Understanding the Retry Storm Antipattern
 Abhinav Singh
Abhinav Singh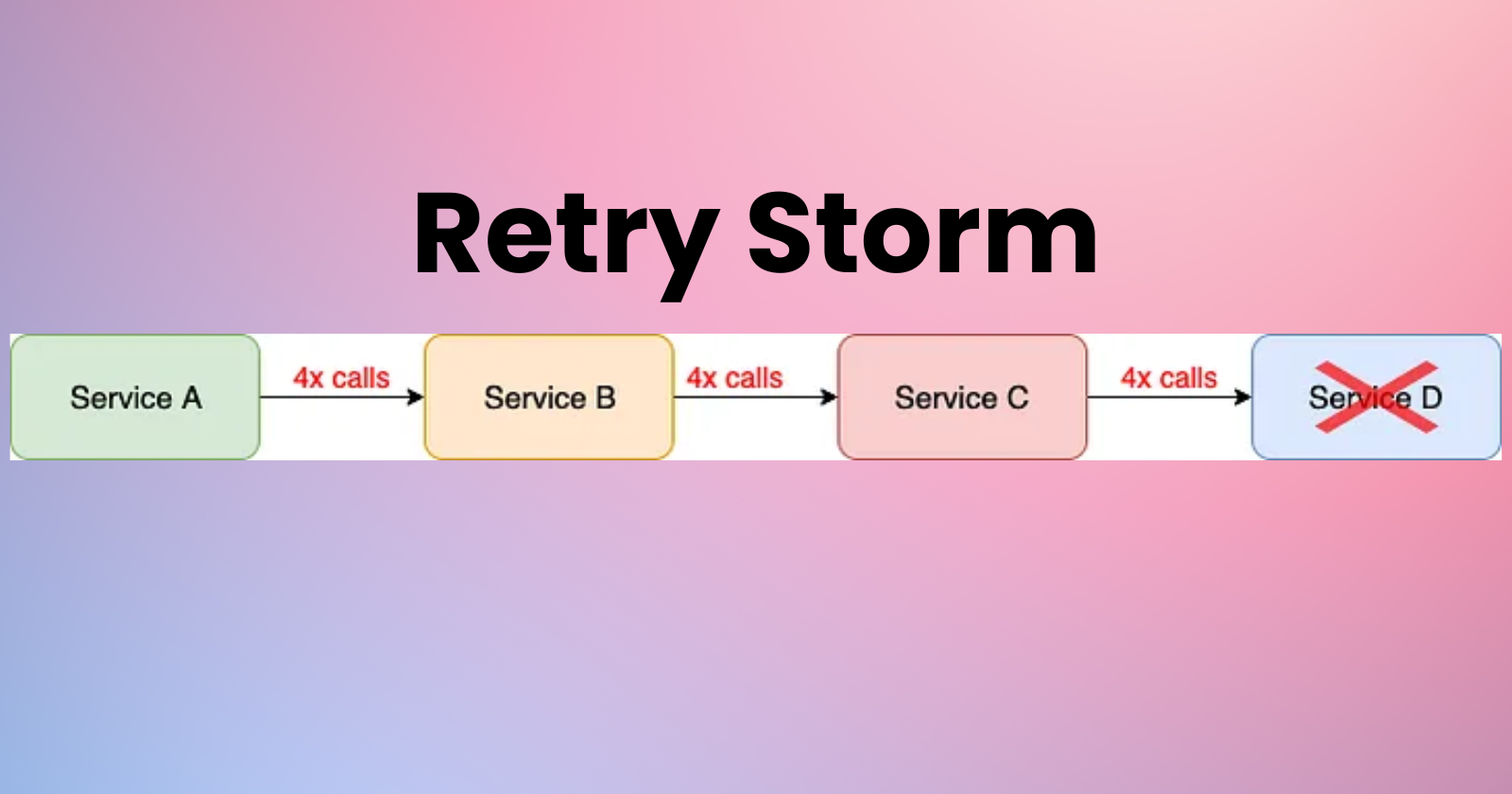
In the realm of software development, encountering challenges and obstacles is not uncommon. These challenges often present themselves in the form of antipatterns, which are commonly recognized solutions that may seem reasonable at first but can lead to unintended consequences or negative outcomes in the long run. One such antipattern that developers often face is the Retry Storm Antipattern.
What is a Retry Storm?
Imagine a scenario where a service or component in a distributed system encounters a transient failure, such as a network timeout or database connection issue. In response to this failure, the system is designed to retry the operation automatically after a brief delay. While retries are essential for handling temporary glitches and ensuring system reliability, they can also lead to unexpected consequences if not managed properly.
A retry storm occurs when a large number of retries are triggered simultaneously, often in response to a widespread failure or bottleneck within the system. These retries can overwhelm downstream services, exacerbating the problem and potentially causing a cascade of failures throughout the system. In essence, the system gets stuck in a loop of retry attempts, unable to break free from the cycle of failure.

Causes of Retry Storms
Retry storms can be caused by various factors, including:
Synchronous Retry Logic: When multiple clients or services encounter a failure simultaneously and retry their requests synchronously, it can lead to a surge in retry attempts, exacerbating the problem.
Exponential Backoff Strategies: While exponential backoff is a common technique used to space out retry attempts and prevent congestion, it can inadvertently contribute to retry storms if not implemented correctly. If all clients adopt the same backoff strategy, they may end up retrying simultaneously after each backoff period, leading to a concentrated burst of retries.
Cascading Failures: A single failure or bottleneck in the system can trigger a cascade of retries from dependent services or components, exacerbating the problem and amplifying the impact of the original failure.
Consequences of Retry Storms
Retry storms can have several detrimental effects on the stability and performance of a system, including:
Increased Latency: The sheer volume of retry attempts can overload downstream services, leading to increased latency and response times for all requests.
Resource Exhaustion: Retry storms can consume significant computational resources, such as CPU cycles and memory, further exacerbating the problem and potentially causing resource exhaustion or outages.
Degraded User Experience: High latency and increased error rates resulting from retry storms can degrade the overall user experience, leading to frustration and dissatisfaction among users.
System Instability: In extreme cases, retry storms can render the entire system unstable or unresponsive, leading to widespread outages and service disruptions.
Mitigating Retry Storms
To mitigate the risk of retry storms and minimize their impact on system reliability, developers can employ several strategies, including:
Exponential Backoff with Jitter: Instead of using a fixed exponential backoff strategy, introducing jitter or randomness into the backoff intervals can help distribute retry attempts more evenly and prevent synchronized retry storms.
Circuit Breaker Pattern: Implementing circuit breakers can help detect and isolate failures, preventing them from cascading throughout the system and triggering retry storms.
Throttling and Rate Limiting: Introducing throttling mechanisms and rate limits can help control the flow of retry attempts, preventing overload and congestion during periods of high demand or failure.
Monitoring and Alerting: Proactively monitoring system health and performance can help detect early signs of retry storms and trigger alerts or automated responses to mitigate the impact.
Conclusion
In conclusion, retry storms are a common antipattern in distributed systems that can have detrimental effects on system reliability and performance. By understanding the causes and consequences of retry storms and implementing appropriate mitigation strategies, developers can minimize the risk of recurrence and ensure the stability and resilience of their systems. Remember, while retries are a valuable tool for handling transient failures, they must be used judiciously and in conjunction with other resilience patterns to avoid unintended consequences.
Retry storms exemplify the delicate balance between reliability and performance in distributed systems. While it's essential to ensure that systems can recover from transient failures, it's equally important to prevent those retries from overwhelming the system and causing further issues. By implementing robust retry strategies and incorporating mechanisms for fault isolation and recovery, developers can navigate the complexities of distributed systems more effectively and ensure a smoother experience for end-users.
In the ever-evolving landscape of software development, learning from antipatterns like retry storms is crucial for improving system design and resilience. By identifying potential pitfalls and understanding their underlying causes, developers can make more informed decisions and build more robust and reliable systems. Ultimately, the goal is to create software that not only meets the functional requirements but also delivers a seamless and dependable user experience, even in the face of adversity.
Subscribe to my newsletter
Read articles from Abhinav Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by