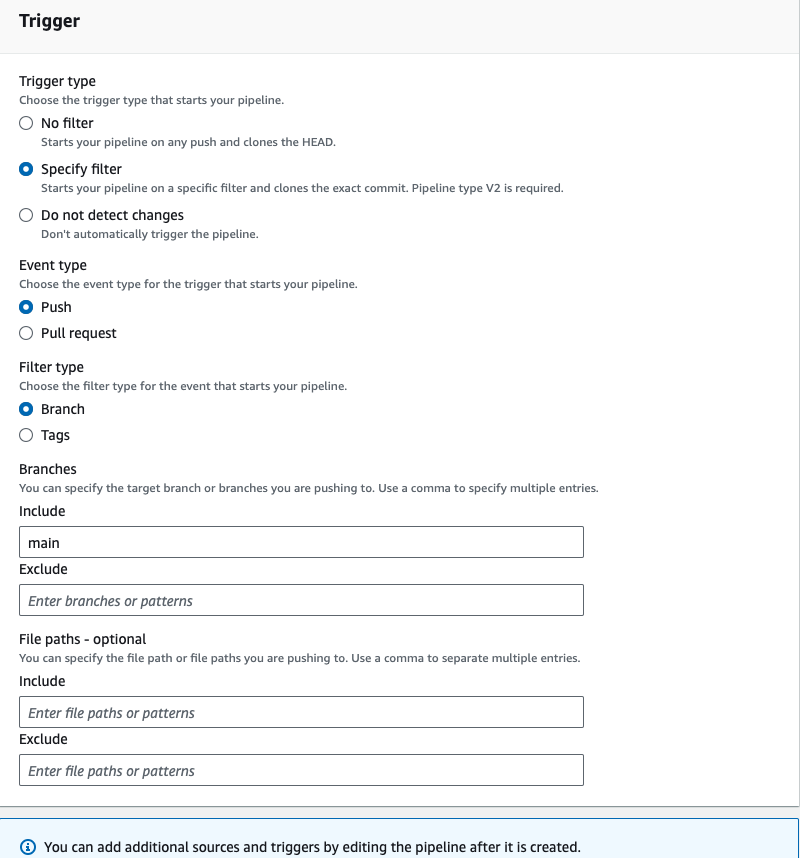
- In the trigger section, specify the trigger like when you want to run your pipeline. after specifying then click on next.
- In the build stage, the build provider should be codebuild, select the us-east-1 region, and then click on create project.
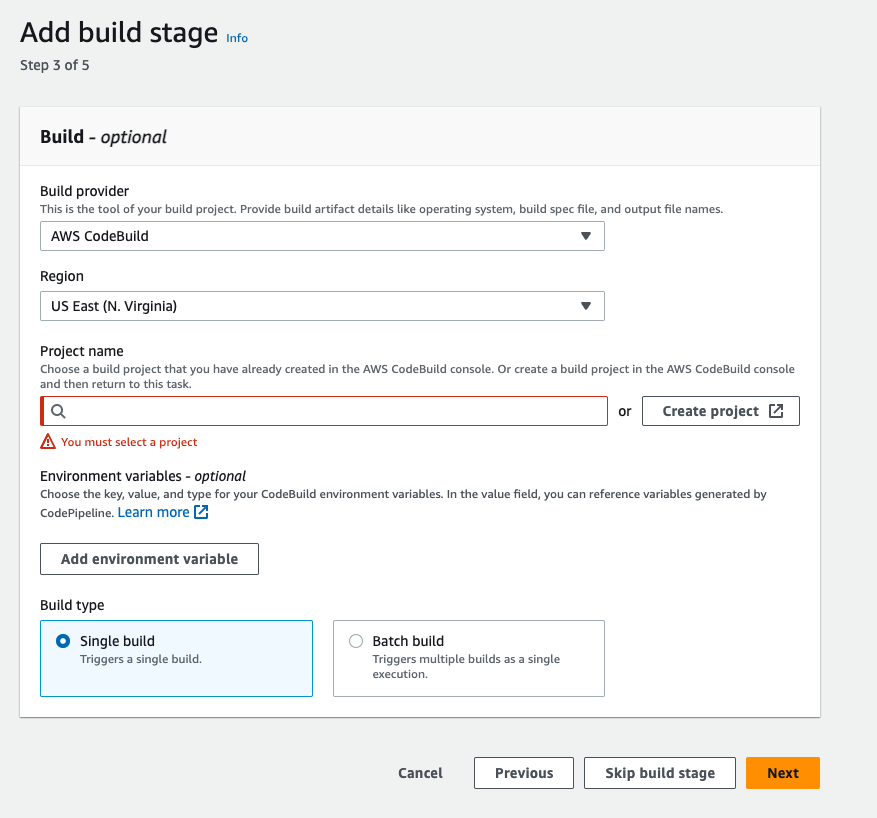
- Give the Project name SCA means static code analysis.
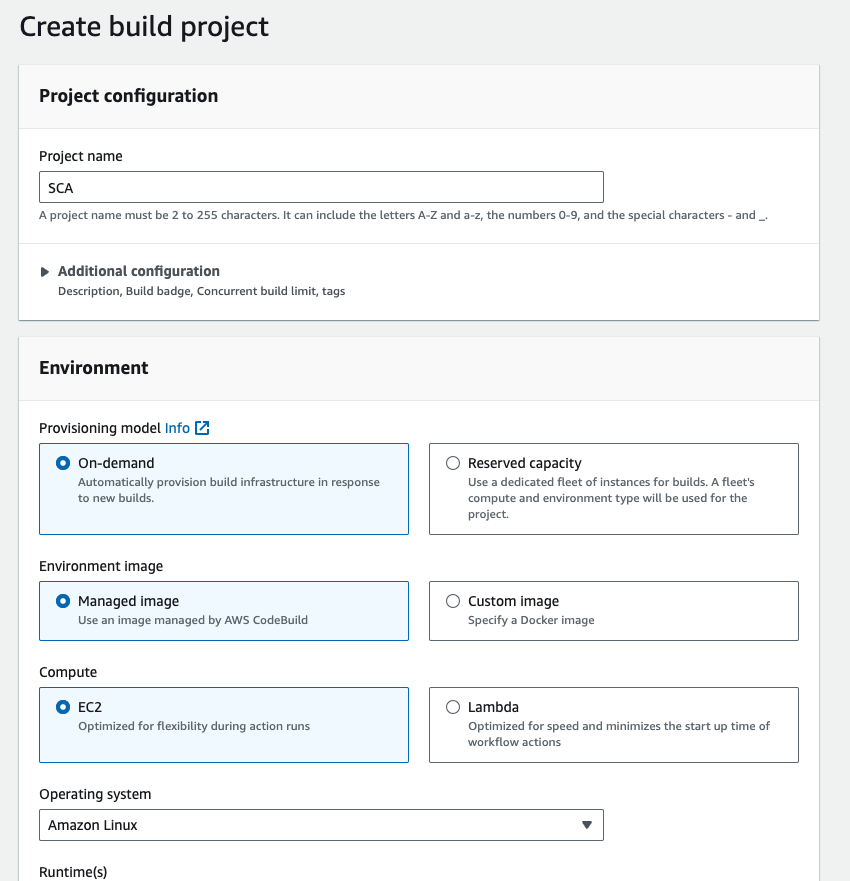
- In the environment section, the service role should be existing service role, because if you don't created the serivce role before then check our previous steps, otherwise you will get permission erros.
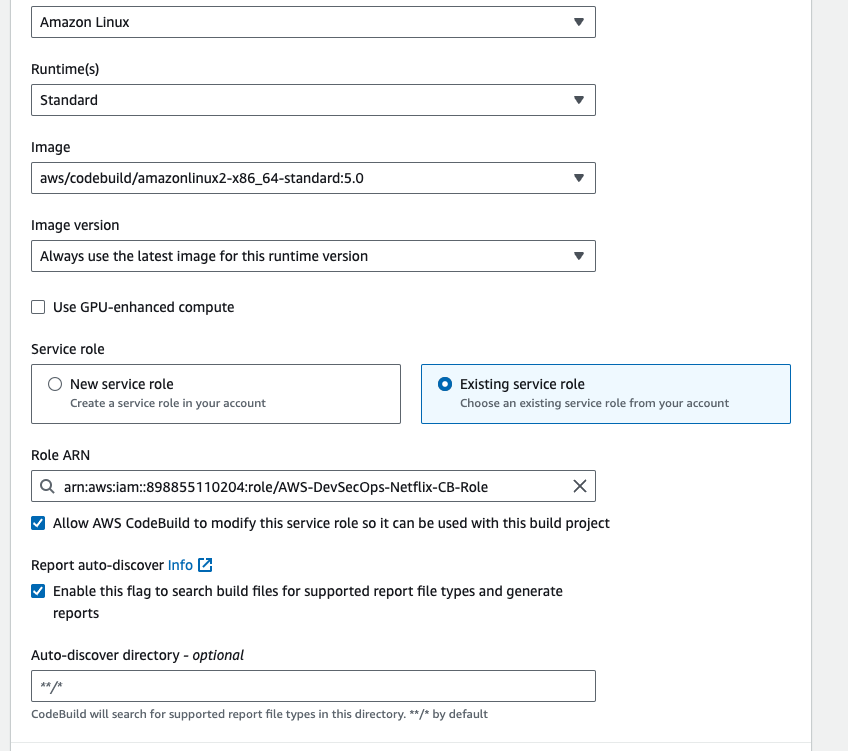
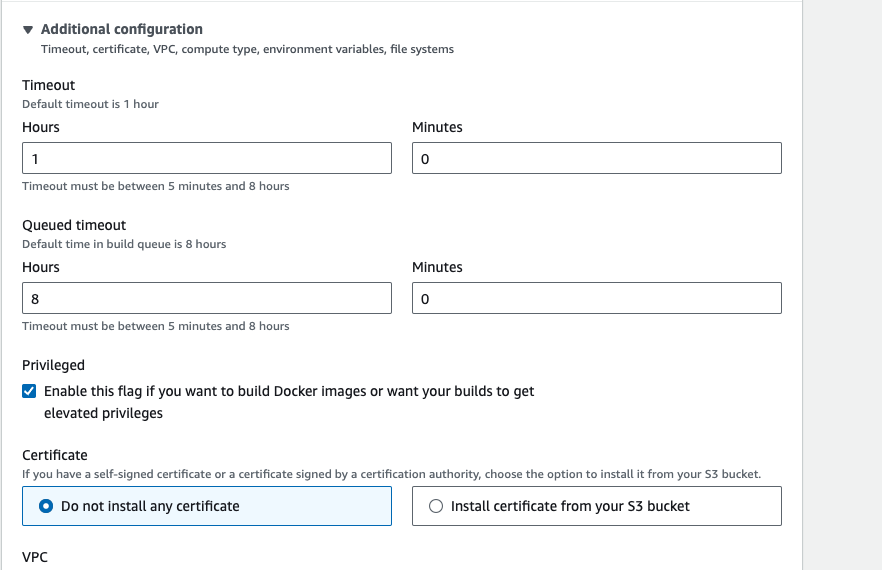
- Go to Additional configuration -> enable the privileged check box.
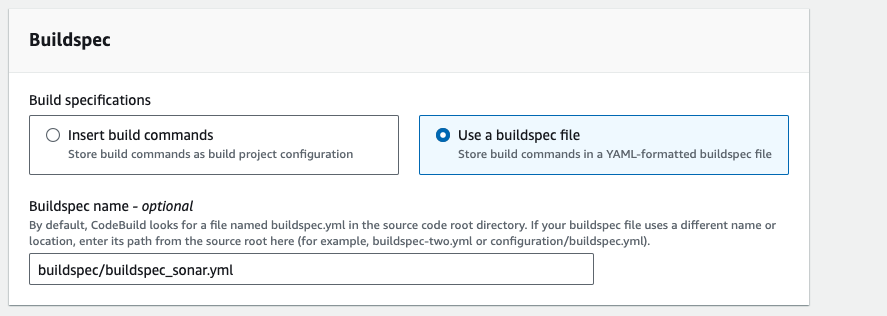
- Go to buildspec section, in this section select build specifictions "use a buildspec file", and give the path name. then click on continue to codepipeline
- Click on next
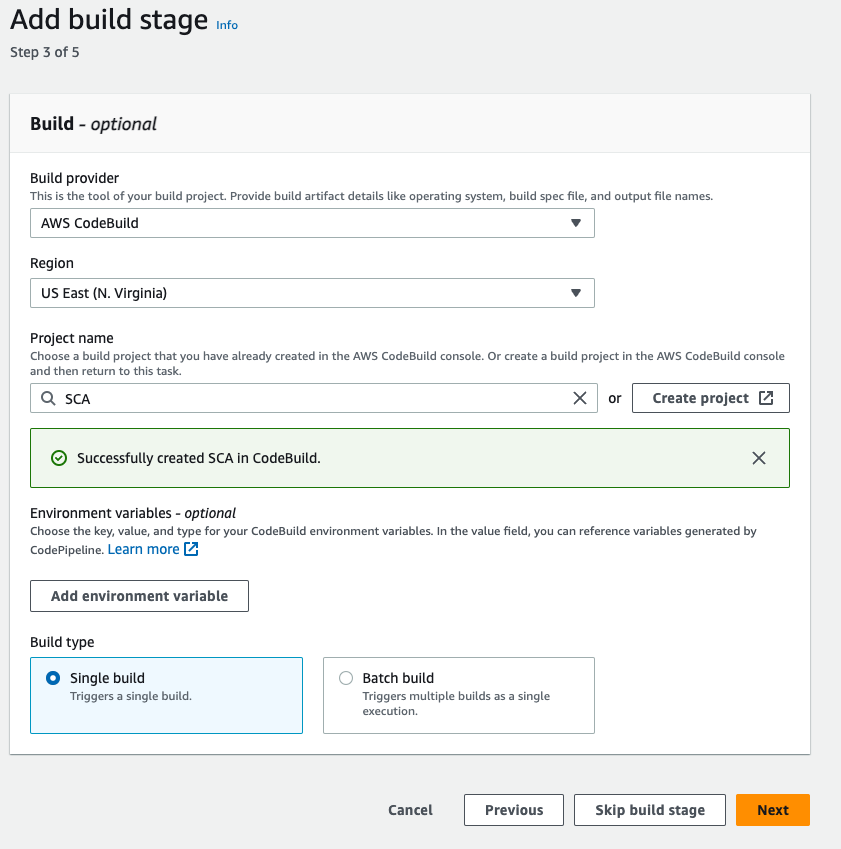
then click on skip the deploy stage, and then click on next then click on create pipeline.
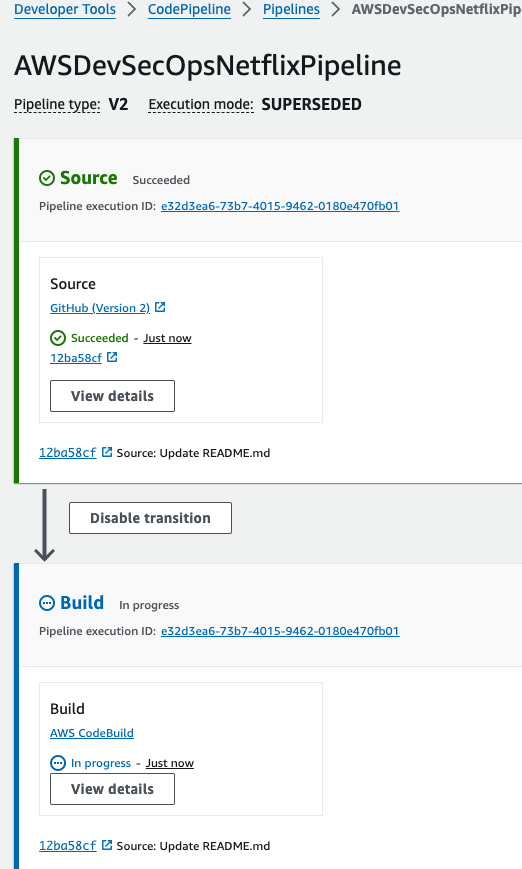
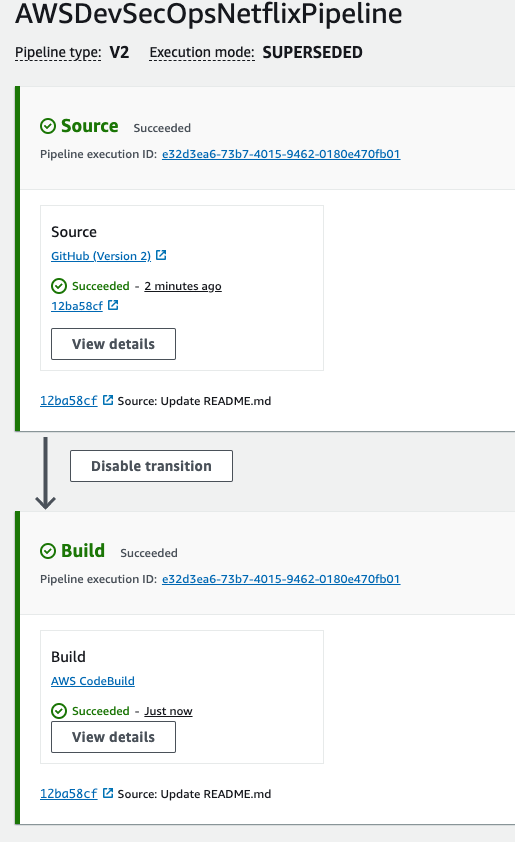
- Go to sonarqube url -> click on projects.
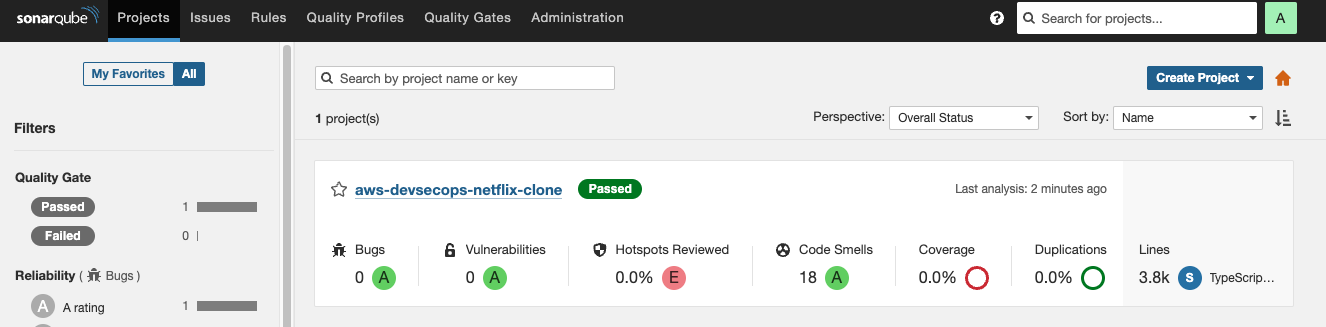
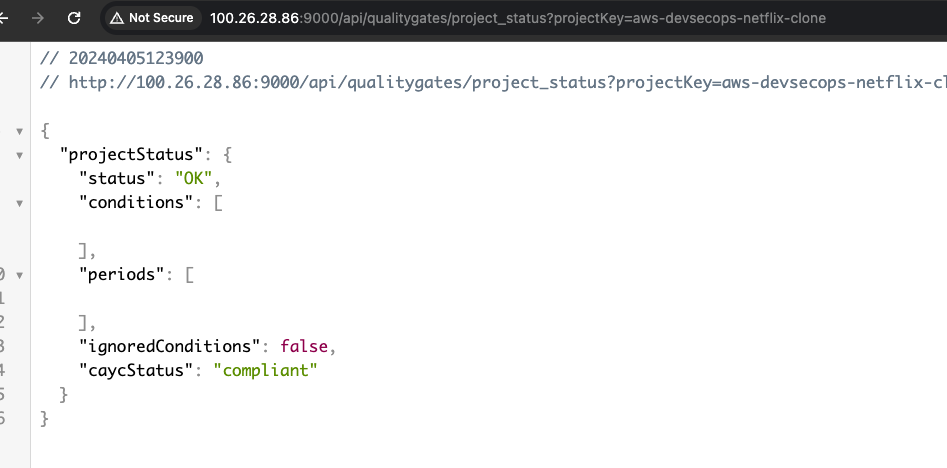
- Getting quality status is OK, if the qualtiy status is not ok then build will be failed.
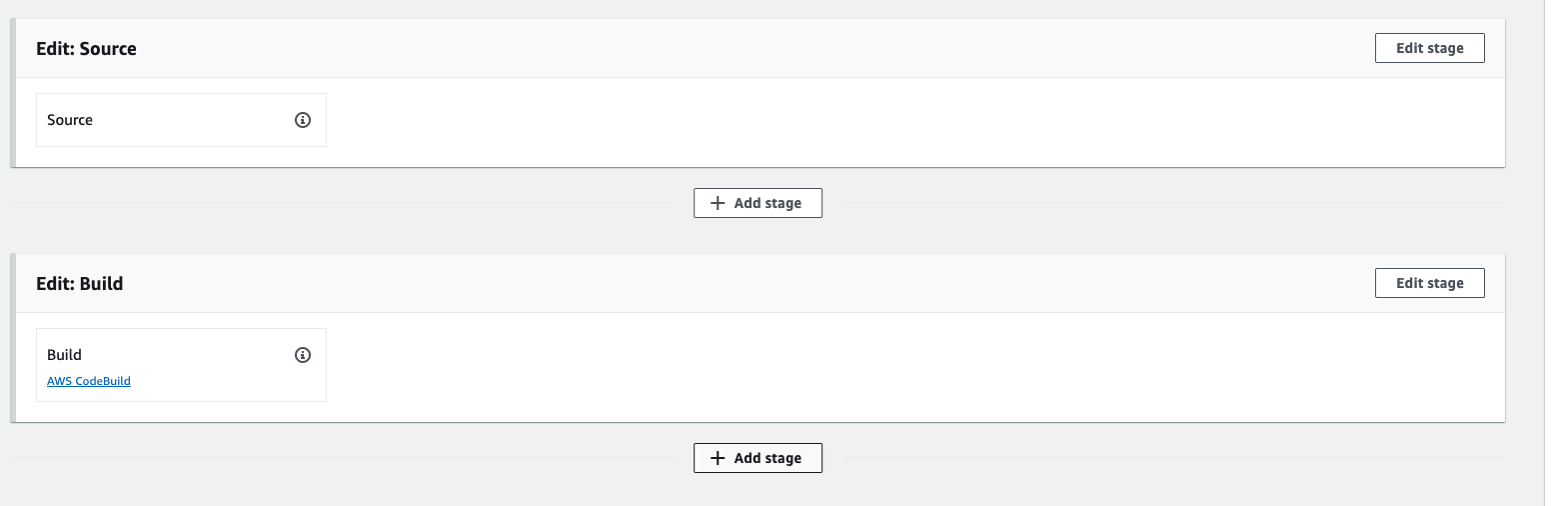
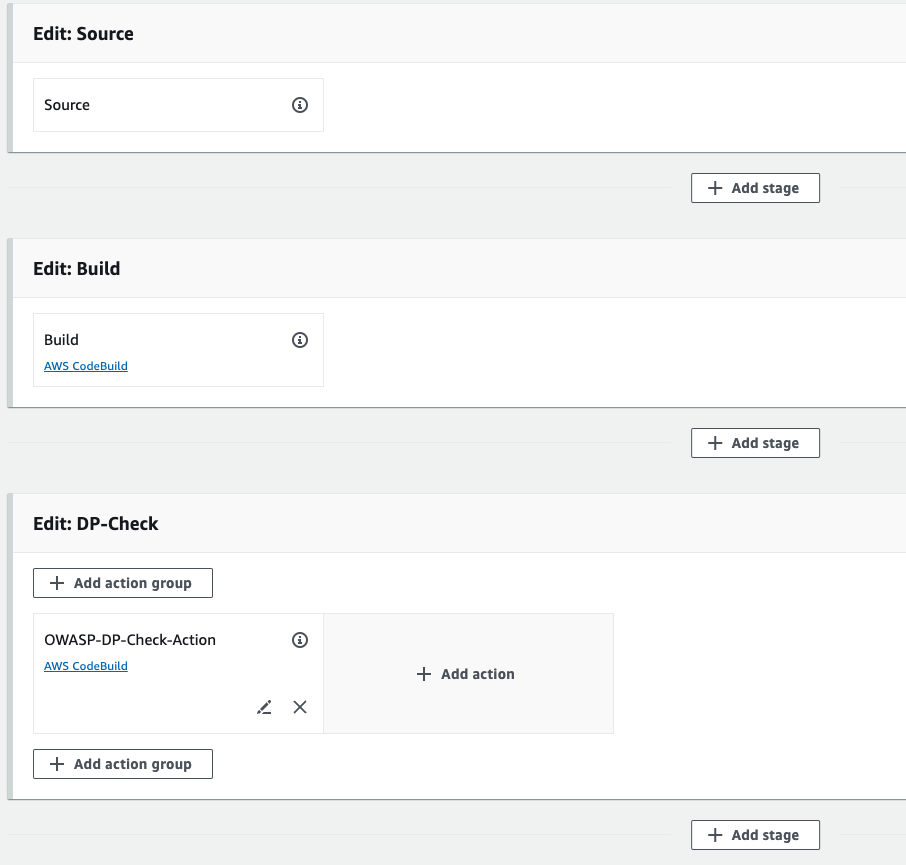
Now, we need to add more stages, So to add codebuild stages then click on edit button.
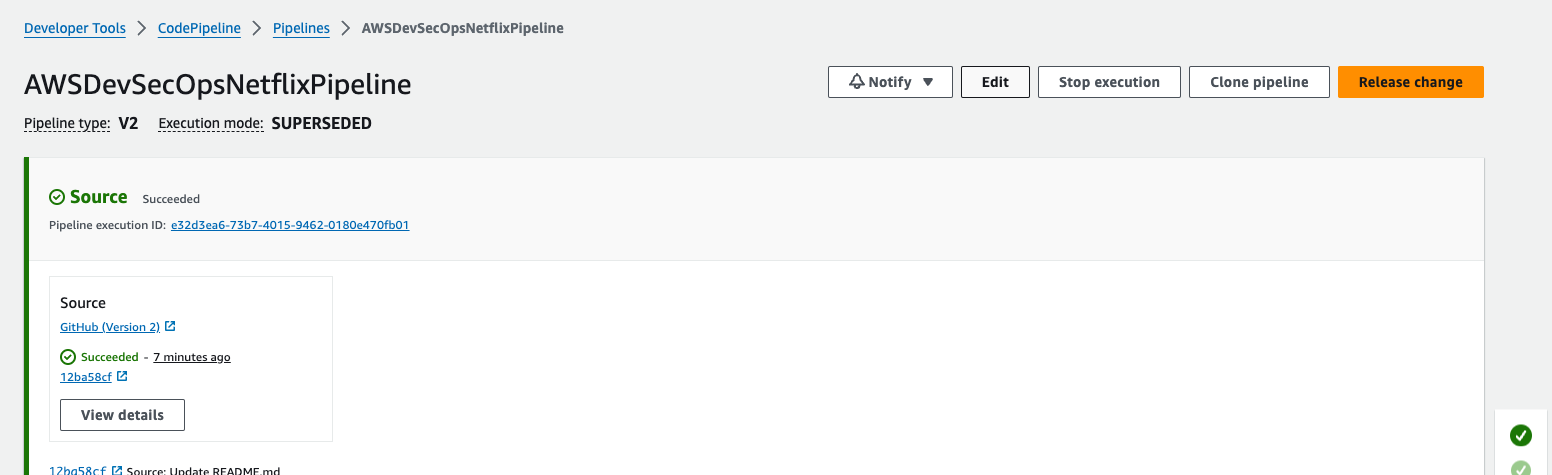
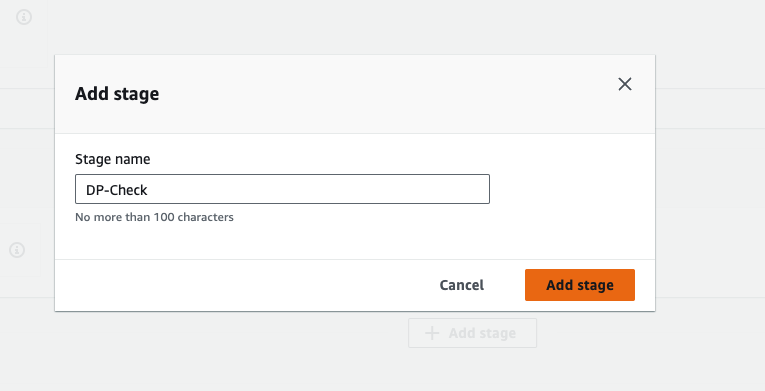
- Click on Add stage, Give the stage name DP-Check, means we are using OWASP dependency checker tool.
- Click on add section group.
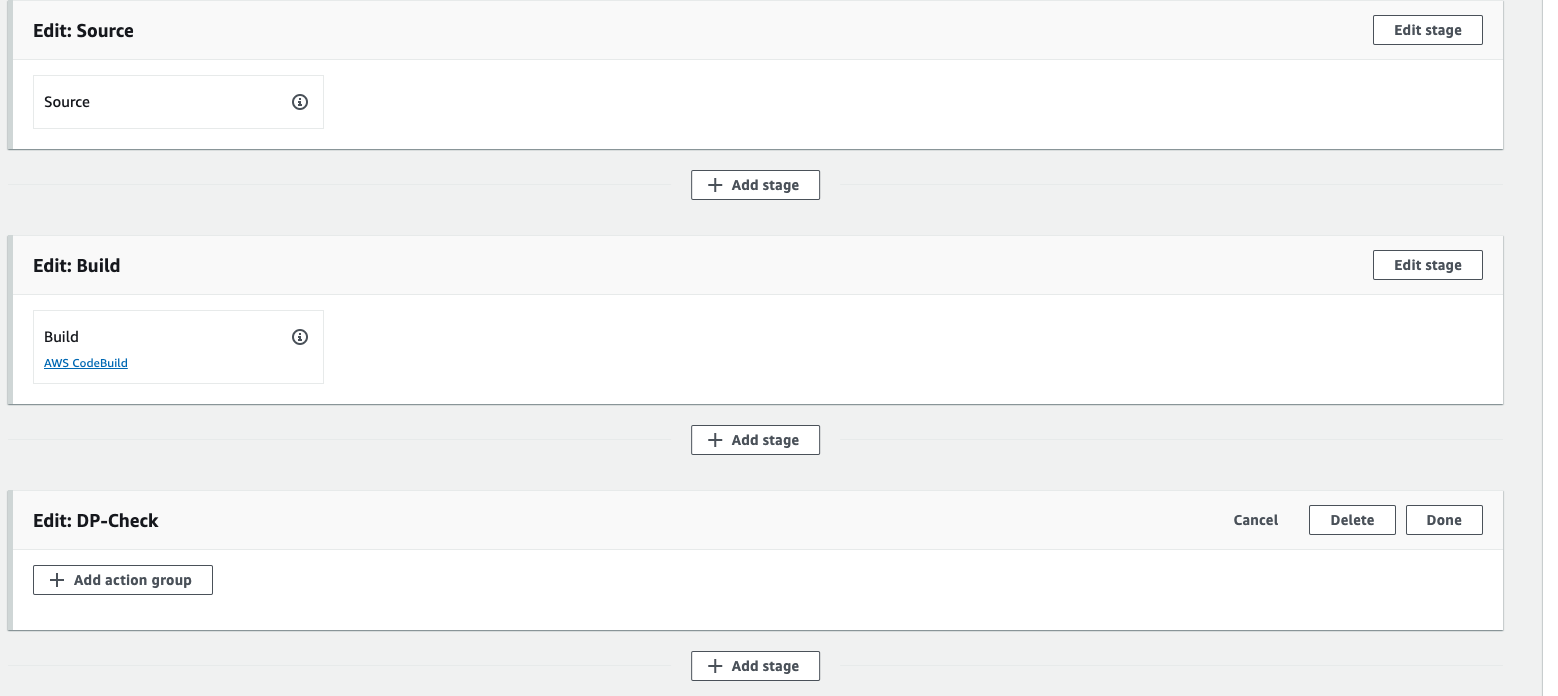
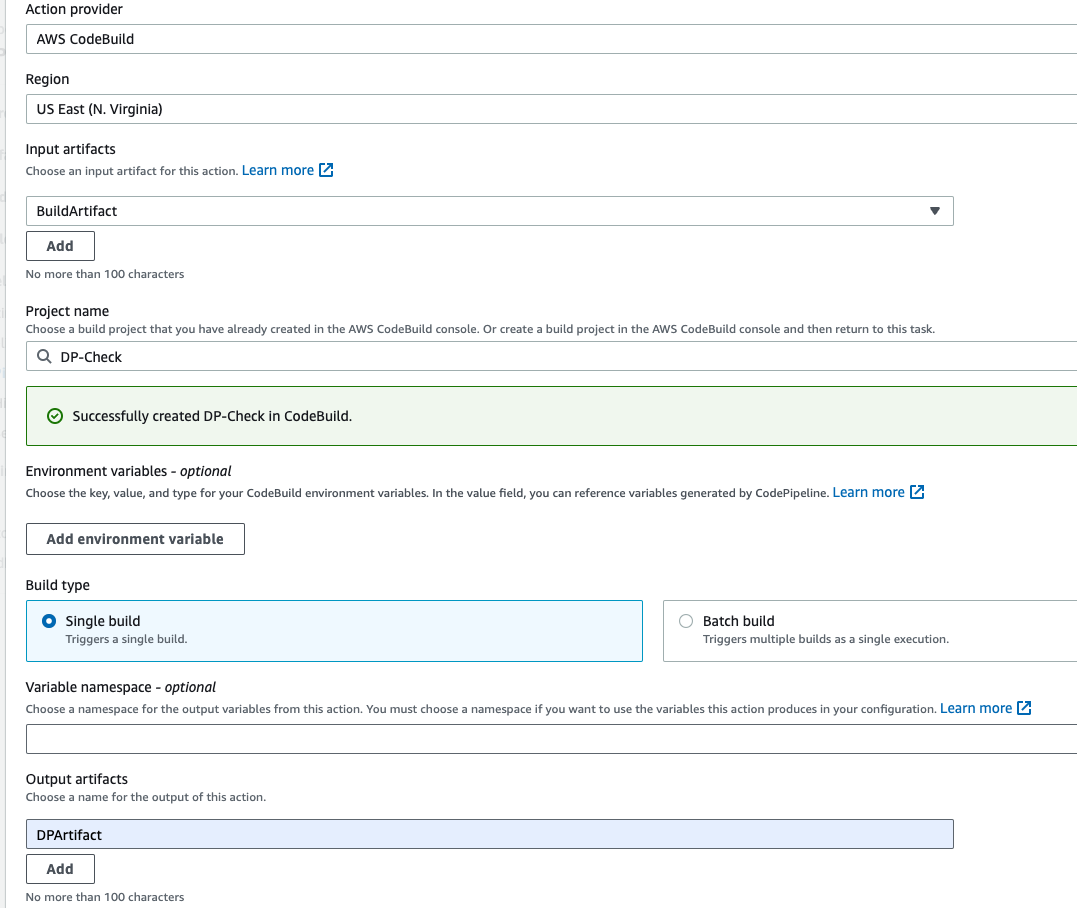
- Give the Action name, OWASP-DP-Check-Action, Action provider should be codebuild, select the region us-east-1, select the input artifact as buildartifact, because we are getting the artifact from the previous build, then click on create a project.
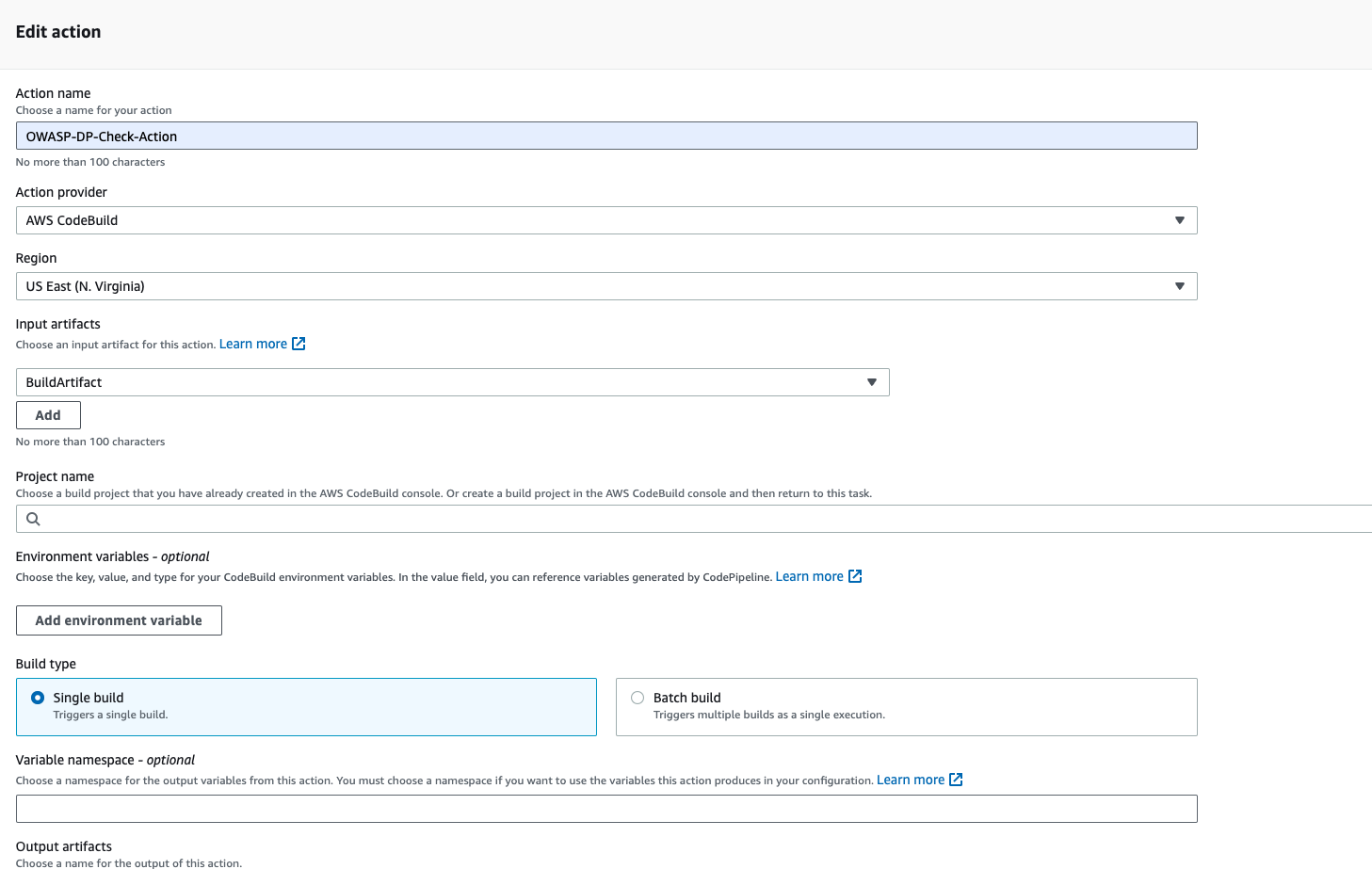
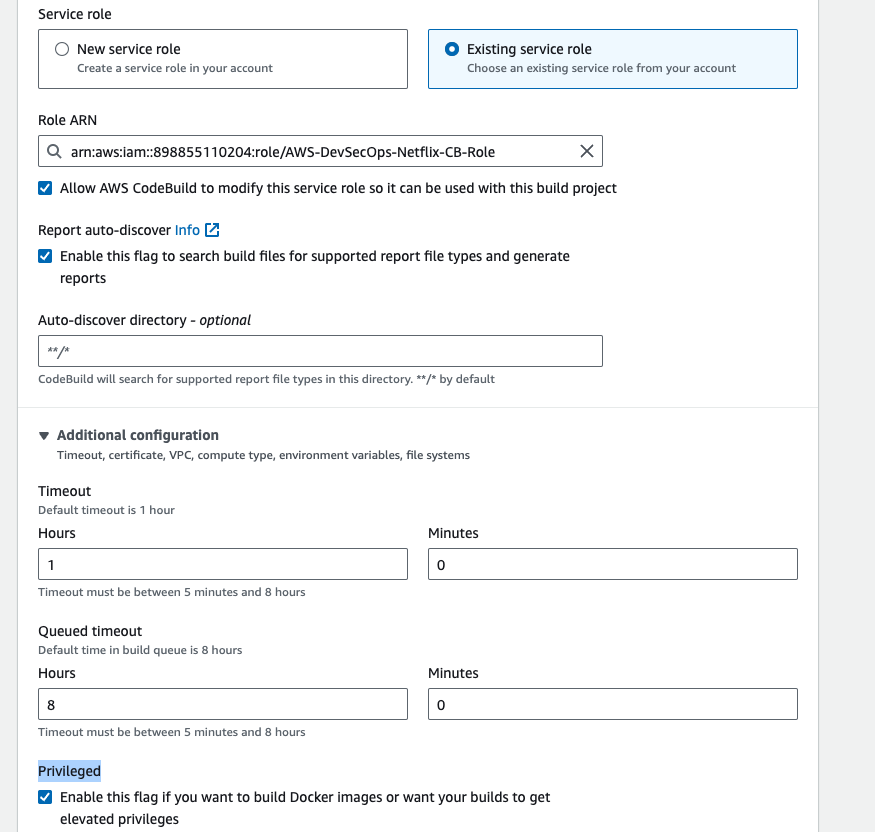
- Give the project name DP-Check, and in the environment section service role select the existing service role, and then go to addtional configuration, enable the Privileged check box.
- In the buildspec section, select the build specifications as buildspec file and then enter the path then click on continue to codepipeline.
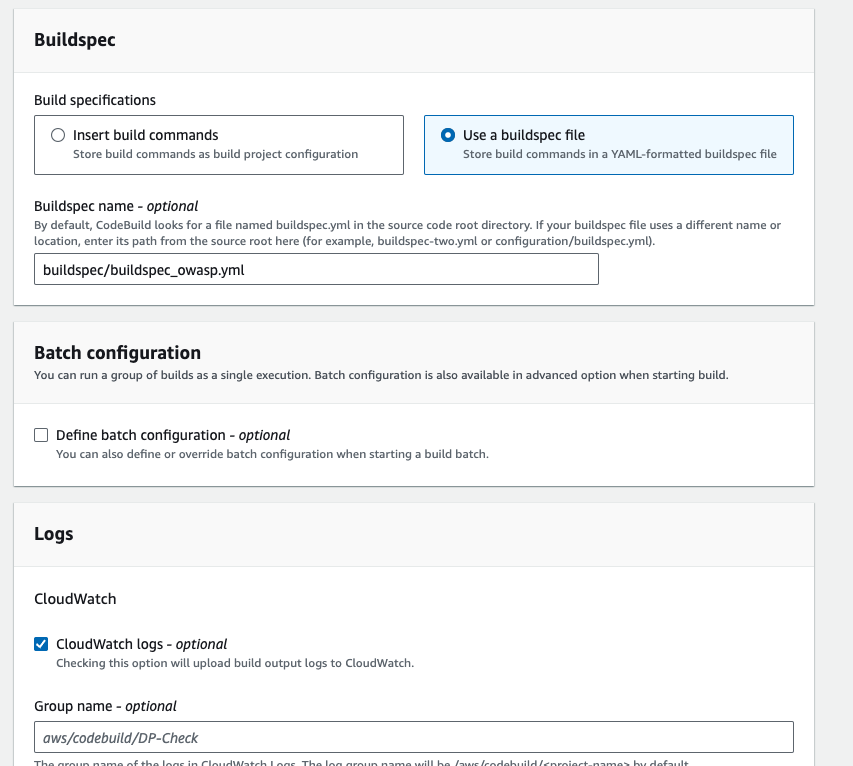
- Select the Project name, and in the output artifact type DPArtifact, then click on done.
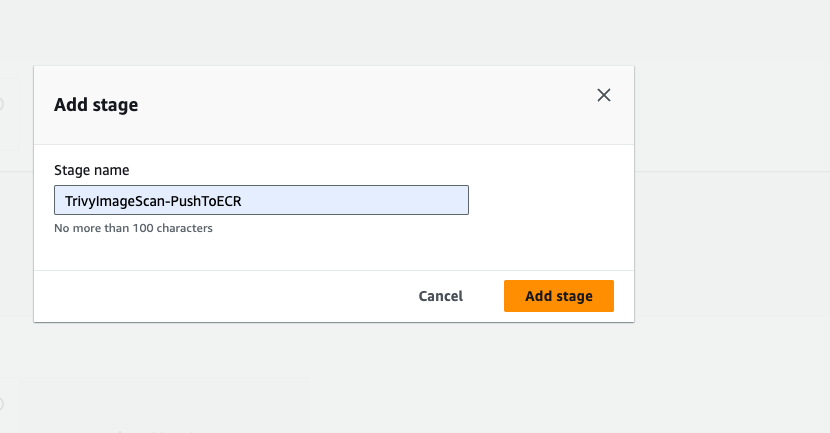
- Click on again Add stage, now we are going to add one more build or stage for trivy.
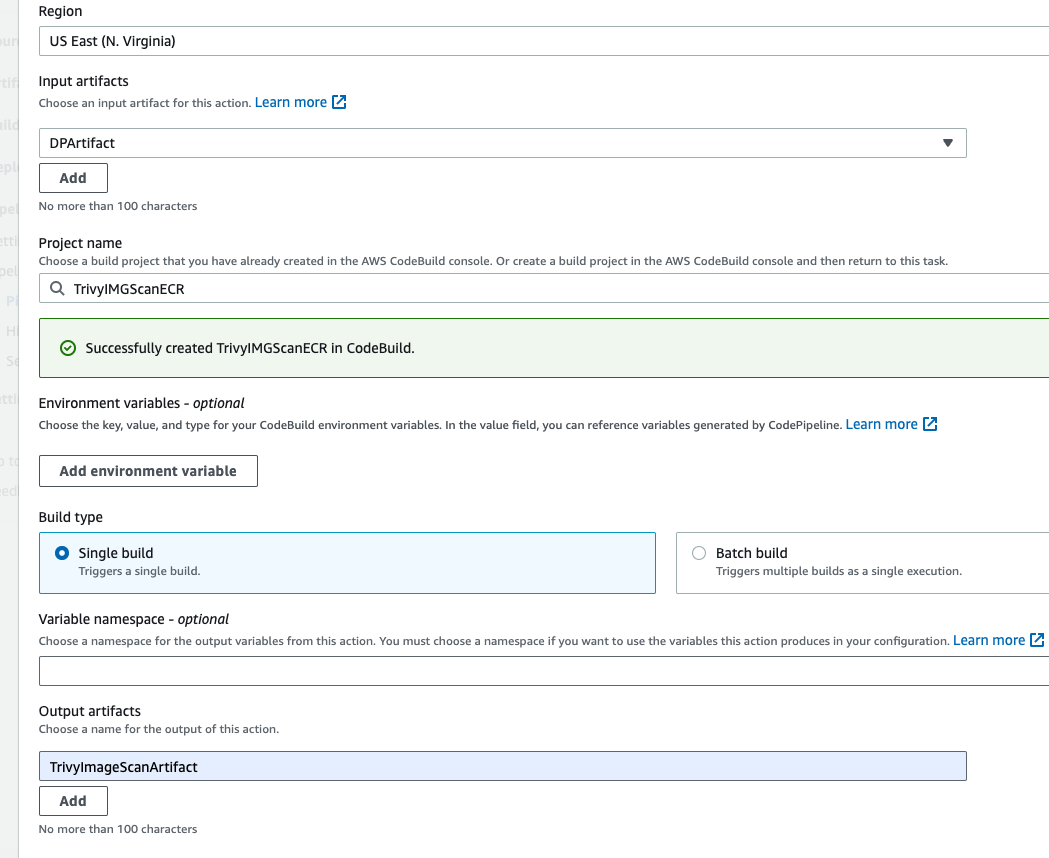
Give the stage name TrivyImageScan-PushToECR, then click on add stage, Go to add action group.
- Action name should be TrivyECRAction, action provider should be codebuild, and in the input artifact select the DPArtifact, and then create a new project.
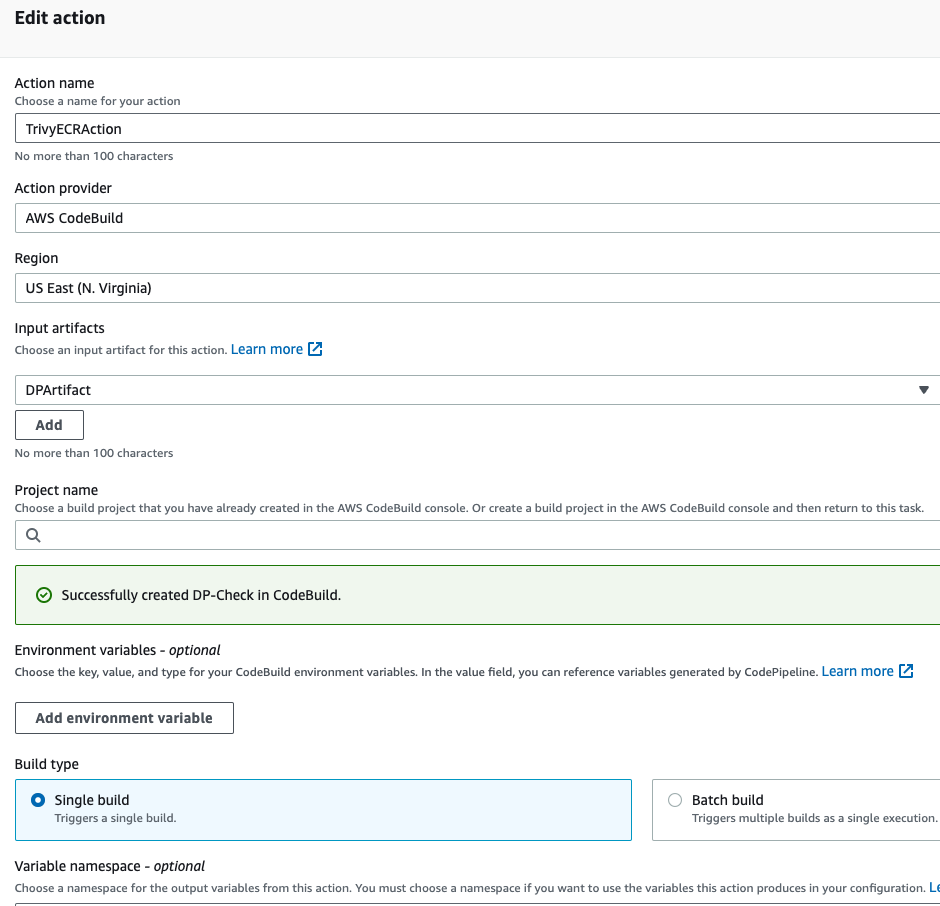
- Give the project name TrivyIMGScanECR.
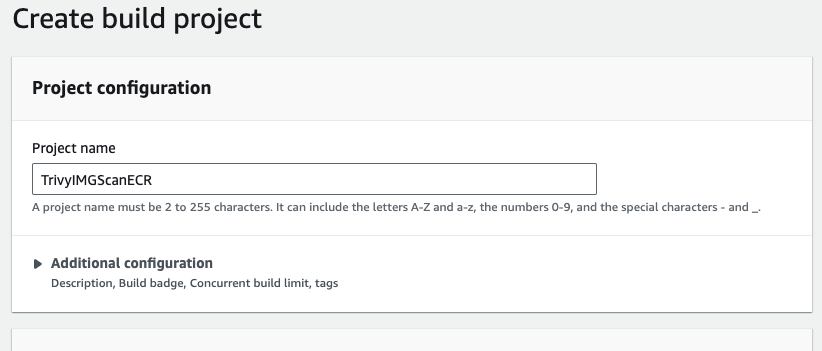
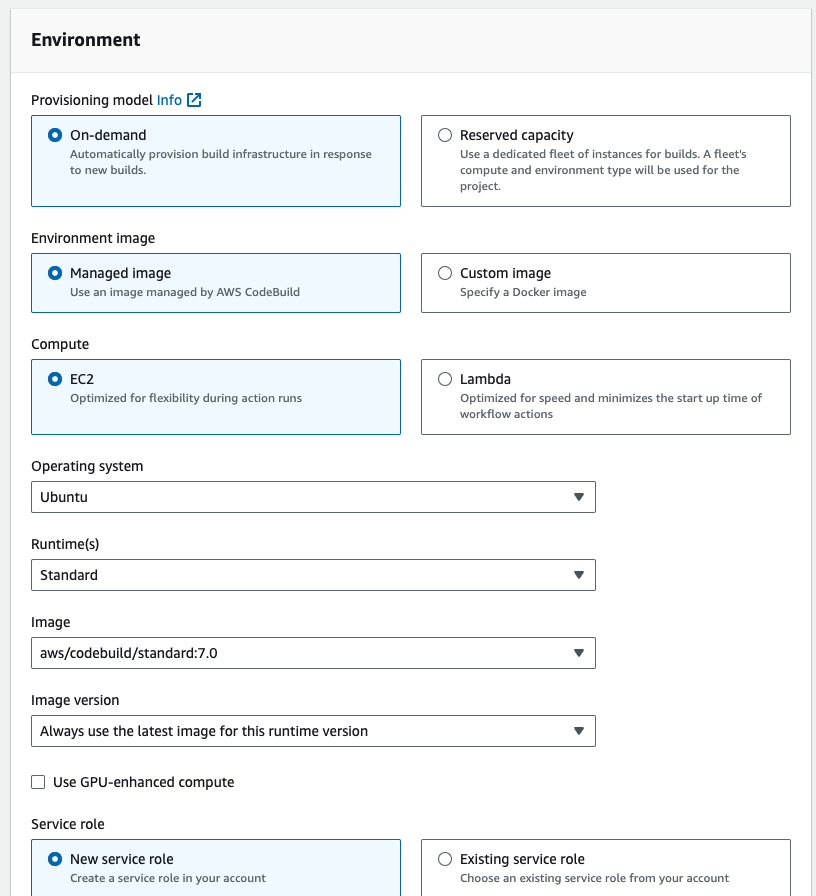
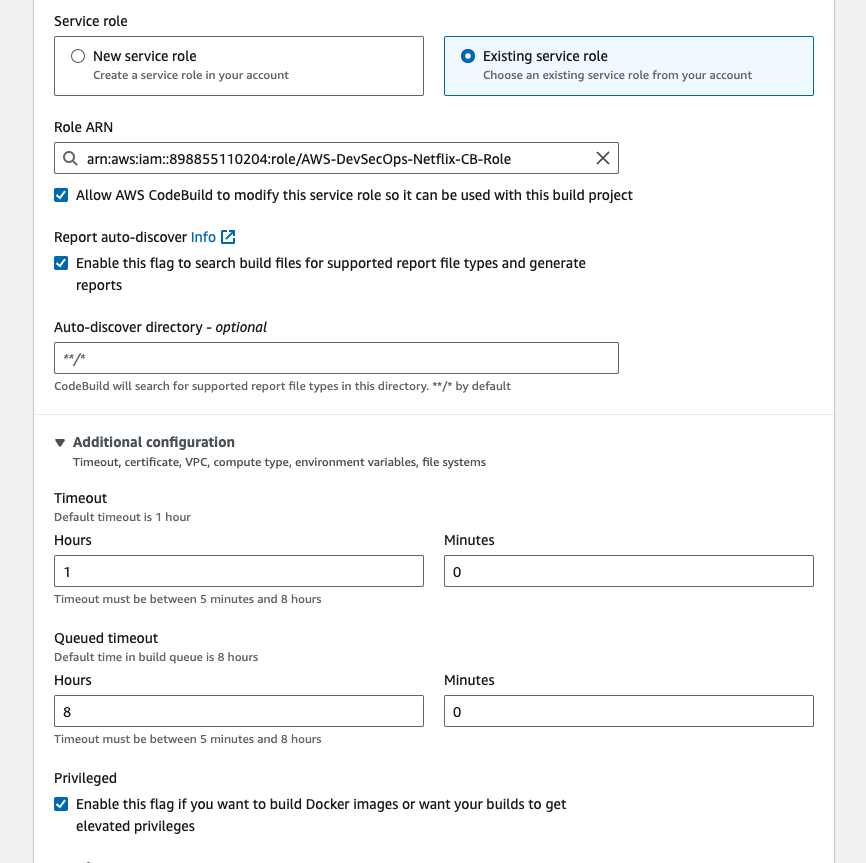
- and in the environement section, select the ubuntu as a runtime, and in the service role select existing service role. Go to addtional configuration, enable the priviledged check box.
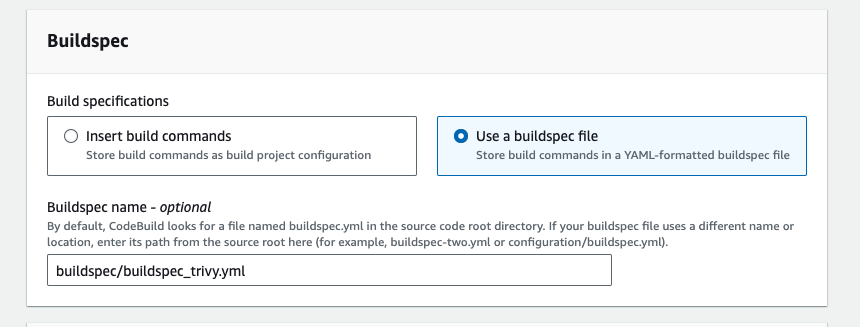
- in the buildspec section, select buildpsec as a file, and enter the buildspec file path.
then click on continue to code pipeline, In the Output artifact, enter the TrivyImageScanArtifact and then click on done.
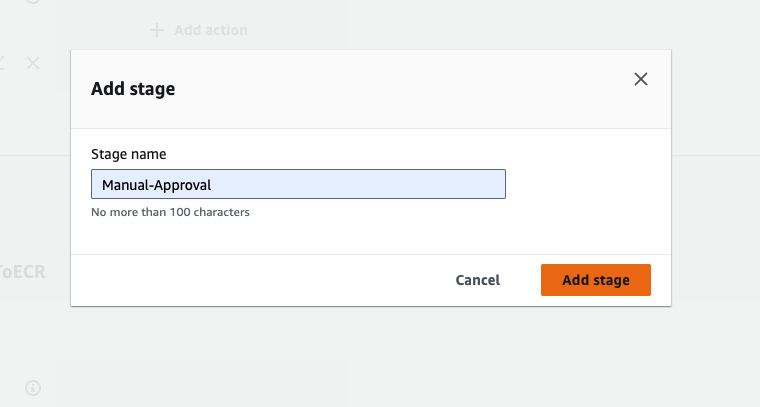
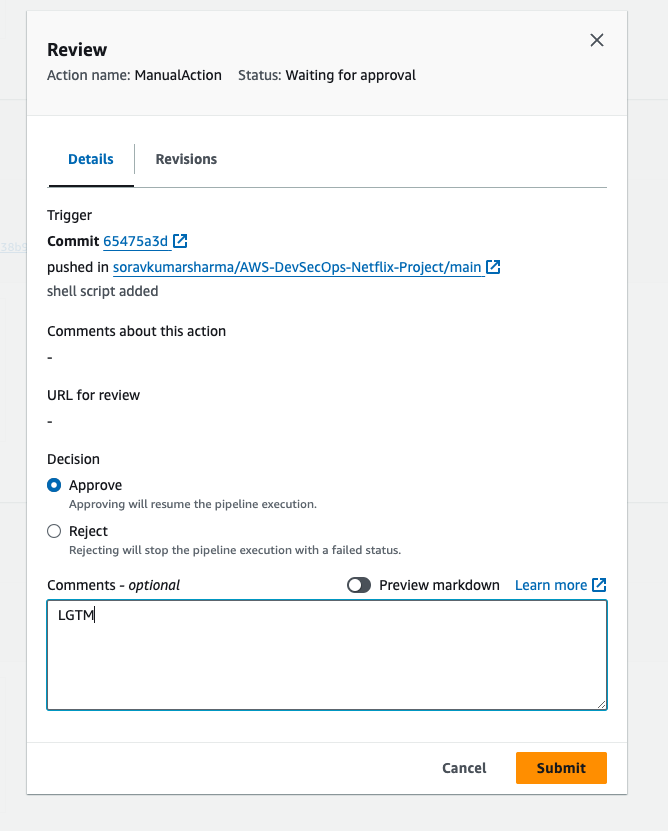
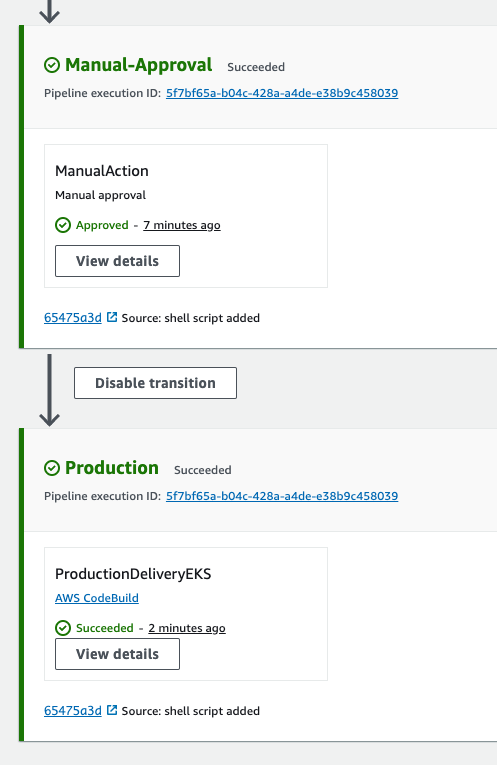
Click on again add stage button, give the stage name Manual-Approval, and then click on add stage, and then click on add action group.
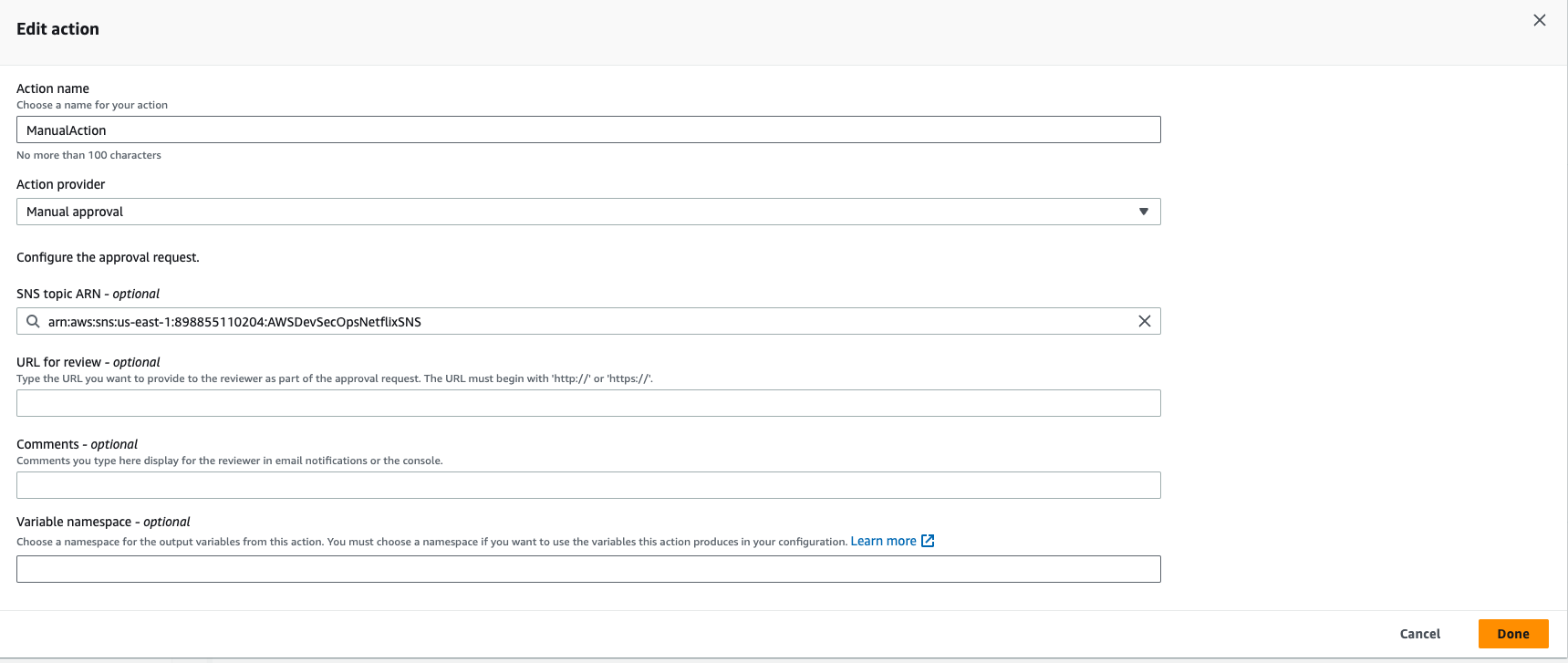
- Give the Action name "ManualAction", the action provider should be Manual approval, select the SNS topic that created before. and then click on done.
- Again Click on add stage button, give the stage name, and then click on add stage, then click on add action group.
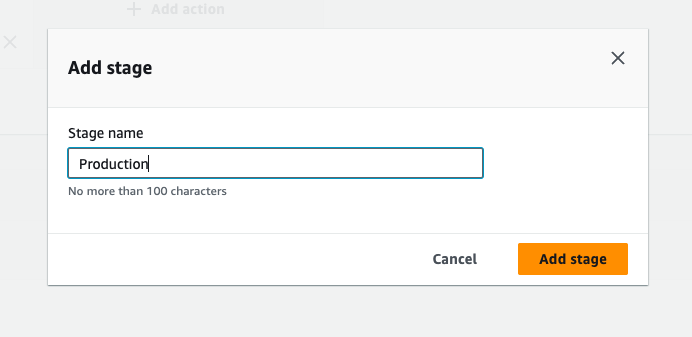
- Give the action name, "ProductionDeliveryEKS", the action provider should be codebuild, select the input artifact as previous stage output artifact, and then create a new project.
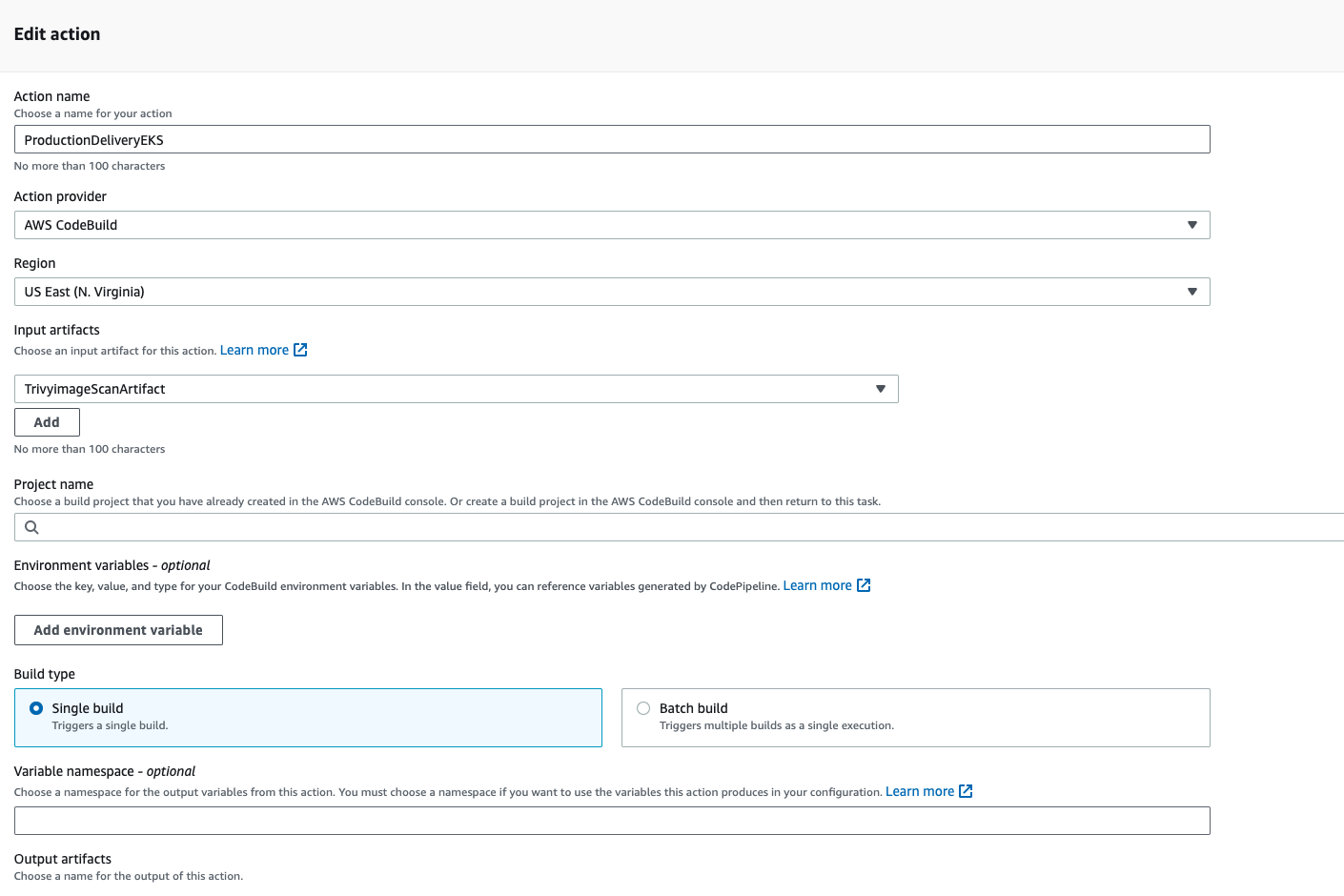
- Give the project name "ProductionEKS", and select the existing service role, in the environment section.
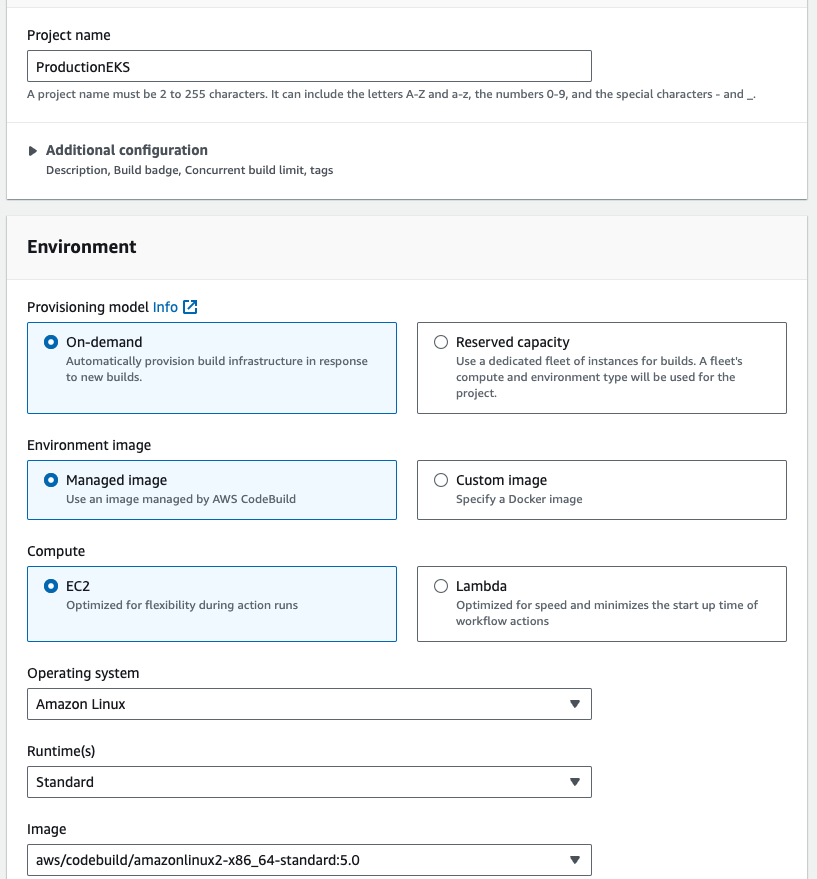
- Go to additional configuration, enable the priviledged check box.
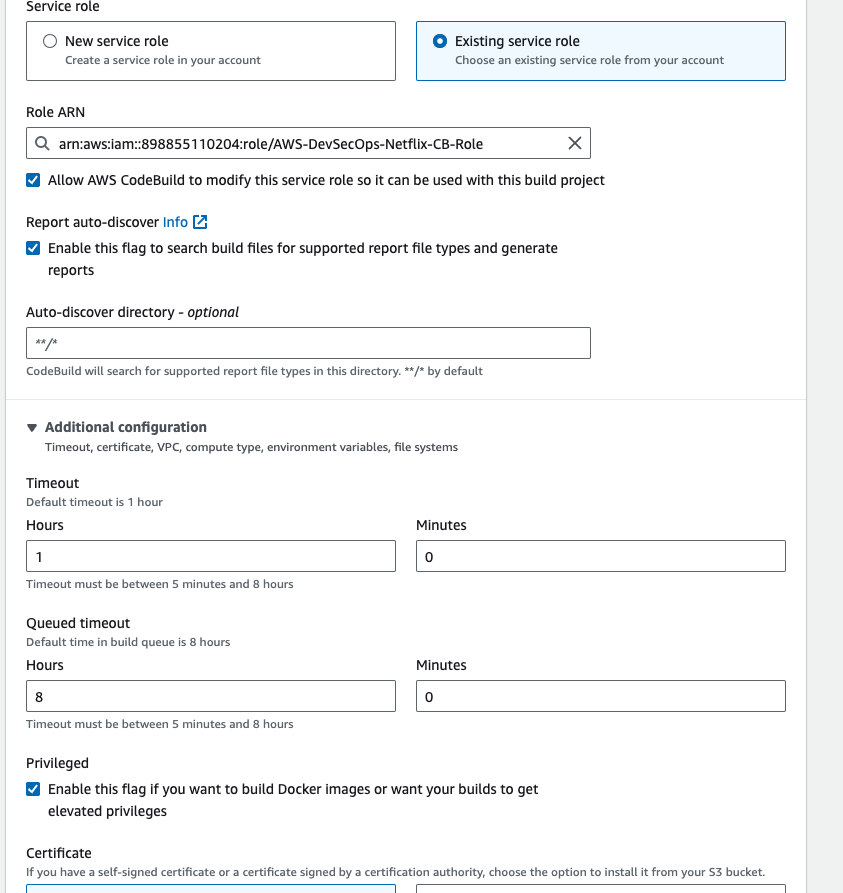
- In the buildspec section, enter the buildspec file path, then click on continue to codepipeline
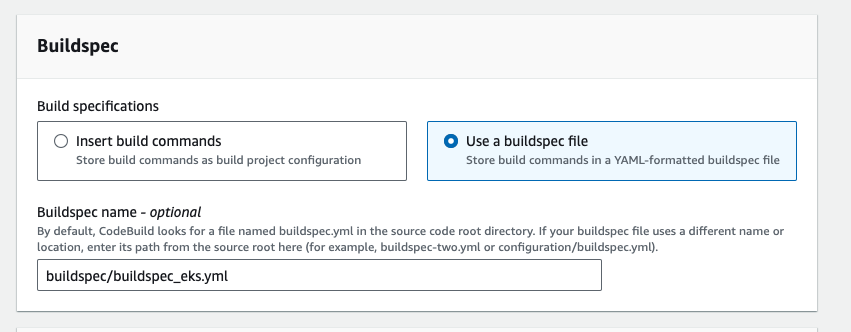
- Give the output artifact name EKSArtifact and click on done.
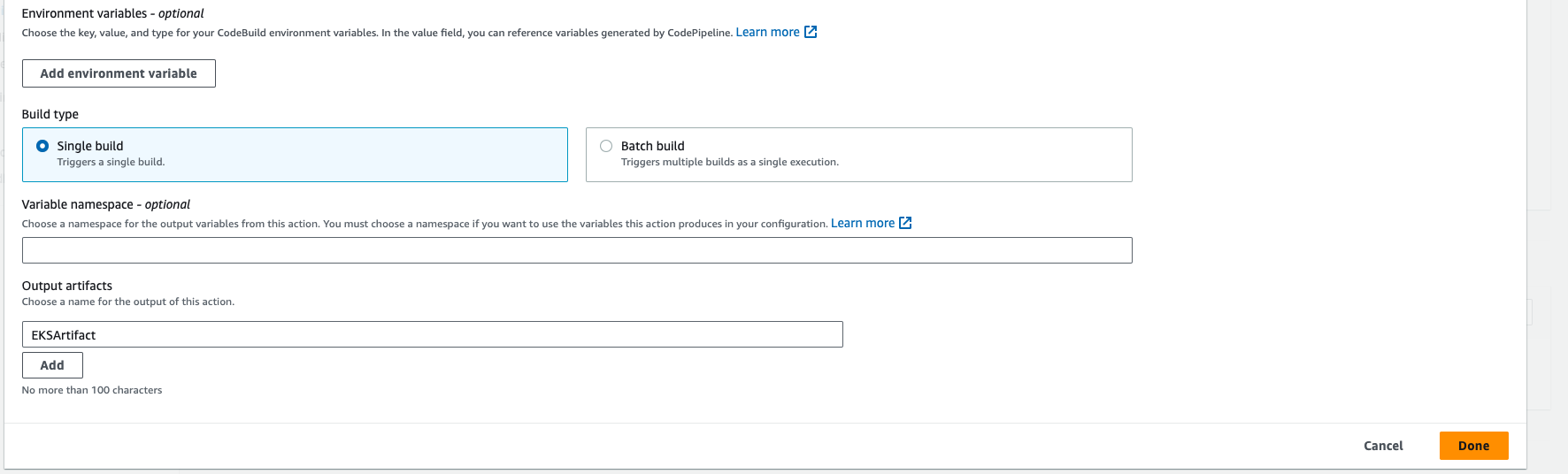
- After clicked on done, go above and click on save.

- Go to your github repo, and make a commit to run the codepipeline.
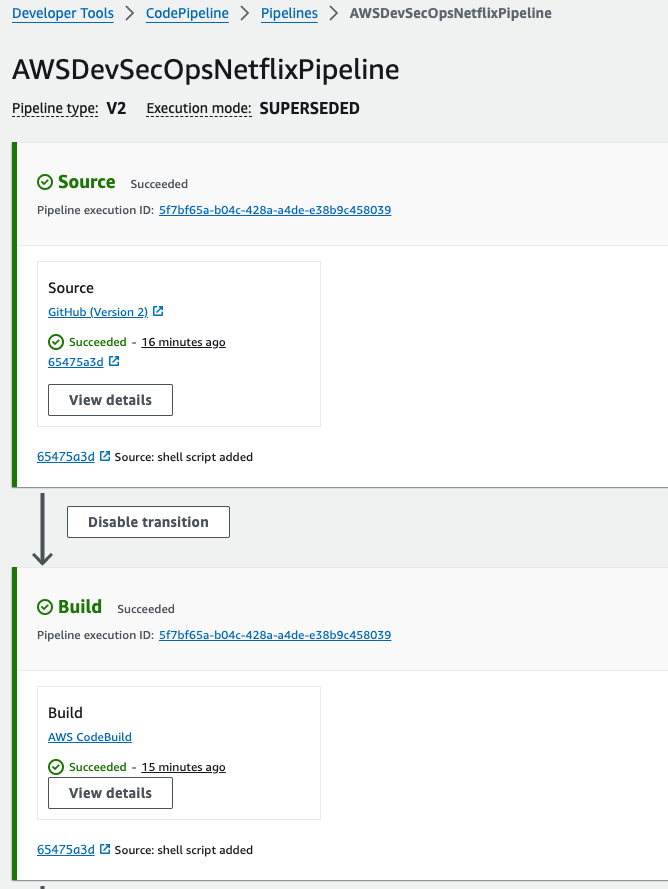
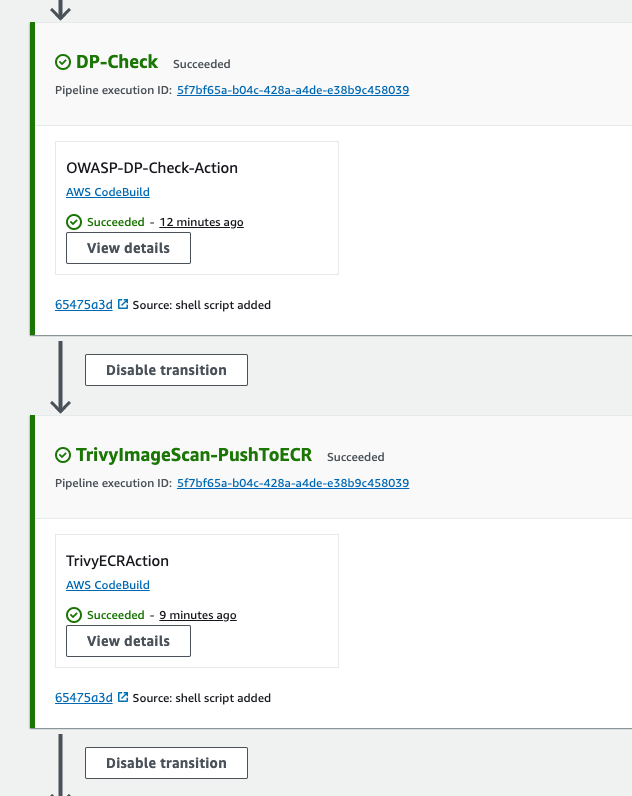
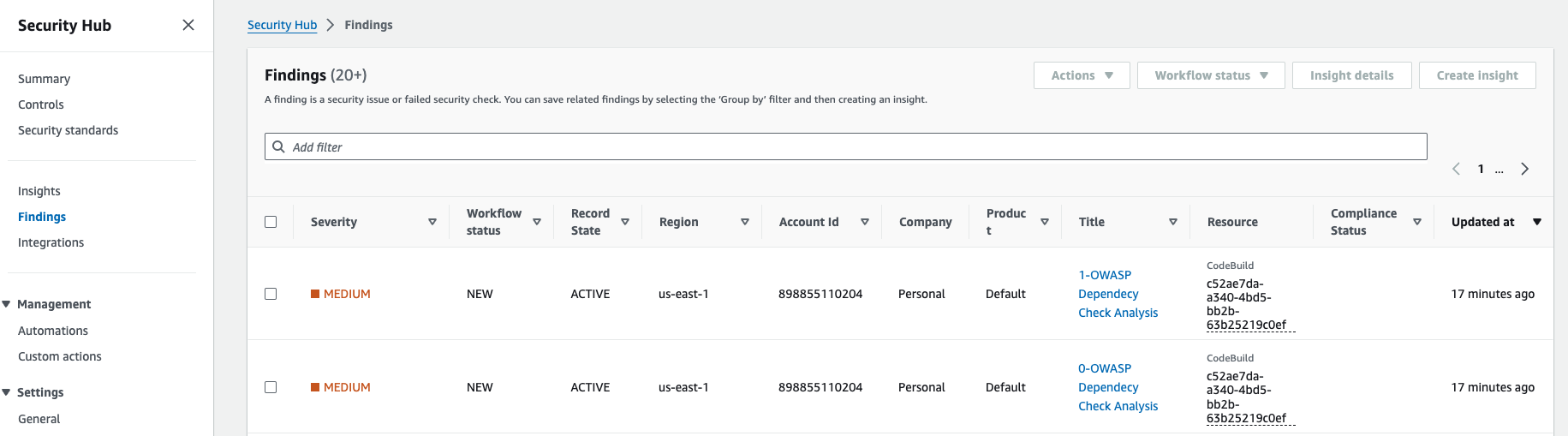
To check the severity, then go to security hub, go to findings.
Go to your "Netflix-Admin-Instance", and run the following command to access the alb-dns-name,
kubectl get ingress
- copy the address and then paste it in the tab.

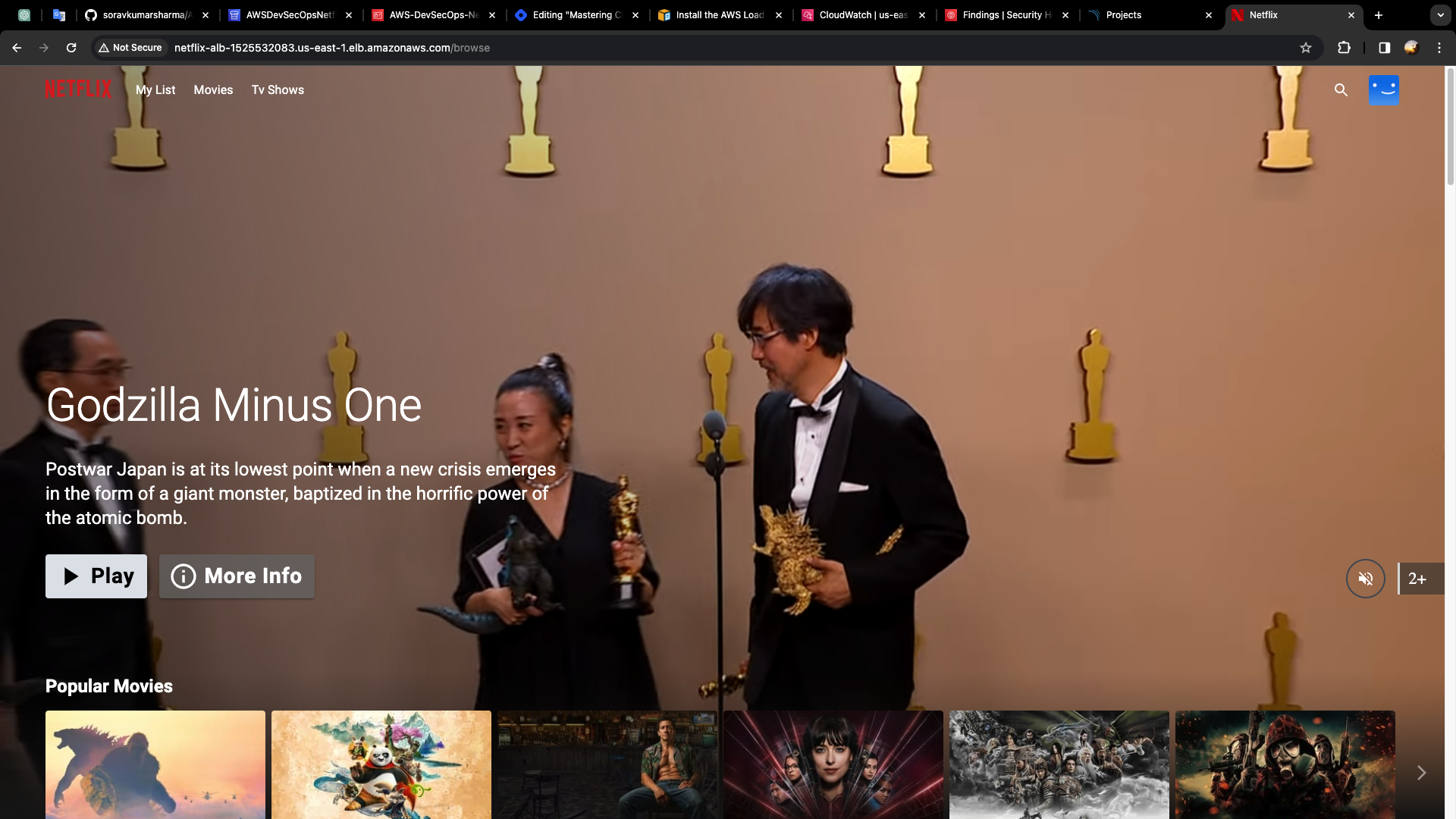
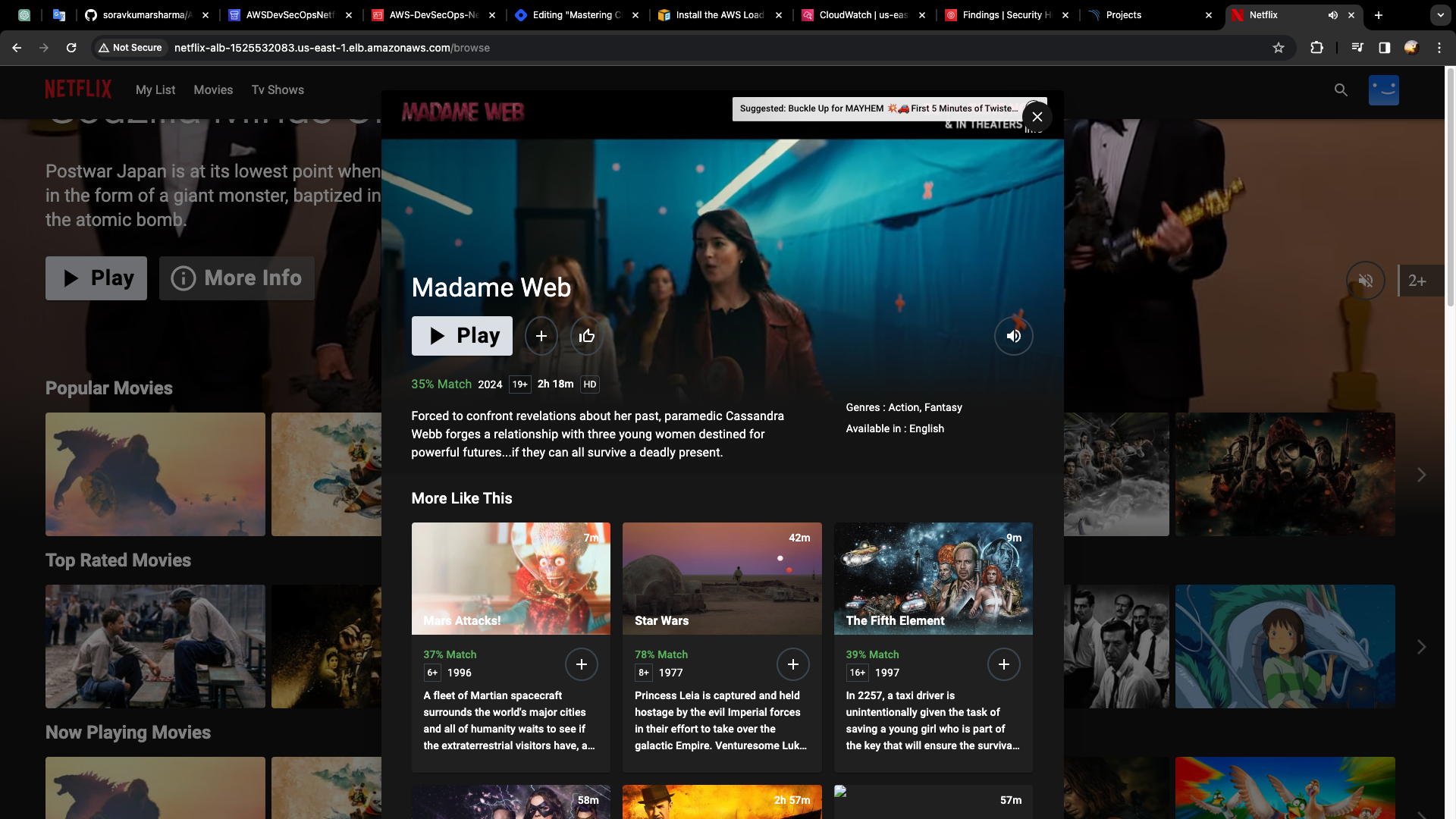
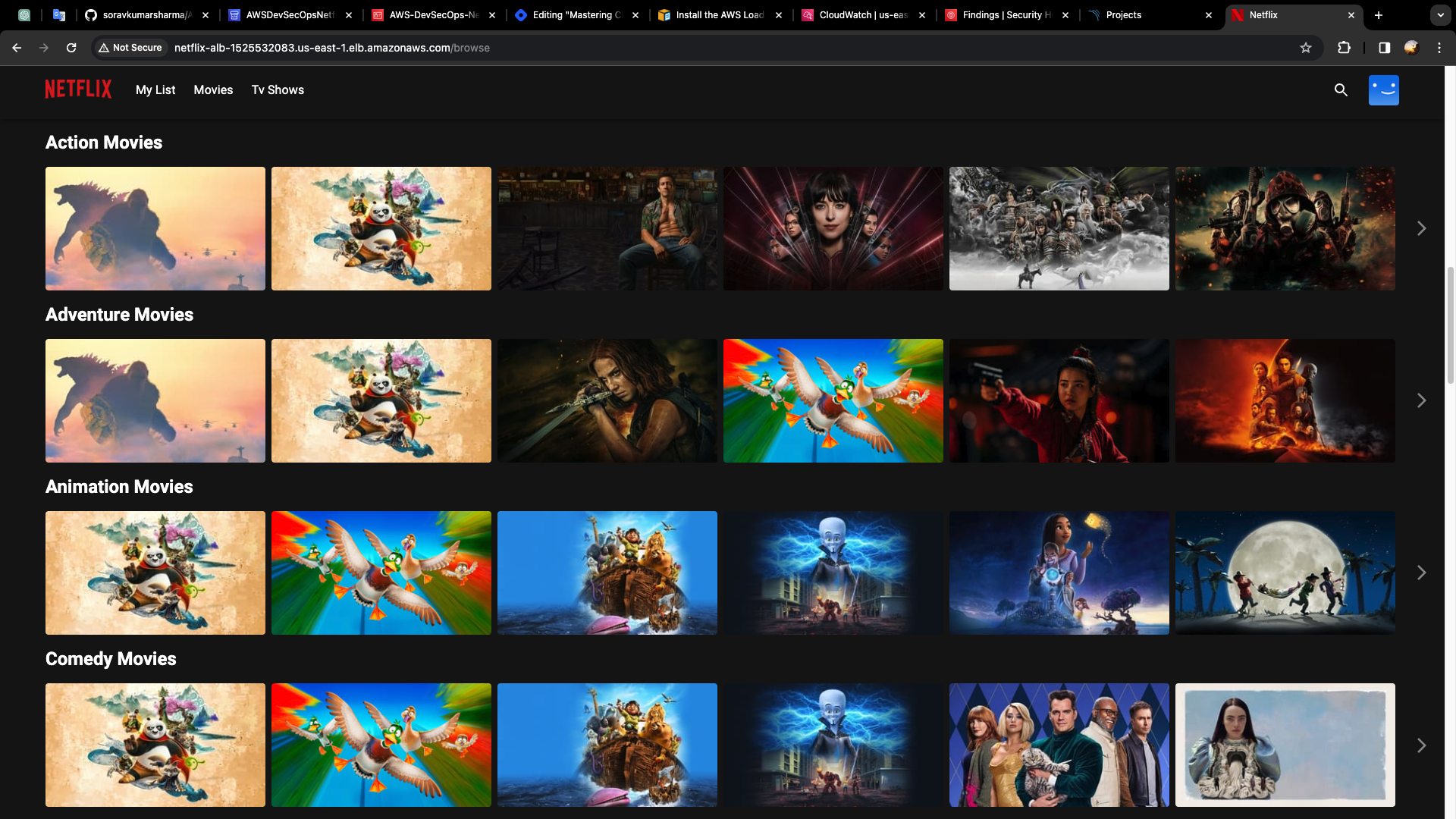
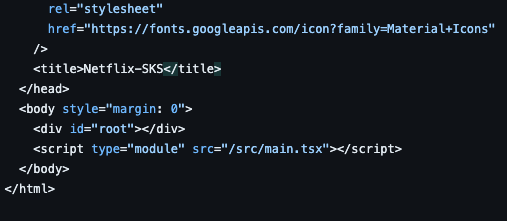
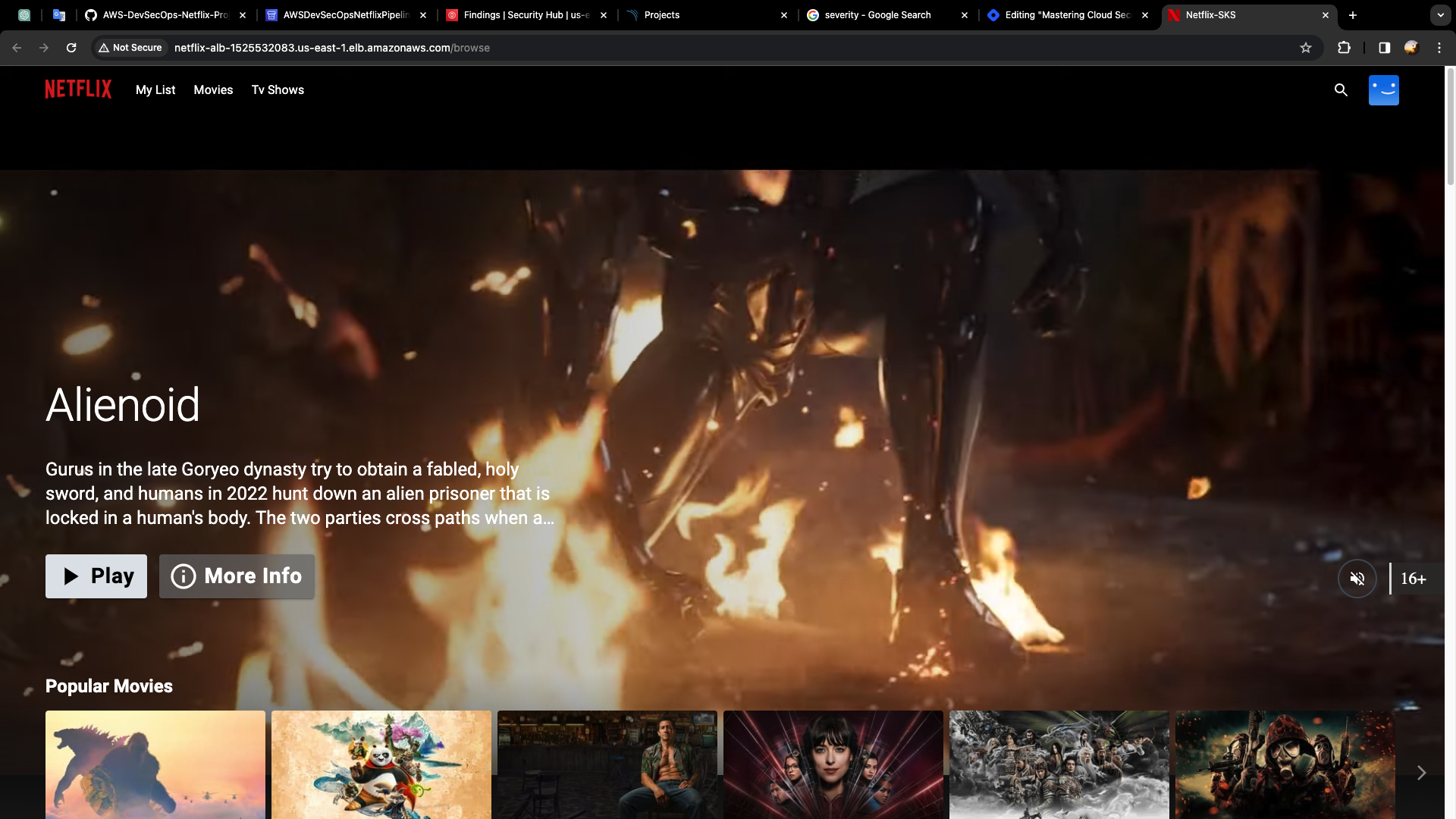
Let's check the entire, pipeline, by changing the title of this project, Go to github repo, index.html
Change the title from Netflix to Netflix-SKS
Codepipeline got triggered.
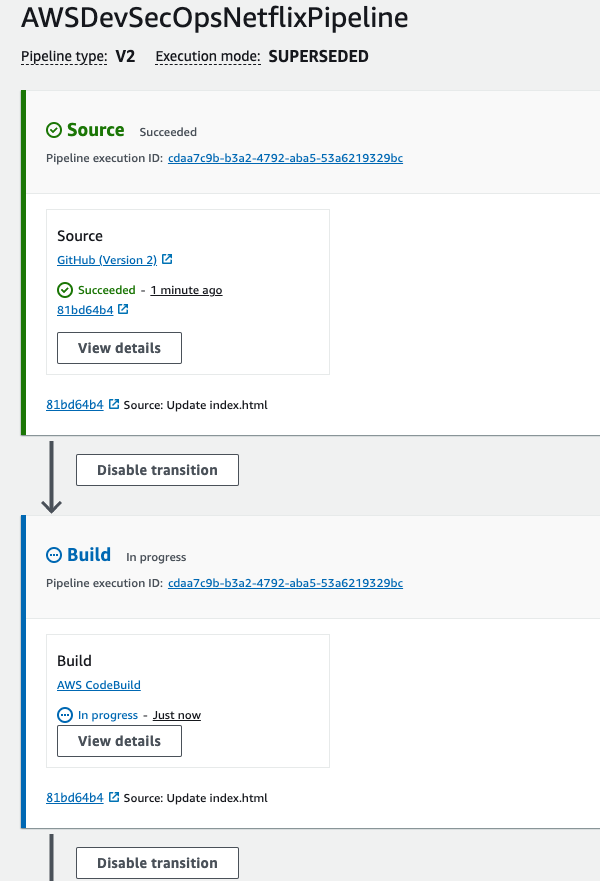
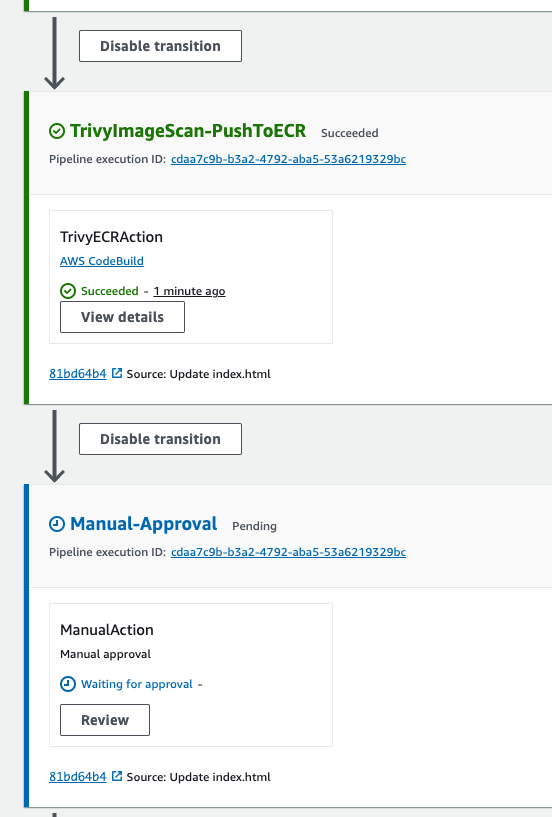
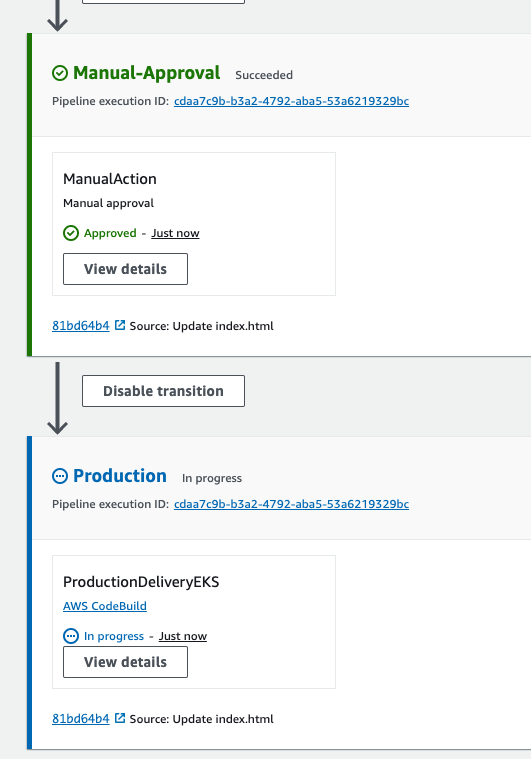
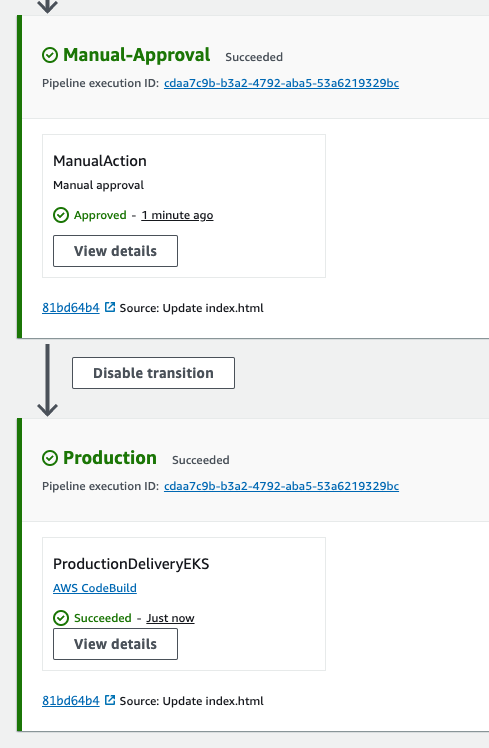
- Codebuild
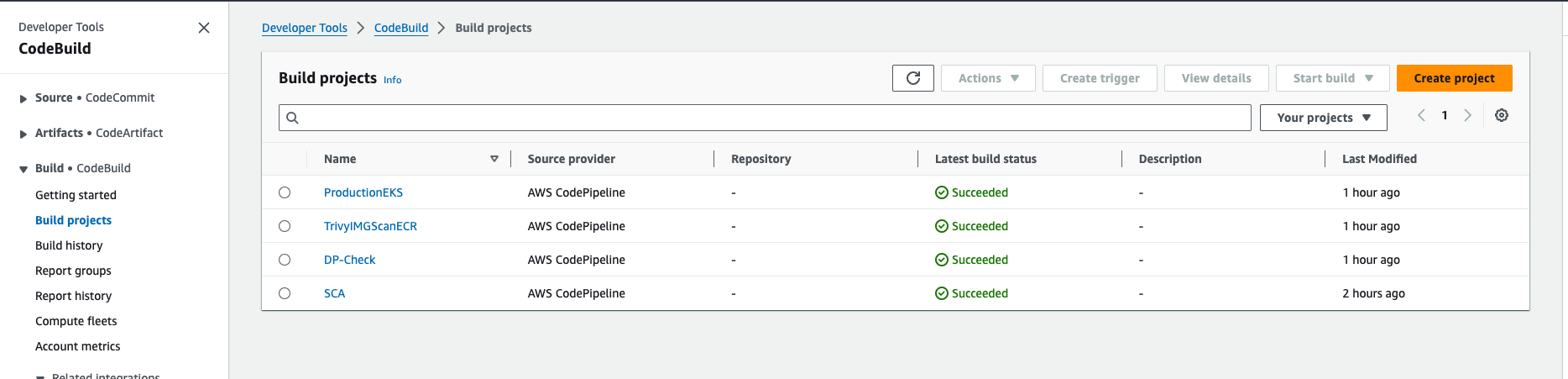
- ECR
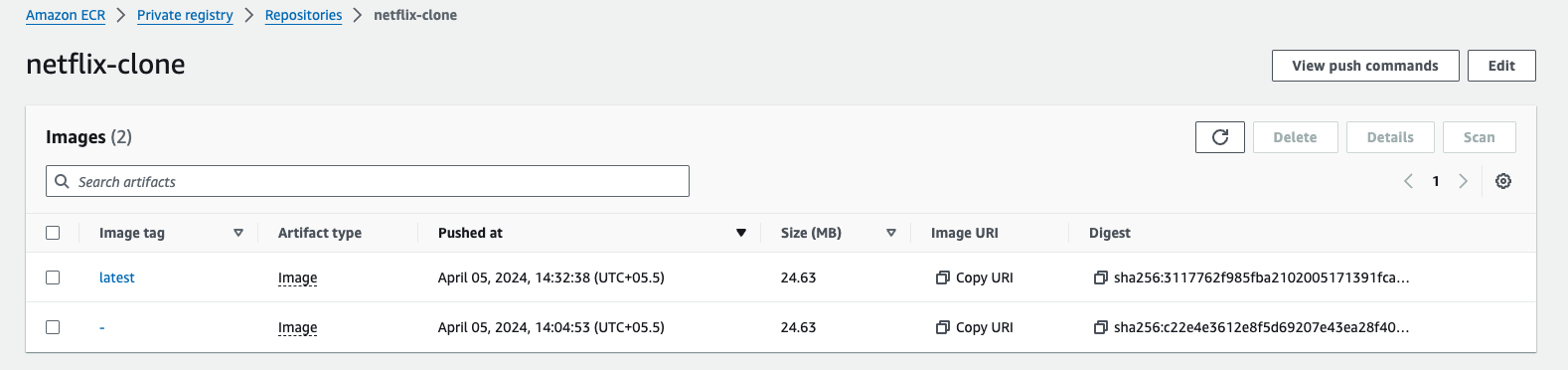
- ALB - Application Load Balancer

- Go to alb-dns-name, and check the changes are reflected or not.
Subscribe to my newsletter
Read articles from Sorav Kumar Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sorav Kumar Sharma
Sorav Kumar Sharma
As a passionate DevOps Engineer, I'm dedicated to mastering the tools and practices that bridge the gap between development and operations. Currently pursuing my bachelor’s in Computer Science and Engineering at Guru Nanak Dev University (Amritsar), I'm honing my skills in automation, continuous integration/continuous deployment (CI/CD), and cloud technologies. Eager to contribute to efficient software delivery and infrastructure management. Open to learning and collaborating with like-minded professionals. Let's connect and explore opportunities in the dynamic world of DevOps.