Document Clustering with Python: Techniques and Real-World Examples
 Prakhar Kumar
Prakhar Kumar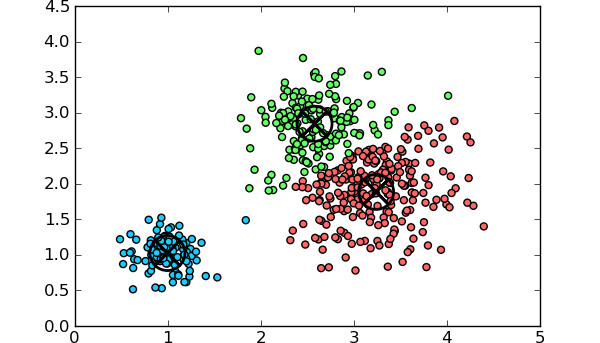
Introduction: Document clustering, a fundamental task in natural language processing (NLP), involves grouping similar documents together based on their content. In this blog post, we'll explore various clustering techniques in Python, provide implementation examples, and showcase real-world applications of document clustering.
Understanding Document Clustering: Document clustering aims to organize a collection of documents into clusters or groups where documents within the same cluster are similar in terms of their content or topics. It enables efficient information retrieval, content organization, and exploration of large text datasets.
Python Libraries for Document Clustering: Python offers robust libraries and tools for implementing document clustering techniques:
scikit-learn: scikit-learn provides a comprehensive suite of clustering algorithms, including K-means clustering, hierarchical clustering, DBSCAN, and more.
Gensim: Gensim offers implementations of topic modeling algorithms like Latent Dirichlet Allocation (LDA) and Latent Semantic Analysis (LSA), which can be used for document clustering.
NLTK: NLTK provides tools for text preprocessing, tokenization, and stemming, essential for preparing text data before clustering.
spaCy: spaCy's linguistic annotations and named entity recognition (NER) capabilities can be useful for text preprocessing and feature extraction in document clustering tasks.
Techniques for Document Clustering:
K-means Clustering: A popular clustering algorithm that partitions documents into K clusters based on their feature similarity.
Hierarchical Clustering: Builds a hierarchy of clusters by recursively merging or splitting clusters based on their similarity.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Clusters documents based on density, suitable for datasets with irregular cluster shapes and noise.
Topic Modeling-Based Clustering: Utilizes topic modeling algorithms like LDA or LSA to group documents based on latent topics extracted from the text.
Python Implementation Examples:
Example 1: K-means Clustering with scikit-learn
pythonCopy codefrom sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.datasets import fetch_20newsgroups
# Load sample text dataset
data = fetch_20newsgroups(subset='all', categories=['sci.space', 'rec.autos', 'talk.politics.guns'])
# Vectorize text data using TF-IDF
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(data.data)
# Apply K-means clustering
num_clusters = 3
kmeans_model = KMeans(n_clusters=num_clusters, random_state=42)
kmeans_model.fit(tfidf_matrix)
# Print cluster labels for documents
print("Cluster Labels:")
for i, label in enumerate(kmeans_model.labels_):
print(f"Document {i}: Cluster {label}")
Example 2: Hierarchical Clustering with scikit-learn
pythonCopy codefrom sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import fetch_20newsgroups
# Load sample text dataset
data = fetch_20newsgroups(subset='all', categories=['comp.graphics', 'sci.med', 'talk.politics.misc'])
# Vectorize text data using TF-IDF
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(data.data)
# Apply Hierarchical clustering
num_clusters = 3
hierarchical_model = AgglomerativeClustering(n_clusters=num_clusters, linkage='ward')
hierarchical_model.fit(tfidf_matrix.toarray())
# Print cluster labels for documents
print("Cluster Labels:")
for i, label in enumerate(hierarchical_model.labels_):
print(f"Document {i}: Cluster {label}")
Example 3: Topic Modeling-Based Clustering with Gensim
pythonCopy codefrom gensim import corpora, models
from sklearn.datasets import fetch_20newsgroups
# Load sample text dataset
data = fetch_20newsgroups(subset='all', categories=['rec.sport.baseball', 'sci.space', 'talk.politics.misc'])
# Tokenize and preprocess text data
tokenized_docs = [doc.split() for doc in data.data]
# Create a dictionary and corpus
dictionary = corpora.Dictionary(tokenized_docs)
corpus = [dictionary.doc2bow(doc) for doc in tokenized_docs]
# Apply LDA for topic modeling
lda_model = models.LdaModel(corpus, num_topics=3, id2word=dictionary)
# Print topics and documents assigned to each topic
print("Topics:")
for topic_id, words in lda_model.show_topics(num_words=5):
print(f"Topic {topic_id}: {words}")
# Assign documents to topics
for i, doc in enumerate(corpus):
topic_id, _ = max(lda_model[doc], key=lambda x: x[1])
print(f"Document {i}: Topic {topic_id}")
Real-World Applications of Document Clustering:
News Aggregation: Clustering news articles into topics for personalized news recommendation systems.
Customer Segmentation: Grouping customer reviews or feedback to identify common themes and preferences.
Text Classification: Preprocessing step for text classification tasks by organizing similar documents into clusters.
Search Result Clustering: Clustering search results to improve user experience and content organization in search engines.
Conclusion: Document clustering is a versatile technique with numerous applications in text analysis and information retrieval. Python's rich ecosystem of libraries and algorithms makes it accessible and efficient to implement document clustering techniques, enabling researchers and businesses to extract meaningful insights and patterns from large text datasets.
Subscribe to my newsletter
Read articles from Prakhar Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by