Schema Driven Development & Single Source of Truth
 Ayush Ghai
Ayush GhaiTable of contents
- What is Schema Driven Development?
- Check out our video on Schema-Driven Development and Single Source of Truth below:
- What are the signs that your team doesn't use SDD?
- The 8 best practices
- Why should you care about ensuring best practices?
- What are guardrails? Why are they necessary?
- Schema Driven Development (SDD) and Single Source of Truth (SST)
- What is SDD?
- Usecases of SDD and SST
- Validation of data at exchange boundaries
- Generation of Swagger, Graphql & other schemas and CRUD APIs from DB schema
- Generation of more schemas: Graphql, gRpc, WSDL etc.
- Unification of different eventsources (decoupled or modular architecture)
- Authentication & Authorisation
- Generating API clients
- Generating Test cases
- Generating UI Components
- Parallel development across backend and client/frontend teams
- Benefits of SDD and SST
- Experience on your own
- Conclusion
In the upcoming articles we will cover the 8 most important first principles based best practices that every 10X tech team needs to follow. This article focuses on Schema Driven Development (SDD) and Single Source of Truth (STT) paradigms as two first principles every team must follow. It is an essential read for CTOs, tech leaders and every aspiring 10X engineer out there. While I will touch on SDD mainly, I will talk in brief also about the 8 practices I believe are essential, and why we need them. Later in the blog you will see pratical examples of SDD and STT with screenshots and code snippets as applicable.
What is Schema Driven Development?
SDD is about using a single schema definition as the single source of truth, and letting that determine or generate everything else that depends on the schema. For ex. generating CRUD APIs for multiple kinds of event sources and protocols, doing input/output validations in producer and consumer, generating API documentation & Postman collection, starting mock servers and parallel development, generating basic test cases. And as well - sigh of relief that changing in one place will reflect change everywhere else automatically (Single Source of Truth)
SDD helps to speedily kickstart and smoothly manage parallel development across teams, without writing a single custom line of code by hand . It is not only useful for kickstarting the project, but also seamlessly upgrading along with the source schema updates. For ex. If you have a database schema, you can generate CRUD API, Swagger, Postman, Test cases, Graphql API, API clients etc. from the source database schema. Can you imagine the effort and errors saved in this approach? Hint: I once worked in a team of three backend engineers who for three months, only wrote CRUD APIs, validations, documentation and didn't get time to write test cases. We used to share Postman collection over emails.
What differentiates great (10X) teams, leaders and engineers from the rest of the teams, leaders and engineers is the definition of "what works"
Check out our video on Schema-Driven Development and Single Source of Truth below:
What are the signs that your team doesn't use SDD?
Such teams don't have an "official" source schema. They manually create and manage dependent schemas, APIs, test cases, documentation, API clients etc. as independent activities (while they should be dependent on the source schema). For ex. They handcraft Postman collections and share over email. They handcraft the CRUD APIs for their Graphql, REST, gRpc services.
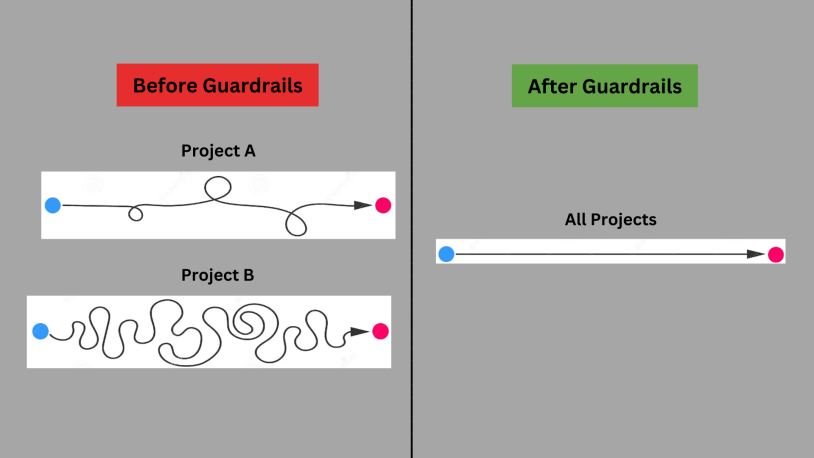
The conventional approach (without SDD)
In this approach you will have
Multiple sources of Truth (your DB schema, the user.schema.js file maintained separately, the Express routes & middlewares maintained separately, the Swagger and Postman collections maintained separately, the test cases maintained separately and the API clients created separately. So much redundant effort and increased chances of mistakes!
Coupling of schema with code, with event sources setup (Express, Graphql etc).
Non-reusability of the effort already done.
Lack of standardisation and maintainability - Also every developer may implement this differently based on their style or preference of coding. This means more chaos, inefficiencies and mistakes! And also difficulty to switch between developers.
You will be
Writing repetitive validation code in your event source controllers, middleware and clients
Creating boilerplatefor authentication & authorisation
Manually creating Swagger specs & Postman collection (and maintaining often varying versions across developers and teams, shared across emails)
Manually creating CRUD APIs (for database access)
Manually writing integration test cases
Manually creating API clients
Whether we listen on (sync or async) events, query a database, call an API or return data from our sync event calls (http, graphql, grpc etc) - in all such cases you will be witnessing
Redundant effort in maintaining SST derivatives & shipping upgrades
Gaps in API, documentation, test cases, client versions
Increased work means increase in the probability of errors by 10X
Increased work means increased areas to look into when errors happen (like finding needle in haystack) - Imagine wrong data flowing from one microservice to another, and breaking things across a distributed system! You would need to look across all to identify the source of error.
When not following SST, there is no real source of truth
This means whenever a particular API has a new field or changed schema, we need to make manual change in five places - service, client(s), service, swagger, postman collection, integration test cases. What if the developer forgets to update the shared Postman collection? Or write validation for the new field in the APIs? Do you now see how versions and shared API collections can often get out of sync without a single source of truth? Can you imagine the risk, chaos, bugs and inefficiencies this can now bring?
Before we resume back to studying more about SDD and SST, lets have a quick detour to first understand some basic best practices which I believe are critically important for tech orgs, and why they are important?
The 8 best practices
In upcoming articles we will touch upon these 8 best practices.
Schema Driven Development & Single Source of Truth (topic of this post)
Configure Over Code
Security & compliance
Decoupled (Modular) Architecture
Shift Left Approach
Essential coding practices
Efficient SDLC: Issue management, documentation, test automation, code reviews, productivity measurement, source control and version management
Observability for fast resolution
Why should you care about ensuring best practices?
As a tech leader should your main focus be limited to hustling together an MVP and taking it to market?
But MVP is just a small first step of a long journey. This journey includes multiple iterations for finding PMF, and then growth, optimisation and sustainability. There you face dynamic and unpredictable situations like changing teams, customer needs, new compliance, new competition etc. Given this, should you lay your foundation keeping in mind the future as well? For ex. maintainability, agility, quality, democratisation & avoiding risks?
The hallmark of any great team is both - good defence and good offence. Following best practices allows you do achieve both in not just the first days but forever.
As a result of almost 22 years of experience in tech, based on the good things and also the horrors we have seen across the industry and companies of all sizes, me and my senior colleagues who built Godspeed's microservice framework, took special effort to bring some of the following best practices as part of the framework design itself.
While I will take examples from Godspeed here in this blog, I am just using them as reference. My intention is that want you to focus mainly on the practices and see if they make sense to you too! If they do you may follow them across any tech stack - whether by using Godspeed or writing own framework (which many teams do - and why we made Godspeed too!).
What are guardrails? Why are they necessary?
In essence, guardrails are like a guided path for developers, designed and enforced within your project setup or tech infra. They outline the correct way to approach things and define (or enforce) what developers need to do (or need not do) to avoid common pitfalls. Think of them as your guided navigation in a dense forest of codes & functions when implementing your projects. These help you reach your destination (i.e. reliable releases + satisfied users + agile iterations from day 1 to forever) not only fast but with reliable quality of output across a team of diverse skill sets (including junior developers and changing team).
Guardrails are extremely useful for serious tech orgs, irrespective of whether you are building, scaling or migrating monoliths, microservices and/or serverless functions based projects.
As a tech leader you should have SDD and SST as guardrails in your tech org, across all your projects and teams
Schema Driven Development (SDD) and Single Source of Truth (SST)
Fascinating? Let's elaborate on this schema-driven development.
You can see a video about this topic here (in context of Godspeed's microservice framework)
As discussed in previous post of this series, software is all about playing with data and every data has a shape and every shape has an inherent schema. Schemas define how data is stored and exchanged. For ex. database schema, REST API schema, Graphql Schema, Protobuf, WSDL schema etc. For the same there are standards like Prisma for databases, or Swagger for REST API.
What is SDD?
SDD is about using a single schema definition as the single source of truth, and letting that determine or generate everything else that depends on the schema. For ex. generating CRUD APIs for multiple kinds of event sources and protocols, doing input/output validations in producer and consumer, generating API documentation & Postman collection, starting mock servers and parallel development, generating basic test cases. And as well - sigh of relief that changing in one place will reflect change everywhere else automatically (Single Source of Truth)
Usecases of SDD and SST
Validation of data at exchange boundaries
Honouring the schema shared between consumer and producer
Whether you consume data, send data, receive data or return data - preventing wrong data from coming into your service or going from your service to another service will help stop the propagation of wrong data (and bugs) beyond the exchange boundaries. This prevents bugs at source and also reduces the impact area and investigation area for bugs, helping in quicker identification and resolution of issues. This means
Prevention of bugs at source, during development time, by flagging wrong input or response against the promised contract
Reducing bug Introduction Rate per sprint (BIR)
Reducing mean Time to Detection (MTTD) and
Reducing mean Time To Resolution (MTTR) of issues or bugs.
Reducing time and effort wasted of many more people when original bug lies in one small corner of the system
Let me show you how SDD works in Godspeed.
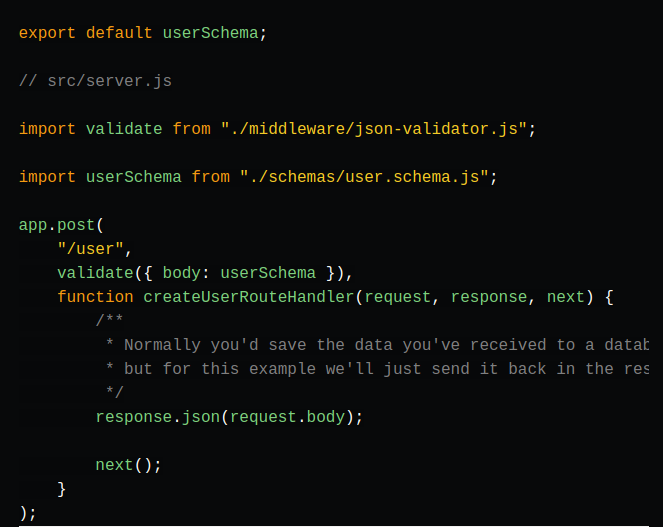
Example Schema (this is Godspeed + Swagger format of an event)

A sample event in Godspeed
Auto-generated Swagger (and Postman) from the SST schema
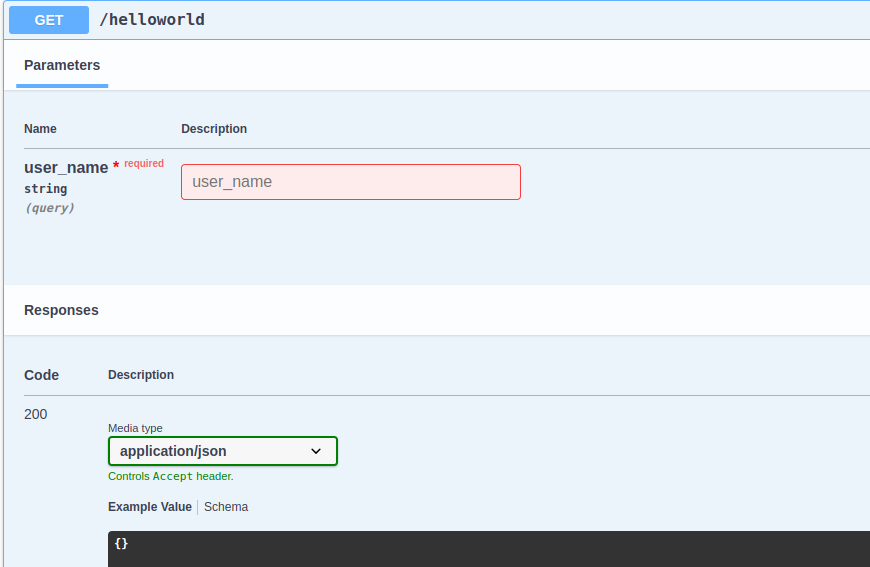
In case of Godspeed's microservice framework the swagger collection is generated when the service starts. You can configure swagger's top level details like endpoint, security schemes, servers, info etc in the Express or Fastify (any http type) eventsource's configuration file.
When following SDD you can start checking the data exchanged against the promised contract.
Ex. 1: Wrong input to event
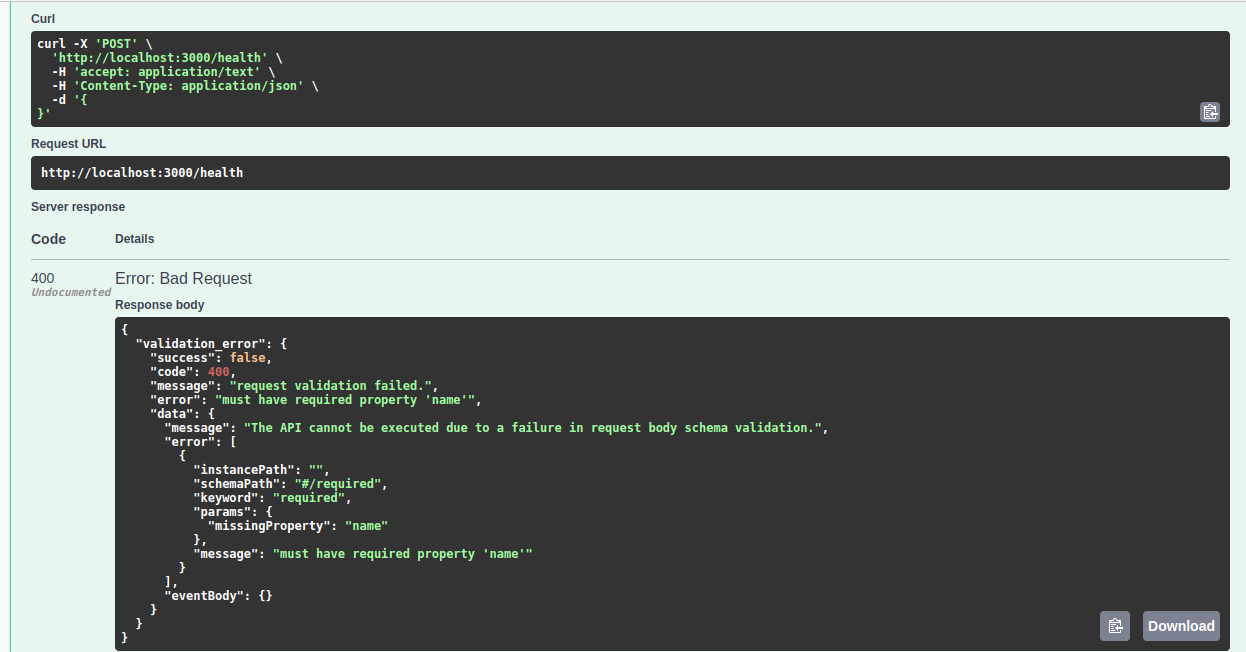
Ex 2: Sending wrong API response
Your service should return a 500 status code saying I am unable to return correct data as promised in my published swagger spec!
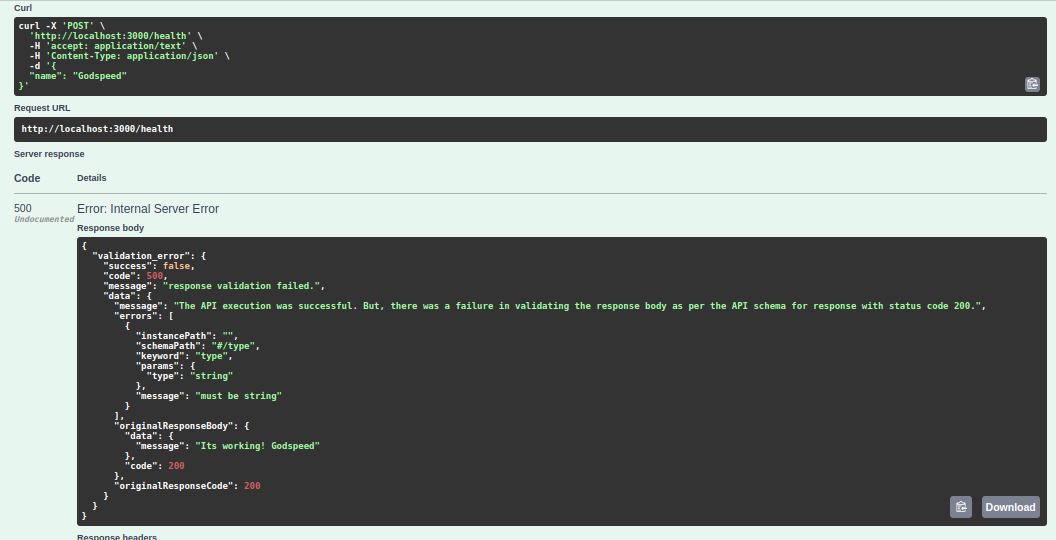
The service should return a 500 status code saying I am unable to return correct data!
Same validation checks could be done in other places too
Before making calls to another API (third party or microservice)
Checking response from another API
Before sending data to a message bus, against a topic
Checking data shape when consuming a message bus event
Generation of Swagger, Graphql & other schemas and CRUD APIs from DB schema
If you have your DB schema defined you can generate CRUD APIs. It is supported in not only Godspeed but some other frameworks as well. For ex. in Godspeed, using a Prisma model as single source of truth schema definition, you can generate CRUD APIs over REST and Graphql, over all popular databases like Postgres, Mysql, MsSql, Mongodb, Cockroachdb, Mariadb etc and as well Elasticsearch, along with events specs, Swagger and Postman.
A Prisma schema file
You can generate this by scanning your existing database or by hand
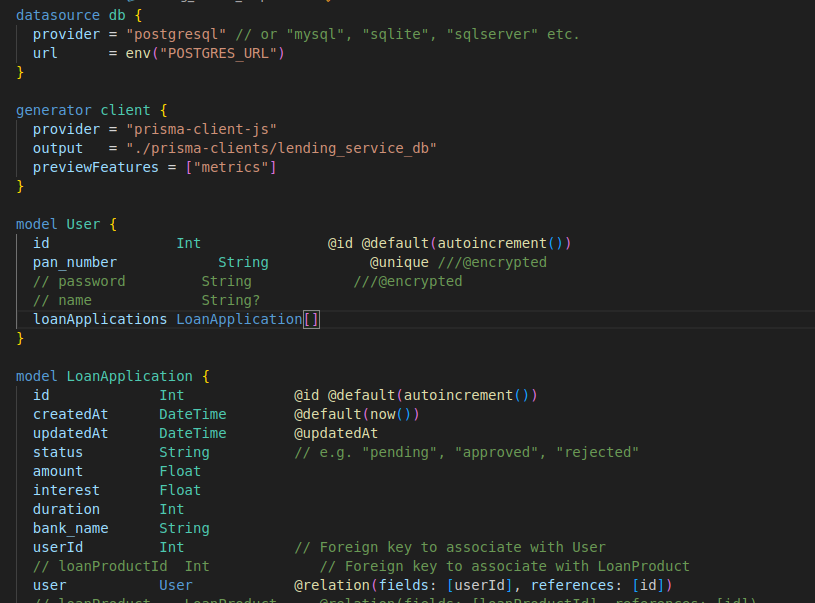
p.s. Note the ///@encrypted tag in schema definition. This plugin in Godspeed will automatically encrypt when saving or searching, and decrypt when returning this field
From Prisma model: Generate your CRUD API Event Schemas
In Godspeed we have defined a standard event definition format which
Extends or derives from Swagger spec
Supports multiple event sources in a decoupled manner (as developer crafted or pre-existing plugins)
Supports pure functions which are decoupled from event sources SDK and styles (like Express, Fastify, Graphql) and simply return data with status code and headers.
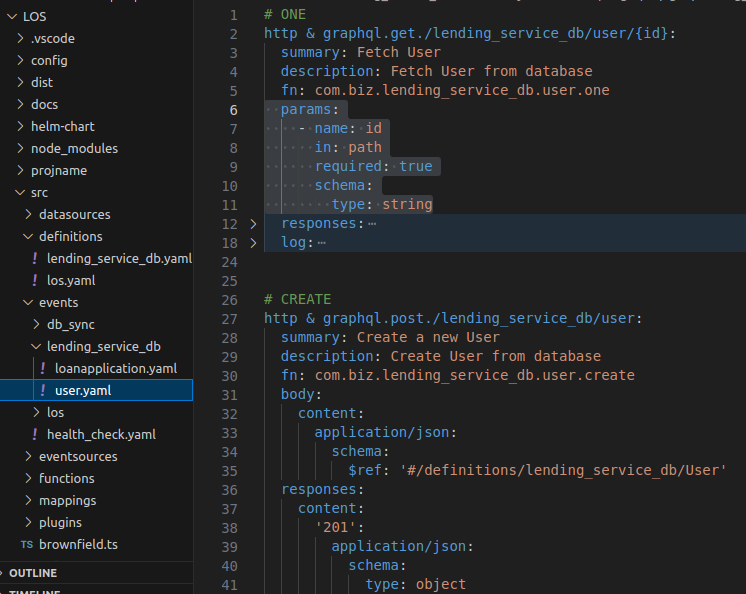
Pure functions
In Godspeed, gen-crud-api command generates event definitions and functions for CRUD over a given Prisma model.
From Prisma model: Generate your JSON Schema definitions of DB entities
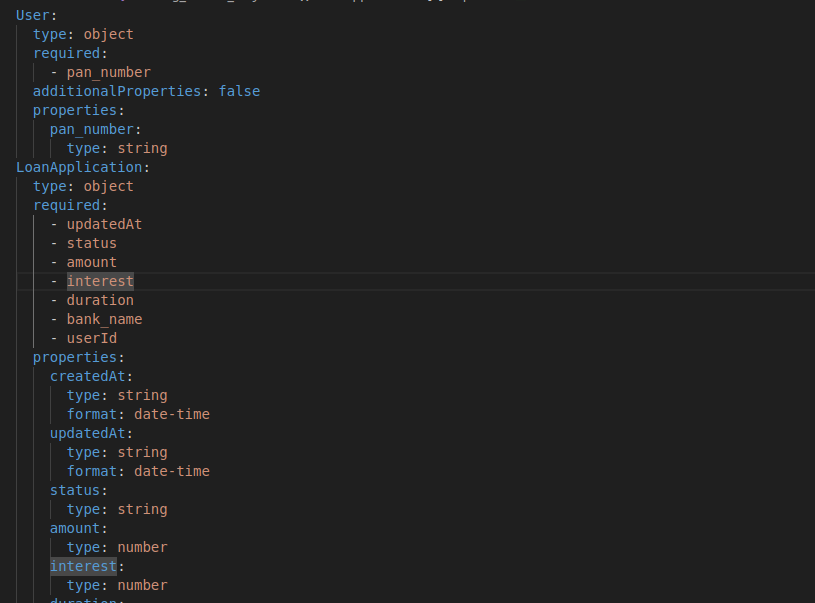
From Prisma model: Generate your Swagger Spec
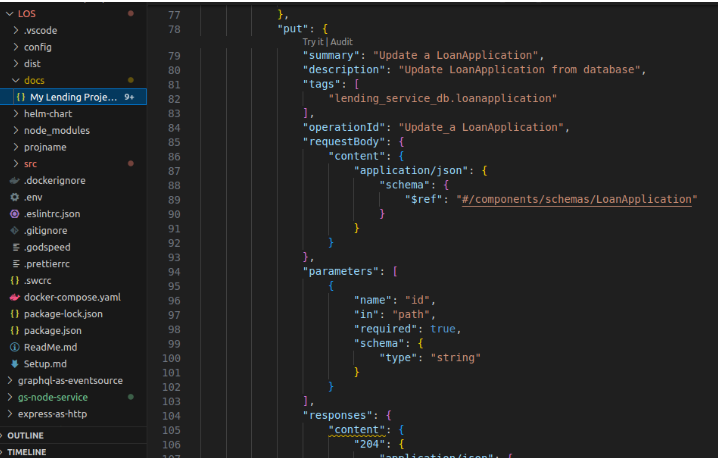
From Generated Swagger: Automatically load Swagger Endpoint in your Express or Fastify service
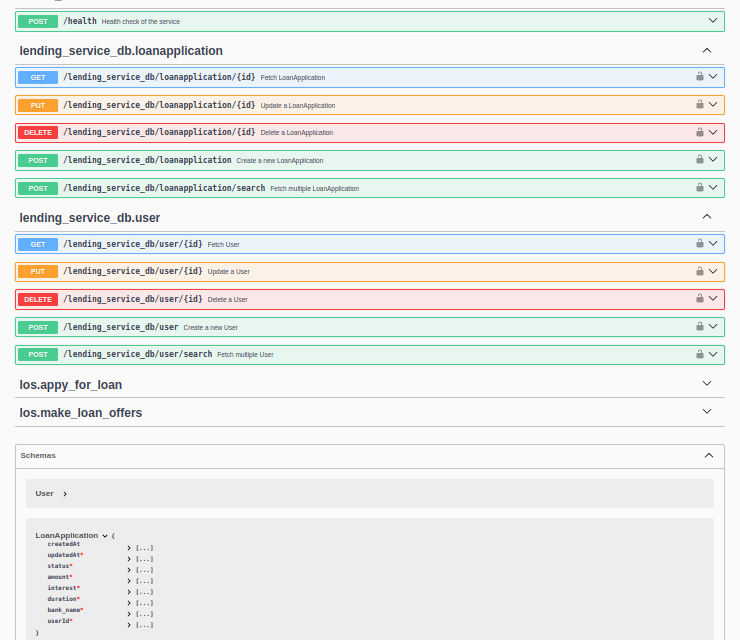
From generated Swagger: Generate your Postman collection
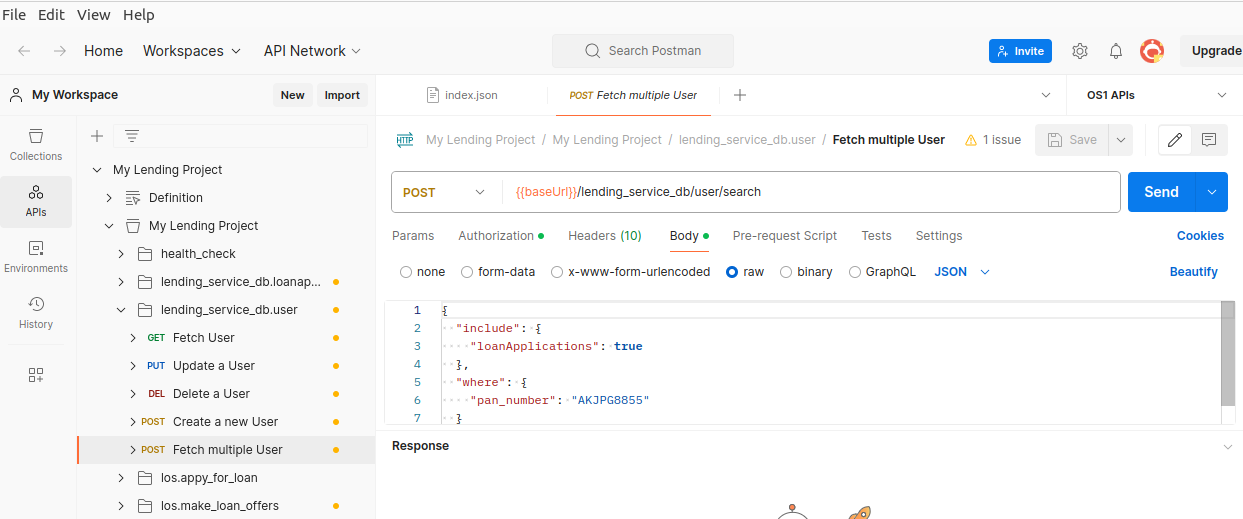
Please for 10X sake, don't create Postman collections by hand and share by email! Let that be auto-generated and available any time from within your project.
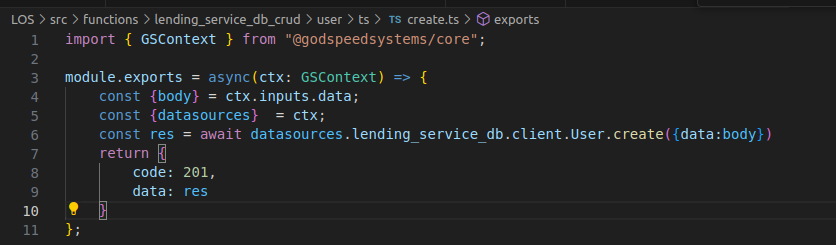
From Prisma schema: Generate your CRUD Functions
Option 1: In Godspeed's YAML DSL
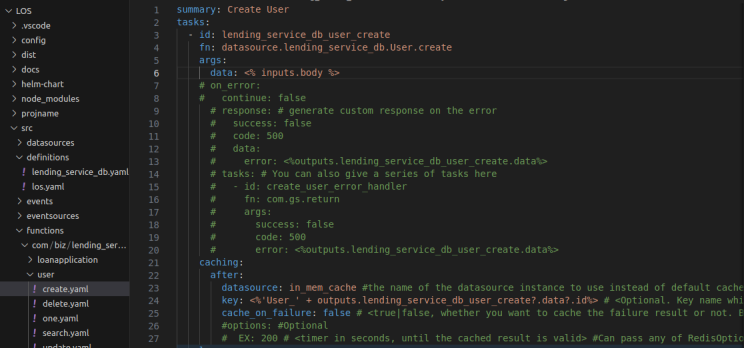
Option 2: Can also replace YAML functions with Typescript functions
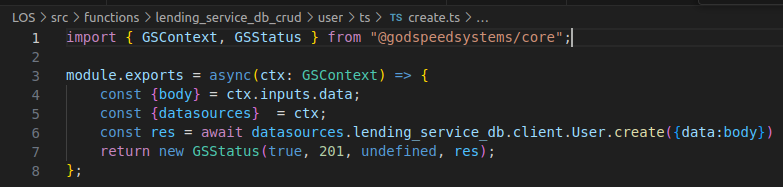
In the above example, I have shown how you can write DB access code using the datasources loaded in you use Godspeed project. Currently Godspeed does not support generating Typescript code for CRUD. But when following SDD, you will write a plugin to generate Typescript or any other language or DSL code from the universal schema (SST).
Generation of more schemas: Graphql, gRpc, WSDL etc.
From a single source of truth schema, which could be your Prisma schema (for pure CRUD service), or Godspeed's or your self defined event schemas, you can generate Swagger, Postman, Graphql, grpc, WSDL or any other schema! Such open source tools exists. Godspeed supports generating Swagger + Postman and Graphql currently.
From Godspeed standard event schema: Generate your Graphql Schema
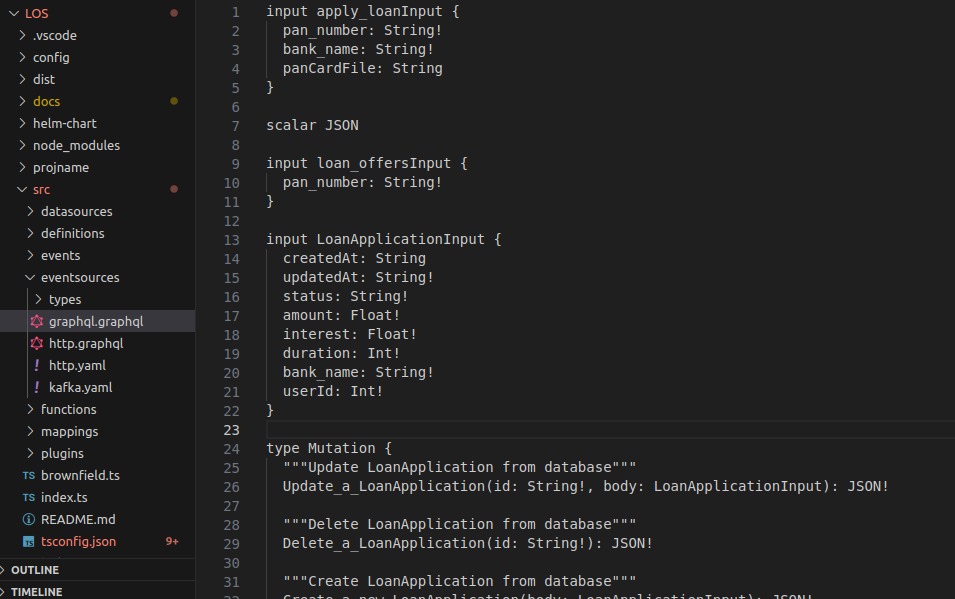
In case you want to support gRpc, WSDL or any other schema format, you just need a single schema converter implementation and remove all chances of human or AI errors in generating those schemas in deterministically correct format.
Unification of different eventsources (decoupled or modular architecture)
With the a universal event schema defined in one place, you can run a REST service, a Graphql service, a gRpc service all honouring the same contract.
Your Graphql service can be up and running without a single line of handwritten code
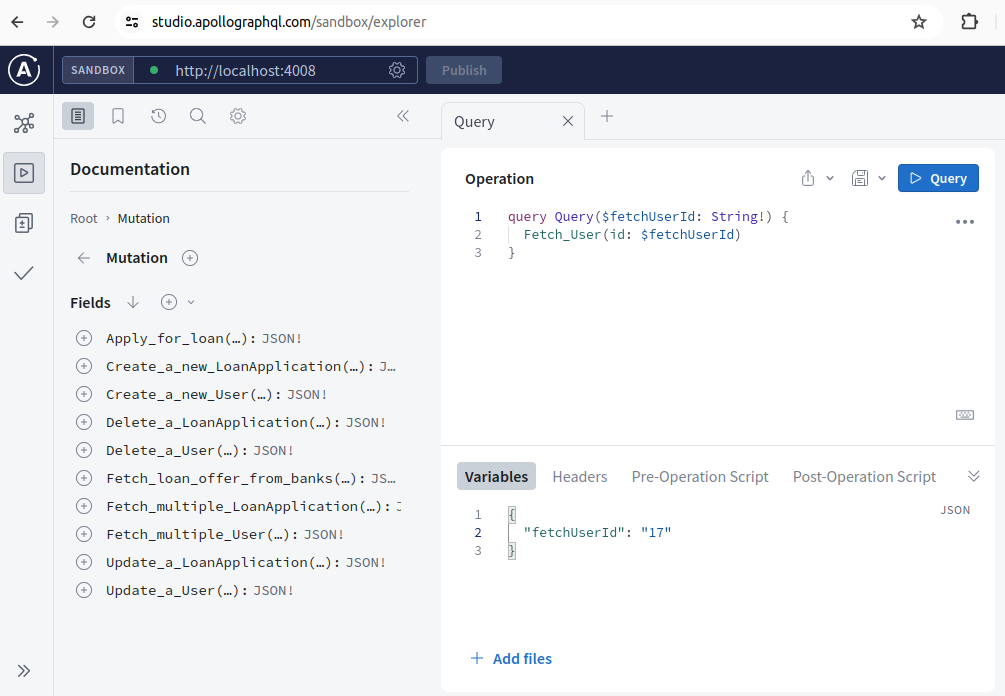
Authentication & Authorisation
As a 10X tech org, you should think or creating reusable and configurable infrastructure. This includes your event sources with typical middleware like authentication and authorisation. For ex. in Godspeed you can install plugins for Express, Fastify or Apollo Graphql and configure them.
When you do that, you can configure the authentication and authorisation policies at the event source and event level, without having to code middle wares and developers writing their own style of boilerplate. This means standardisation and reduced time, effort, chances of error and development chaos across multiple and changing teams. You will be creating standardised infra for your org!
Configuration based authn and authz will not only add the logic within your REST or Graphql service but will also help set security schemes in your published specs across Swagger, Postman.
Event source level configuration in your Express, Fastify or Apollo Graphql service (for all endpoints)
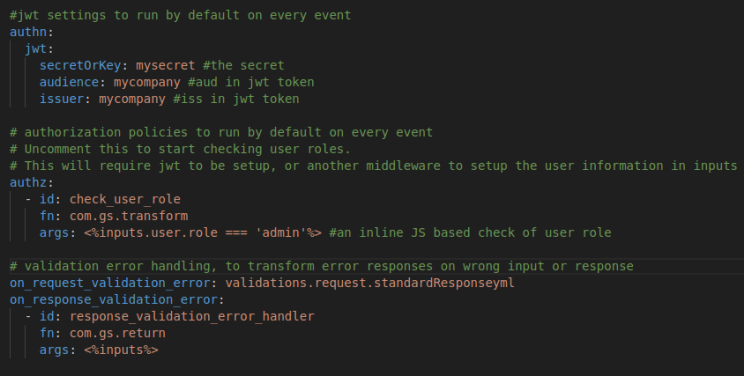
Event level override (customising authn authz logic per event)
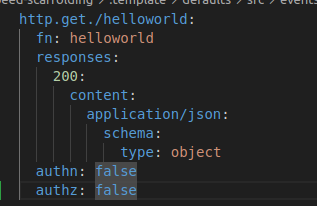
You can add custom handling for example disabling authn/authz, or another custom implementation different from eventsource's default authn/authz for all endpoints
Now authentication and authorization works just by declaration as part of your schema
REST service authorisation error
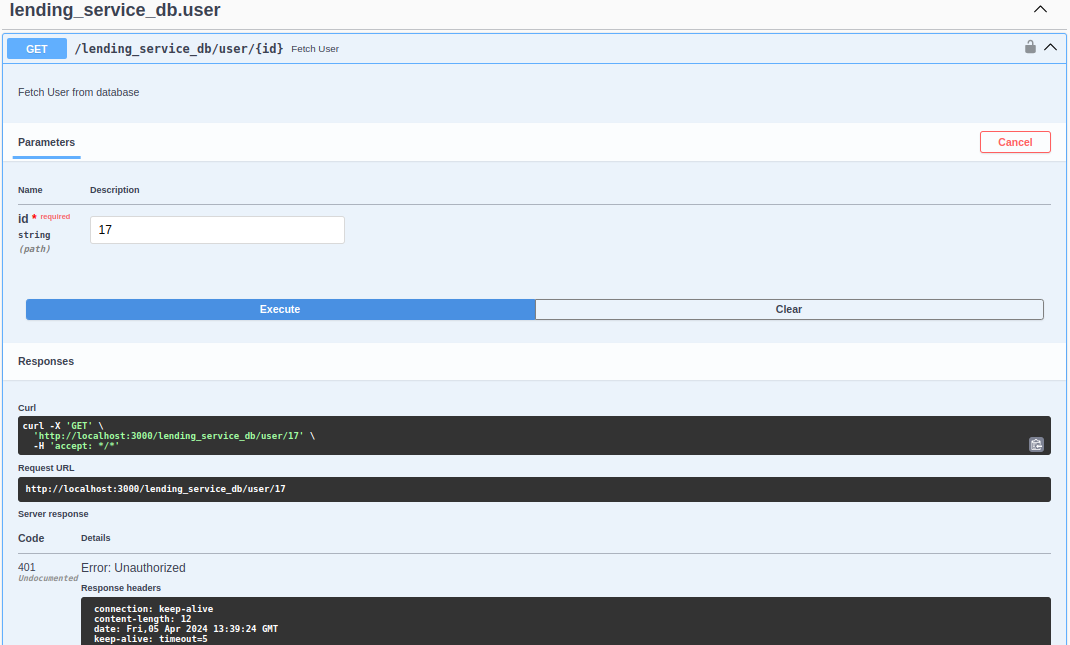
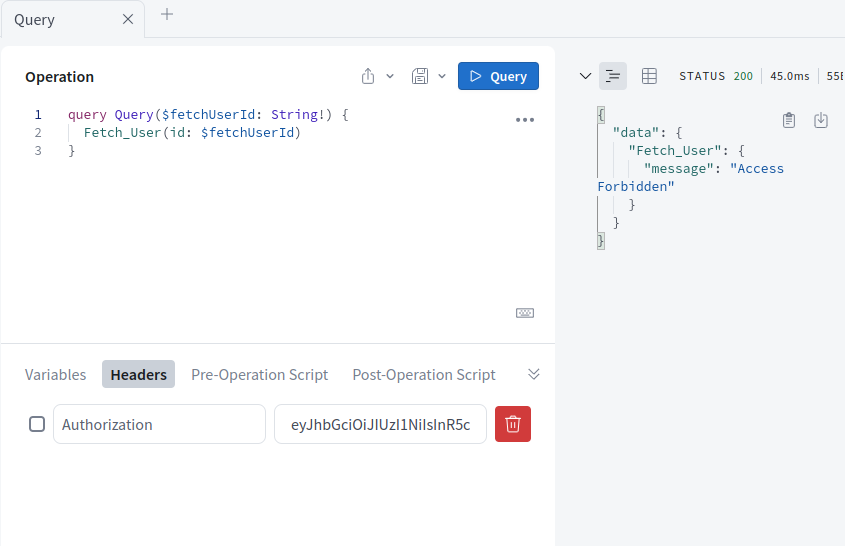
Graphql Authorization Error
Generating API clients
You can generate API clients in any language from a Swagger spec using Swagger Codegen or in case of Godspeed, you can generate YAML workflows for consuming a Swagger API (coming soon)
Generating Test cases
You can generate API integration test cases from Postman collection within Postman environment, or even by using AI to generate test cases over a 3rd gen language testing framework like Chai/Mocha or Robot. This feature is not yet implemented in Godspeed.
Generating UI Components
In Elasticgraph, we wrote a generator to generate the basic data admin UI from the schema of the database entities plus some added annotations. For ex. the autosuggest annotated fields would be used for autosuggestion component in the UI. The fields to show in search results and also the filters on that page would be annotated in the schema definition itself. This can be pretty handy for generating internal tools declaratively.
Parallel development across backend and client/frontend teams
By having your data exchange boundaries defined before you start to develop and test your backend, frontend or dependent microservices independently.
Autogenerating your API Clients (as shown above)
Running mock service based on Swagger spec to start parallel development
Benefits of SDD and SST
Reduced time, effort, cost. Even more so in case of growing code base and teams(s)
Lowered barrier of professional tech experience. And hence more output from younger engineers.
Reduced probability of errors (hence reduced BIR - bug introduction rate)
Prevention of propagation of incorrect data across services
Reduced area of investigation for bugs. And hence - reduced MTTR (mean time to resolve)
Decoupled or modular architecture for greater maintainability and agility
Prevention of technical debt
Better quality and uptime
Increased competitive advantage by being more agile, productive and having happier users.
Experience on your own
The code shown here is of Loan Origination System starter template, from Godspeed's sample projects repository on Github. Feel free to clone it and run the project, and experience the benefits of SDD and SST yourself.
You can watch my video on Schema Driven Development guardrail in Godspeed [here](https://youtu.be/jtn8rvfs7lo?feature=shared).
Conclusion
I believe SDD and SST is paramount for any serious tech org. Every aspiring CTO will try to safeguard his/her organisation against the pitfalls mentioned earlier, by adopting this approach. It just makes common sense!
I hope you find this post useful. Stay tuned for more posts on best practices.
Subscribe to my newsletter
Read articles from Ayush Ghai directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ayush Ghai
Ayush Ghai
A seasoned tech professional and entrepreneur with 17 years of experience. Graduate from IIT Kanpur, CSE in 2006. Founder of www.godspeed.systems